Connectionist Temporal Classification|CTC
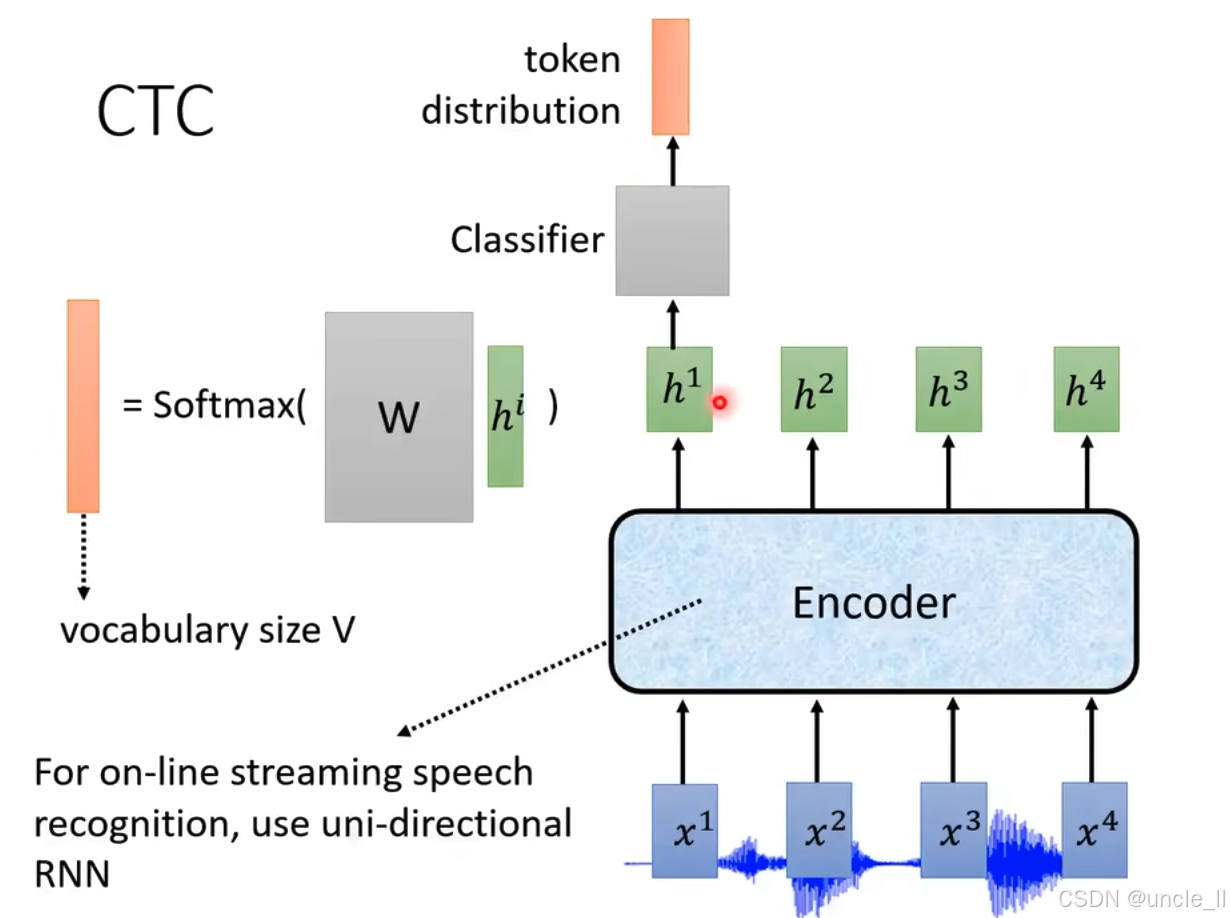
基于連接主義時間分類(CTC)的語音識別架構,具體描述如下:
- 輸入層:底部的 x 1 , x 2 , x 3 , x 4 x^1, x^2, x^3, x^4 x1,x2,x3,x4代表輸入的語音信號分幀數據,是語音識別的原始輸入。
- 編碼器(Encoder):淺藍色模塊表示編碼器(如循環神經網絡 RNN),負責對輸入的語音幀 x i x^i xi 進行特征提取和時序建模,輸出隱藏狀態 h 1 , h 2 , h 3 , h 4 h^1, h^2, h^3, h^4 h1,h2,h3,h4。
- 分類器(Classifier):每個隱藏狀態 h i h^i hi輸入到分類器(灰色模塊),通過矩陣 W W W 線性變換后,再經過 Softmax 函數,生成詞匯表 V V V 大小的概率分布( token?distribution \text{token distribution} token?distribution),表示每個時刻對應詞匯表中各 token 的預測概率。
