什么是網絡爬蟲?
網絡爬蟲(Web Crawler)是一種自動獲取網頁內容的程序。它可以訪問網站,抓取頁面內容,并從中提取有價值的數據。在信息爆炸的時代,爬蟲技術可以幫助我們高效地收集、整理和分析互聯網上的海量數據。
爬蟲的發展歷程
要理解今天的爬蟲技術,我們需要先了解它的歷史演變。爬蟲技術的發展與互聯網的成長緊密相連,經歷了從簡單工具到復雜系統的轉變。
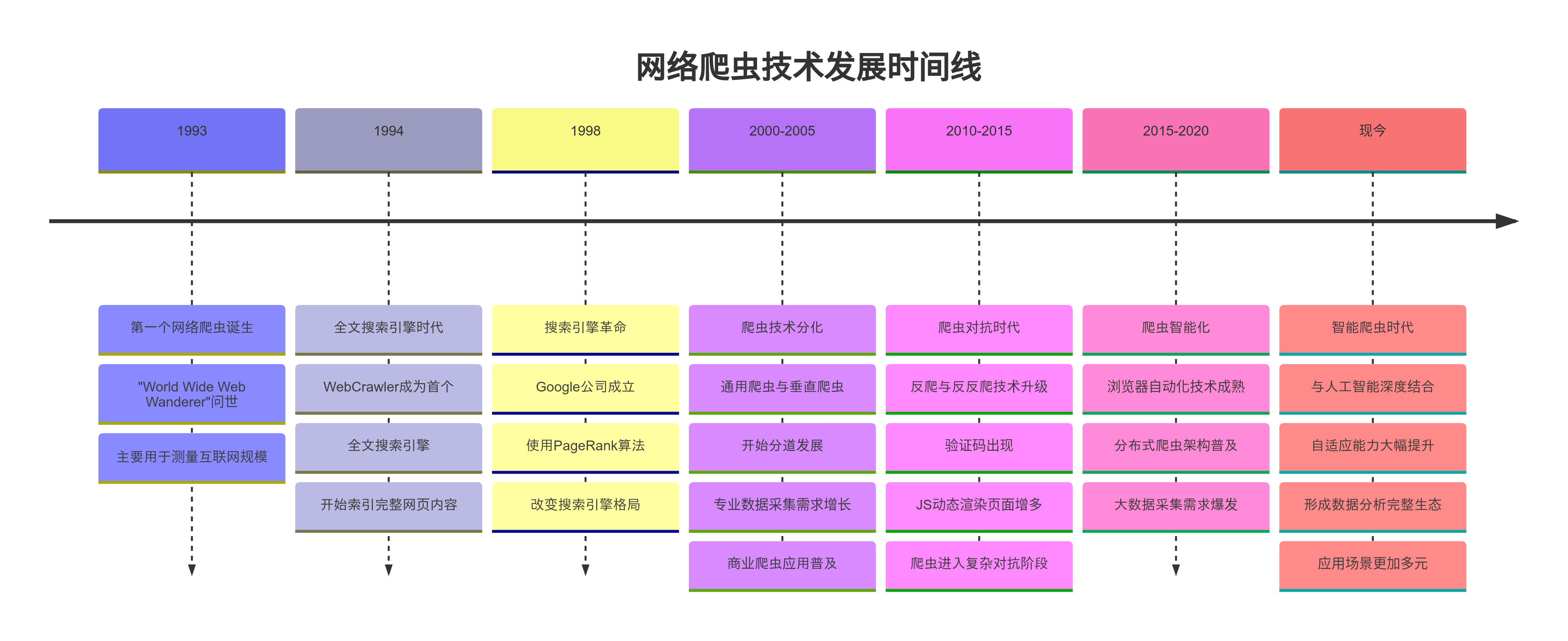
- 1993年 - 第一個網絡爬蟲 “World Wide Web Wanderer” 出現,主要用于測量互聯網規模
- 1994年 - WebCrawler成為第一個全文搜索引擎,開始索引整個網頁內容
- 1998年 - Google建立,使用PageRank算法的爬蟲技術革新了搜索引擎
- 2000年代初 - 通用爬蟲和垂直爬蟲開始分化,專業數據采集需求增長
- 2010年代 - 反爬與反反爬技術不斷升級,爬蟲技術進入復雜對抗階段
- 現今 - 爬蟲技術與人工智能、大數據分析結合,應用場景更加廣泛
隨著爬蟲技術的不斷發展,它們也逐漸形成了不同的類型以滿足各種需求。
爬蟲的分類
根據工作方式和目標不同,爬蟲可以分為幾種主要類型:
- 通用爬蟲: 也稱為全網爬蟲,類似于搜索引擎使用的爬蟲系統。它們不針對特定網站,而是嘗試抓取互聯網上盡可能多的網頁,建立廣泛的數據索引。百度、谷歌等搜索引擎使用的就是這類爬蟲。通用爬蟲通常規模龐大,需要處理海量數據和復雜的網頁排名算法。
- 垂直爬蟲: 專注于特定領域或網站的爬蟲,只抓取與特定主題相關的內容。比如只抓取電商網站的商品信息、只收集新聞網站的文章或只獲取社交媒體的特定數據。垂直爬蟲更加精準高效,適合有明確目標的數據采集需求。
- 增量式爬蟲: 關注數據的更新變化,只抓取新增或修改的內容,而不是重復抓取整個網站。這類爬蟲通常會記錄上次抓取的時間戳或內容特征,通過比對確定哪些內容需要更新。增量式爬蟲大大減少了重復工作,提高了效率和資源利用率。
