目錄
1 DistCp概述與應用場景
2 DistCp架構設計解析
2.1 系統架構圖
2.2 執行流程圖
3 DistCp核心技術原理
3.1 并行拷貝機制
3.2 斷點續傳實現原理
4 DistCp實戰指南
4.1 常用命令示例
4.2 性能優化策略
5 異常處理與監控
5.1 常見錯誤處理流程
5.2 監控指標建議
6 與替代方案對比
6.1 技術選型決策樹
7 總結
1 DistCp概述與應用場景
DistCp(Distributed Copy)是Hadoop生態系統中的 分布式數據拷貝工具,專為大規模數據跨集群/跨目錄遷移而設計。典型應用場景:
- 跨集群數據遷移(如Hadoop版本升級)
- 生產環境到測試環境的數據同步
- 冷熱數據分離存儲
- 數據備份與災備
2 DistCp架構設計解析
2.1 系統架構圖
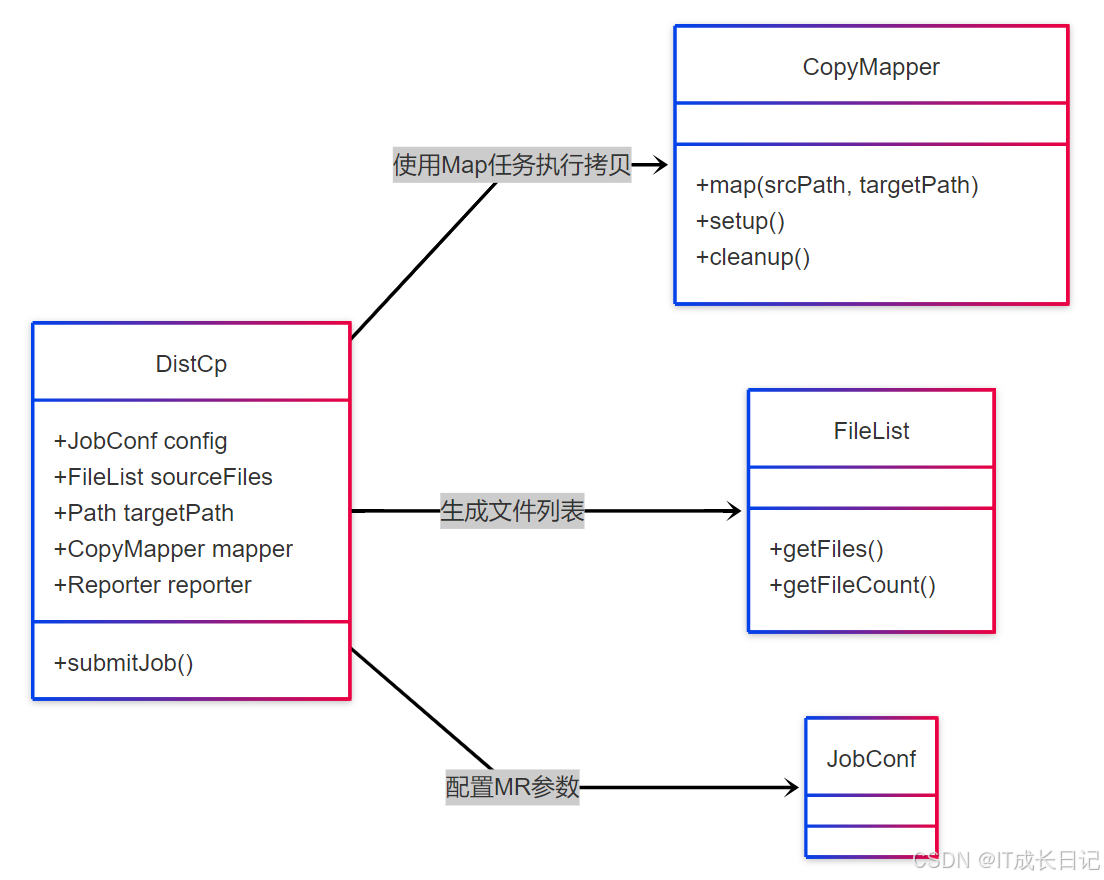
組件職責說明:
- DistCp:主控制類,負責參數解析和作業提交
- CopyMapper:實際執行文件拷貝的Map任務
- FileList:維護待拷貝文件的清單
- JobConf:配置MapReduce作業參數
2.2 執行流程圖

流程關鍵點:
- 列表構建階段:遞歸掃描源路徑生成文件清單
- 分片策略:默認每10個文件一個分片(可配置)
- 校驗階段:通過對比源和目標文件的CRC32確保一致性
3 DistCp核心技術原理
3.1 并行拷貝機制

并行化實現:
- 每個Map任務處理一個文件分片
- 默認并行度=min(文件數/10, 集群slot數)
- 支持通過-m參數手動設置Mapper數量
