本教程展示了 ES|QL 語法的示例。請參考 Query DSL 版本,以獲得等效的 Query DSL 語法示例。
這是一個使用 ES|QL 進行全文搜索和語義搜索基礎知識的實踐介紹。
有關 ES|QL 中所有搜索功能的概述,請參考《使用 ES|QL 進行搜索》。
在這個場景中,我們為一個烹飪博客實現搜索功能。該博客包含各種屬性的食譜,包括文本內容、分類數據和數字評分。
安裝
如果你還沒有安裝好自己的 Elasticsearch 及 Kibana,請參考如下的文章來進行安裝。你可以選擇 Elastic Stack 8.x 的安裝步驟來進行安裝:
-
如何在 Linux,MacOS 及 Windows 上進行安裝 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安裝 Elastic 棧中的 Kibana
如果你想使用 docker 來進行一鍵安裝,請參考文章 “使用 start-local 腳本在本地運行 Elasticsearch”。
運行 ES|QL 查詢
在本教程中,你將看到以下格式的 ES|QL 示例:
FROM cooking_blog
| WHERE description:"fluffy pancakes"
| LIMIT 1000如果你想在 Dev Tools 控制臺中運行這些查詢,你需要使用以下語法:
POST /_query?format=txt
{"query": """FROM cooking_blog| WHERE description:"fluffy pancakes"| LIMIT 1000"""
}如果你更喜歡使用你最喜歡的編程語言,請參考客戶端庫,以獲取官方和社區支持的客戶端列表。
步驟 1:創建索引
創建 cooking_blog 索引以開始:
PUT /cooking_blog現在為索引定義映射:
PUT /cooking_blog/_mapping
{"properties": {"title": {"type": "text","analyzer": "standard", /* 1 */"fields": { /* 2 */"keyword": {"type": "keyword","ignore_above": 256 /* 3 */}}},"description": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"author": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"date": {"type": "date","format": "yyyy-MM-dd"},"category": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"tags": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"rating": {"type": "float"}}
}- 如果未指定 analyzer,文本字段默認使用 standard analyzer。這里包含它是為了演示目的。
- 這里使用 multi-fields 將文本字段同時索引為 text 和 keyword 數據類型。這使得在同一個字段上既能進行全文搜索,也能進行精確匹配 / 過濾。注意,如果使用動態映射,這些 multi-fields 會自動創建。
- ignore_above 參數會防止在 keyword 字段中索引長度超過 256 個字符的值。同樣,這是默認值,這里包含它是為了演示目的。它有助于節省磁盤空間,并避免 Lucene 的 term 字節長度限制所帶來的潛在問題。
