Title
題目
Guided ultrasound acquisition for nonrigid image registration usingreinforcement learning
基于強化學習的用于非剛性圖像配準的引導式超聲采集
01
文獻速遞介紹
超聲成像通常用于引導手術和其他醫療程序,在這些過程中,臨床醫生會持續手動采集二維(2D)超聲圖像。這些在術中采集的超聲圖像,通常在三個方面較為稀疏:(1)它們不像磁共振(MR)和計算機斷層掃描(CT)等其他體部醫學圖像那樣在規則的網格位置上進行采樣,切片之間的間隔是可變的;(2)在沒有外部空間跟蹤的情況下,這些圖像之間的相對位置是未知的;(3)它們只覆蓋有限的區域,并且感興趣區域(ROI)很可能不完整,例如存在使用該成像方式無法看到的缺失特征,或者只顯示了某個結構(如器官)的一部分。 在這項工作中,我們專注于開發一種機器學習方法,以在超聲圖像與三維(3D)體部術前CT圖像配準的特定背景下,克服上述挑戰。當前最先進的方法,由于超聲圖像的稀疏性以及可用于對齊的信息有限,在配準準確性方面往往存在不足。特別是,我們認為可以利用超聲采集的交互性來解決上述挑戰。在此背景下,使超聲采樣成為所學習的配準算法的一個組成部分,可能是提高這種配準類型準確性的關鍵,但到目前為止,這方面的研究和闡述還很有限。 一堆超聲圖像與體部術前圖像(如3D CT圖像)之間的空間對齊,在一些臨床場景中是很有用的。例如,在超聲圖像引導的介入手術過程中,跟蹤術前圖像中確定的腫瘤位置(德拉科波洛斯和克里索霍伊季斯,2016年;古亞等人,2010年;埃爾哈瓦里等人,2010年),或者在術中超聲成像時,相對于術前采集的更大視野(FOV),在通常較小的體積中定位感興趣區域,以用于術中導航(胡等人,2012年;阿明等人,2003年;溫等人,2008年;彭尼等人,2004年)。 體部圖像被定義為在單個圖像坐標系中定義了體素位置的3D圖像,在這里是術前CT圖像,其強度值是從規則的網格位置采樣得到的。在這種情況下,如果超聲圖像能夠被重建為體部圖像,那么配準就變成了一個“體對體配準”問題。無論是否使用外部跟蹤器(托馬熱維奇等人,2005年;黑爾德曼等人,2010年;海塞爾曼等人,2020年),徒手超聲圖像的3D重建可能會遇到一些問題,比如需要優化重建參數或者處理不完整的信息。現有的圖像配準方法主要集中在體對體配準(比利亞隆等人,2011年;湯姆森等人,2020年),最近也出現了基于機器學習的算法以提高效率和準確性(陳等人,2021年)。大多數方法仍然只適用于特定的感興趣應用,而一個適用于更廣泛問題的通用解決方案仍然是一個活躍的研究領域。 “體對切片配準”問題也得到了研究,部分原因是二維圖像之間的相對位置未知,在這種情況下,每個二維超聲圖像通常是獨立地與體部圖像進行對齊(費拉ante和帕拉吉奧斯,2017年)。超聲圖像坐標和體對切片變換都是在3D空間坐標系中定義的,因此二維超聲圖像被稱為圖像“切片”。 將其表述為一種機器學習方法時,體對切片配準可以從多個相鄰圖像作為輸入中受益,并且還可以聯合預測多個切片(2D圖像)與體部圖像之間的變換(費拉ante和帕拉吉奧斯,2017年)。為了清晰起見,本文將這種情況稱為“體對堆配準”,其中一系列連續采集的圖像被稱為一“堆”切片。體對堆配準與先進行3D重建的方法之間的區別在于,二維圖像之間的相對位置是事先獨立估計(先重建的方法),還是隱含地處理(體對堆方法)。 ### 1.2 變形的約束不足估計 雖然一般來說,體對體配準在估計非剛性變形方面是一個不適定問題,但正是由于需要額外估計單個切片與體部圖像之間的3D變換,使得體對堆配準可以說受到的約束更少。這種約束的缺乏促使大多數現有研究采用高度受限的變換模型,例如具有六個自由度(DOF)的剛性變換假設,這通常用于術中數據與術前數據的配準。一個典型的例子是我們在這項工作中對肝臟超聲與CT配準的應用,其中首先應用剛性配準來對齊術中超聲切片和術前CT圖像(魏等人,2021b;溫等人,2008年;孫等人,2018年;拉馬利尼奧等人,2020年)。 除了可以建模為受約束的剛性或仿射變換的切片與體部圖像之間的坐標系轉換之外,器官運動和其他軟組織變形需要使用更高階的變換模型來進行補償。已經有研究提出將非剛性配準應用于這種情況(埃爾哈瓦里等人,2010年;李等人,2010年;蘭格等人,2003年)。部分由于其約束不足的性質,在非剛性方法中使用了一種重要的“配準參數”:對變形正則化的加權(例如位移梯度的非平滑懲罰項L2范數或彎曲能量(哈斯金斯等人,2020年;傅等人,2020b;陳等人,2021年),以促進平滑(從而受到約束)的局部組織變形)。然而,盡管肝臟不同部位的材料屬性(如硬度)以及不同解剖結構(如血管)和病理結構(如腫瘤)之間存在差異,但這個權重通常是固定的,并且被認為在各處都相同。與此類似,早期嘗試使用生物力學模型作為先驗約束變換模型時,只研究了均勻彈性(厄茲居爾等人,2018年)。 然而,從許多已報道的結果中可以明顯看出,肝臟內不同區域之間的配準性能差異很大(拉馬利尼奧等人,2020年)。空間自適應變形正則化可能為這種應用提供更靈活的變換模型,盡管這可能會使其不適定性加劇。 在體對切片配準之外,空間自適應變形正則化可以通過數據驅動的方法來推斷(辛普森等人,2015年;帕皮耶茲等人,2013年;里肖姆等人,2010年;埃爾莫西略等人,2002年)。對于基于學習的配準算法,這些配準參數變成了超參數,并且可以通過超網絡(胡普斯等人,2021年)進行重新參數化,以便在測試時進行高效的自適應調整。其他可自適應的配準方法也以元學習的形式被提出(樸等人,2022年;鮑姆等人,2022年)。這些方法需要在測試時基于一些示例對訓練好的配準模型進行微調。例如,鮑姆等人(2022年)在一個交互式設置中闡述了這個問題,在微調過程中,配準可以通過用戶添加的數據進行手動調整。 ### 1.3 不相等的超聲采樣位置 除了局部變形之外,包括解剖特征在內的成像內容在不同的成像位置也有很大差異。這是配準性能具有空間依賴性的另一個可能原因。例如,在基于血管的配準算法中,所采集切片中包含的血管結構的復雜性和豐富性,對成功配準起著重要的積極作用(拉馬利尼奧等人,2020年、2018年、2022年)。 在本文中,我們認為所有切片的采樣位置可以通過以下兩個參數進行參數化:(1)這一堆切片的起始位置(相對于某個參考);(2)這一堆切片的物理長度(例如以毫米為單位),這里假設沿著器官表面有一條線性采集路徑。這種近似線性的采集路徑適用于臨床應用中廣泛的需要接觸的超聲成像,例如侵入性肝臟手術、經直腸前列腺介入、胎兒異常檢測和肌肉骨骼成像。因此,這一堆切片的長度可以被視為一個配準參數,它控制著空間覆蓋范圍和準確的初始定位(隨后進行局部非剛性配準)之間的平衡,也就是說,更長的一堆切片應該覆蓋更多用于配準的特征,但可能需要估計更復雜的非剛性變換,而當這一堆切片的長度趨近于零時,就不再需要切片之間的變換了。 上述觀察結果激發了這項工作的主要貢獻之一:開發一種交互式配準方法,該方法允許對超聲采樣位置進行順序建議,并從這些建議的位置采集后續的超聲切片。圖像采樣操作的順序反過來應該提供圖像切片數據,以便進行一個更適定、更容易配準的體對堆配準。 總之,這項工作提出了一個新的框架,該框架針對具有挑戰性的體對堆術中配準任務,優化了以下兩個方面的序列:a)超聲圖像堆的采樣位置;b)空間變化的變形正則化。 由于配準任務在相應特征方面的稀疏性以及在超聲成像方向和深度方面的依賴性,它也是一個部分到整體的配準。值得強調的是,我們提出的涉及配準和定位的工作,與同時定位與地圖構建(SLAM)文獻中的方法(施塔赫尼斯等人,2016年;朱利爾和厄爾曼,2001年;戴維森,2003年;薩拉斯-莫雷諾等人,2013年)之間存在相似性。在這項工作中,相對于參考解剖標志對超聲探頭進行定位和可視化(可選擇作為術中的視覺輔助,在體部CT中可識別),可以被視為SLAM公式中的地圖構建部分。這里沒有進一步形式化SLAM算法的這個觀點,但在可能的情況下采用了一致的符號表示。 我們提出了一個引導式術中圖像采集框架,用于采集適合與術前CT進行配準的超聲掃描圖像。與之前的工作通常是指對已經采集的圖像進行微調配準的引導(鮑姆等人,2022年;樸等人,2022年)不同,我們的工作是引導圖像采集到能夠提高配準性能的區域。此外,為了實現這個新穎的應用,我們從超網絡中推導出了強大的獎勵信號,這使得能夠根據任務性能對強化學習控制器進行訓練,而這是強化學習中一個尚未充分探索的領域。 總的貢獻總結如下: (1)我們制定了一種新的交互式體對堆配準算法,用于順序采集的超聲切片堆與術前CT之間的配準。 (2)我們提出了一種基于超網絡的配準模型,該模型可以在不同區域進行泛化,并且在測試時可以針對三個條件變量進行自適應調整,即一個控制變形正則化的參數、一個堆長度參數以及一個指示堆起始位置的參數(詳見第2.1節); (3)我們提出了一種基于強化學習的優化方法,用于在測試時估計這些條件變量,以引導用于配準目的的超聲堆采集; (4)我們使用從接受腹腔鏡肝臟分期和切除術的患者的CT掃描中獲得的臨床術前數據以及模擬的術中超聲數據,對我們提出的框架進行了評估,并將其與文獻中常見的其他配準方法進行了比較。 在第3節中,我們認為使用模擬的術中數據為驗證手術中的可變形模型提供了實際可行的真實數據,而目前使用真實臨床數據無法做到這一點。由于手術應用的性質和所提出的引導式采集,它也作為支持進一步交互式數據采集的必要初步實驗證據。此外,使用模擬的術中數據還使我們能夠報告一些有意義的驗證指標,例如術中圖像和術前圖像中相應標志點的目標配準誤差,而這在真實的術中數據上可能是無法實現的。在模擬環境中,使用模擬的術中數據以及基于先前工作的誤差估計進行的全局對齊,使我們能夠展示一個新穎的圖像采集引導框架,以引導采集從而實現更好的配準。
Abatract
摘要
We propose a guided registration method for spatially aligning a fixed preoperative image and untrackedultrasound image slices. We exploit the unique interactive and spatially heterogeneous nature of thisapplication to develop a registration algorithm that interactively suggests and acquires ultrasound imagesat optimised locations (with respect to registration performance). Our framework is based on two trainablefunctions: (1) a deep hyper-network-based registration function, which is generalisable over varying locationand deformation, and adaptable at test-time; (2) a reinforcement learning function for producing test-timeestimates of image acquisition locations and adapted deformation regularisation (the latter is required dueto varying acquisition locations). We evaluate our proposed method with real preoperative patient