Word直接導出的pdf不夠清晰,使用打印導出的pdf又不帶書簽以及目錄跳轉功能這一問題,查閱網上資料使用Adobe DC似乎能夠解決但是下載安裝比較麻煩,于是寫了python程序解決該問題。
解決思路: 使用python腳本對兩個pdf文件進行合并,合并小體積的帶書簽的pdf和高清版本的pdf文件。
Step1:準備帶書簽的pdf,并命名為999.pdf (該名稱與程序對應)
使用word導出功能,選擇最小文件導出,并勾選書簽導出選項。

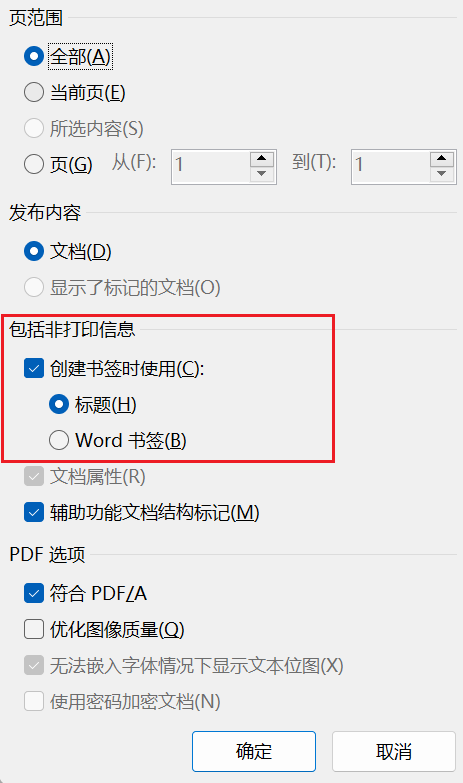
Step2:打印輸出高清pdf文件,并命名為a.pdf
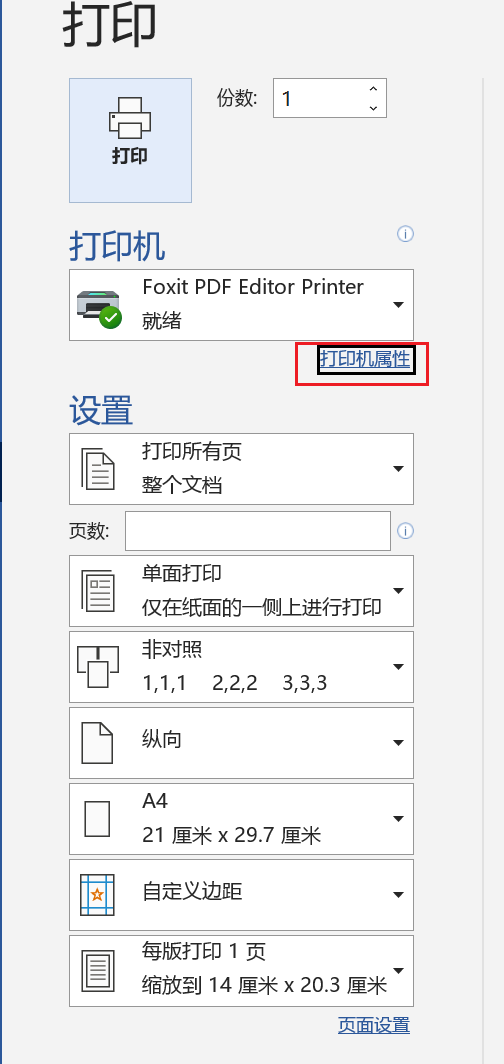
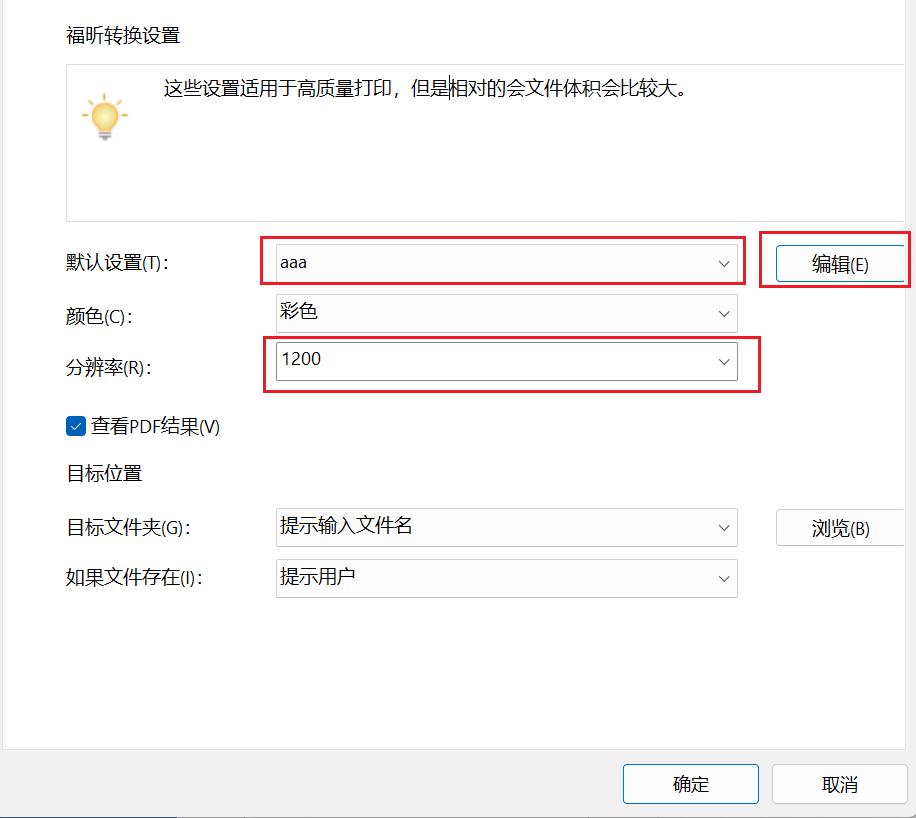
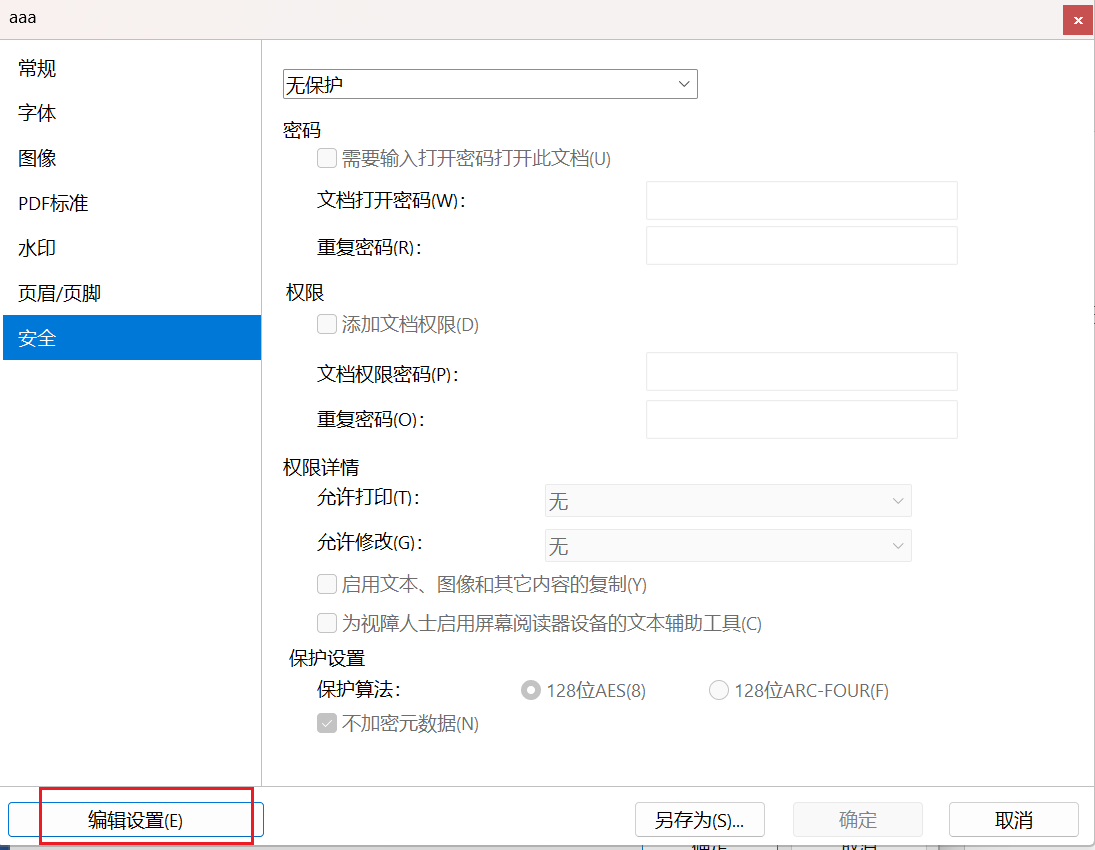
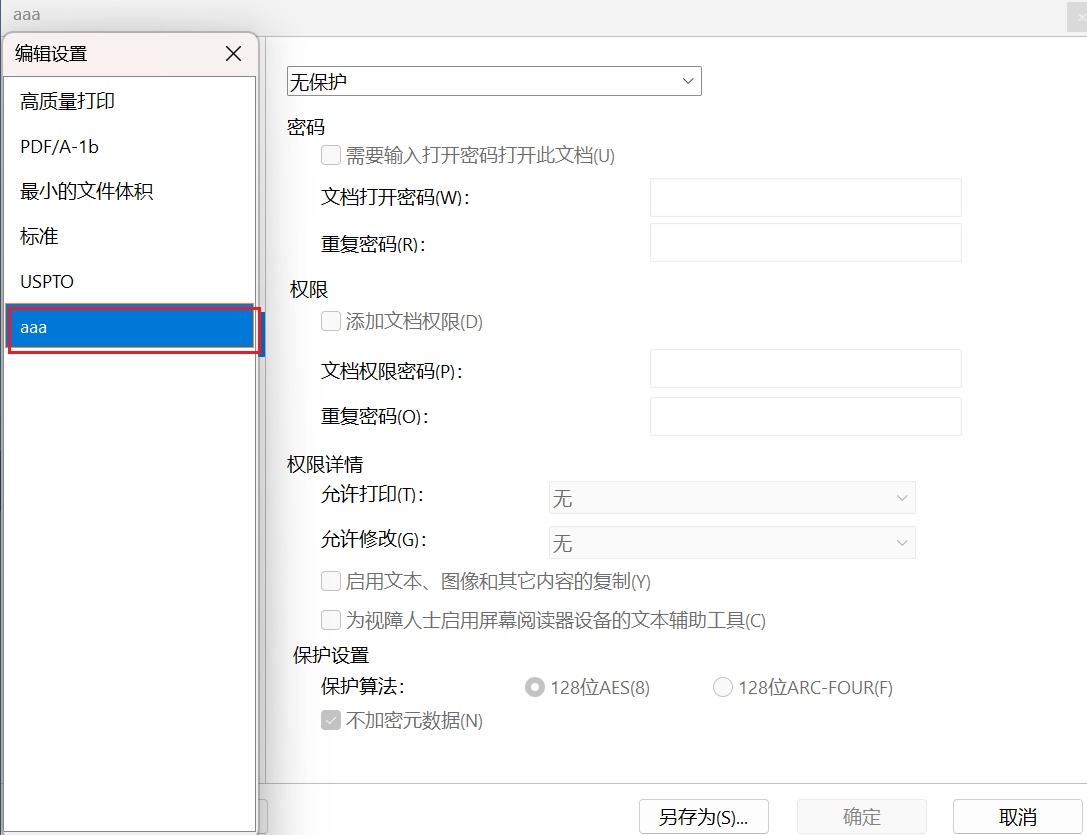
打印使用福昕pdf的虛擬打印機,最高支持2400dpi的清晰度,我一般選1200dpi,已經足夠清晰了。(也可以使用自帶的Microsoft pdf 打印輸出 但最高只支持600dpi)
打印導出文件,并命名為a.pdf
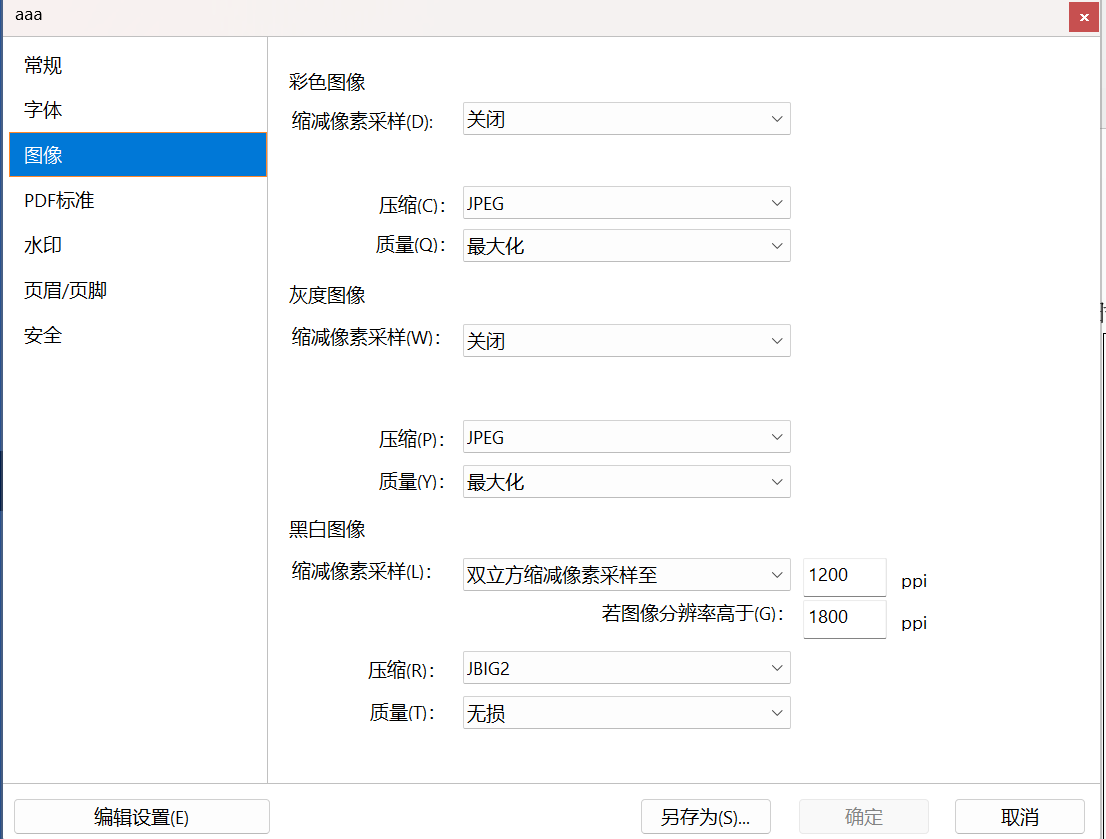
如果遇到導出的pdf文件太大可以不勾選word選項中的“不壓縮文件中的圖像”來進一步限制打印輸出文件大小。
###使用Microsoft pdf打印輸出文件也可以用代碼替代執行,但最高只有600dpi,不如福昕pdf
import win32com.client
from pathlib import Path
import os
import timedef convert_docx_to_hd_pdf(input_docx, output_pdf):# 確保輸出路徑存在output_path = Path(output_pdf).parentos.makedirs(output_path, exist_ok=True)# 創建Word應用對象word = win32com.client.DispatchEx("Word.Application")word.Visible = Truetry:# 打開文檔doc = word.Documents.Open(str(Path(input_docx).resolve()))# 獲取文檔總頁數total_pages = doc.ComputeStatistics(2) # 2 = wdStatisticPagesprint(f"文檔共 {total_pages} 頁,開始轉換...")