提示:全文搜索依賴于文本分析。文本分析會對文本數據進行規范化和標準化處理,從而可以高效地存儲到倒排索引中,并實現近實時搜索。分析會在索引時和搜索時同時進行。本教程不會詳細介紹分析過程,但了解文本是如何被處理的對于創建高效的搜索查詢非常重要。
步驟 2:向索引添加示例博客文章
現在你需要使用 Bulk API 索引一些示例博客文章。注意,文本字段會在索引時進行分析,并生成 multi-fields。
POST /cooking_blog/_bulk?refresh=wait_for
{"index":{"_id":"1"}}
{"title":"Perfect Pancakes: A Fluffy Breakfast Delight","description":"Learn the secrets to making the fluffiest pancakes, so amazing you won't believe your tastebuds. This recipe uses buttermilk and a special folding technique to create light, airy pancakes that are perfect for lazy Sunday mornings.","author":"Maria Rodriguez","date":"2023-05-01","category":"Breakfast","tags":["pancakes","breakfast","easy recipes"],"rating":4.8}
{"index":{"_id":"2"}}
{"title":"Spicy Thai Green Curry: A Vegetarian Adventure","description":"Dive into the flavors of Thailand with this vibrant green curry. Packed with vegetables and aromatic herbs, this dish is both healthy and satisfying. Don't worry about the heat - you can easily adjust the spice level to your liking.","author":"Liam Chen","date":"2023-05-05","category":"Main Course","tags":["thai","vegetarian","curry","spicy"],"rating":4.6}
{"index":{"_id":"3"}}
{"title":"Classic Beef Stroganoff: A Creamy Comfort Food","description":"Indulge in this rich and creamy beef stroganoff. Tender strips of beef in a savory mushroom sauce, served over a bed of egg noodles. It's the ultimate comfort food for chilly evenings.","author":"Emma Watson","date":"2023-05-10","category":"Main Course","tags":["beef","pasta","comfort food"],"rating":4.7}
{"index":{"_id":"4"}}
