1. 引言:CPU虛擬化的核心問題
讓多個進程看似同時運行在一個物理CPU上。核心思想是時分共享 (time sharing) CPU。為了實現高效且可控的時分共享,本章介紹了一種關鍵機制,稱為受限直接執行 (Limited Direct Execution, LDE)。
1.1 LDE的基本思想
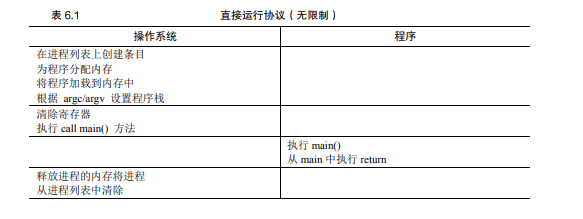
- 直接執行 (Direct Execution): 為了性能,讓用戶程序盡可能直接在硬件CPU上運行。
- 受限 (Limited): 操作系統必須施加限制,以確保它能保持對系統的控制權,并且用戶程序不能執行危險或非授權的操作。
1.2 問題推導

LDE協議有兩個階段:
- 第一階段(在系統引導時):內核初始化陷阱表,并且CPU記住它的位置以供隨后使用。內核通過特權指令來執行此操作。
- 第二階段(運行進程時):在使用從陷阱返回指令開始執行進程之前,內核設置了一些內容(例如,在進程列表中分配一個節點,分配內存)。這會將CPU切換到用戶模式并開始運行該進程。
2. 問題1:如何執行受限制的操作?
2.1 背景
直接執行時,如果進程需要執行I/O等特權操作怎么辦?不能讓用戶進程隨意操作硬件。
2.2 解決方案:引入特權級別 (Processor Modes)
- 用戶模式 (User Mode): 運行用戶程序,權限受限,不能執行特權指令(如I/O)。
- 內核模式 (Kernel Mode): 運行操作系統內核,擁有最高權限,可以執行任何指令,訪問任何硬件。
2.3 解決方案:受保護的控制權轉移 (Protected Control Transfer)