- 深層爬蟲: 能夠突破常規爬蟲的限制,處理需要用戶交互、表單提交或JavaScript動態渲染的內容。普通爬蟲可能只能獲取靜態HTML,而深層爬蟲能夠模擬瀏覽器行為,執行JavaScript代碼,處理AJAX請求,甚至能填寫表單并提交,從而獲取隱藏在"深層網絡"中的數據。
網絡爬蟲工作原理
網絡爬蟲雖然種類多樣,但基本工作原理是相似的。下圖展示了爬蟲的典型工作流程:
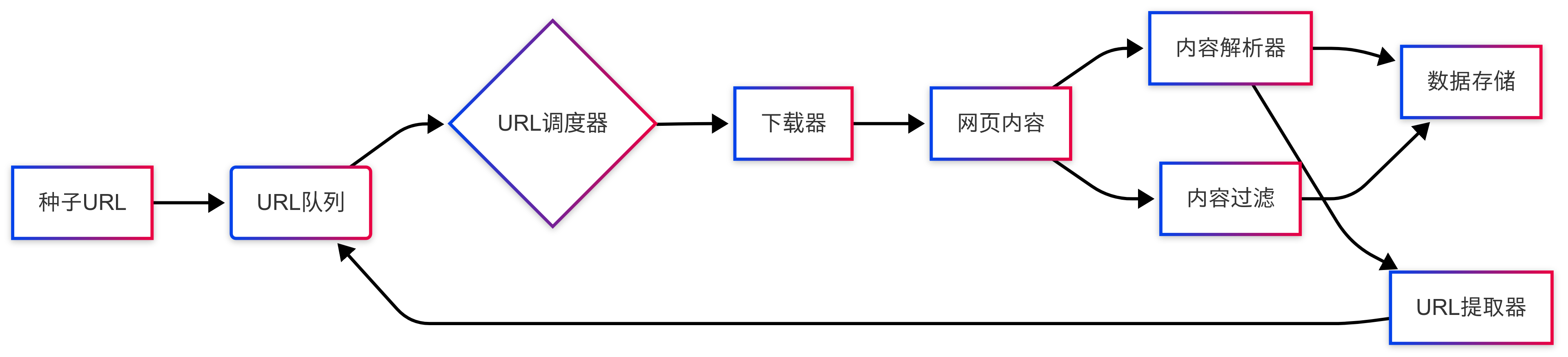
網絡爬蟲的工作流程通常遵循一個循環往復的過程,主要包括以下幾個環節:
-
初始化種子URL:爬蟲從一組預定義的起始URL(稱為種子URL)開始工作。這些URL是爬取過程的入口點,類似于探索迷宮的起點。
-
URL隊列管理:爬蟲維護一個待爬取的URL隊列。初始時,隊列中只有種子URL,隨著爬取過程的推進,新發現的URL會不斷加入隊列。
-
URL調度器:負責從URL隊列中選擇下一個要爬取的URL。調度器會考慮各種因素,如URL優先級、訪問頻率限制、網站禮儀(robots.txt)等。
-
網頁下載:爬蟲向目標URL發送HTTP請求,獲取網頁內容。這一步可能會處理各種HTTP狀態碼、重定向、超時等情況。
-
內容解析:獲取到網頁內容后,爬蟲會解析HTML/XML結構,提取有價值的數據。常用的解析方法包括正則表達式、XPath、CSS選擇器或專門的解析庫(如BeautifulSoup)。
-
數據過濾與存儲:對提取的數據進行清洗、去重、格式化等處理,然后存儲到文件、數據庫或其他存儲系統中。
-
URL提取:從已下載的頁面中提取新的URL鏈接,這些新URL經過篩選后(去除重復、不符合規則的URL)加入到URL隊列中,等待后續爬取。
-
循環迭代:重復上述過程,直到達到預定的終止條件,如隊列為空、達到最大爬取數量或時間限制等。
在實際應用中,爬蟲系統還會增加很多功能模塊,如反爬處理、分布式協作、失敗重試、數據驗證等,以提高爬取的效率、穩定性和準確性。
為什么選擇Python進行網絡爬取?
