在進入這個進階版系列之前,讓我們先回顧一下云計算與大數據系統的基本設計原則,總結起來有如下幾條:
(1)基礎架構:更多采用商品現貨硬件(如PC架構)?,而很少使用定制化高端(如小型主機)硬件。
(2)擴展性:追求動態擴展、橫向擴展,而非靜態擴展、垂直擴展。需要指出的是,系統擴展性不能是以犧牲性能為前提的,如我們在前面的文章中討論過的,橫向擴展的系統在簡單、淺層查詢的高并發場景中有優勢,但是在復雜、深層查詢的場景中,垂直擴展的系統更具優勢,因此,系統擴展過程中通常是縱向擴展與橫向擴展兼而有之的。
(3)可用性:追求彈性而非零故障(取決于商品現貨硬件)?。
(4)高性能:通過分解與分布而非壓迫來實現。
(5)可用性:更多地關注平均故障恢復時間而非平均故障間隔時間,這一點是使用了商品現貨硬件后做出的改變。
(6)容量規劃:相對于第二平臺架構設計中的最差情形規劃(即導致大量資源被浪費的最大負載規劃)?,第三平臺(云計算與大數據)的規劃精細度要高得多,多采用細顆粒度。
(7)期望失敗:可以容忍部分系統組件的失敗,以此來換取整個系統的持續在線。微服務架構與面向災難(失敗或死機)的系統架構、服務與測試設計框架可以說都是在期望失敗思路的指導下誕生的。
基于這些基本設計原則,我們來逐一分析可擴展系統構建、開源開發與商業模式,以及從服務驅動的體系架構到微服務架構這3個方面。
構建可擴展系統的目的是實現可擴展的應用與服務。我們首先了解一下可擴展應用與服務的九大誤區:
①完全依賴本地資源:數據沒有實現云(網絡)存儲。
②服務采用強依賴性:服務的強依賴性指的是B服務依賴于A服務,而A服務下線后將直接導致B服務的下線。在第三平臺的架構設計中,我們應把B服務設計為當A服務不可用時,采用其他渠道繼續提供服務,例如從內容分發服務(Content DeliveryNetwork,CDN)或緩存區中保存的數據繼續提供服務,以此來提高用戶體驗,同時在后臺通知DevOps團隊修復故障服務。
③CDN無用論:CDN的最大價值在于降低服務器和網絡的壓力,以及提升用戶體驗。除非自建CDN,否則利用現有CDN服務提供商網絡不失為上策(規模經濟效應)?。
④緩存無用論:緩存是提供系統整體效能加速的一把雙刃劍,好的設計原則會讓系統事半功倍,壞的設計原則可能讓用戶總是得到過期的數據。在后文中我們會介紹正確使用緩存的方法。
⑤縱向擴展而非橫向擴展:縱向擴展的最大問題是如果系統是單機系統,就會出現因系統升級或硬件故障而下線。此外,還有一個問題是基于縱向擴展設計的系統的瓶頸性顯而易見,因此縱向擴展的擴展性能甚為堪憂。
但是,這并不說明縱向擴展不再有價值,實際上,在真正的商業環境中,很多高可用系統的架構都采用主從熱備份、多機互為熱備份、分布式共識等架構,它們往往比單純的橫向擴展系統有更為簡捷的架構邏輯,更易于維護,性價比也更高,甚至有更高的系統算力——是的,你沒有看錯,很多所謂的“水平分布式系統”的算力都非常糟糕。其中最核心的邏輯在于,在一個實例的CPU并發能力都沒有得到充分利用的前提下就貿然地堆疊更多的實例,并不能獲得更高的并發算力,因為多實例間的網絡通信會讓系統性能呈指數級下降。
構建分布式系統的第一原則就是:先縱向擴展,再橫向擴展。這個和先學會走再學習跑是一個道理。縱向擴展與橫向擴展之間的關系并非是從0到1的關系,它們之間還有0.5、0.25、0.75。打個具體的比方,單機系統可以升級為多機熱備份系統,多機熱備份可以升級為分布式共識系統,分布式共識系統再繼續擴展為多級分布式共識系統,直至在可行的條件下拓展為大規模水平分布式系統。而在真正的商業環境下,大規模水平分布式系統不但極為少見,而且系統效率往往并不高。在全球范圍內,只有在極為特殊的情境下,大規模水平分布式系統才能物盡其用。換而言之,為了追求“水平”分布式而部署水平分布式是盲目且沒有價值的行為。
⑥單點失效是可以容忍的:可擴展系統構建中應避免任何可能出現的單點故障。從存儲、網絡、計算的IaaS層一直到應用層,應當盡可能全部實現高可用性。