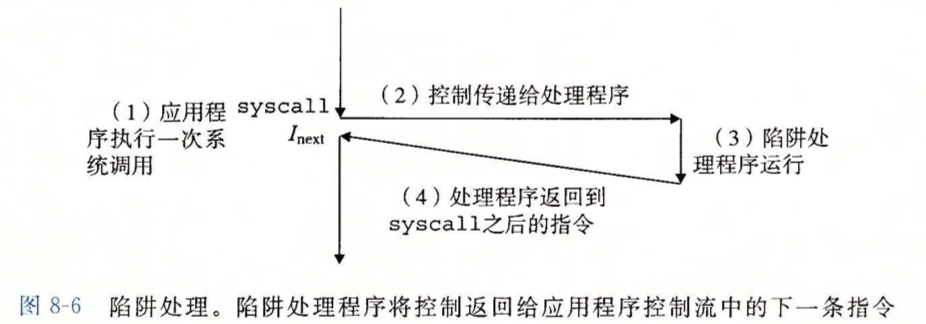
- 系統調用 (System Calls): 用戶程序通過執行特殊的
trap指令,陷入(trap)到內核。 - 陷入過程:
trap指令會提升CPU權限到內核模式,并跳轉到操作系統預設的代碼地址。 - 陷阱表 (Trap Table): 操作系統在啟動時設置一個陷阱表,告訴硬件在發生特定事件時應該跳轉到內核中的哪個處理程序。
- 返回: 內核完成工作后,執行
return-from-trap指令,降低CPU權限回用戶模式。
3. 問題2:如何在進程之間切換?
3.1 背景
實現了LDE后,當一個進程在CPU上運行時,操作系統本身并沒有運行。那么操作系統如何奪回控制權以切換到另一個進程,實現時分共享呢?
3.2 子問題:如何重獲CPU的控制權?
方案1 (協作式 Cooperative):
- 依賴進程"自覺"
- 進程通過發起系統調用或產生錯誤將控制權交還給OS
- 缺陷: 如果進程陷入死循環且不進行系統調用或出錯,OS將失去控制權
方案2 (非協作式/搶占式 Preemptive):
- 硬件支持——時鐘中斷 (Timer Interrupt)
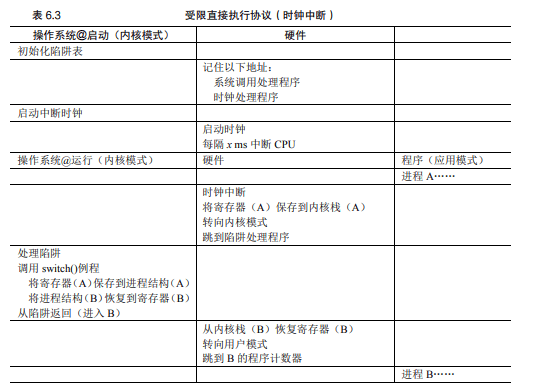
- OS在啟動時設置并啟動一個硬件時鐘
- 時鐘會定期產生中斷信號,強制打斷當前運行的進程
- CPU控制權轉移給OS預設的中斷處理程序
3.3 機制:上下文切換 (Context Switch)
當OS決定切換進程時,執行上下文切換:
- 保存當前進程的狀態到其進程結構(如PCB)或內核棧中
- 加載下一個要運行進程的狀態
- 切換內核棧指針
- 通過
return-from-trap指令返回,CPU開始執行新加載的進程
4. 潛在問題:并發問題
提出擔憂: 如果在處理系統調用或中斷時,又發生了一個中斷怎么辦?
初步解答: 這是并發問題,將在后續章節詳細討論。常用方法包括在處理中斷時禁止中斷 (disable interrupts),或使用復雜的**鎖 (locking)**機制來保護內核數據結構。
5. 深入理解Trap和Trap Table
5.1 Trap (陷阱)
在操作系統和計算機體系結構的語境下,"陷阱"是一種機制,它允許將處理器的控制權從用戶模式安全地轉移到內核模式。
目的:
- 執行受限操作: 通過系統調用實現
- 處理異常和錯誤: 如除零、訪問無效內存
- 響應硬件中斷: 如時鐘中斷、I/O完成信號
過程:
- 觸發: 由
trap指令、CPU錯誤/異常或硬件中斷觸發 - 硬件動作: 保存狀態、提升權限、查詢陷阱表
- 內核執行: 跳轉到陷阱處理程序
- 返回: 通過
return-from-trap指令返回用戶模式
5.2 Trap Table (陷阱表)
陷阱表是一個由操作系統內核創建和維護的數據結構,通常是一個數組。
內容: 每一項包含內核中特定處理程序代碼的內存地址
設置: 操作系統在啟動過程中初始化陷阱表
作用: 指導硬件在發生事件時應該跳轉到哪里
重要性: 確保控制權轉移的安全性和可控性
6. 陷阱表的技術實現
6.1 陷阱表概述
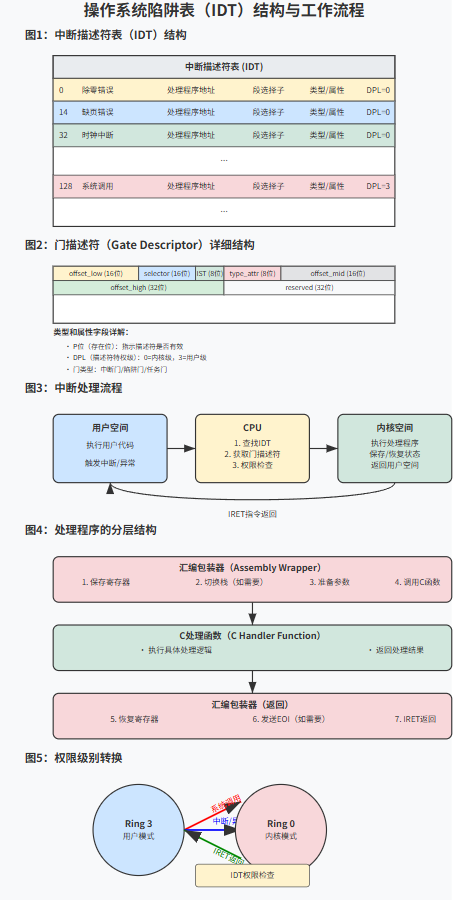
- 陷阱表本質上是一個數組結構
- 數組的索引對應中斷/異常/陷阱編號
- 數組的每個元素包含處理該事件的內核代碼地址和控制信息
6.2 x86架構的實現:中斷描述符表(IDT)
在x86架構中,陷阱表被稱為中斷描述符表(IDT),最多包含256個條目。
門描述符結構:
struct idt_entry {uint16_t offset_low; // 處理程序地址低16位uint16_t selector; // 段選擇子uint8_t ist; // IST索引和保留位uint8_t type_attr; // 類型和屬性uint16_t offset_mid; // 處理程序地址中16位uint32_t offset_high; // 處理程序地址高32位uint32_t zero; // 保留位
} __attribute__((packed));
6.3 IDT初始化代碼示例
void initialize_idt() {// 設置除零錯誤處理程序set_idt_gate(0, (uint64_t)÷_by_zero_handler, KERNEL_CS, 0x8E, 0);// 設置缺頁錯誤處理程序set_idt_gate(14, (uint64_t)&page_fault_handler, KERNEL_CS, 0x8E, 0);// 設置時鐘中斷處理程序set_idt_gate(32, (uint64_t)&timer_interrupt_handler, KERNEL_CS, 0x8E, 0);// 設置系統調用處理程序(注意DPL=3)set_idt_gate(128, (uint64_t)&system_call_handler, KERNEL_CS, 0xEE, 0);// 設置IDT指針idt_pointer.limit = sizeof(idt_table) - 1;idt_pointer.base = (uint64_t)&idt_table;// 加載IDT寄存器load_idt(&idt_pointer);