了解了爬蟲的基本原理后,接下來的問題是:用什么工具和語言來實現爬蟲?雖然許多編程語言都可以開發爬蟲,但Python已成為這一領域的主導語言。這不是偶然的,而是有充分理由的選擇,主要原因包括:
- 簡潔易學:Python語法簡單清晰,代碼可讀性高,學習曲線平緩。與其他語言相比,用更少的代碼就能實現相同功能,讓開發者可以專注于爬蟲邏輯而非語法細節。比如我使用下面的3行代碼就能實現爬取百度搜索頁面的數據:
import requests
response = requests.get("https://www.baidu.com")
print(response.text)
-
豐富的庫支持:Python擁有為爬蟲量身定制的工具生態系統:
- Requests:直觀易用的HTTP庫,簡化網絡請求
- BeautifulSoup:強大的HTML/XML解析器
- Scrapy:全功能爬蟲框架,提供完整解決方案
- Selenium/Playwright:瀏覽器自動化工具,處理動態網頁
- Pandas:高效的數據處理與分析庫
-
活躍的社區支持:大量教程、文檔和示例代碼,遇到問題時容易找到解決方案。爬蟲技術不斷更新,社區也持續提供應對各種反爬策略的方法。
-
跨平臺兼容性:Python程序可在Windows、Mac、Linux等各種操作系統上無縫運行,便于部署和維護。
-
與數據科學生態系統緊密集成:爬蟲的最終目的往往是數據分析,Python在這方面具有獨特優勢。爬取后的數據可直接使用Pandas、NumPy處理,用Matplotlib可視化,甚至用于機器學習。
-
并發處理能力:通過多線程、異步IO(asyncio)和協程,Python能高效處理大量并發請求,這對爬蟲至關重要。
-
應對反爬策略的靈活性:Python生態提供了多種工具來處理cookies、會話管理、用戶代理偽裝和驗證碼識別等反爬挑戰。
雖然其他語言也可以開發爬蟲,但Python在易用性、開發效率和功能完整性上的優勢使其成為爬蟲開發的理想選擇,特別適合從入門到精通的學習過程。