3.2 斷點續傳實現原理
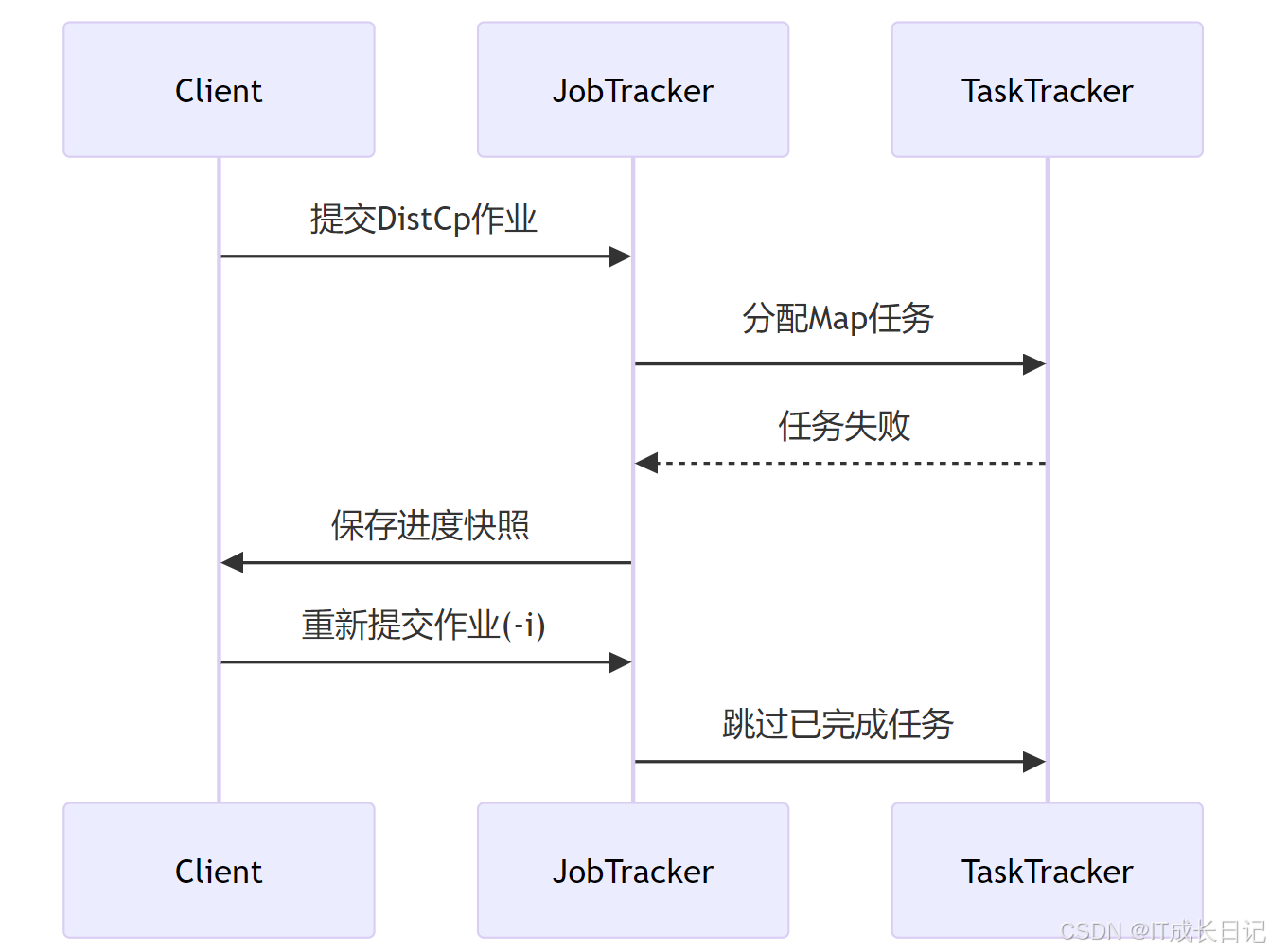
關鍵參數:
- -i:忽略失敗任務
- -update:只拷貝新增/修改文件
- -append:追加寫入目標文件
4 DistCp實戰指南
4.1 常用命令示例
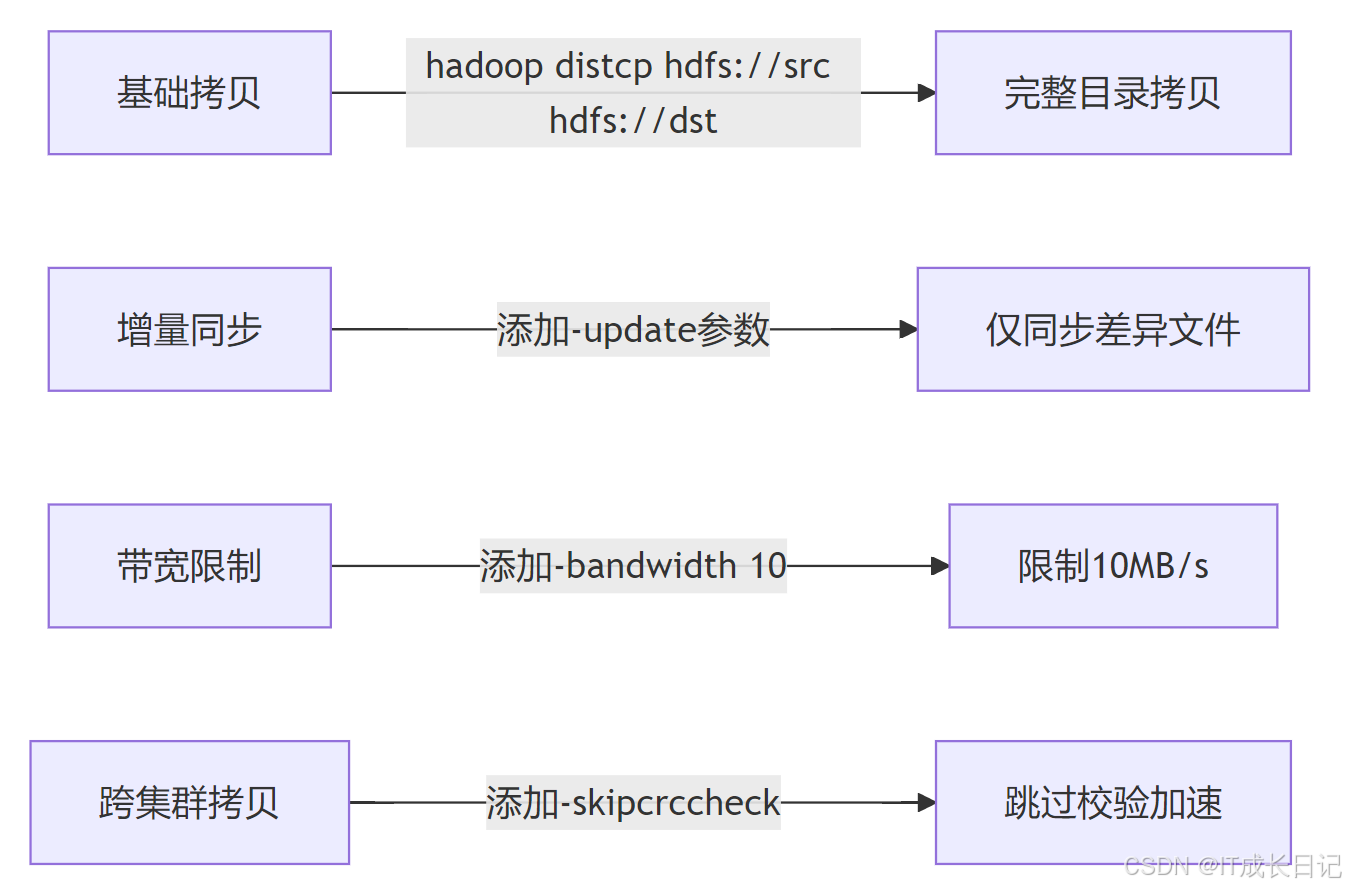
- 參數優化建議
# 示例
hadoop distcp \-Ddfs.client.socket-timeout=240000 \-Ddfs.datanode.socket.write.timeout=720000 \-bandwidth 50 \ # 限制帶寬50MB/s-m 100 \ # 設置100個Mapper-update \ # 增量模式-strategy