一、向量化表示的核心概念
1.1 特征空間與向量表示
- 多維特征表示:通過多個特征維度(如體型、毛發長度、鼻子長短等)描述對象,每個對象對應高維空間中的一個坐標點,來表示狗這個對象,這樣可以區分出不同種類的狗狗;如果有些種類難以區分,還可以繼續擴充向量的維度。世界萬物都可以用這種方法表達。
- 向量特性:
- 相似對象在特征空間中距離更近
- 支持向量運算(如:警察-小偷 ≈ 貓-老鼠)
- 典型應用場景:
- 以圖搜圖(圖片向量化)
- 視頻推薦(視頻向量化)
- 商品推薦(商品向量化)
- 智能問答(文本向量化)

1.2 向量數據庫特點
| 特性 | 傳統數據庫 | 向量數據庫 |
|---|---|---|
| 存儲結構 | 數據表 | 向量集合 |
| 查詢方式 | 精確匹配 | 相似度搜索 |
| 查詢結果 | 確定值 | 近似最近鄰 |
二、最近鄰問題(Nearest Neighbors)
2.1 暴力搜索(Flat Search)
- 原理:線性掃描所有向量,計算與查詢向量的相似度
- 相似度度量:
- 余弦相似度(向量夾角)
- 歐氏距離(向量間距)
- 優缺點:
- ? 100%準確率
- ? O(n)時間復雜度
- 暴力算法:優點是搜索質量是完美的,缺點是耗時;如果數據集小,搜索時間可以接受,那可以用。
