一、大模型概述
1、大模型概念
LLM是指用有大量參數的大型預訓練語言模型,在解決各種自然語言處理任務方面表現出強大的能力,甚至可以展現出一些小規模語言模型所不具備的特殊能力
2、語言模型language model
語言建模旨在對詞序列的生成概率進行建模,以預測未來tokens的概率,語言模型的發展:
1)統計語言模型SLM:?統計語言模型使用馬爾可夫假設(Markov Assumption)來建立語言序列的預測模型,通常是根據詞序列中若干個連續的上下文單詞來預測下一個詞的出現概率,經典的例子是n-gram模型,在此模型中一個詞出現的概率只依賴于前面的n-1個詞,比如一個3gram模型只考慮前兩個詞對第三個詞出現概率的影響
2)神經語言模型NLM:使用神經網絡來預測詞序列的概率分布,如RNN包括LSTM和GRU等變體,這樣NLM就可以考慮更長的上下文或整個句子的信息,而傳統的統計語言模型使用固定窗口大小的詞來預測;在該模型中引入分布式詞表示,每個單詞被編碼為實數值向量,即詞嵌入(word embeddings)用來捕捉詞與詞之間的語法關系
3)預訓練語言模型PLM: PLM開始在規模無標簽語料庫上進行預訓練任務,學習語言規律知識,并且針對特定任務進行微調(fine-tuning)來適應不同應用場景;而對于大規模的長文本,谷歌提出了transformer--通過自注意力機制(self- attention)和高度并行化能力,可以在處理序列數據時捕捉全局依賴關系,極大提高序列處理任務的效率
4)大語言模型LLM: 當一些研究工作嘗試訓練更大的預 訓練語言模型(例如 175B 參數的 GPT-3 和 540B 參數的 PaLM)來探索擴展語言 模型所帶來的性能極限。這些大規模的預訓練語言模型在解決復雜任務時表現出 了與小型預訓練語言模型(如 330M 參數的 BERT 和 1.5B 參數的 GPT2)不同 的行為,這種大模型具 有但小模型不具有的能力通常被稱為“涌現能力”(Emergent Abilities),這些大型的預訓練模型就是LLM

3、大模型特點?
1)參數數量龐大,數據需求巨大
2)計算資源密集
3)泛化能力強
4)遷移學習效果佳
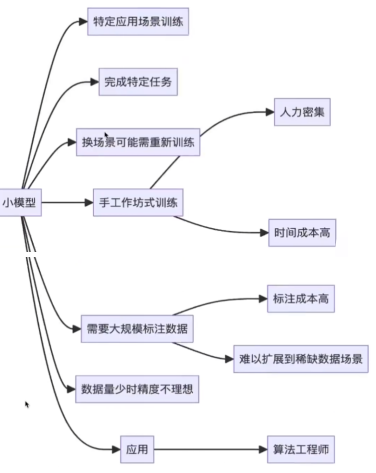
4、小模型vs大模型
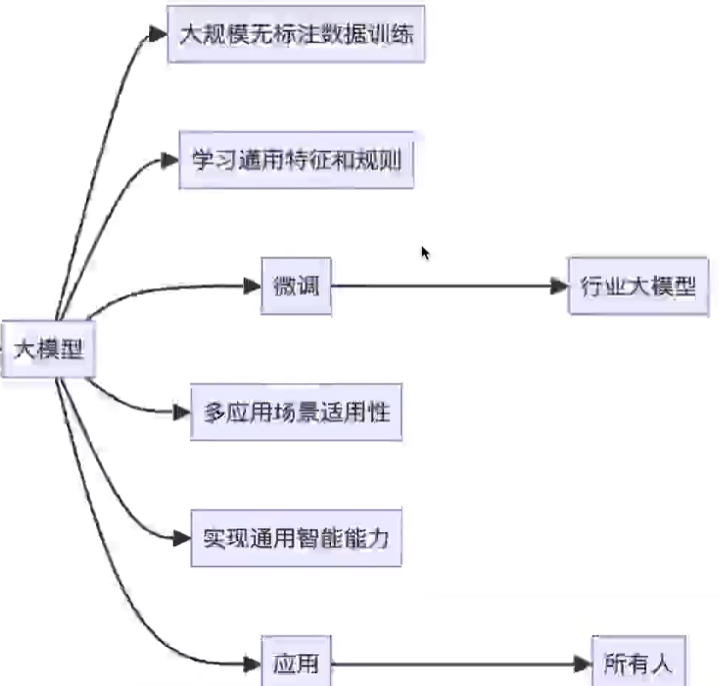
5、大模型企業應用
1)通用大模型

2)行業大模型
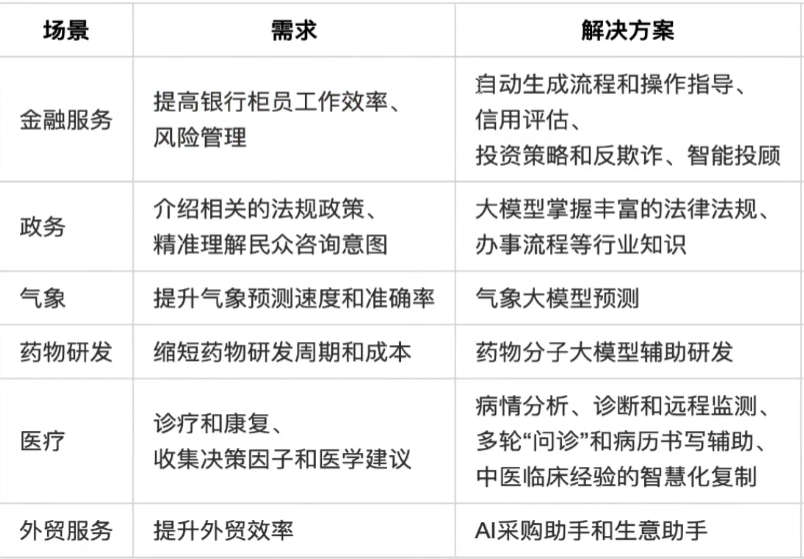
3)產業大模型
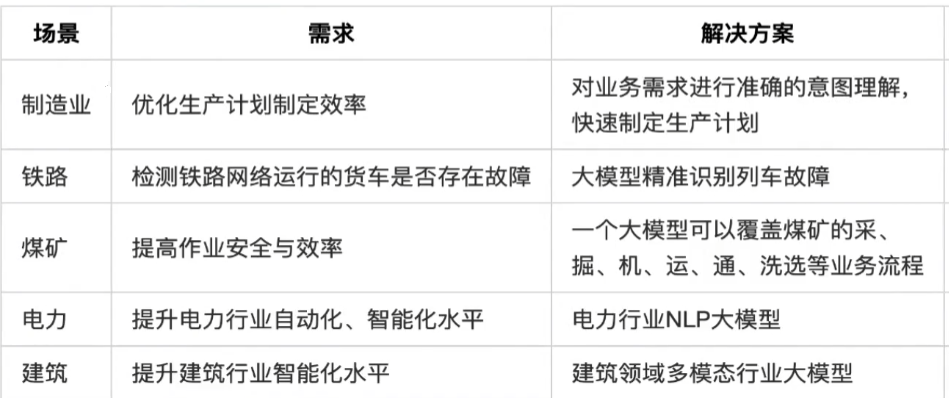
二、大模型基礎
1、大模型構建過程
1)大規模預訓練 (Large-Scale Pre-training)