⑦無狀態與解耦合無關緊要:無狀態是架構與服務解耦的先決條件。典型的有狀態服務是傳統的數據庫服務,每一筆交易會有多次操作,前后之間存在狀態依賴性,以實現數據的一致性。而無狀態服務沒有這種強一致性和依賴性要求,因而可以更容易實現分布式處理和并行處理。無狀態+解耦合是微服務架構的核心理念——構建云計算或大數據服務的主要原則。
⑧只要關系數據庫:與這個觀點相對應的一個極端是RDBMS徹底無用論。此二者都是非此即彼,尤其在大數據時代,RDBMS獨立難支,但是沒有RDBMS也是有失偏頗的。除了少數非常專一的應用與服務只需要某種單一數據庫——例如鍵值數據庫NoSQL,多數系統需要兩種或多種數據庫來豐富數據處理能力。
⑨數據復制無用論:這個誤區呼應第一個誤區。可擴展應用及基礎架構中解決的最核心的問題是數據的高可用性和可擴展性,這兩者主要是通過數據復制來實現的,例如數據庫系統中的讀復制以及分片處理技術。
要衡量一個系統的可擴展性,通常可以從以下5個維度來進行:
①負載:負載可擴展性是衡量分布式系統能力最主要的指標,它主要關注系統隨著負載增/減的可伸縮性(彈性)?。在第一、第二平臺時代,分布式系統的主要方式是縱向擴展;在第三平臺時代,分布式系統的主要方式是橫向擴展。
②功能:系統實現并提供新功能的代價與便捷性。
③跨區域:系統支持廣泛區域用戶與負載的能力。例如,從一個區域的數據中心延展到另一個或多個區域的數據中心,以更好就近支持本地負載的這種能力。
④管理:系統管理的安全性與便捷性,以及支持新客戶的能力。例如,對多租戶環境的支持,如何在同一物理架構上實現良好的數據安全性與一致性支持等。
⑤異構:異構可擴展性主要是指對不同硬件配置的支持性,其中包括系統硬件升級、對不同供應商硬件的無縫繼承等。
如果從數學(算法)角度來衡量可擴展系統,那么我們通常采用的是時間復雜度。如果一個系統對資源(計算、網絡、存儲等)的需求與輸入(服務的節點、用戶數等)的關系符合,則我們認為該系統具有可擴展性;反之如果是
或更高階的關系,則該系統不具有可擴展性。
在網絡領域(如路由協議)?,當路由器節點增加時,路由列表長度(內存資源)與路由節點之間的關系是O(lgN),即隨著路由節點的增加,路由列表增長趨緩(增長曲線趨平)?,則該路由協議具有可擴展性。
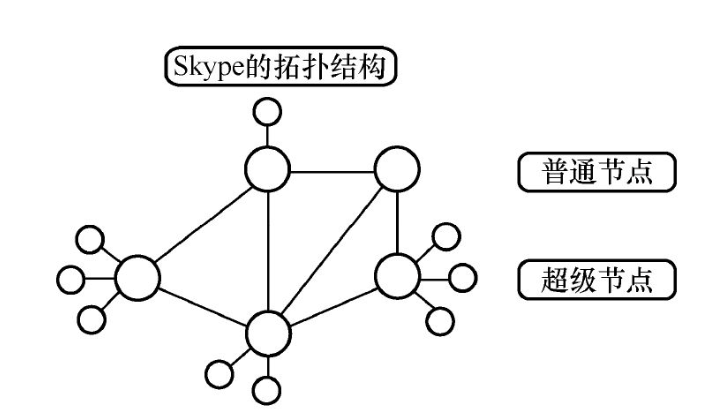
以點對點文件分享網絡(服務)的發展為例,最早的內容分享系統Napster的設計架構是一臺中央索引服務器,該服務器負責收集每個加入節點的可分享文件列表,這樣的設計導致系統存在單一故障點,也容易被黑客攻擊或招來法律訴訟。有鑒于Napster的法律訴訟敗訴,隨后出現的Gnutella解決了Napster的單點失效問題,推出了純分布式點對點文件分享服務。在早期階段,Gnutella的在線文件查詢設計采用泛洪查詢模式,即一個節點發出的文件搜索請求會分發給網絡內其他所有節點,從而導致在整個網絡規模超過一定規模后多數查詢會因超時而失敗(這種擴展性改革雖然避免了單點失效,但系統效率被降低了)?。后來Gnutella采用了分布式哈希表,它的設計原則是網絡中每個節點只需要與另外的lgN個節點互動來生成分布式哈希表中的鍵值,因此系統可擴展到容納數以百萬計的節點的這種方案才解決了文件查詢可擴展性的問題。當然,在純分布式P2P系統中,分布式哈希表所面臨的問題是查詢關鍵字只支持完全匹配,不支持模糊匹配、模式查詢。這一問題在混合式P2P系統中得到了解決,例如Skype音視頻服務系統采用的是兩級用戶架構——超級節點+普通節點,其中超級節點負責建立查詢索引與普通節點間路由,普通節點則是用戶終端。圖4-1展示的是Skype的混合P2P架構。混合P2P架構在實踐中既解決了可擴展性不足(存在單點失效)的問題,也解決了純分布式系統的信息索引與查詢困難的問題。
一套完整的云應用/服務架構通常可以被分為負載均衡層、應用服務層、緩存服務層數據庫服務層以及云存儲層。云應用/服務的5層架構如圖2所示。