- 優化思路:**縮小搜索范圍**,比如用【***聚類算法***】(比如k-means),【***哈希算法***】(位置敏感哈希)等,但不能不能保證是最近鄰的(除了暴搜能保證,其他都不能保證)
2.2 近似最近鄰搜索(ANN)(Approximate Nearest Neighbors)-提速度
2.2.1 基于聚類的方法(以K-Means為例)
- 隨機生成四個點,作為初始的聚類中心點,然后根據與中心點距離的遠近進行分類;
- 計算已有分類的平均點,該平均點作為中心點繼續分類,然后不斷重復,趨于收斂
# K-Means偽代碼
1. 隨機初始化k個中心點
2. while not converged:a. 將每個向量分配到最近的中心點b. 重新計算每個簇的中心點(均值)
3. 搜索時只需查詢最近簇內的向量
- 優化技巧:
- 增加聚類數量(降低速度)
- 查詢多個最近簇(降低速度)
- 權衡:搜索質量 vs 搜索速度
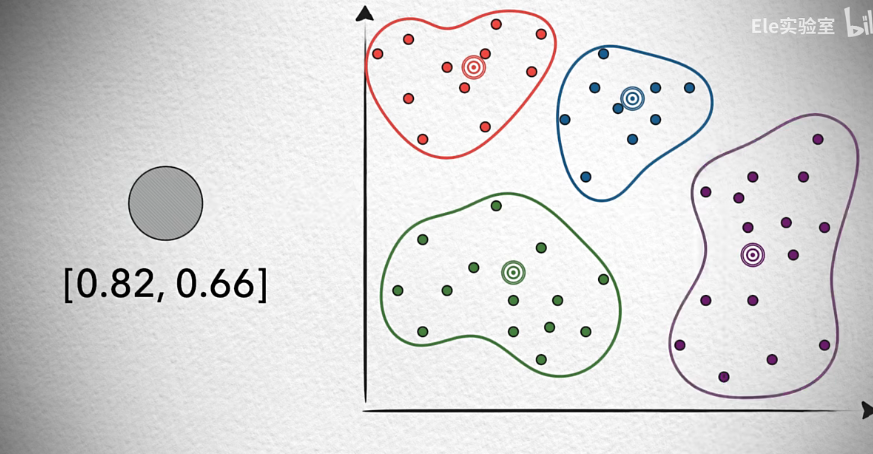
2.2.2 位置敏感哈希(LSH)(Locality Sensitive Hashing)
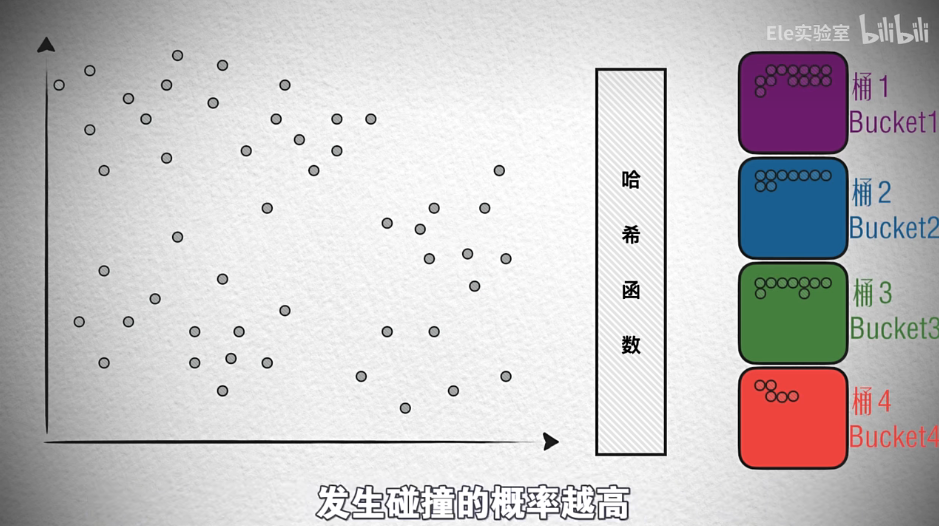
核心特性:
- 高碰撞概率設計