爬蟲與網絡請求模型
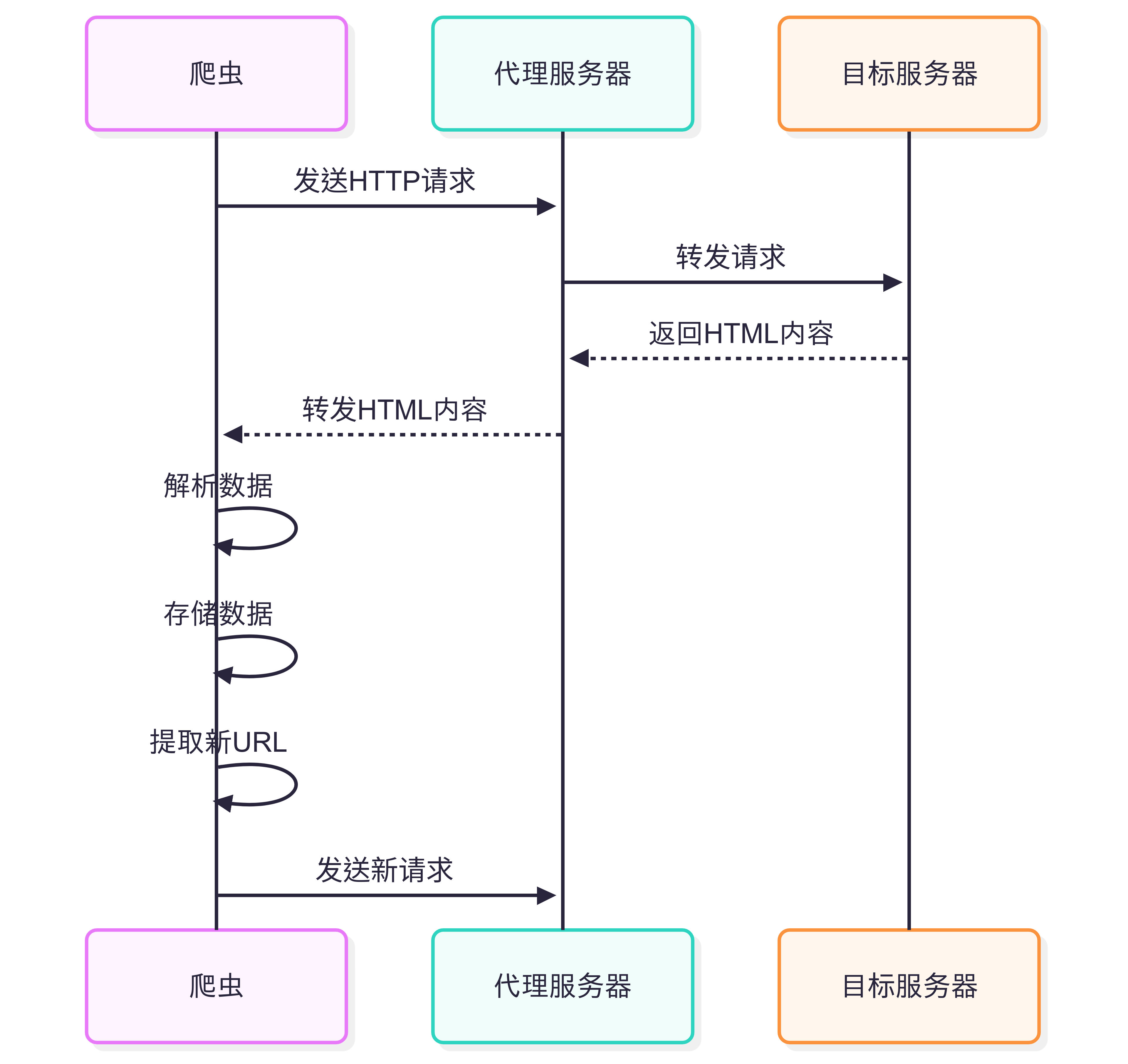
上圖展示了爬蟲工作過程中的網絡請求交互模型。整個過程可以分為以下幾個步驟:
-
發起請求:爬蟲程序首先向代理服務器發送HTTP請求,這一步通常包含目標URL和各種請求參數。
-
請求轉發:代理服務器接收到爬蟲的請求后,將其轉發給目標服務器。使用代理服務器可以隱藏爬蟲的真實IP地址,減少被目標網站封禁的風險。
-
內容返回:目標服務器處理請求后,將HTML內容返回給代理服務器。
-
內容傳遞:代理服務器將收到的HTML內容轉發回爬蟲程序。
-
數據處理:爬蟲收到HTML內容后,進行三個關鍵操作:
- 解析數據:使用解析器提取需要的信息
- 存儲數據:將有價值的數據保存到文件或數據庫
- 提取新URL:從頁面中發現新的鏈接,加入待爬取隊列
-
循環爬取:爬蟲根據新提取的URL,向代理服務器發送新的請求,整個過程循環往復,直到滿足終止條件。
這種模型體現了爬蟲工作的基本流程,特別是在使用代理服務器的情況下,既能提高爬取效率,又能增強爬蟲的隱蔽性和穩定性。
如何查看和遵守robots.txt
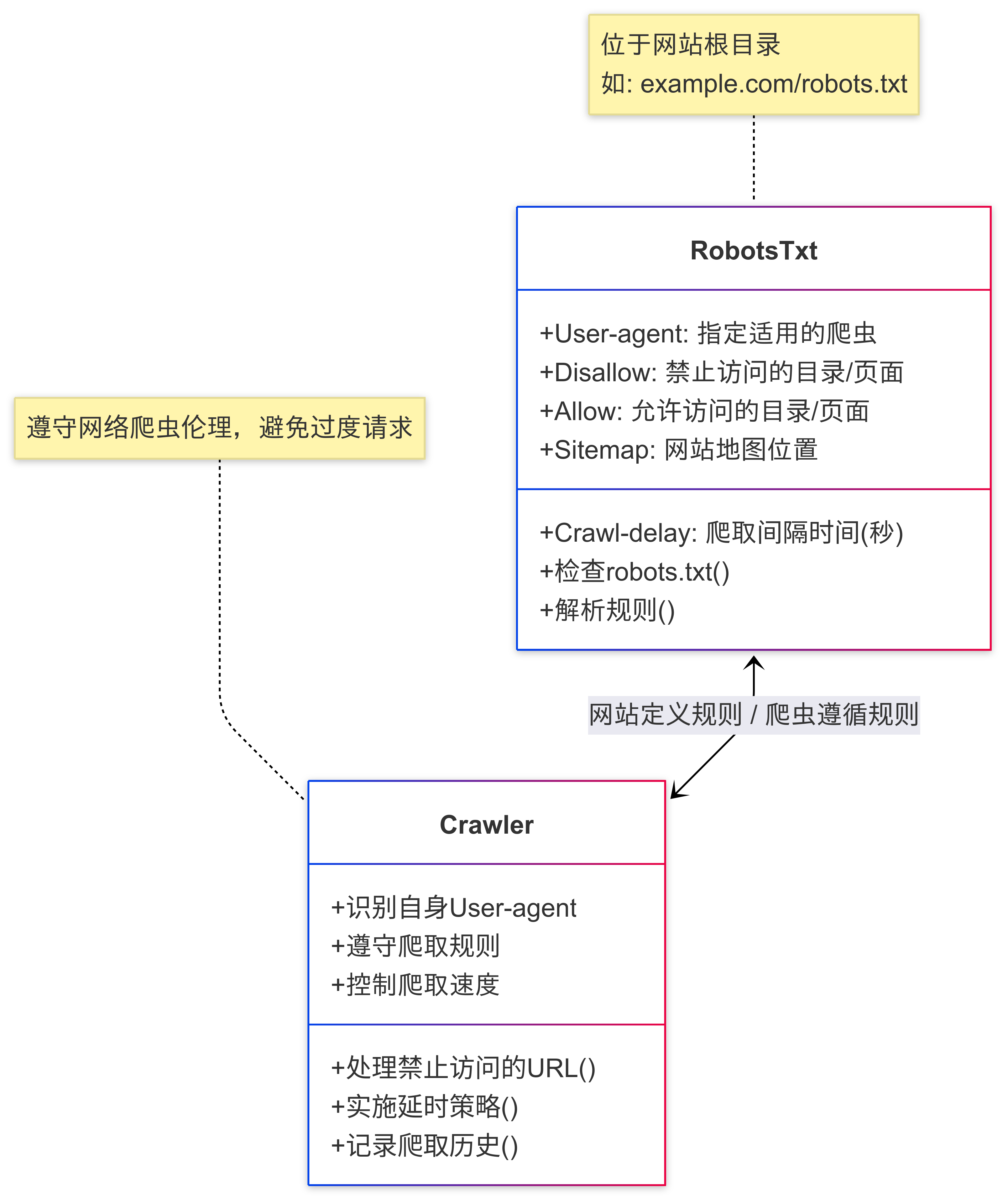
作為負責任的爬蟲開發者,我們應該尊重網站所有者的意愿。robots.txt是網站根目錄下的一個文本文件,用于告訴爬蟲哪些頁面可以爬取,哪些不可以。遵守robots.txt是網絡爬蟲的基本道德準則。
如何查看robots.txt文件:
- 直接訪問: 將網址后面加上"/robots.txt"
https://www.baidu.com/robots.txt
- 通過Python代碼查看:
import requestsdef get_robots_txt(url):# 確保URL格式正確if not url.startswith('http'):url = 'https://' + url# 移除URL末尾的斜杠(如果有)if url.endswith('/'):url = url[:-1]# 獲取robots.txt文件robots_url = url + '/robots.txt'try:response = requests.get(robots_url)if response.status_code == 200:print(f"成功獲取 {robots_url}")return response.textelse:print(f"無法獲取robots.txt,狀態碼: {response.status_code}")return Noneexcept Exception as e:print(f"發生錯誤: {e}")return None# 使用示例
robots_content = get_robots_txt('www.baidu.com')
print(robots_content)
robots.txt文件典型內容示例:
User-agent: *
Disallow: /private/
Disallow: /admin/
Allow: /public/
Crawl-delay: 10
解釋:
User-agent: *- 適用于所有爬蟲Disallow: /private/- 禁止爬取/private/目錄下的內容Allow: /public/- 允許爬取/public/目錄下的內容Crawl-delay: 10- 建議爬蟲每次請求之間間隔10秒
robots.txt文件分析圖解:
理解了網站的爬取規則后,我們可以開始實際的爬蟲編寫。下面是一個簡單的Python爬蟲示例,展示了基本的爬取過程。
一個簡單的Python爬蟲示例
以下是一個基礎的Python爬蟲示例,用于爬取百度熱搜榜的內容:
import requests
from bs4 import BeautifulSoup# 發送HTTP請求
url = "https://top.baidu.com/board?tab=realtime"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