data, andsimulated intraoperative data with variable field-of-view. In addition to simulation of intraoperative data, wesimulate global alignment based on previous work for efficient training, and investigate probe-level guidancetowards an improved deformable registration. The evaluation in a simulated environment shows statisticallysignificant improvements in overall registration performance across a variety of metrics for our proposedmethod, compared to registration without acquisition guidance or adaptable deformation regularisation, andto commonly used classical iterative methods and learning-based registration. For the first time, efficacy ofproactive image acquisition is demonstrated in a simulated surgical interventional registration, in contrastto most existing work addressing registration post-data-acquisition, one of the reasons we argue may haveled to previously under-constrained nonrigid registration in such applications.
我們提出了一種引導式配準方法,用于對固定的術前圖像和未跟蹤的超聲圖像切片進行空間對齊。我們利用該應用獨特的交互性和空間異質性,開發了一種配準算法,該算法能夠交互式地建議并在優化位置(從配準性能角度考慮)采集超聲圖像。 我們的框架基于兩個可訓練的函數:(1)一個基于深度超網絡的配準函數,它能在不同的位置和變形情況下具有泛化能力,并且在測試階段具有適應性;(2)一個強化學習函數,用于在測試階段估計圖像采集位置,并對變形正則化進行調整(由于采集位置不同,需要進行后者的調整)。 我們使用真實的患者術前數據以及具有可變視野的模擬術中數據對所提出的方法進行評估。除了模擬術中數據外,為了進行高效訓練,我們還基于以往的工作模擬了全局對齊,并研究了能實現更優可變形配準的探頭級引導。 在模擬環境中的評估顯示,與沒有采集引導或可調整變形正則化的配準方法相比,以及與常用的經典迭代方法和基于學習的配準方法相比,我們提出的方法在各種指標上的整體配準性能有了統計學上的顯著提升。與大多數現有工作著眼于數據采集后的配準不同,我們首次在模擬的手術介入配準中證明了主動式圖像采集的有效性。我們認為,這可能是此類應用中以往非剛性配準約束不足的原因之一。
Method
方法
The proposed guidance framework relies on two functions: (1) ahyper-network-based registration function to allow adaptive registration; and (2) a reinforcement learning function to guide the operatortowards regions that aid registration. The hyper-network based registration function allows varying conditioning variables at test-timei.e., varying stack length or regularisation weight and can accommodate different sampling locations within the liver. These conditioningvariables and sampling locations are suggested by the reinforcementlearning function, at test-time. The reinforcement learning functionmay be trained using a reward signal derived only from the performance gain/loss of the registration network subsequent to eachsuggestion. Once trained, the RL function guides the operator in termsof the conditioning variables (including a prescribed stack length,regularisation weight and sampling location) towards an optimal registration and the hyper-network based registration function provides theregistration using these conditioning variables.