- 相似向量更可能哈希到同桶
- 哈希碰撞:由于輸入是固定長度的數據,而輸出是固定長度的哈希值,根據鴿巢原理,必然會出現數據不同而哈希值相同的情況,這叫碰撞。
- 正常而言,哈希算法要盡可能減少碰撞的發生,而(對向量)位置敏感哈希函數-LSH則相反,盡可能讓位置相近的數據發生碰撞,然后根據哈希碰撞來進行分組,構建方法:隨機劃出直線分割平面,兩面的點分別增加意味0或1來表示
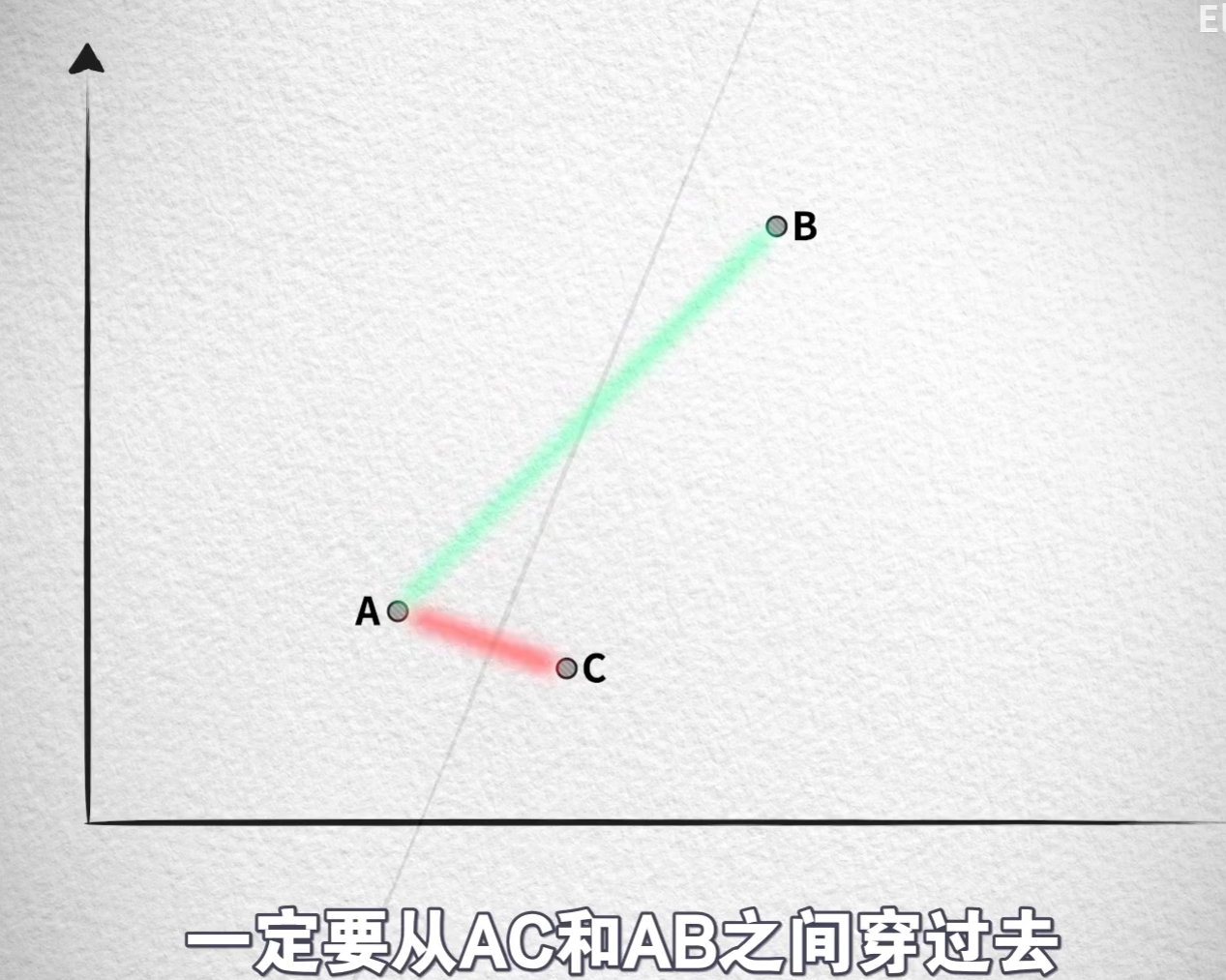
隨機超平面哈希實現(隨機投影):
- 在d維空間中隨機生成超平面
- 根據向量在超平面哪側生成bit(1/0)
- 組合多個超平面結果生成二進制哈希碼
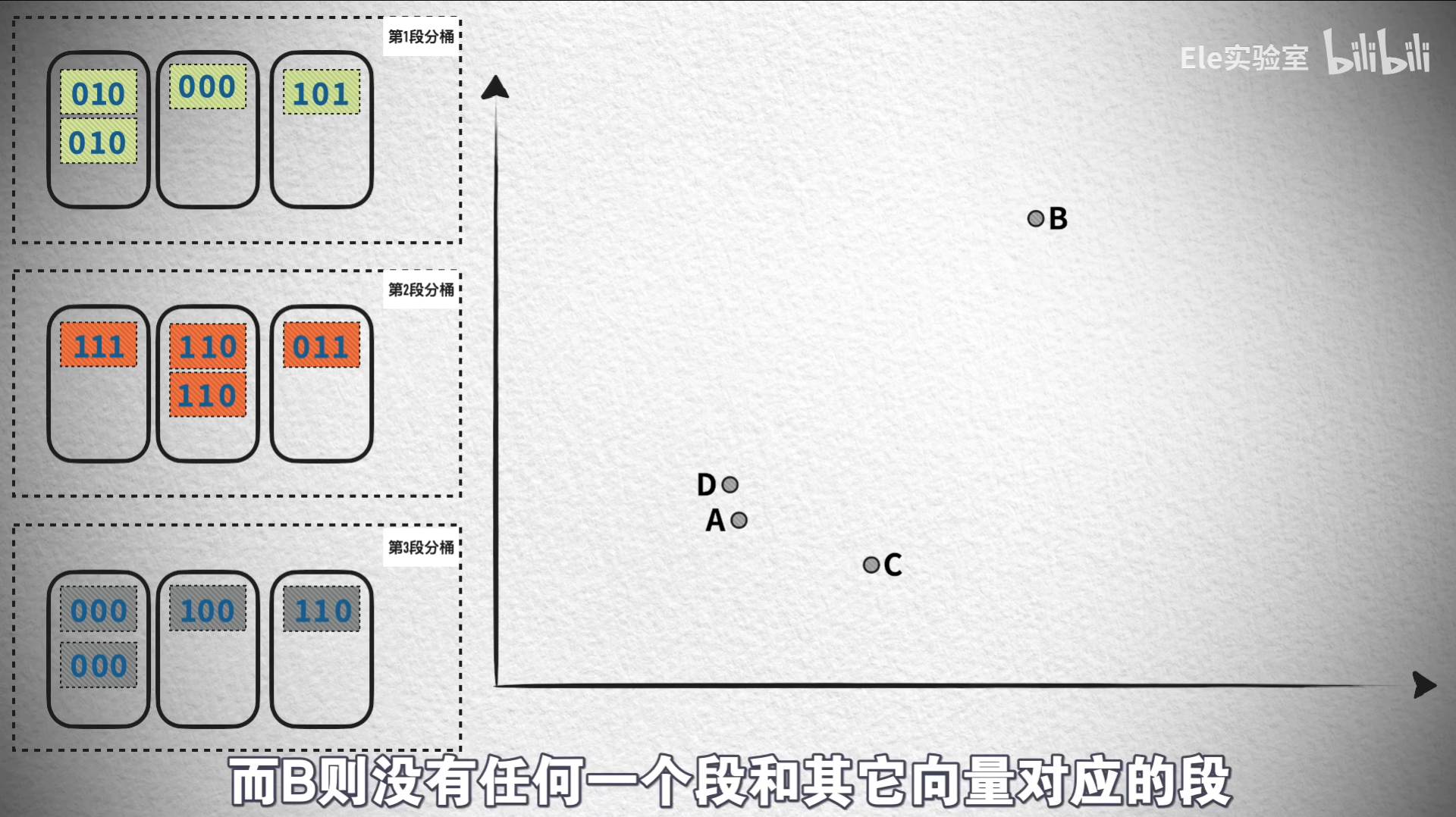
分段優化策略:合理地擴充
- 將哈希碼分成m段
- 只要任意一段匹配即作為候選
- 顯著提高召回率
積量化(Product Quantization)-省內存
問題:除了搜索速度,還有內存開銷問題
方法——量化(Quantization):降低向量本身大小,但產生碼本
聚類算法訓練——有損壓縮(圖片中每個像素點都被其所在分類質心點所替代)——在一定程度保留原始信息——給質心編碼,只需存儲單個編碼值,減少空間(把向量用質心編碼表示就是量化)——碼本