{"title":"Vegan Chocolate Avocado Mousse","description":"Discover the magic of avocado in this rich, vegan chocolate mousse. Creamy, indulgent, and secretly healthy, it's the perfect guilt-free dessert for chocolate lovers.","author":"Alex Green","date":"2023-05-15","category":"Dessert","tags":["vegan","chocolate","avocado","healthy dessert"],"rating":4.5}
{"index":{"_id":"5"}}
{"title":"Crispy Oven-Fried Chicken","description":"Get that perfect crunch without the deep fryer! This oven-fried chicken recipe delivers crispy, juicy results every time. A healthier take on the classic comfort food.","author":"Maria Rodriguez","date":"2023-05-20","category":"Main Course","tags":["chicken","oven-fried","healthy"],"rating":4.9}步驟 3:執行基本的全文搜索
全文搜索涉及在一個或多個文檔字段上執行基于文本的查詢。這些查詢會根據文檔內容與搜索詞的匹配程度為每個匹配的文檔計算相關性評分。Elasticsearch 提供了多種查詢類型,每種類型都有其自己的文本匹配方式和相關性評分機制。
ES|QL 提供兩種方式來執行全文搜索:
- 完整 match 函數語法: match(field, "search terms")
- 使用 match 運算符的簡潔語法: field::"search terms"
兩種方式是等效的,可以互換使用。簡潔語法更簡潔,而函數語法則允許更多配置選項。為了簡潔,我們將在大多數示例中使用簡潔語法。
有關函數語法可用的高級參數,請參考 match 函數參考文檔。
基本全文查詢
以下是在 description 字段中搜索 "fluffy pancakes" 的方法:
FROM cooking_blog /* 1 */
| WHERE description:"fluffy pancakes" /* 2 */
| LIMIT 1000 /* 3 */- 指定要搜索的索引
- 全文搜索默認使用 OR 邏輯
- 返回最多 1000 條結果
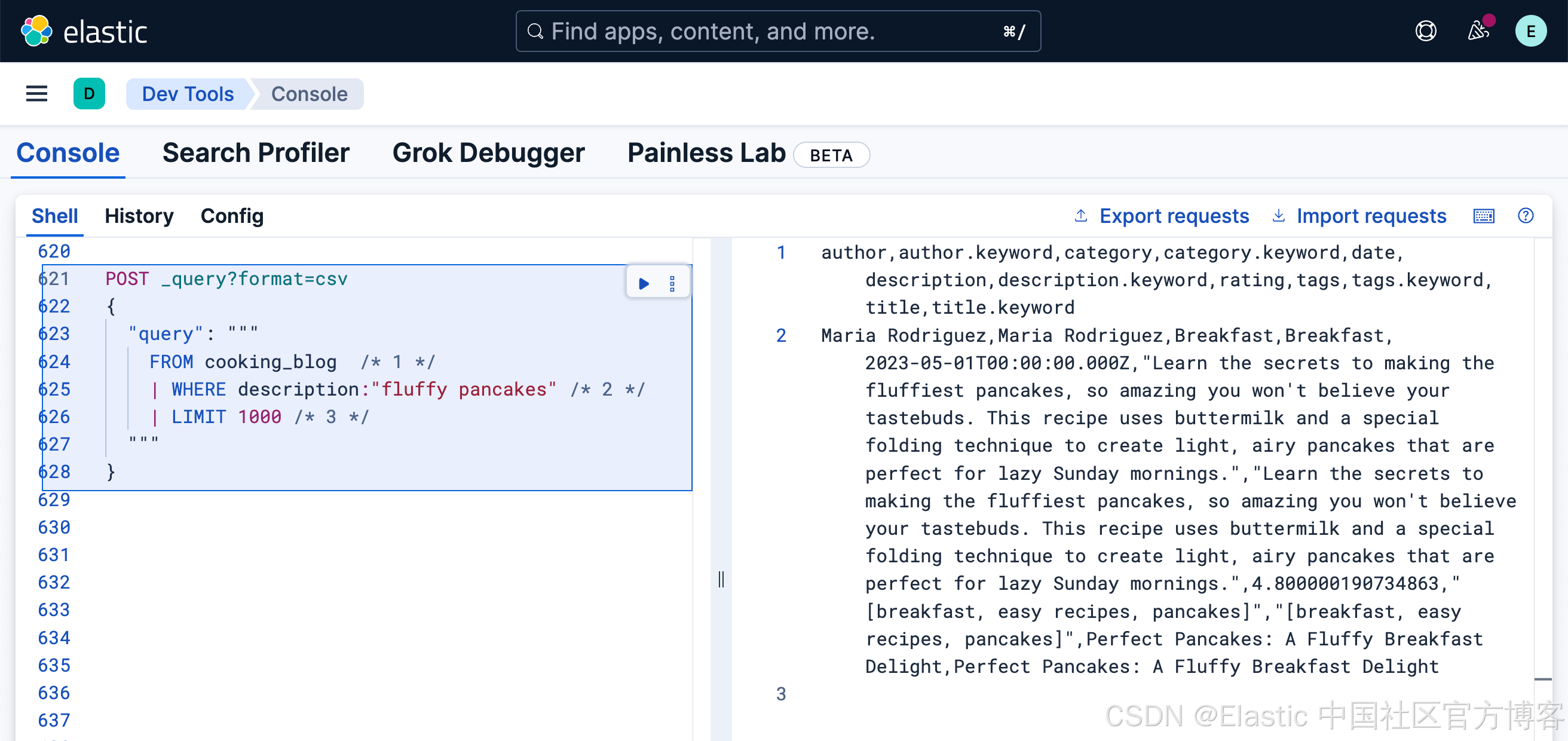
注意:結果的排序不是按相關性,因為我們尚未請求 _score 元數據字段。我們將在下一節中介紹相關性評分。
默認情況下,就像 Query DSL 的 match 查詢一樣,ES|QL 在詞項之間使用 OR 邏輯。這意味著它會匹配在 description 字段中包含 "fluffy" 或 "pancakes",或兩者都有的文檔。
提示:你可以使用 KEEP 命令控制響應中包含哪些字段:
FROM cooking_blog | WHERE description:"fluffy pancakes" | KEEP title, description, rating | LIMIT 1000更多有關 ES|QL 的查閱,請閱讀 “Elasticsearch:ES|QL 查詢展示”。
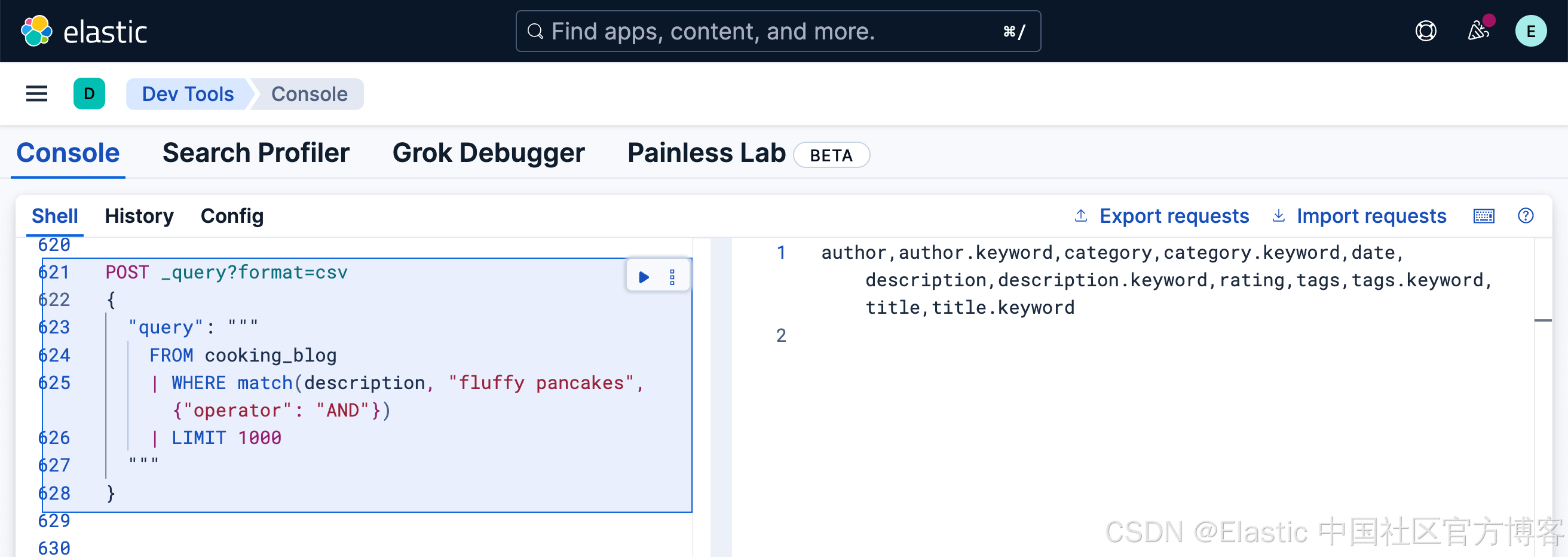
在匹配查詢中要求所有詞項
有時你需要確保所有搜索詞都出現在匹配的文檔中。以下是使用函數語法和 operator 參數實現這一點的方法:
FROM cooking_blog
| WHERE match(description, "fluffy pancakes", {"operator": "AND"})
| LIMIT 1000POST _query?format=csv
{"query": """FROM cooking_blog| WHERE match(description, "fluffy pancakes", {"operator": "AND"}) | LIMIT 1000"""
}
由于沒有文檔在 description 中同時包含 "fluffy" 和 "pancakes",因此這個更嚴格的搜索在我們的示例數據中返回零條結果。
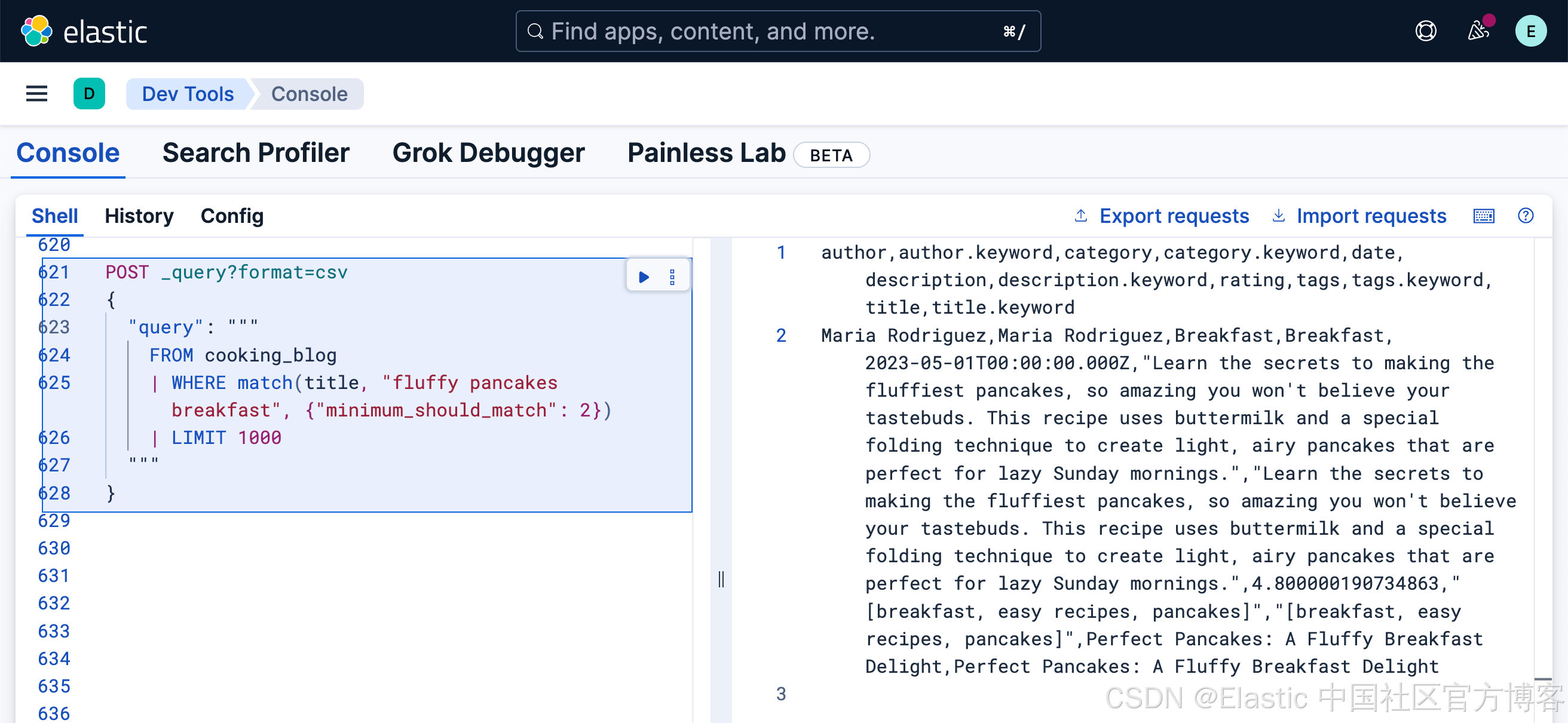
指定匹配的最小詞項數
有時,要求所有詞項匹配過于嚴格,而默認的 OR 行為又過于寬松。你可以指定必須匹配的最小詞項數:
FROM cooking_blog
| WHERE match(title, "fluffy pancakes breakfast", {"minimum_should_match": 2})
| LIMIT 1000此查詢搜索 title 字段,要求至少匹配 3 個詞項中的 2 個:"fluffy"、"pancakes" 或 "breakfast"。
步驟 4:語義搜索和混合搜索
索引語義內容
Elasticsearch 允許你根據文本的意義進行語義搜索,而不僅僅是依賴特定關鍵詞的存在。當你希望找到與給定查詢在概念上相似的文檔時,即使它們不包含精確的搜索詞,也非常有用。
當你的映射中包含 semantic_text 類型的字段時,ES|QL 支持語義搜索。這個示例映射更新添加了一個名為 semantic_description 的新字段,類型為 semantic_text:
PUT /cooking_blog/_mapping
{"properties": {"semantic_description": {"type": "semantic_text"}}
}接下來,將包含內容的文檔索引到新字段中:
POST /cooking_blog/_doc
{"title": "Mediterranean Quinoa Bowl","semantic_description": "A protein-rich bowl with quinoa, chickpeas, fresh vegetables, and herbs. This nutritious Mediterranean-inspired dish is easy to prepare and perfect for a quick, healthy dinner.","author": "Jamie Oliver","date": "2023-06-01","category": "Main Course","tags": ["vegetarian", "healthy", "mediterranean", "quinoa"],"rating": 4.7
}注意:在上面,我們并沒有指名是使用什么方法進行的向量化。在默認的情況下,它使用的是 ELSER 模型。你需要啟動 ELSER。詳細的部署,請參考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR”。
執行語義搜索
一旦文檔被底層模型處理并運行在推理端點上,你就可以執行語義搜索。以下是針對 semantic_description 字段的一個自然語言查詢示例:
FROM cooking_blog
| WHERE semantic_description:"What are some easy to prepare but nutritious plant-based meals?"