所提出的引導框架依賴于兩個函數:(1)一個基于超網絡的配準函數,用于實現自適應配準;(2)一個強化學習函數,用于引導操作人員前往有助于配準的區域。 基于超網絡的配準函數允許在測試時改變條件變量,也就是說,可以改變圖像堆長度或正則化權重,并且能夠適應肝臟內不同的采樣位置。在測試時,這些條件變量和采樣位置是由強化學習函數給出建議的。 強化學習函數可以使用僅從每次建議之后配準網絡的性能提升/下降情況中得出的獎勵信號來進行訓練。一旦訓練完成,強化學習函數就會根據條件變量(包括規定的圖像堆長度、正則化權重和采樣位置)引導操作人員實現最優配準,而基于超網絡的配準函數則利用這些條件變量來進行配準。
Conclusion
結論
In this work we propose a flexible guided nonrigid registrationframework based on two functions central to the framework. Thefirst is a hyper-network-based registration function, which is adaptableat test-time with respect to registration parameters. The second isa reinforcement learning function which learns to estimate optimalregistration parameter settings as well as sampling locations to improve nonrigid registration performance for a common preoperativeto intraoperative registration task, stack-to-volume registration. Theguidance in terms of sampling location for intraoperative imaging andthe settings for registration parameters, which control the image acquisition as well as registration, allows for a nonrigid registration to beobtained which leads to lower error compared to counterparts withoutthese components for the tested application of liver ultrasound to CTregistration. We have demonstrated the applicability of the proposedapproach using real preoperative CT data and simulated intraoperativeUS data from patients undergoing laparoscopic liver surgery, and haveshown meaningful performance improvements together with physicallyplausible registrations. Although, evaluated on simulated data, thiswork serves as a base for future work that can evaluate guidancetowards improved registration within realistic intraoperative settings,where interaction between the RL controller and data acquisition areconsidered.
在這項工作中,我們提出了一個靈活的引導式非剛性配準框架,該框架基于兩個核心函數。第一個是基于超網絡的配準函數,它在測試時能夠針對配準參數進行自適應調整。第二個是強化學習函數,該函數學習估計最優的配準參數設置以及采樣位置,以便在常見的術前到術中配準任務(即堆到體配準)中提高非剛性配準性能。 關于術中成像的采樣位置的引導,以及控制圖像采集和配準的配準參數設置,使得能夠實現一種非剛性配準。與在測試的肝臟超聲與CT配準應用中沒有這些組件的方法相比,這種配準產生的誤差更低。 我們使用真實的術前CT數據以及來自接受腹腔鏡肝臟手術患者的模擬術中超聲數據,證明了所提出方法的適用性,并且展示了有意義的性能提升以及符合物理實際的配準結果。盡管是在模擬數據上進行評估,但這項工作為未來的研究奠定了基礎。未來的研究可以在現實的術中場景中評估能夠改善配準的引導方法,并且會考慮強化學習控制器與數據采集之間的相互作用。
Results
結果
4.1. Registration performance
For evaluating the registration function, we turn the reader’s attention to the top block of results presented in Table 1. When comparingthe hypernet, with fixed optimal registration parameter values over theentire set, to a non-hypernet registration network or to an empiricallyconfigured iterative registration, we expect little difference betweenthe two for supporting a test-time optimisable alternative withoutcompromising registration capability. Indeed, as detailed in Table 1,statistical significance was not observed for all tested metrics (p-values* 0.050 for all), except for the GDM metric for comparison with theiterative registration variant (p-values = 0.008 and 0.006 for the twocomparisons). The standard deviation of the Jacobian determinant wasbetween 0.58-1.97 (95th percentile). For comparisons to DRAMMSand DEEDS, while some metrics are improved compared to the hypernet approach, these improvements are within the margin of error.Moreover, DEEDs or DRAMMs would require substantial modificationswithin our hypernet-based guidance framework, which allows test-timeadaptation of conditioning variables. Note that these methods requiregeometrically reconstructed images on a regular grid, with substantialoverlapping common anatomical features already present, which makestheir use in our application challenging and uncommon within currentliterature. Thus, we use our hypernet approach in subsequent experiments. It should also be noted that image-only registration networkstill manages to substantially reduce registration error compared toun-registered cases. We use the best-performing hypernet approach forsubsequent experiments.