存在問題——維度災難:
維度增加(數據稀疏)——需要非常大的聚類數——維度災難——碼本指數級膨脹,超過了量化節約出來的內存,得不償失
進一步解決:高維分成低維(128->16–子空間需要的聚類數量小2^8)——拼接子向量——笛卡爾積——積量化PQ(Product Quantization)


NSW (Navigable Small World) - 犧牲內存,換取速度和質量
6人理論小世界——導航小世界nsw

需要手動建立圖結構
保證以下性質:

需要這個:德勞內三角剖分法

但是這個建立的圖結構搜索時候不一定很快速,所以nsw方法如下,
在隨機足夠放回向量的初始階段向量點非常的稀疏,很容易在距離較遠的點之間建立連接,通過長鏈接快速導航,再通過短鏈接精細化搜索
這就是NSW算法的大致工作原理,短連接滿足了德勞內三角,長鏈接幫助快速導航,妙在先粗快,后細慢

HNSW(Hierarchical NSW):分層的導航小世界
搜索時候從最上層進入,快速導航,逐步進入下一層,比 NSW 更可控穩定。缺點就是占用內存太大

三、關鍵技術對比
| 方法 | 預處理成本 | 查詢速度 | 內存消耗 | 準確性 | 補充說明 |
|---|---|---|---|---|---|
| 暴力搜索 | 無 | 慢 | 低 | 100% | 線性掃描所有向量,保證結果完全準確,但時間復雜度高(O(n)),僅適用于小規模數據集。 |
| K-Means聚類 | 高 | 快 | 中 | 80-95% | 通過聚類縮小搜索范圍,犧牲少量精度換取速度。增加聚類數量可提高準確性,但會降低查詢速度。 |
| LSH | 中 | 最快 | 高 | 70-90% | 基于哈希碰撞的近似搜索,適合高維數據。分段策略可提高召回率,但內存開銷較大。 |
| NSW | 中 | 快 | 中 | 85-98% | 基于圖結構的導航小世界,通過長鏈接快速導航、短鏈接精細化搜索。預處理成本低于HNSW,但穩定性稍差。 |
| HNSW | 高 | 最快 | 高 | 90-99% | 分層NSW,搜索時從頂層快速導航到底層,精度接近暴力搜索,但內存占用高,適合大規模實時場景和高維向量場景:既解決了高維數據的稀疏性問題,又避免了傳統方法因維度增長導致的性能崩塌,成為高維向量搜索的黃金標準 |
| PQ(積量化) | 高 | 中 | 低 | 75-90% | 通過子空間量化和笛卡爾積壓縮向量,顯著節省內存,但需權衡精度損失。適合內存受限的部署場景。 |
關鍵總結
- 速度優先級:LSH ≈ HNSW > NSW > K-Means > PQ > 暴力搜索
- 內存優先級:PQ < 暴力搜索 < NSW < K-Means < HNSW < LSH
- 精度優先級:暴力搜索 > HNSW > NSW > K-Means > PQ > LSH
適用場景建議
- 實時推薦/搜索:HNSW(高精度+高速)
- 內存敏感型應用:PQ(如移動端、嵌入式設備)
- 中等規模數據:NSW(平衡速度與內存)
- 高維數據快速過濾:LSH(如去重、粗篩)