}
6.4 處理程序實現
C語言處理函數:
void timer_interrupt_handler_c() { /* 時鐘中斷邏輯 */ }
uint64_t system_call_handler_c(uint64_t syscall_num, uint64_t arg1, ...) { /* 處理系統調用 */ }
匯編包裝器:
timer_interrupt_handler_asm:pushaq ; 保存所有通用寄存器call timer_interrupt_handler_c ; 調用C函數popaq ; 恢復所有通用寄存器iretq ; 中斷返回
7. 總結
通過LDE機制解釋了如何虛擬化CPU的核心思想是讓程序直接運行,但預先設置好硬件限制(用戶/內核模式、陷阱處理、時鐘中斷),就像給房間做"寶寶防護 (baby proofing)"一樣。這樣既保證了效率,又維持了OS的控制權。
關鍵機制包括:
- 特權級別分離
- 受保護的控制權轉移
- 時鐘中斷
- 上下文切換
- 陷阱表
實驗:測量上下文調度時間
創建兩個進程。
創建兩個管道 (pipe) 用于這兩個進程間雙向通信。
管道 1:進程 A -> 進程 B
管道 2:進程 B -> 進程 A
關鍵: 將這兩個進程綁定到同一個 CPU 核心上運行。這可以使用 sched_setaffinity() (Linux) 或類似系統調用。這是為了確保測量的是單個 CPU 上的上下文切換,而不是因為進程在不同 CPU 間遷移。
進行乒乓通信:
進程 A 向管道 1 寫入少量數據(例如 1 字節)。
進程 A 嘗試從管道 2 讀取數據。由于管道 2 是空的,進程 A 會阻塞 (block)。
操作系統檢測到進程 A 阻塞,執行上下文切換,調度進程 B 運行。
進程 B 嘗試從管道 1 讀取數據(讀取 A 寫入的數據)。
進程 B 向管道 2 寫入少量數據。
進程 B 嘗試從管道 1 讀取數據。由于管道 1 現在是空的,進程 B 會阻塞。
操作系統檢測到進程 B 阻塞,執行上下文切換,調度進程 A 運行(此時 A 可以讀到 B 寫入的數據,解除阻塞)。
這樣完成了一個來回 (round trip)。
重復這個來回很多次。
記錄總時間,除以總的來回次數,得到平均每次來回的時間。
注意: 一個完整的來回包含兩次上下文切換(A->B 和 B->A)。所以,用平均來回時間除以 2,得到單次上下文切換的估算成本。
2.2 工具
pipe(): 創建 UNIX 管道。
fork(): 創建子進程。
write(), read(): 通過管道讀寫數據。
sched_setaffinity(): (Linux) 將進程綁定到指定 CPU 核心。需要包含 <sched.h> 并可能需要定義 _GNU_SOURCE。
wait() 或 waitpid(): 父進程等待子進程結束。
計時函數: 使用 clock_gettime() 。
#define _GNU_SOURCE // 需要這個宏才能使用 sched_setaffinity
#define _POSIX_C_SOURCE 199309L
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sched.h>
#include <time.h>
#include <string.h> // For memset#define ITERATIONS 100000 // 上下文切換測量的迭代次數
#define CPU_TO_BIND 0 // 綁定到 CPU 核心 0,確保你的系統有這個核心// Helper function to calculate time difference in nanoseconds
long long timespec_diff_ns(struct timespec start, struct timespec end) {return (end.tv_sec - start.tv_sec) * 1000000000LL + (end.tv_nsec - start.tv_nsec);