| 目標 | 為模型參數找到好的“初值點”,使其編碼世界知識,具備通用的語言理解和生成能力。可以看作是世界知識的壓縮。 |
| 方法? | 使用海量(當前普遍?2~3T tokens?規模,并有擴大趨勢)的無標注文本數據,通過自監督學習任務(當前主流是“預測下一個詞”)訓練解碼器架構 (Decoder Architecture)?模型。 |
| 關鍵要素? | 1.?數據:高質量、多源化數據的收集與嚴格清洗至關重要,直接影響模型能力。? 2.?算力:需求極高(百億模型需數百卡,千億模型需數千甚至萬卡集群),訓練時間長。? 3.?技術與人才:涉及大量經驗性技術(數據配比、學習率調整、異常檢測等),高度依賴研發人員的經驗和能力。 |
2)指令微調與人類對齊 (Instruction Fine-tuning & Human Alignment)
| 動機? | 預訓練模型雖有知識,但不擅長直接按指令解決任務。需要進一步訓練以適應人類的使用方式和價值觀。 |
| 指令微調? | 目標:使模型學會通過問答形式解決任務。? 方法:使用“任務輸入-輸出”配對數據進行有監督的模仿學習 (Imitation Learning)。? 作用:主要在于激發模型在預訓練階段學到的能力,而非注入新知識。? 資源:所需數據量(數十萬到百萬級)和算力遠小于預訓練。 |
| ?人類對齊? | 目標:使模型行為符合人類的期望、需求和價值觀(如“有用、誠實、無害”)。? 主流方法:?RLHF?(基于人類反饋的強化學習)。? RLHF過程: 標注員對模型輸出進行偏好排序?-> 訓練獎勵模型 (Reward Model)?-> 使用強化學習根據獎勵模型優化語言模型。? 資源:通常比SFT消耗多,但遠小于預訓練。也在探索更簡化的對齊方法。 |
| 產出? | 一個能夠進行良好人機交互,能按指令解決問題,并且行為更符合人類期望的最終模型。 |
2、擴展法則
通過增大模型參數量、訓練數據量和計算量來提升模型能力,而且這種提升往往比改進模型架構或算法本身帶來的提升更顯著。?為了量化研究這種規模擴展帶來的性能提升,研究人員提出了擴展法則來研究規模擴展與模型性能(通常用損失函數 Loss 來衡量)的關系,可以幫助預測不同資源投入下的模型性能:
1)KM 擴展法則
建立模型性能與三個主要因素模型規模 N?(參數量)、數據規模 D?(token 數量)、計算算力 C?(通常指訓練期間的總計算量) 之間的冪律關系
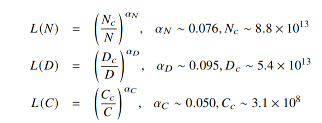
推論:為了達到最低的 Loss,增大模型規模 N 比增大訓練數據量 D 更有效。也就是說,分配更多計算資源給模型參數增長,帶來的收益更大。
2)Chinchilla 擴展法則