- 小數據集或驗證場景:暴力搜索(確保100%準確率)
四、典型應用場景
-
大語言模型:
- 對話歷史向量化存儲
- 實現"記憶檢索"功能
-
推薦系統:
- 用戶/商品聯合向量空間
- 實時相似推薦
-
多媒體檢索:
- 跨模態向量搜索(圖→文,文→視頻)
以上是整理的筆記,筆記 pdf 下載 --》 【向量數據庫與近似最近鄰算法】-CSDN文庫
速覽b站原片!–》 【上集】向量數據庫技術鑒賞_嗶哩嗶哩_bilibili
我的其他文章
RAG調優|AI聊天|知識庫問答
- 你是一名平平無奇的大三生,你投遞了簡歷和上線的項目鏈接,結果HR真打開鏈接看!結果還報錯登不進去QAQ!【RAG知識庫問答系統】新增模型混用提示和報錯排查【用戶反饋與優化-2025.04.28-CSDN博客
- 你知不知道像打字機一樣的流式輸出效果是怎么實現的?AI聊天項目實戰經驗:流式輸出的前后端完整實現!圖文解說與源碼地址(LangcahinAI,RAG,fastapi,Vue,python,SSE)-CSDN博客
- 【豆包寫的標題…】《震驚!重排序為啥是 RAG 調優殺手锏?大學生實戰項目,0 基礎也能白嫖學起來》(Langchain-CSDN博客
- 【Langchain】RAG 優化:提高語義完整性、向量相關性、召回率–從字符分割到語義分塊 (SemanticChunker)-CSDN博客
-
- 如何讓你的RAG-Langchain項目持久化對話歷史\保存到數據庫中_rag保存成數據庫-CSDN博客
- 分享開源項目oneapi的部分API接口文檔【oneapi?你的大模型網關】-CSDN博客
Agent
- 【MCP】哎只能在cursor中用MCP嗎?NONONO!三分鐘教你自己造一個MCP客戶端!-CSDN博客
docker
- 【docker0基礎教學】手把手教你將你的本地項目進行docker部署-CSDN博客
- 怎么把我的前后端項目通過docker部署到云服務器【手把手教學】-CSDN博客
前端
- 面試官:你會怎么做前端web性能優化?我:.%*&.!-CSDN博客
- CDN是啥?十分鐘讓Cloudflare免費為你的網站做CDN加速!-CSDN博客
nginx
- Nginx 反向代理,啥是“反向代理“啊,為啥叫“反向“代理?而不叫“正向”代理?-CSDN博客
- 關于nginx,負載均衡是什么?它能給我們的業務帶來什么?怎么去配置它?-CSDN博客
好用插件
- 你想不想讓你寫的博客一鍵發布多平臺?!
















![【算法題】荷蘭國旗問題[力扣75題顏色分類] - JAVA](http://pic.xiahunao.cn/【算法題】荷蘭國旗問題[力扣75題顏色分類] - JAVA)

![AtCoder AT_abc404_g [ABC404G] Specified Range Sums](http://pic.xiahunao.cn/AtCoder AT_abc404_g [ABC404G] Specified Range Sums)