# 輸出路徑output_pdf_abs = str(Path(output_pdf).resolve())# 設置打印機為Microsoft Print to PDFword.ActivePrinter = "Microsoft Print to PDF"# 設置打印選項word.Options.PrintBackground = Trueword.Application.Options.PrintDraft = Falseword.Application.Options.PrintProperties = False# 執行打印print("開始高質量打印...")word.ActiveDocument.PrintOut(OutputFileName=output_pdf_abs,Range=0,Item=0,Copies=1,Pages="",PageType=0,PrintToFile=True,Collate=False)# 等待打印完成print("正在等待打印完成...")# 等待文件生成max_wait = 30 # 最多等待30秒start_time = time.time()while time.time() - start_time < max_wait:if os.path.exists(output_pdf) and os.path.getsize(output_pdf) > 0:print(f"PDF導出完成: {output_pdf}")print(f"文件大小: {os.path.getsize(output_pdf)} 字節")return Truetime.sleep(1)print("等待超時,請檢查輸出文件")return Falseexcept Exception as e:print(f"轉換失敗: {str(e)}")return Falsefinally:try:doc.Close(SaveChanges=False)except:password.Quit()# 執行轉換
if __name__ == "__main__":convert_docx_to_hd_pdf('88.docx', '999.pdf') ## 88.docx為word文件名總之會得到兩個pdf文件如下

Step3:創建虛擬環境,并執行文件合并
conda create -n xxx python=3.9conda activate xxxcd xxxxxpip install pikepdf pathlib os然后運行程序,在此之前需在程序中指定目錄頁碼范圍,比如我的word目錄對應9-10頁
修改如下部分
![]()
![]()
運行
import pikepdf
from pathlib import Path
import osstart_page = 8