| LIMIT 5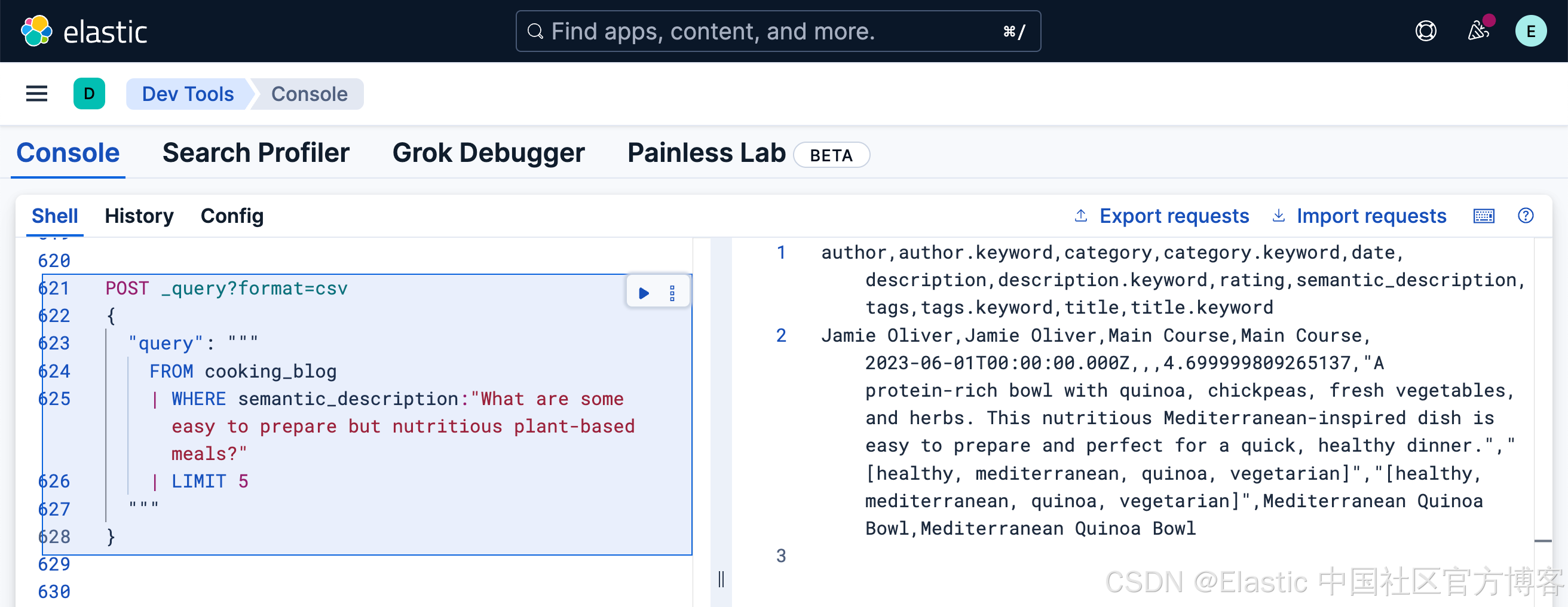
執行混合搜索
你可以將全文搜索和語義查詢結合起來。在這個示例中,我們結合了全文搜索和語義搜索,并使用了自定義權重:
FROM cooking_blog METADATA _score
| WHERE match(semantic_description, "easy to prepare vegetarian meals", { "boost": 0.75 })OR match(tags, "vegetarian", { "boost": 0.25 })
| SORT _score DESC
| LIMIT 5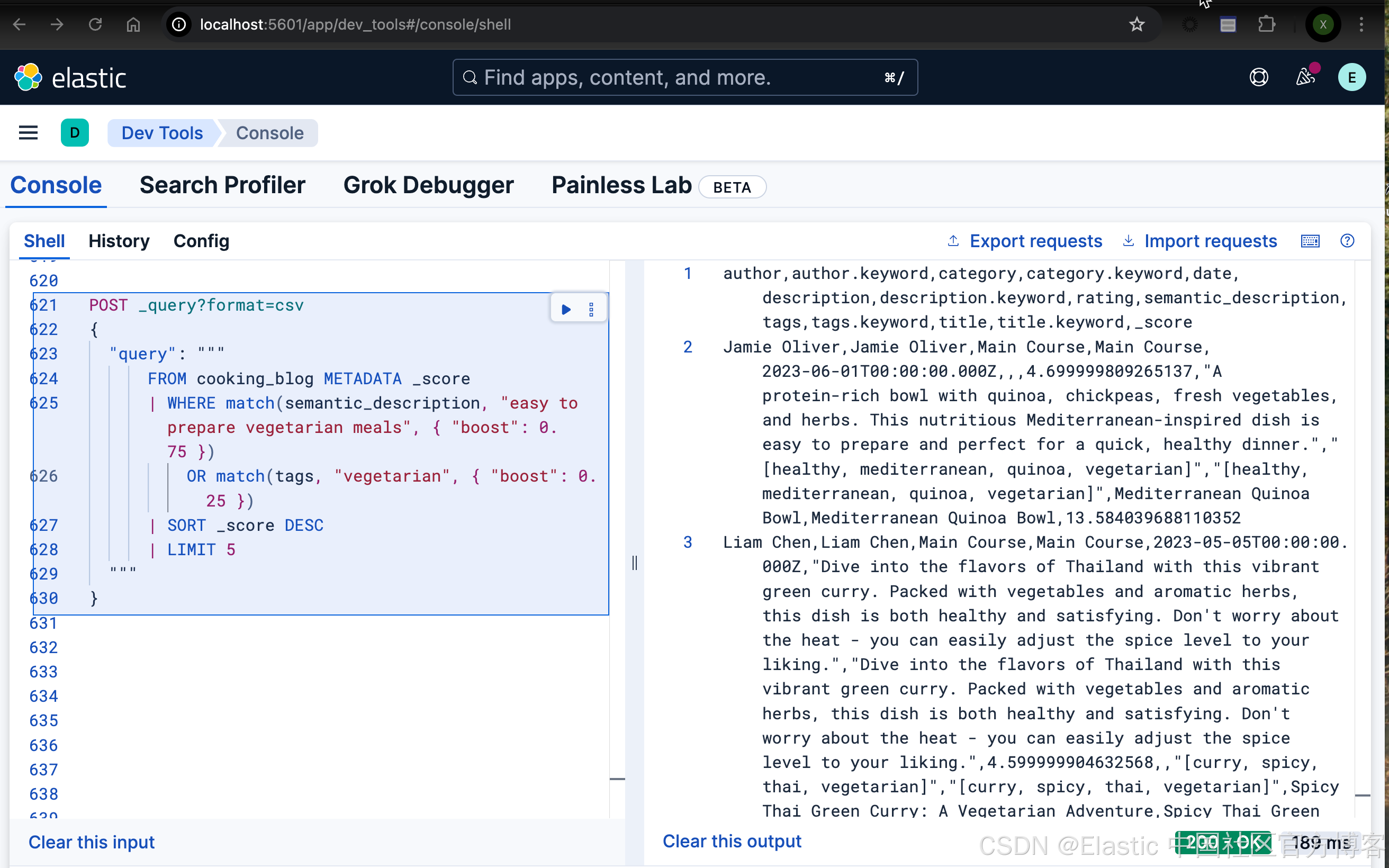
步驟 5:一次搜索多個字段
當用戶輸入搜索查詢時,他們通常不知道(或不關心)他們的搜索詞是否出現在特定字段中。ES|QL 提供了同時在多個字段中進行搜索的方法:
FROM cooking_blog
| WHERE title:"vegetarian curry" OR description:"vegetarian curry" OR tags:"vegetarian curry"
| LIMIT 1000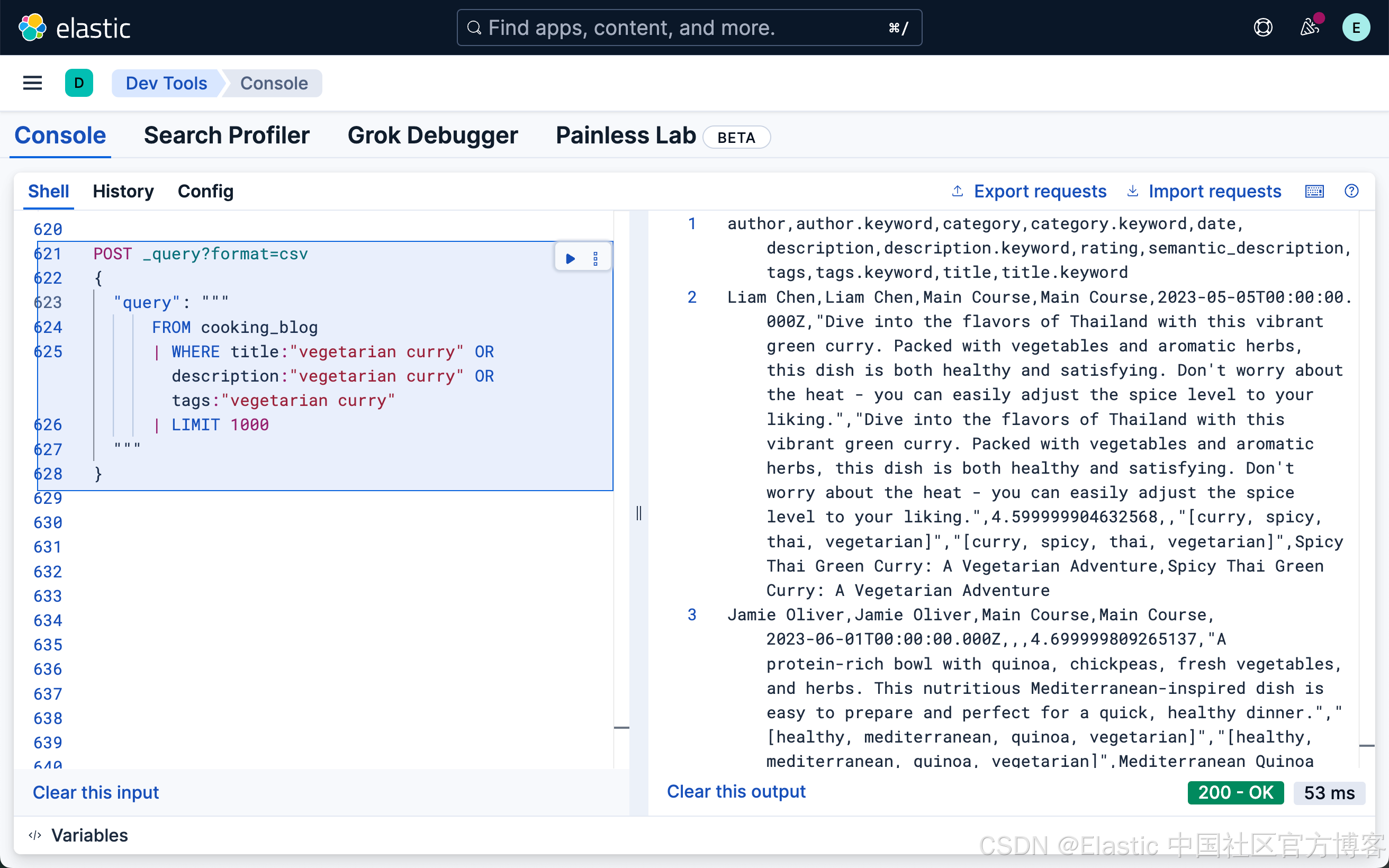
這個查詢在 title、description 和 tags 字段中搜索 "vegetarian curry"。每個字段的重要性相同。
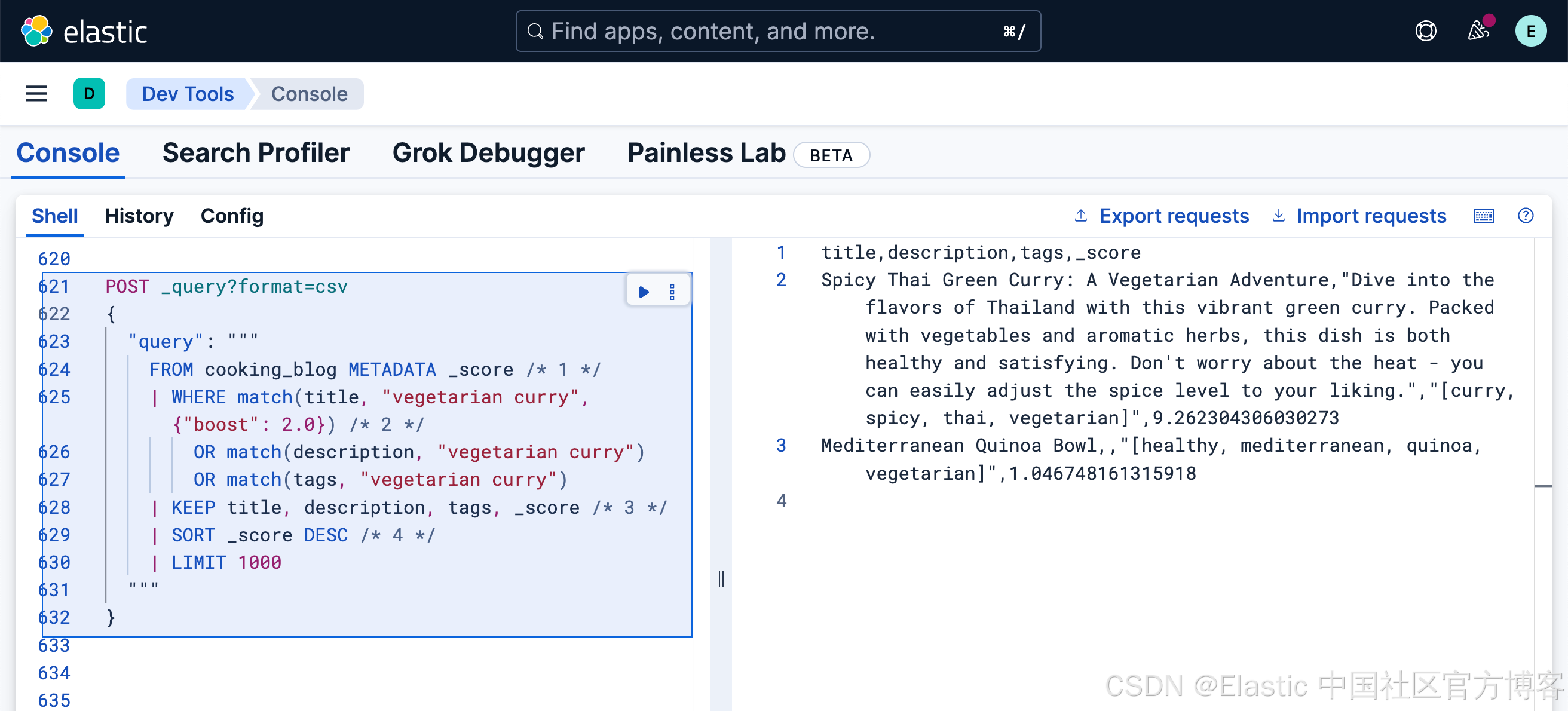
然而,在許多情況下,某些字段(如標題)中的匹配可能比其他字段更相關。我們可以通過評分來調整每個字段的重要性:
FROM cooking_blog METADATA _score /* 1 */