- 在線流式處理說明:圖下方文字 “For on - line streaming speech recognition, use uni - directional RNN” 指出,對于在線流式語音識別,采用單向 RNN,確保實時處理,不依賴未來幀的數據。
該架構通過 CTC 解決語音幀與文本標簽的對齊問題,適用于端到端的語音識別任務,特別是需要實時處理的流式場景。
 介紹連接主義時間分類(CTC)的核心特性及處理規則:
介紹連接主義時間分類(CTC)的核心特性及處理規則:
- 輸入輸出特性:
- 輸入 T T T 個聲學特征,輸出 T T T 個 tokens(忽略下采樣),即輸入與輸出時間步一一對應。
- 輸出處理規則:
- 輸出 tokens 包含空白符 ? \phi ?,最終需通過“合并重復 tokens,去除 ( \phi )”得到最終結果。
- 示例說明:
- 英文示例:
- ? ? d d ? e ? e ? p p \phi \ \phi \ d \ d \ \phi \ e \ \phi \ e \ \phi \ p \ p ????d?d???e???e???p?p:合并重復的 d d d、 e e e、 p p p,去除 ? \phi ?,得到 d e e p d \ e \ e \ p d?e?e?p。
- ? ? d d ? e e e e ? p p \phi \ \phi \ d \ d \ \phi \ e \ e \ e \ e \ \phi \ p \ p ????d?d???e?e?e?e???p?p:合并重復的 d d d、 e e e、 p p p,去除 ? \phi ?,得到 d e p d \ e \ p d?e?p。
- 中文示例:
- “好 好 棒 棒 棒 棒 棒”:合并重復的“好”“棒”,得到“好 棒”。
- “好 ? \phi ? 棒 ? \phi ? 棒 ? ? \phi \ \phi ???”:合并重復的“棒”,去除 ? \phi ?,得到“好 棒 棒”。
- 英文示例:
通過這些規則,CTC 解決了語音幀與文本標簽對齊的難題,適用于語音識別等序列建模任務。
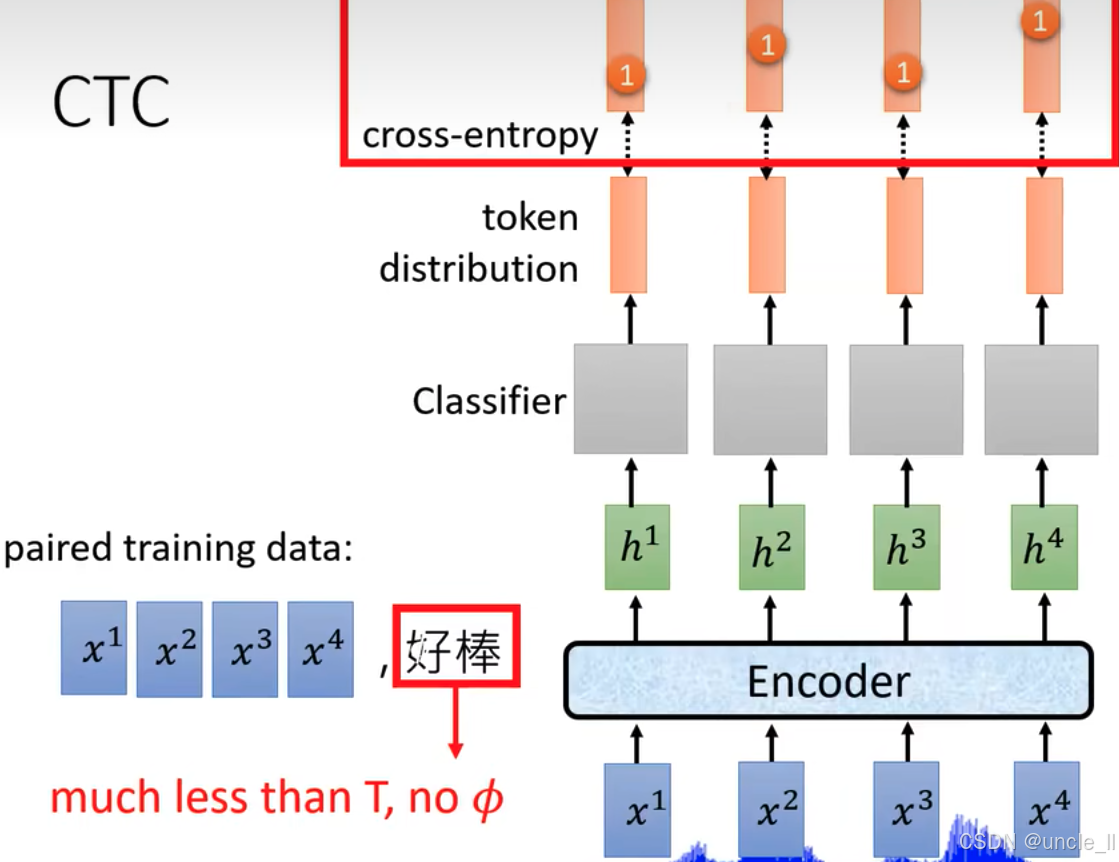
展示連接主義時間分類(CTC)在訓練中的應用,具體內容如下:
- 左側訓練數據:標注為 “paired training data”,輸入為 x 1 x^1 x1到 x 4 x^4 x4的聲學特征,對應標簽為 “好棒”。紅色文字 “much less than T T T, no ? \phi ?” 表明標簽長度遠小于輸入時間步 T T T,且不含空白符 ? \phi ?,體現了 CTC 處理輸入輸出長度不對齊的特性。
- 右側模型架構:
- Encoder(編碼器):處理輸入$ x^1$到 x 4 x^4 x4,輸出隱藏狀態 h 1 h^1 h1到 h 4 h^4 h4。