response = requests.get(url, headers=headers)# 檢查請求是否成功
if response.status_code == 200:# 解析HTML內容soup = BeautifulSoup(response.text, 'html.parser')# 提取熱搜標題hot_titles = soup.select("div.c-single-text-ellipsis")for i, title in enumerate(hot_titles, 1):print(f"{i}. {title.text.strip()}")
else:print(f"請求失敗,狀態碼: {response.status_code}")
這個示例中我們使用requests庫對百度熱搜榜發起HTTP請求,獲取頁面的HTML內容。然后利用BeautifulSoup庫(這是一個強大的HTML解析工具,后續博客會詳細介紹)對獲取的內容進行解析。通過選擇器定位到熱搜標題所在的元素(具有"c-single-text-ellipsis"類的div元素),我們能夠準確提取出當前的熱搜話題,并按順序打印出來。代碼中還添加了請求頭信息和錯誤處理機制,確保爬取過程更加穩定可靠。
代碼運行結果如下圖所示:
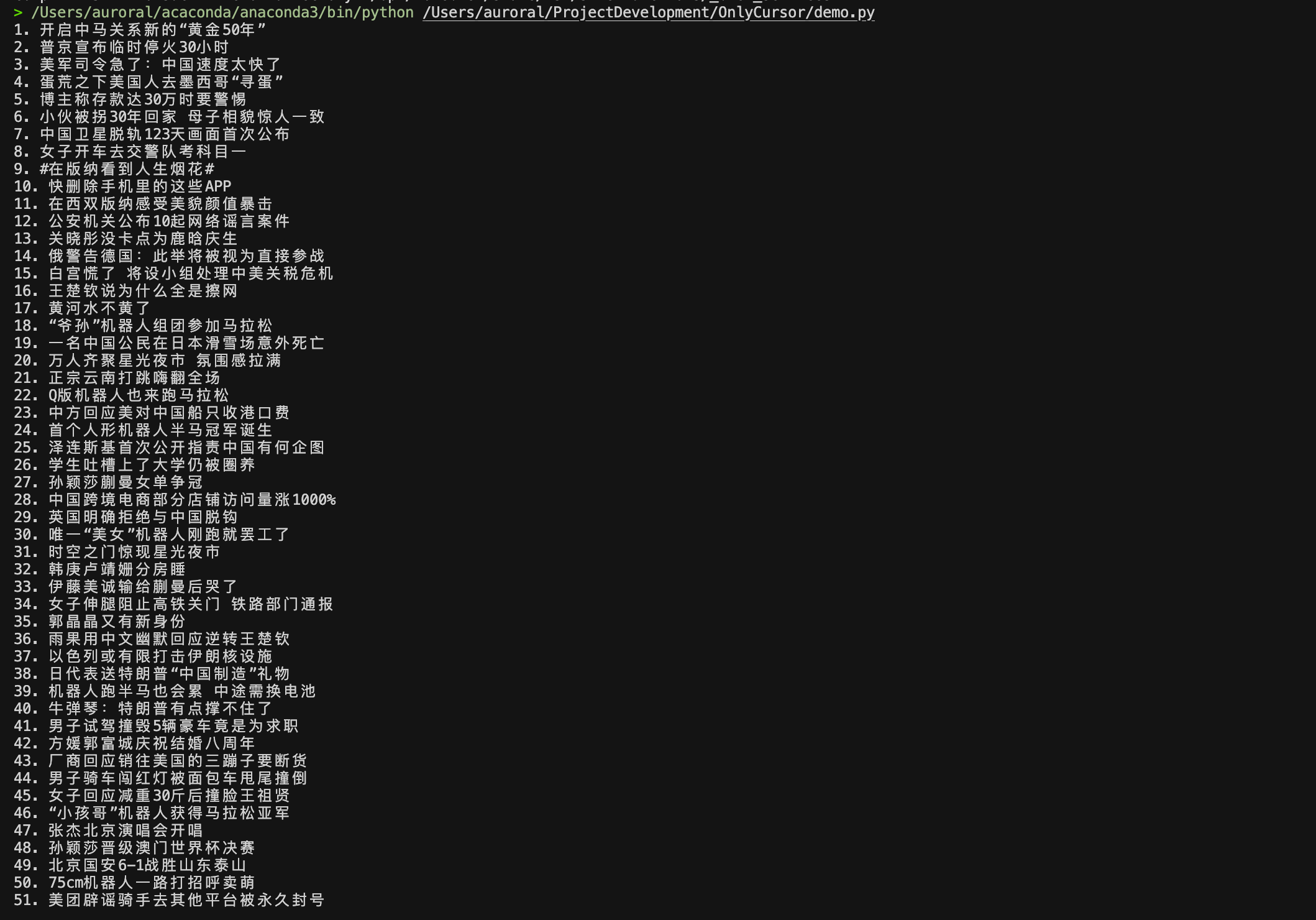
雖然上面的例子很簡單,但在實際開發爬蟲時,我們需要考慮很多因素。接下來,讓我們看看爬蟲開發中需要注意的一些重要事項。
網絡爬蟲需要注意的重要事項
1. 法律與道德考量
- 尊重robots.txt:這是網站指定爬蟲行為的標準文件,應當遵守。
- 識別網站的爬蟲政策:有些網站明確禁止爬蟲,有些則有特定的API可用。
- 避免過度請求:高頻率的請求可能導致服務器負擔過重。
- 遵守數據使用條款:確保你對抓取的數據的使用符合網站的條款。
- 注意個人隱私數據:不應爬取和存儲涉及個人隱私的數據。