4.1 配準性能 為了評估配準函數,我們請讀者關注表1頂部的結果模塊。當將在整個數據集上具有固定最優配準參數值的超網絡,與非超網絡配準網絡或經驗配置的迭代配準進行比較時,我們期望在不影響配準能力的前提下,為測試時可優化的替代方案提供支持,且這兩者之間差異不大。事實上,如表1中詳細所示,除了在與迭代配準變體進行比較時的廣義距離度量(GDM)指標(兩次比較的p值分別為0.008和0.006)外,對于所有測試指標均未觀察到統計學上的顯著差異(所有指標的p值均大于0.050)。雅可比行列式的標準差在0.58到1.97之間(第95百分位數)。 在與DRAMMS和DEEDS方法進行比較時,雖然某些指標相比超網絡方法有所改善,但這些改善都在誤差范圍內。此外,DEEDS或DRAMMS方法若要應用于我們基于超網絡的引導框架中,需要進行大量修改,而我們的框架允許在測試時對條件變量進行自適應調整。請注意,這些方法需要在規則網格上對幾何重建的圖像進行處理,且已經存在大量重疊的常見解剖特征,這使得它們在我們的應用中使用起來具有挑戰性,并且在當前文獻中也不常見。 因此,我們在后續實驗中采用超網絡方法。還應注意的是,與未配準的情況相比,僅基于圖像的配準網絡仍然能夠大幅降低配準誤差。在后續實驗中,我們使用性能最佳的超網絡方法。
Figure
圖
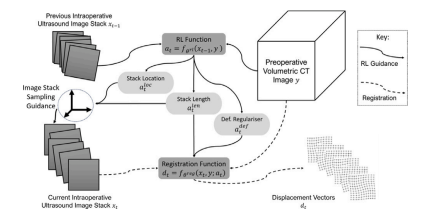
Fig. 1. An overview of the proposed registration and guidance scheme being usedintraoperatively. The guided image stack sampling is the effector 𝑒 described inSection 2.3.1. The transformations between slices as well as between slices and thepreoperative volume for this challenging volume-to-stack registration, are unknown
圖1:所提出的術中使用的配準和引導方案概述。引導式圖像堆采樣是第2.3.1節中描述的執行器e。對于這個具有挑戰性的體對堆配準而言,切片之間以及切片與術前體部圖像之間的變換都是未知的。
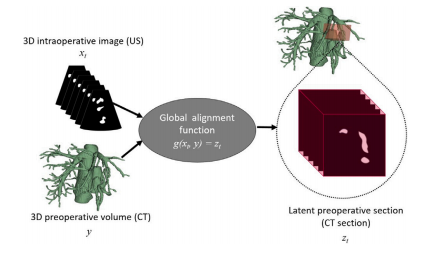
Fig. 2. An overview of the global alignment function, which has been simulated inthis work based on errors reported in previous works (Ramalhinho et al., 2022, 2020).Grey: non-parametric fixed function; Dotted bubble: expanded visualisation.
圖2:全局對齊函數的概述,在這項工作中,該函數是基于先前研究(拉馬利尼奧等人,2022年、2020年)中所報告的誤差情況進行模擬的。灰色部分:非參數固定函數;帶點氣泡:展開后的可視化展示。
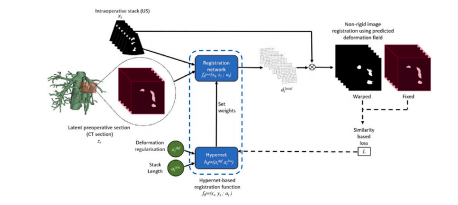
Fig. 3. Hypernet based registration network. Blue: parametric trainable function; Bluedashed bubble: combination of functions; Dotted bubble: expanded visualisation; Green:variables; Dashed line: used for function training. The hypernet re-parameterises theweights of the registration network based on the input conditioning variables, thisweight-modification adapts the registration network to represent the new conditioningvariable setting
圖3:基于超網絡的配準網絡。藍色:參數化的可訓練函數;藍色虛線氣泡:函數組合;帶點氣泡:展開的可視化;綠色:變量;虛線:用于函數訓練。超網絡根據輸入的條件變量對配準網絡的權重進行重新參數化,這種權重調整使配準網絡能夠適應新的條件變量設置。
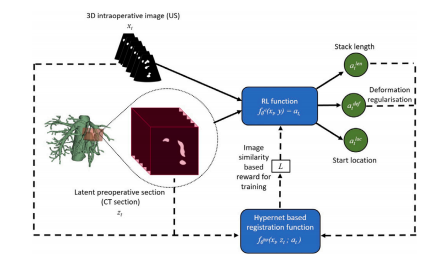
Fig. 4. Reinforcement learning function. Blue: parametric trainable function; Dottedbubble: expanded visualisation; Green: variables; Dashed lines: used for functiontraining. The RL function suggests conditioning variable settings that guide the operatortowards an optimal registration. The function is trained using a reward signal derivedfrom the registration network, quantifying performance gains/losses subsequent to anyconditioning variables suggestions by the RL function.