}int main() {int pipe1[2]; // Pipe: Parent -> Childint pipe2[2]; // Pipe: Child -> Parentpid_t child_pid;struct timespec start_time, end_time;long long total_elapsed_ns;double avg_round_trip_ns, avg_context_switch_ns;char buffer = 'x'; // 用于在管道中傳輸的單個字節// 創建兩個管道if (pipe(pipe1) == -1 || pipe(pipe2) == -1) {perror("pipe creation failed");return 1;}// 創建子進程child_pid = fork();if (child_pid == -1) {perror("fork failed");return 1;}// 設置 CPU 親和性 (Affinity)cpu_set_t cpu_set;CPU_ZERO(&cpu_set);CPU_SET(CPU_TO_BIND, &cpu_set);if (sched_setaffinity(0, sizeof(cpu_set_t), &cpu_set) == -1) {perror("sched_setaffinity failed");// 不一定是致命錯誤,但測量結果可能不準}if (child_pid == 0) {// --- 子進程代碼 ---close(pipe1[1]); // 關閉 pipe1 的寫端close(pipe2[0]); // 關閉 pipe2 的讀端for (long i = 0; i < ITERATIONS; ++i) {// 從父進程讀if (read(pipe1[0], &buffer, 1) != 1) {perror("Child read failed");exit(1);}// 寫回給父進程if (write(pipe2[1], &buffer, 1) != 1) {perror("Child write failed");exit(1);}}close(pipe1[0]);close(pipe2[1]);exit(0);} else {// --- 父進程代碼 ---close(pipe1[0]); // 關閉 pipe1 的讀端close(pipe2[1]); // 關閉 pipe2 的寫端// 獲取開始時間 (在循環開始前)if (clock_gettime(CLOCK_MONOTONIC, &start_time) == -1) {perror("clock_gettime start failed");return 1;}// 執行乒乓通信循環for (long i = 0; i < ITERATIONS; ++i) {// 寫給子進程if (write(pipe1[1], &buffer, 1) != 1) {perror("Parent write failed");exit(1);}// 從子進程讀 (會阻塞,觸發 A->B 切換)if (read(pipe2[0], &buffer, 1) != 1) {perror("Parent read failed");exit(1);}// 讀完后,子進程會阻塞,觸發 B->A 切換}// 獲取結束時間if (clock_gettime(CLOCK_MONOTONIC, &end_time) == -1) {perror("clock_gettime end failed");return 1;}// 等待子進程結束wait(NULL);close(pipe1[1]);close(pipe2[0]);// 計算總耗時total_elapsed_ns = timespec_diff_ns(start_time, end_time);// 計算平均每次來回耗時avg_round_trip_ns = (double)total_elapsed_ns / ITERATIONS;// 計算平均每次上下文切換耗時 (來回時間 / 2)avg_context_switch_ns = avg_round_trip_ns / 2.0;printf("Measured %ld round trips between two processes on CPU %d.\n", (long)ITERATIONS, CPU_TO_BIND);printf("Total time: %lld ns\n", total_elapsed_ns);printf("Average round trip time: %.2f ns\n", avg_round_trip_ns);printf("Average context switch cost: %.2f ns\n", avg_context_switch_ns);}return 0;
}// 編譯: gcc -o measure_ctxsw measure_ctxsw.c -lrt -D_GNU_SOURCE
// 運行: ./measure_ctxsw
8. 參考資料
- 陷阱、中斷、異常、信號
- OSTEP

)

:剖析創業增長引擎與精益畫布指標)





)


)





- KMP算法)