| WHERE match(title, "vegetarian curry", {"boost": 2.0}) /* 2 */OR match(description, "vegetarian curry") OR match(tags, "vegetarian curry")
| KEEP title, description, tags, _score /* 3 */
| SORT _score DESC /* 4 */
| LIMIT 1000- 請求 _score 元數據以獲取基于相關性的結果
- 標題匹配的重要性是其他字段的兩倍
- 在結果中包含相關性評分
- 必須明確按 _score 排序才能查看基于相關性的結果
提示:在 ES|QL 中使用相關性評分時,理解 _score 非常重要。如果你在查詢中不包含 METADATA _score,你將無法在結果中看到相關性評分。這意味著你將無法根據相關性進行排序或基于相關性評分進行過濾。
當你包含 METADATA _score 時,WHERE 條件中的搜索功能會貢獻相關性評分。過濾操作(如范圍條件和精確匹配)不會影響評分。
如果你想要最相關的結果排在前面,必須通過顯式使用 SORT _score DESC 或 SORT _score ASC 來按 _score 排序。
步驟 6:過濾和查找精確匹配
過濾允許你根據精確標準縮小搜索結果的范圍。與全文搜索不同,過濾是二元的(是/否),并且不會影響相關性評分。過濾執行比查詢更快,因為排除的結果不需要進行評分。
FROM cooking_blog
| WHERE category.keyword == "Breakfast"
| KEEP title, author, rating, tags