圖4:強化學習函數。藍色:參數化的可訓練函數;帶點氣泡:展開的可視化展示;綠色:變量;虛線:用于函數訓練。強化學習函數會給出條件變量設置建議,引導操作人員實現最優配準。該函數使用從配準網絡導出的獎勵信號進行訓練,該獎勵信號用于量化強化學習函數給出的任何條件變量建議之后的性能提升或下降情況。?
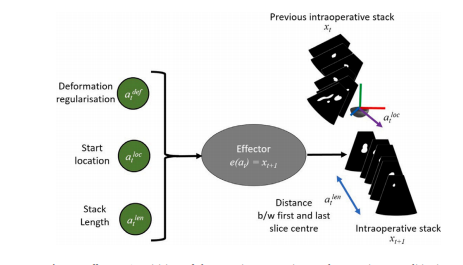
Fig. 5. Effector. Acquisition of the next intraoperative stack 𝑥𝑡+1, given conditioningvariables. Grey: non-parametric fixed function; Green: variables. The effector takes inthe guidance sampled from the RL function and uses it to acquire a new stack/sweepof US. This may be a human following the RL guidance intraoperatively, where theguidance is delivered to the human operator via a constructed map (see Section 2.4).
圖5:執行器。在給定條件變量的情況下,獲取下一個術中圖像堆𝑥𝑡+1。灰色:非參數固定函數;綠色:變量。執行器接收從強化學習函數中采樣得到的引導信息,并利用該信息獲取新的超聲圖像堆/掃描結果。這可能是術中由人按照強化學習給出的引導進行操作,引導信息會通過構建的地圖傳遞給操作人員(詳見第2.4節)。
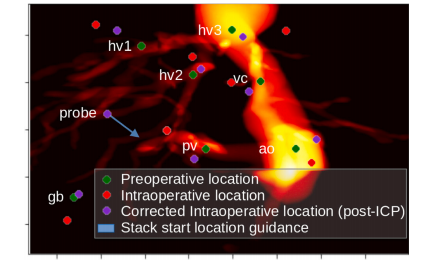
Fig. 6. A 2D point cloud map of landmarks constructed as an intraoperative aid(projected into 2D coronal view and overlaid onto a 2D projection of the preoperativevolume). Intraoperative points sampled using global alignment function and correctiondone as described in Section 2.4. hv: hepatic vein (1, 2, 3 corresponds to right, middleand left); pv: portal vein branching point; gb: gall bladder; ao: aorta; vc: vena cava.Sampling guidance arrow comprises of 𝑎**𝑡 and shows the direction and magnitude ofsuggested direction.
圖6:構建的作為術中輔助工具的二維地標點云圖(投影到二維冠狀視圖并疊加在術前體部圖像的二維投影上)。術中的點是使用全局對齊函數進行采樣,并按照第2.4節中所述進行校正。hv:肝靜脈(1、2、3分別對應右、中、左肝靜脈);pv:門靜脈分支點;gb:膽囊;ao:主動脈;vc:下腔靜脈。采樣引導箭頭由𝑎𝑡組成,顯示了建議方向的方向和大小。
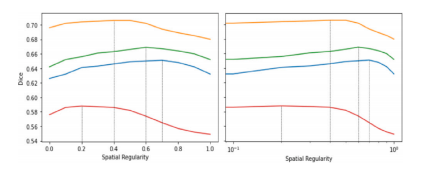
Fig. 7. Effect of varying 𝑎 𝑑𝑒𝑓 𝑡 , the spatial regularity of deformation at various startinglocations 𝑎 𝑙𝑜𝑐 𝑡 . Left: Linear scale; Right: Logarithmic scale, where each colour is adifferent sampling location and dotted lines indicate optimal values.
圖7:在不同起始位置(a{loc}^t) 處,改變變形的空間正則化參數(a{def}^t) 所產生的影響。 左側:線性刻度;右側:對數刻度,其中每種顏色代表一個不同的采樣位置,虛線表示最優值。 ?