該法則認為?KM 法則可能低估了數據規模 D 的重要性。他們在給定計算預算 C 下,同時調整 N 和 D提出了新的擴展法則
![]()
推論:對于給定的計算預算 C,要達到最優性能(最低 Loss),模型規模 N 和數據規模 D 應該按比例同步擴展。他們的研究表明,最優的 N 和 D 大約與 C 的平方根 成正比,意味著計算預算應該大致平均分配給模型規模增長和數據規模增長
3)局限性
-
擴展法則主要預測的是預訓練損失 (Pre-training Loss),這與模型在具體下游任務上的表現、涌現能力(Emergent Abilities, 如推理、遵循復雜指令)以及對齊后(如 RLFH 后)的實際效果不完全等同。
-
模型性能是多維度的,Loss 只是其中一個指標。擴展法則難以預測模型是否“有用”、“誠實”、“無害”等對齊相關的特性。
-
存在逆向擴展現象 (Inverse Scaling):在某些特定任務或指標上,模型規模增大反而導致性能下降。
-
數據質量的影響難以簡單量化進 D 中,但對模型能力至關重要。
3、涌現能力
特征:特定任務的性能在模型規模達到某個閾值后,出現突然的、遠超隨機水平的性能躍升
1)上下文學習 (In-context Learning, ICL)
模型能根據提示中給出的少量任務示例(Demonstrations)來完成新任務,無需進行模型參數的更新(梯度下降)。
例子:?GPT-3 (175B) 展現出強大的ICL能力,而GPT-1/2則不具備。能力也與任務相關,例如13B的GPT-3在簡單算術上可以ICL,但175B在波斯語問答上效果不佳。
2)指令遵循 (Instruction Following):
模型能理解并執行自然語言指令來完成任務,即使沒有在提示中給出具體示例(零樣本泛化)。通常通過指令微調 (Instruction Tuning ),使用大量(任務指令,任務輸出)的數據對進行訓練。
例子:?FLAN-PaLM 在規模達到 62B 及以上時,才在復雜的 BBH 推理基準上展現出較好的零樣本能力。但較小模型(如 2B)用高質量數據微調也能掌握一定(尤其是簡單任務)指令遵循能力。
3)逐步推理 (Step-by-step Reasoning)
模型能解決需要多個推理步驟的復雜任務(如數學應用題),特別是利用思維鏈 (Chain-of-Thought, CoT)?提示策略時,即在提示中引導模型生成中間的推理步驟,從而得到更可靠的答案。
例子:?CoT 對 PaLM 的 62B 和 540B 模型在算術推理上有提升,但對 8B 模型效果不明顯,且在 540B 上提升更顯著。提升效果也因任務而異。








—— 共現詞矩陣及Python實現)




計算模型面試內容整理-拓撲排序(Topological Sort)和節點依賴與并行度)
)