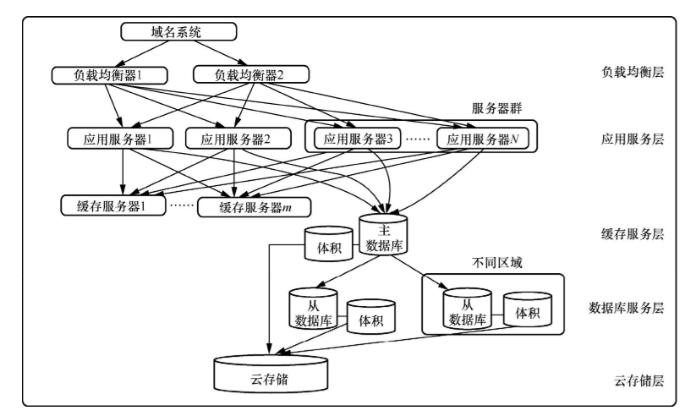
下面我們主要介紹負載均衡層、應用服務層和緩存服務層。
(1)負載均衡層
負載均衡層是5層架構中最先面對用戶的,也是相對容易實現的。通常為了避免單點失效,至少設置兩臺負載均衡服務器(通常在兩臺物理主機之上,以避免單機硬件故障導致的單點失效)?。整個擴展設置過程通常可以完全自動化,例如通過DNS API來配置新增或刪除負載均衡節點。常見的負載均衡解決方案有HAProxy和Nginx,它們通常可以支持跨云平臺的負載均衡,即服務器及其他層跨云。當然這種架構的設計與實現復雜度會急劇增高,云爆發就是典型的跨云基礎架構模式。智能的負載均衡層能做到根據應用服務器層的健康狀態和負載狀態動態引流,以確保系統真正實現均衡的負載。
云服務提供商通常會提供現成的負載均衡服務,例如AWS的ELB、RackSpace的CLB,還有VMware vCloud Air Gateway Services,它們都提供強大的負載均衡服務。
(2)應用服務層
負載均衡層之下就是應用服務層,它負責處理負載均衡層轉發的用戶請求,并返回相應的數據集。通常數據集分為靜態數據與動態數據,前者大抵可以被保留在緩存服務層,以降低應用服務器及數據庫服務器的負載(見圖2)?,并加快客戶端獲得返回數據的速度;后者通常需要數據庫服務層的配合來動態生成所需數據集。本層的擴展經常通過對現有服務器的負載進行監控(主要是CPU,其次為內存、網絡、存儲空間)?,并根據需要進行橫向擴展(即水平擴展)或縱向擴展(即垂直擴展)來實現。橫向擴展通常是上線同構的服務器(物理機或虛擬機)?,以降低現有服務器或服務器集群負載;縱向擴展則對CPU、內存、網絡、存儲空間等進行升級。橫向擴展通常不需要系統下線,但是縱向擴展要求被升級的主機(可能是虛擬機或容器)重啟。
應用服務層涉及應用服務邏輯,因而當多臺服務器協同工作時,還需要確保它們之上所運行服務的一致性。DevOps通常作為PaaS層一部分任務或數據中心的管理與編排組件,實現一致化的應用升級和部署。
(3)緩存服務層
緩存服務層既可能存在于應用服務器層與數據庫服務器層之間,也可能在應用服務器層之上,前者可以被用來降低數據庫服務器的重復計算量與網絡負載,后者則被用來降低應用服務器負載與網絡帶寬消耗。緩存技術的應用范圍極廣,從Web服務器到中間件再到數據庫都大量使用緩存,以降低不必要的重復計算,進而提高系統的綜合性能。
緩存服務層的擴展性實現在避免出現單點失效的基礎之上,單個節點的緩存服務器/應用服務器共享節點的方式在生產環境中都是不可取的,主要問題是如何實現多緩存節點間的負載均衡。常見的分布式簡單緩存實現是Memcached(全球較為繁忙的20個網站中有18個使用了Memcached)?,多臺Memcached服務器間形成了一張哈希表,當有新的緩存節點加入或舊的節點被刪除(或下線)時,現有節點并不需要全部進行大規模改動來生成新的哈希表(這種方法被稱作一致性哈希算法)?。對于哈希表中數據的替換與更新,Memcached采用的是生存時間值(Time to Live,TTL)與最近最少使用(Least Recently Used,LRU)模式。對于更復雜的高擴展性緩存系統的設計來說,屬于NoSQL類的CouchBase數據庫提供了更為健全的企業級緩存功能的實現方式,例如數據常存、自動負載均衡、多租戶支持等。
?(文/Ricky - HPC高性能計算與存儲專家、大數據專家、數據庫專家及學者)
· END ·






)


)




![[計算機網絡]數據鏈路層](http://pic.xiahunao.cn/[計算機網絡]數據鏈路層)



![[特殊字符]算法次元突破:螺旋矩陣的“能量解碼術” vs 超立方體的“維度折疊指南”](http://pic.xiahunao.cn/[特殊字符]算法次元突破:螺旋矩陣的“能量解碼術” vs 超立方體的“維度折疊指南”)