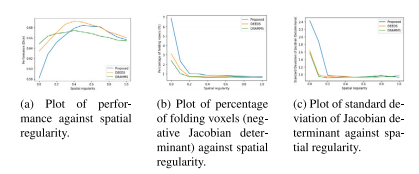
Fig. 8. Effect of 𝑎 𝑑𝑒𝑓 𝑡 , the spatial regularity of deformation, averaged over 1000locations
圖8:變形的空間正則化參數(a_{def}^t)的影響,該影響是在1000個位置上取平均值得到的。
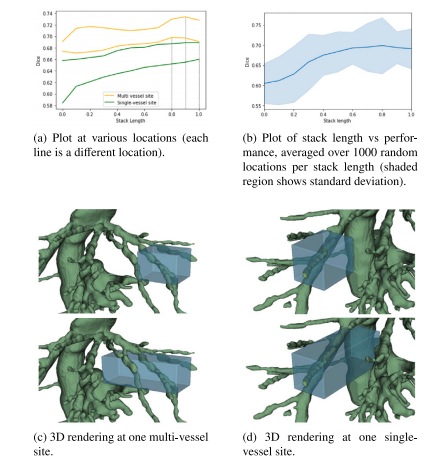
Fig. 9. Effect of varying stack length at various sampling locations
圖9. 在不同采樣位置改變堆疊長度所產生的影響

Fig. 10. Registration performance (DSC) overlaid onto a patient volume with fixedstack length and spatial regularity of deformation. Each column showing a differentview for the same patient (legend on the top-left represents the view presented).
圖10:在固定圖像堆長度和變形空間正則性的情況下,配準性能(DSC,即 Dice 相似系數)疊加顯示在患者的體部圖像上。每一列展示了同一位患者的不同視角(左上角的圖例表示所展示的視角)。

Fig. 11. Registration results presented for 2D slices. Top: latent slice from CTsection (obtained from global alignment), 2nd row: slice from warped US sweep(warped using hypernet-based registration function-predicted deformation), 3rd row:flow field showing warps, Bottom: slice from un-warped US sweep. Slices sampledusing Ramalhinho et al. (2023)
圖11:二維切片的配準結果展示。 頂部:來自CT斷層的潛在切片(通過全局對齊獲得);第二行:來自經過變形的超聲掃描的切片(使用基于超網絡的配準函數預測的變形進行變形處理);第三行:顯示變形情況的流場;底部:來自未變形的超聲掃描的切片。這些切片是根據拉馬利尼奧等人(2023年)的方法采樣得到的。
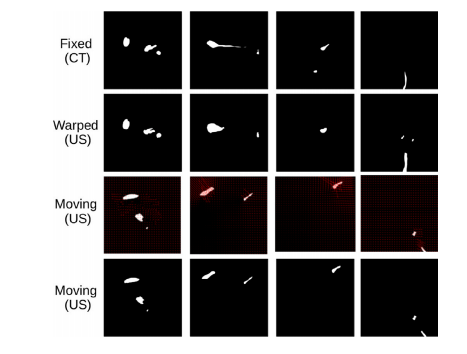
Fig. 12. Registration results presented for equally spaced 2D slices from a single3D volume. Top: latent slice from CT section (obtained from global alignment),2nd row: slice from warped US sweep (warped using hypernet-based registrationfunction-predicted deformation), 3rd row: flow field showing warps, Bottom: slice fromun-warped US sweep. Slices sampled using Ramalhinho et al. (2023).