- Classifier(分類器):將每個 h i h^i hi轉換為 token?distribution \text{token distribution} token?distribution(令牌分布),表示每個時間步對詞匯單元的預測概率。
- 交叉熵損失(cross - entropy):圖中紅色框標注,每個時間步的輸出通過交叉熵與目標標簽比較,指導模型訓練。盡管標簽長度短于輸入時間步,CTC 仍能通過引入空白符 ? \phi ?、合并重復令牌等機制,解決輸入與輸出的對齊問題,實現端到端的訓練。
該圖直觀呈現了 CTC 在語音識別等序列任務中,處理輸入輸出不對齊數據的訓練過程與架構。

窮舉所有的alignment作為訓練數據
訓練原理:CTC 在訓練時考慮所有可能的對齊路徑(即不同的 ? 插入方式),對這些路徑的概率進行求和,通過最大化目標標簽的總概率來更新模型參數。這種方式解決了語音識別等任務中輸入(如聲學特征)與輸出(如文本標簽)長度不一致的難題,無需精確對齊每一個時間步,只需利用插入 ? 的多種對齊方式進行訓練,使模型學習到更魯棒的序列映射關系。
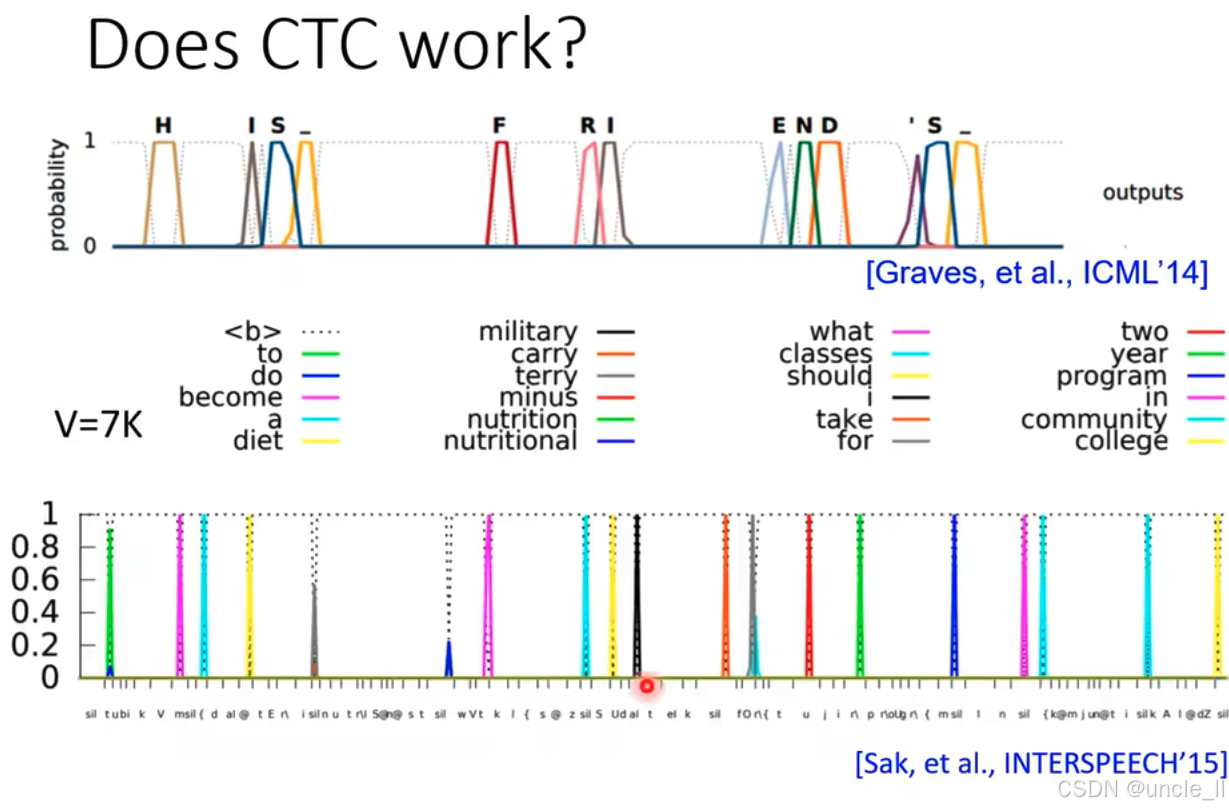
整體通過展示 CTC 模型在語音識別任務中對目標 token / 單詞的高概率預測,直觀證明了 CTC 在序列建模中有效,能夠準確捕捉并輸出目標序列。