2. 技術注意事項
- 設置合理的請求間隔:使用
time.sleep()控制請求頻率。 - 使用代理IP:避免IP被封禁。
- 模擬真實用戶行為:添加請求頭,隨機調整請求間隔。
- 處理反爬機制:驗證碼識別、JavaScript渲染等。
- 異常處理:網絡連接、解析錯誤等都需要妥善處理。
3. 性能考慮
- 異步爬取:使用
asyncio和aiohttp提高效率。 - 分布式爬取:對于大規模爬取任務,考慮使用多機協作。
- 數據存儲優化:選擇合適的存儲方式(文件、數據庫等)。
爬蟲與反爬的攻防關系
隨著互聯網數據價值的不斷提升,爬蟲技術與反爬技術之間形成了一種此消彼長的攻防關系。這種關系呈現出明顯的階段性特征,從最初的簡單對抗發展到如今的復雜博弈。
在早期階段,爬蟲通常以簡單的HTTP請求方式獲取網頁內容,網站則主要通過訪問頻率限制來防御。爬蟲工程師很快發現,只需在請求中添加隨機延時就能有效規避這類限制。這種基礎層面的對抗促使網站開發者升級防御策略。
隨著對抗升級,網站開始實施更復雜的防御措施,例如檢測請求頭中的用戶代理信息,以及限制單一IP的訪問次數。爬蟲技術隨之調整,不僅能夠偽裝請求頭信息,還發展出代理IP池技術,通過不斷切換IP地址來繞過訪問限制。這一階段的特點是技術門檻明顯提高,雙方對抗更加精細化。
當前,我們已進入高級對抗階段。網站普遍采用驗證碼挑戰、前端JavaScript渲染數據以及用戶行為分析等技術手段。爬蟲則相應發展出驗證碼識別、瀏覽器自動化以及用戶行為模擬等對抗技術。例如,Selenium和Puppeteer等工具能夠模擬真實瀏覽器環境,執行JavaScript并渲染頁面,而機器學習算法則用于識別各類驗證碼。
這種持續升級的攻防關系,某種程度上推動了雙方技術的不斷創新與進步。對于數據分析工作而言,理解這種技術演進對于構建穩定的數據獲取渠道至關重要。
常見的Python爬蟲庫介紹
為了應對不同的爬取需求和反爬挑戰,Python生態系統提供了多種爬蟲相關的庫。以下是一些最常用的工具:
| 庫名 | 特點 | 適用場景 |
|---|---|---|
| Requests | 簡單易用的HTTP庫 | 基礎網頁獲取 |
| BeautifulSoup | HTML/XML解析器 | 靜態網頁內容提取 |
| Scrapy | 全功能爬蟲框架 | 大型爬蟲項目 |
| Selenium | 瀏覽器自動化工具 | 需要JavaScript渲染的網頁 |
| Pyppeteer | Puppeteer的Python版本 | 復雜的動態網頁 |
| lxml | 高效的XML/HTML解析器 | 需要高性能解析的場景 |
| PyQuery | 類jQuery語法的解析庫 | 熟悉jQuery的開發者 |
| aiohttp | 異步HTTP客戶端/服務器 | 高并發爬蟲 |
掌握了這些工具后,我們就能應對各種網頁爬取的需求。爬蟲技術的應用場景也非常廣泛。
爬蟲的應用場景
爬蟲技術不僅僅是一種技術能力,更是解決各種數據獲取需求的實用工具。以下是一些常見的應用場景:
- 數據分析與商業智能: 收集市場數據、競品情報
- 搜索引擎: 建立網頁索引和排名
- 學術研究: 獲取大量研究數據
- 內容聚合: 新聞、價格比較等聚合服務
- 社交媒體監測: 輿情分析、品牌監控
- 機器學習訓練數據: 為AI模型提供訓練數據集
結語
Python爬蟲技術為我們提供了一種強大的工具,可以自動化獲取互聯網上的各種信息。在掌握基礎知識后,你可以創建從簡單到復雜的各種爬蟲程序,解決數據收集的需求。
在接下來的系列文章中,我們將深入探討各種爬蟲技術,從HTML結構的基本分析開始,逐步學習如何處理不同類型的網站、如何應對各種反爬措施,以及如何構建高效的大規模爬蟲系統。
記住,強大的技術需要負責任地使用。合法合規的爬蟲行為不僅能幫助你獲取所需的數據,也能維護互聯網的健康生態。
下一篇:【Python爬蟲詳解】第二篇:HTML結構的基本分析


)




 browserscan檢測原理逆向分析)
 導入幾何數據)





)


)