圖12:從單個三維體數據中等間距二維切片的配準結果展示。頂部:來自CT斷層的潛在切片(通過全局對齊獲得);第二行:來自經變形的超聲掃描的切片(利用基于超網絡的配準函數所預測的變形進行變形處理);第三行:顯示變形情況的流場;底部:來自未變形的超聲掃描的切片。這些切片是依據拉馬利尼奧等人(2023年)的方法進行采樣的。
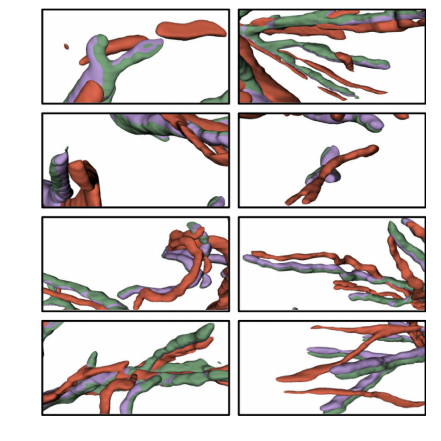
Fig. 13. Registration results presented in 3D using interpolation of ultrasound frames.Red: Sampled US (moving image), Green: latent CT section (obtained from globalalignment) (fixed image), Purple: Warped US (warped moving image)
圖13:通過對超聲幀進行插值后以三維形式呈現的配準結果。紅色:采樣的超聲圖像(浮動圖像),綠色:潛在的CT斷層圖像(通過全局對齊獲得)(固定圖像),紫色:變形后的超聲圖像(已變形的浮動圖像)。
Table
表
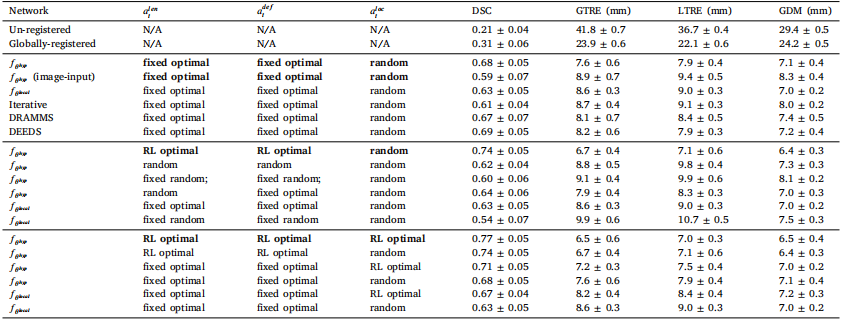
Table 1Table of results on the holdout set. The conditioning variable settings are: ‘fixed optimal’: fixed for the entire holdout set and optimal selected by averaging over the wholeset; ‘fixed random’: fixed for the entire holdout set and randomly selected from an empirically defined range; ‘random’: randomly selected per acquired intraoperative stack; ‘RLoptimal’: optimal selected by RL function per acquired intraoperative stack. The networ
表1 ?留存數據集上的結果表。條件變量設置如下:“固定最優值”:在整個留存數據集上固定不變,且為通過對整個數據集求平均后選取的最優值;“固定隨機值”:在整個留存數據集上固定不變,且從經驗定義的范圍內隨機選取;“隨機值”:針對每次采集的術中圖像堆隨機選取;“強化學習(RL)最優值”:由強化學習函數針對每次采集的術中圖像堆選取的最優值。
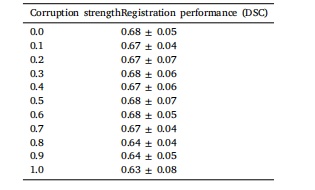
Table 2Impact of segmentation noise on registration performance. The registration model used was 𝑓𝜃*hyp from thefirst row of Table 1.
表2 ?分割噪聲對配準性能的影響。所使用的配準模型是表1第一行中的\(f_{\theta}^{hyp}\) 。?
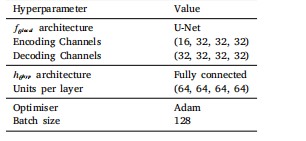
Table 3Hyperparameters for 𝑓𝜃 ?𝑦𝑝
表3 (f_{\theta}^{hyp})的超參數
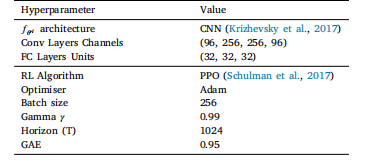
Table 4Hyperparameters for 𝑓𝜃 𝑟𝑙 .
表4 (f_{\theta}^{rl}) 的超參數。
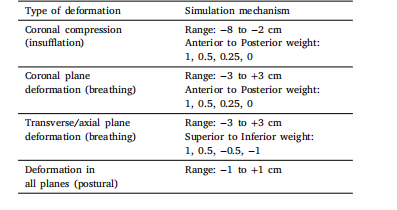
表A.5. Using the proposed framework to guide intraoperative prostate registration
表A.5. 使用所提出的框架來引導術中前列腺配準

Table 6Results on, the holdout set, comparing performance for a task of guided prostate USto MR non-rigid registration. The conditioning variable settings are: ‘fixed optimal’:fixed for the entire holdout set and optimal selected by averaging over the wholeset; ‘fixed random’: fixed for the entire holdout set and randomly selected from anempirically defined range; ‘random’: randomly selected per acquired intraoperativestack; ‘RL optimal’: optimal selected by RL function per acquired intraoperative stack.
表6 在留存數據集上的結果,對比了引導式前列腺超聲與磁共振(MR)非剛性配準任務的性能。條件變量設置如下:“固定最優值”:在整個留存數據集上保持固定,且為通過對整個數據集取平均值后選定的最優值;“固定隨機值”:在整個留存數據集上保持固定,且是從經驗定義的范圍內隨機選取的;“隨機值”:針對每次采集的術中圖像堆隨機選取;“強化學習(RL)最優值”:由強化學習函數針對每次采集的術中圖像堆選取的最優值。












)

)




