Flex.2-preview 文本生成圖像擴散模型介紹
一、模型簡介
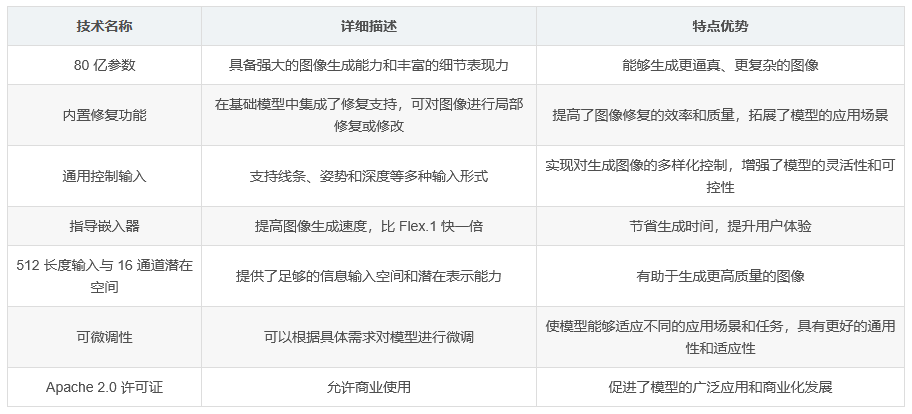
Flex.2-preview 是一種 開源的 80 億參數文本生成圖像擴散模型,具備通用控制和修復支持功能,是 Flex.1alpha 的下一代版本。該模型由社區開發并為社區服務,采用 Apache 2.0 許可證,允許商業使用。它具有 512 長度的輸入、16 通道潛在空間,且可微調。
二、功能特性
-
內置修復功能 :在基礎模型中集成了修復支持,能夠對圖像進行局部修復或修改。
-
通用控制輸入 :支持多種輸入形式,如線條、姿勢和深度信息,實現對生成圖像的多樣化控制。
-
高效性 :具有指導嵌入器,使得圖像生成速度比 Flex.1 提高了一倍。
三、使用方法
ComfyUI 環境
-
安裝 Flex2 Conditioner 節點和 comfyui_controlnet_aux 工具,用于生成控制圖像(姿勢和深度)等。
-
下載 Flex.2-preview.safetensors 模型文件,并放置在 ComfyUI/models/diffusion_models 文件夾下,重啟 ComfyUI。
-
使用預設的工作流程示例來開始控制和修復操作。
Diffusers 環境
-
安裝所需的庫,包括 torch、accelerate、transformers 和 diffusers。
-
導入必要的模塊,如 AutoPipelineForText2Image 和 load_image 等。
-
通過加載 Flex.2-preview 模型,并指定相關參數(如輸入圖像、掩碼、控制圖像等)來生成圖像。
四、技術細節
-
Flex.2 的開發過程經歷了 Flux.1 Schnell、OpenFlux.1、Flex.1-alpha 等階段,每一次迭代都有所進步,而 Flex.2 是目前最大的進步。
-
在控制和修復的訓練方面比較激進,模型在一些方面(如解剖結構和文本)上存在困難,修復功能也在持續改進中。
-
Flex.2 設計為可微調,盡管實踐尚處于實驗階段。可以直接在能夠進行控制和修復的模型上訓練傳統的 LoRAs,Flex.1-alpha 的 LoRAs 也通常能很好地與之配合。
五、局限性與改進
-
局限性
-
模型在處理解剖結構和文本方面存在一定的困難。
-
修復功能仍在完善中,尚未達到理想效果。
-
-
改進措施
-
開發者正通過每次新的訓練運行來改進這些限制。
-
支持通過訓練簡單的 LoRA 來讓模型使用自定義控制。
-
六、未來展望
開發者鼓勵用戶反饋模型的使用體驗,提出改進建議和新功能需求。同時,他們也在探索最佳實踐,以推動 Flex.2-preview 模型的進一步發展和優化。
Flex.2-preview 核心技術匯總表





訪問FPGA的專用SPI接口)





)




)
)