end_page = 9def merge_pdfs_with_bookmarks(image_pdf_path, bookmark_pdf_path, output_pdf_path):"""合并兩個PDF文件,保留第二個PDF的書簽信息和目錄頁,其他頁面使用第一個PDF的內容參數:image_pdf_path: 包含高質量圖片的PDF路徑bookmark_pdf_path: 包含書簽信息的PDF路徑output_pdf_path: 輸出PDF的路徑"""print(f"開始合并PDF文件...")print(f"圖片源PDF: {image_pdf_path}")print(f"書簽源PDF: {bookmark_pdf_path}")try:# 確保輸出目錄存在output_dir = Path(output_pdf_path).parentos.makedirs(output_dir, exist_ok=True)# 打開兩個PDF文件with pikepdf.open(image_pdf_path) as image_pdf, pikepdf.open(bookmark_pdf_path) as bookmark_pdf:# 檢查頁數是否一致if len(image_pdf.pages) != len(bookmark_pdf.pages):print(f"警告: 兩個PDF的頁數不一致! 圖片PDF: {len(image_pdf.pages)}頁, 書簽PDF: {len(bookmark_pdf.pages)}頁")print("繼續合并,但可能導致書簽指向錯誤的頁面")# 創建一個新的PDF,以bookmark_pdf為基礎merged_pdf = pikepdf.Pdf.open(bookmark_pdf_path)# 創建頁面映射表,記錄原始頁面和新頁面的對應關系page_map = {}# 替換除了第8-9頁以外的所有頁面for i in range(len(merged_pdf.pages)):# 頁碼從0開始,所以第9-10頁對應索引8-9if (i > end_page or i < start_page) and i < len(image_pdf.pages): # i != 10-12# 保存原始頁面的引用old_page = merged_pdf.pages[i]old_objgen = old_page.obj.objgen# 使用正確的方法替換頁面# pikepdf不支持直接刪除頁面,但可以直接替換merged_pdf.pages[i] = pikepdf.Page(image_pdf.pages[i])# 記錄頁面映射關系page_map[old_objgen[0]] = merged_pdf.pages[i].obj# 修復文檔內部鏈接(目錄頁鏈接)print("正在修復文檔內部鏈接...")