| SORT rating DESC
| LIMIT 1000
使用 keyword 字段進行精確匹配(區分大小寫)。
注意:這里使用了 category.keyword。它指的是 category 字段的 keyword 多字段,確保進行精確的、區分大小寫的匹配。
在日期范圍內搜索帖子
通常,用戶希望找到在特定時間范圍內發布的內容:
FROM cooking_blog
| WHERE date >= "2023-05-01" AND date <= "2023-05-31"
| KEEP title, author, date, rating
| LIMIT 1000包含日期范圍過濾器。
查找精確匹配
有時,用戶希望搜索精確的術語,以消除搜索結果中的歧義:
FROM cooking_blog
| WHERE author.keyword == "Maria Rodriguez"
| KEEP title, author, rating, tags
| SORT rating DESC
| LIMIT 1000在 author 字段上進行精確匹配。
與 Query DSL 中的 term 查詢類似,這種查詢沒有靈活性,并且區分大小寫。
步驟 7:組合多個搜索條件
復雜的搜索通常需要組合多個搜索條件:
FROM cooking_blog METADATA _score
| WHERE rating >= 4.5 AND NOT category.keyword == "Dessert" AND (title:"curry spicy" OR description:"curry spicy")
| SORT _score DESC
| KEEP title, author, rating, tags, description
| LIMIT 1000將相關性評分與自定義條件結合
對于更復雜的相關性評分和組合條件,你可以使用 EVAL 命令來計算自定義評分:
FROM cooking_blog METADATA _score
| WHERE NOT category.keyword == "Dessert"
| EVAL tags_concat = MV_CONCAT(tags.keyword, ",") /* 1 */
| WHERE tags_concat LIKE "*vegetarian*" AND rating >= 4.5 /* 2 */
| WHERE match(title, "curry spicy", {"boost": 2.0}) OR match(description, "curry spicy") /* 3 */
| EVAL category_boost = CASE(category.keyword == "Main Course", 1.0, 0.0) /* 4 */
| EVAL date_boost = CASE(DATE_DIFF("month", date, NOW()) <= 1, 0.5, 0.0) /* 5 */
| EVAL custom_score = _score + category_boost + date_boost /* 6 */
| WHERE custom_score > 0 /* 7 */
| SORT custom_score DESC
| LIMIT 1000- 將多值字段轉換為字符串
- 通配符模式匹配
- 使用全文本功能,將更新 _score 元數據字段
- 條件加權
- 加權最近內容
- 組合評分
- 基于自定義評分進行過濾










科普)






—— 49.字符異位詞分組題解)