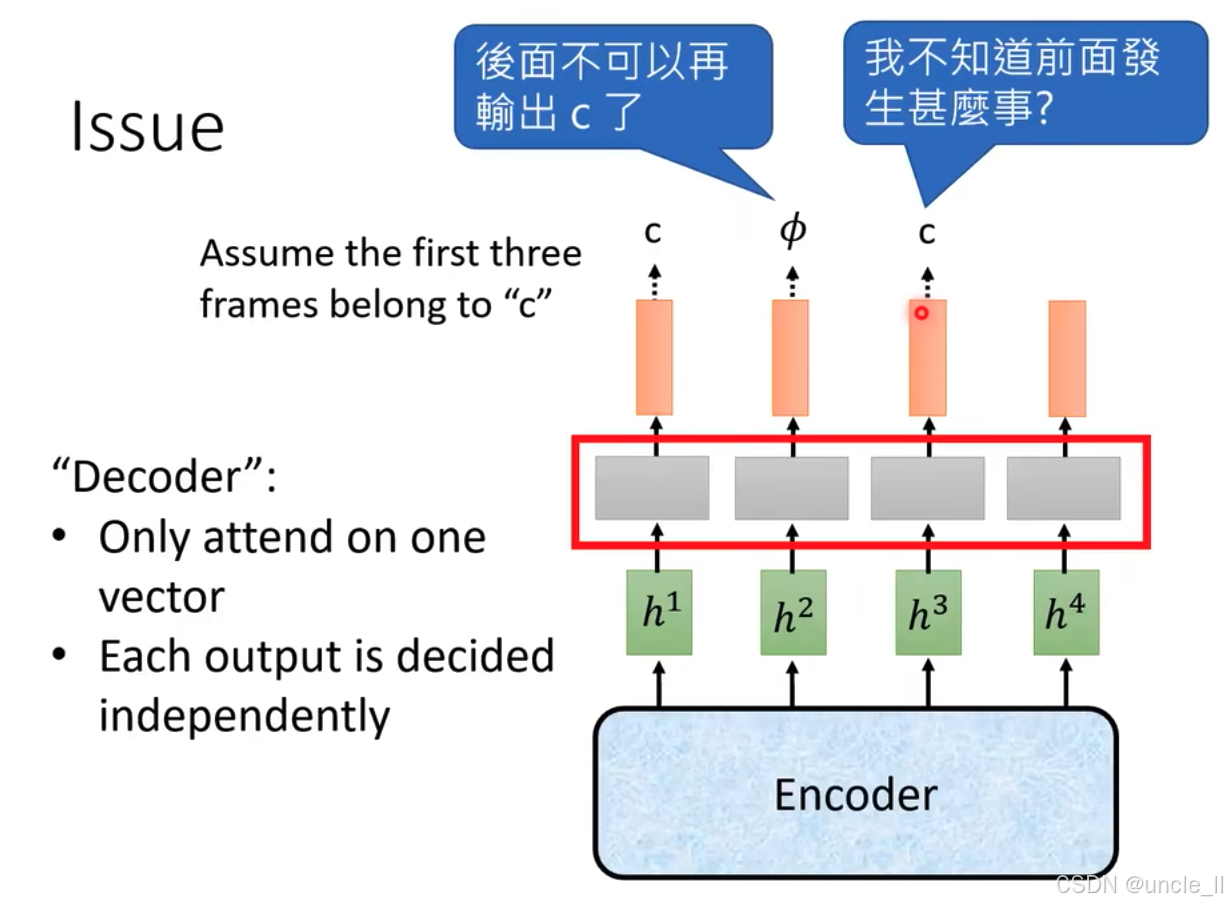
CTC 模型中解碼器(Decoder)存在的問題具體如下:
-
假設與模型結構:
- 假設前三個幀對應字符 “c”。圖中下方的 “Encoder” 生成隱藏狀態 h 1 , h 2 , h 3 , h 4 h^1, h^2, h^3, h^4 h1,h2,h3,h4,傳遞給上方的解碼器(灰色模塊)。
- 解碼器特性標注為 “Only attend on one vector”(僅關注一個向量)和 “Each output is decided independently”(每個輸出獨立決定),即每次僅基于單個輸入向量獨立生成輸出,不考慮前后文依賴。
-
輸出問題示例:
- 輸出序列中出現 “c - ? \phi ? - c”。第一個對話框 “後面不可以再輸出 c 了” 表明,由于前三個幀已對應 “c”,后續不應再輸出 “c”,但解碼器獨立決策未考慮此約束。
- 第二個對話框 “我不知道前面發生甚麼事?” 體現解碼器獨立生成輸出,缺乏對前文信息的記憶與關聯,導致重復或不合理輸出(如再次輸出 “c”)。
綜上, CTC 解碼器因獨立輸出、不考慮前后文依賴而產生的問題,即無法利用序列的歷史信息進行全局優化決策。



















)