# 特別處理目錄頁(第9-10頁,索引8-9)for i in [start_page, end_page]:if '/Annots' in merged_pdf.pages[i]:annots = merged_pdf.pages[i]['/Annots']if isinstance(annots, pikepdf.Array):# print(annots)for annot in annots:# 檢查是否是鏈接注釋if annot.get('/Subtype') == '/Link':# 處理直接目標if '/Dest' in annot:dest = annot['/Dest']if isinstance(dest, pikepdf.Array) and len(dest) > 0:if hasattr(dest[0], 'objgen'):ref_id = dest[0].objgen[0]if ref_id in page_map:dest[0] = page_map[ref_id]# 處理動作目標elif '/A' in annot and isinstance(annot['/A'], pikepdf.Dictionary) and '/D' in annot['/A']:dest = annot['/A']['/D']if isinstance(dest, pikepdf.Array) and len(dest) > 0:if hasattr(dest[0], 'objgen'):ref_id = dest[0].objgen[0]if ref_id in page_map:dest[0] = page_map[ref_id]# 提取書簽信息bookmarks = []if hasattr(bookmark_pdf, 'Root') and '/Outlines' in bookmark_pdf.Root:print("正在提取書簽信息...")# 遞歸提取書簽def extract_bookmarks(outline, bookmarks, depth=0):if '/First' not in outline:returncurrent = outline['/First']while True:title = str(current.get('/Title', ''))dest = current.get('/Dest', None)page_num = 0if dest is not None and isinstance(dest, pikepdf.Array) and len(dest) > 0:# 查找目標頁面page_ref = dest[0]for i, page in enumerate(bookmark_pdf.pages):# 