dynamic \ # 動態分片hdfs://cluster1/data \hdfs://cluster2/data4.2 性能優化策略
調優策略:
- Mapper數量:建議為集群slot數的2-3倍
- 帶寬限制:避免影響生產業務
- 分片策略:小文件多用動態分片
5 異常處理與監控
5.1 常見錯誤處理流程
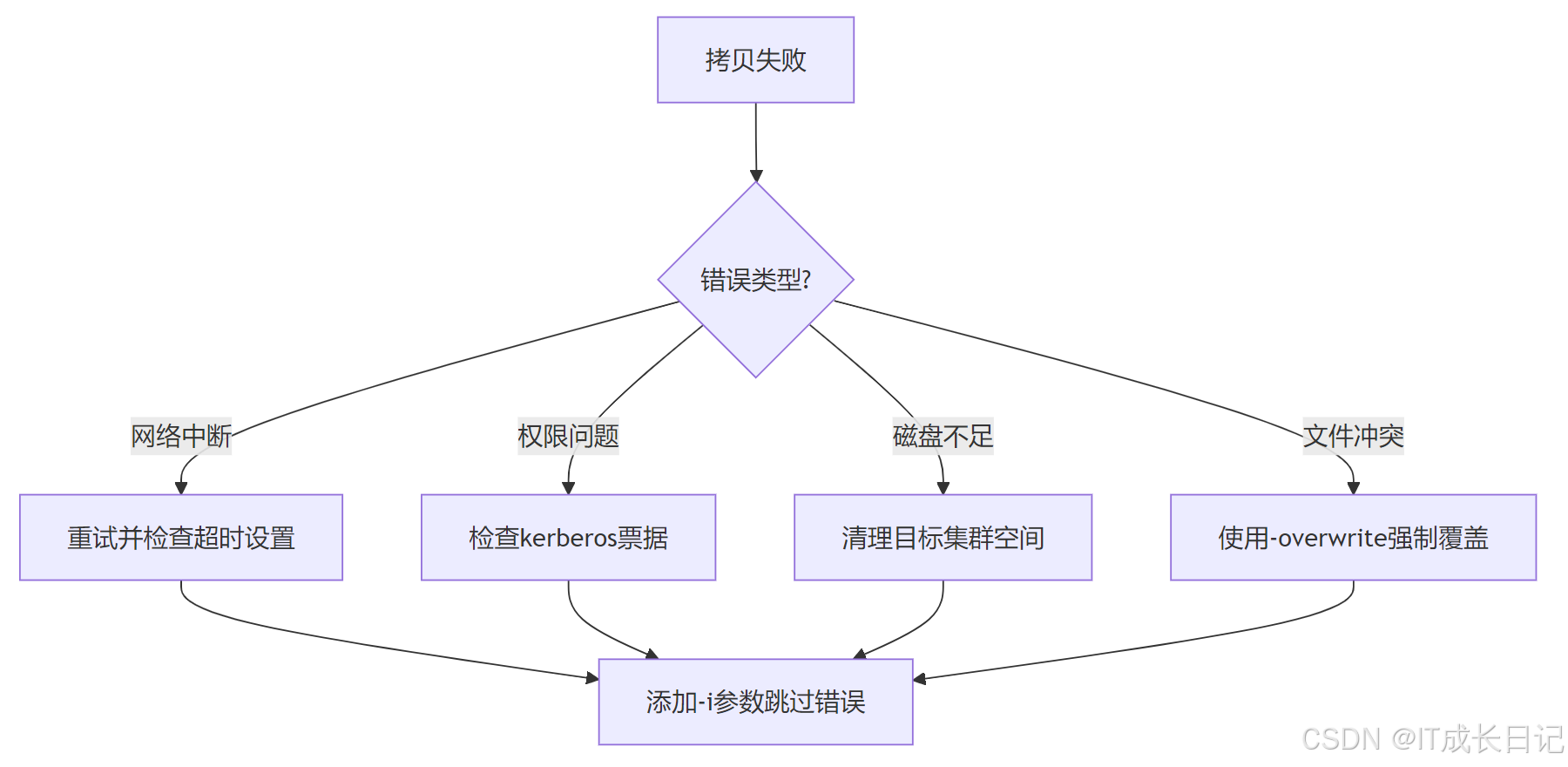
5.2 監控指標建議
監控建議:
- 通過hadoop job -history查看歷史作業
- 監控HDFS寫入速率和集群負載
- 記錄每次拷貝的吞吐量和文件數
6 與替代方案對比
6.1 技術選型決策樹
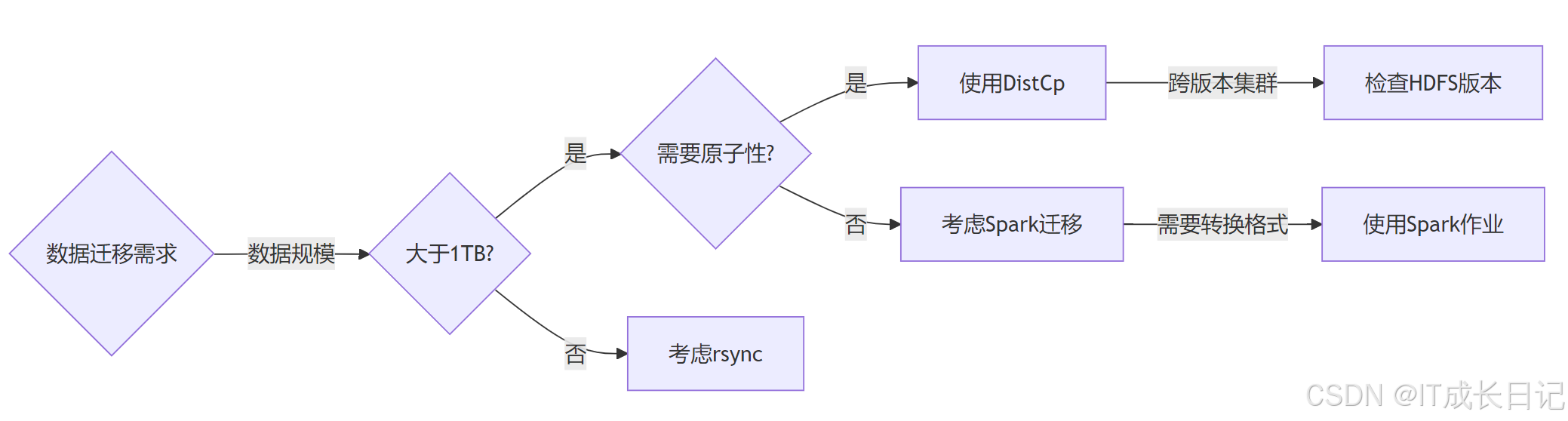
- 方案對比表
| 工具 | 優勢 | 局限性 |
| DistCp | 原生支持、處理海量數據 | 缺乏實時同步能力 |
| Spark | 支持數據轉換 | 需要開發代碼 |
| Rsync | 增量同步精確 | 單節點瓶頸 |
| HDFS NFS | 掛載即用 | 性能較差 |
7 總結
在實際生產環境中,建議先在小規模數據上驗證參數配置,再執行全量遷移。對于PB級數據遷移,可采用分批次執行的策略,同時密切關注集群負載情況。







家族發展史及版本對比)



:水滸傳捕魚模塊邏輯與服務器幀同步詳解)



架構?它如何提升模型效率?)



![[SpringBoot]快速入門搭建springboot](http://pic.xiahunao.cn/[SpringBoot]快速入門搭建springboot)