使用對象ID比較而不是same_as方法if hasattr(page.obj, 'objgen') and hasattr(page_ref, 'objgen'):if page.obj.objgen == page_ref.objgen:page_num = ibreak# 創建書簽項bookmark = {'title': title,'page': page_num,'children': []}bookmarks.append(bookmark)# 處理子書簽if '/First' in current:extract_bookmarks(current, bookmark['children'], depth + 1)# 移動到下一個書簽if '/Next' not in current:breakcurrent = current['/Next']# 提取所有書簽extract_bookmarks(bookmark_pdf.Root['/Outlines'], bookmarks)print(f"提取了 {len(bookmarks)} 個頂級書簽")# 如果有提取到書簽,添加到新PDFif bookmarks:print("正在將書簽添加到新PDF...")# 遞歸創建書簽def create_bookmarks(pdf, bookmarks, parent=None):if not bookmarks:return Nonefirst = Nonelast = Noneprev = Nonefor bookmark in bookmarks:# 創建新書簽current = pdf.make_indirect(pikepdf.Dictionary({'/Title': pikepdf.String(bookmark['title']),'/Parent': parent}))# 設置目標頁面page_idx = bookmark['page']if page_idx < len(pdf.pages):dest = [pdf.pages[page_idx].obj, pikepdf.Name('/Fit')]current['/Dest'] = pdf.make_indirect(pikepdf.Array(dest))# 處理鏈接關系if first is None:first = currentif prev is not None:prev['/Next'] = currentcurrent['/Prev'] = prevprev = currentlast = current# 處理子書簽if bookmark['children']:children_first = create_bookmarks(pdf, bookmark['children'], current)if children_first:current['/First'] = children_first# 找到最后一個子書簽children_last = children_firstwhile '/Next' in children_last:children_last = children_last['/Next']current['/Last'] = children_lastcurrent['/Count'] = len(bookmark['children'])return first# 創建書簽字典outlines = merged_pdf.make_indirect(pikepdf.Dictionary({'/Type': pikepdf.Name('/Outlines'),'/Count': len(bookmarks)}))# 創建書簽樹first = create_bookmarks(merged_pdf, bookmarks, outlines)if first:outlines['/First'] = first# 找到最后一個書簽last = firstwhile '/Next' in last:last = last['/Next']outlines['/Last'] = last# 添加到PDFmerged_pdf.Root['/Outlines'] = outlinesprint("成功添加書簽到新PDF")# 保存合并后的PDFmerged_pdf.save(output_pdf_path)print(f"PDF合并完成! 輸出文件: {output_pdf_path}")print(f"文件大小: {os.path.getsize(output_pdf_path)} 字節")return Trueexcept Exception as e:print(f"合并PDF時出錯: {str(e)}")import tracebacktraceback.print_exc()return Falseif __name__ == "__main__":# 文件路徑image_pdf = ".\a.pdf" # 包含高質量圖片的PDFbookmark_pdf = ".\999.pdf" # 包含書簽信息的PDFoutput_pdf = ".\out.pdf" # 輸出文件# 執行合并merge_pdfs_with_bookmarks(image_pdf, bookmark_pdf, output_pdf)大功告成
![]()
該文件大小一般與高清pdf文件大小相當...
特別說明:該程序對正文中的圖跳轉未作程序編寫。





垂直分庫架構、分布式數據庫)












:精益畫布與創業方向抉擇)
