推薦原文 見:http://docs.xupengboo.top/bigdata/di/sqoop.html
Sqoop(SQL-to-Hadoop) 是 Apache 開源的工具,專門用于在 Hadoop 生態系統(如 HDFS、Hive、HBase) 和 關系型數據庫(如 MySQL、Oracle) 之間高效傳輸批量數據。專注于關系型數據庫 ? Hadoop 。
Apache Sqoop 項目已于 2021 年 6 月停止維護,并被移至 Apache Attic。這意味著官方不再對 Sqoop 進行更新或提供支持。Apache Attic 是 Apache 軟件基金會(ASF)設立的一個存儲庫,專門用于存放那些已停止活躍開發或維護的項目。
官方地址:https://sqoop.apache.org/
下載地址:https://archive.apache.org/dist/sqoop/
一、安裝 Hadoop 客戶端
由于 Sqoop 獨立安裝到一臺服務上面,所以需要在獨立服務器上安裝 Hadoop 的客戶端。
- 配置
/etc/hosts文件。
192.168.10.68 vm-01
192.168.10.69 vm-02
192.168.10.70 vm-03
- 下載以及安裝 Hadoop 客戶端。(按照之前 Hadoop 集群安裝 章節部署的集群操作)。
cd /opt
# 選擇合適的hadoop版本,要與Hadoop集群匹配
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
# 解壓
tar -xzvf hadoop-3.2.4.tar.gz
# /usr/local通常被用作本地軟件安裝目錄。
mv hadoop-3.2.4 /usr/local/hadoop
- 配置相關文件:
core-site.xml:
<configuration><property><name>fs.defaultFS</name><value>hdfs://vm-01:9000</value> <!-- 這里是主節點的 IP 地址, 此處為 vm-01 的 IP 地址 --></property>
</configuration>
hdfs-site.xml:
<configuration><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>vm-01:8020</value></property>
</configuration>
yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties --><!-- YARN ResourceManager 地址 --><property><name>yarn.resourcemanager.address</name><value>vm-01:8032</value></property>
</configuration>
mapred-site.xml:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value> <!-- 使用 YARN 作為 MapReduce 框架 --></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property>
</configuration>
- 執行命令校驗:
hadoop fs -ls / # 應返回遠程 HDFS 根目錄列表# 注意:我們并不是要創建一個hadoop子節點,僅僅是個客戶端,所以不用啟動hadoop的start相關腳本,可通過jps查看。
二、Sqoop 部署
:::tip
注意:選擇 Sqoop 的版本需要與所使用的 Hadoop 版本相匹配,以確保兩者的兼容性和穩定性。不同版本的 Sqoop 依賴于特定版本的 Hadoop,因此在部署時需要注意兩者的對應關系。
:::
此處,已有的 hadoop 3.2.4,這是使用更穩定的版本: Sqoop 1.4.7。
- 下載 Sqoop 二進制包
curl -O -L https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz /opt
cd /opt
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoopvi /etc/profile
export SQOOP_HOME=/opt/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
- 配置 Sqoop
# 復制模板配置文件
cp $SQOOP_HOME/conf/sqoop-env-template.sh $SQOOP_HOME/conf/sqoop-env.sh
# 編輯 sqoop-env.sh,設置 Hadoop 路徑
vi sqoop-env.sh
# 配置hadoop公共庫和mapreduce的庫目錄
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
- 下載驅動(不同的數據庫,要給Sqoop不同的依賴驅動包)
cd $SQOOP_HOME/lib/
wget https://jdbc.postgresql.org/download/postgresql-42.7.3.jar
- 基本導入命令,例如:將 PostgreSQL 表中的數據導入到 HDFS 的指定目錄
# 測試檢查讀取表格數據
sqoop eval \--driver org.postgresql.Driver \--connect jdbc:postgresql://192.168.10.66:5432/postgres \--username "root" \--password "0818" \--query "SELECT * FROM table_name2 LIMIT 1"# 強制指定 HDFS 操作用戶身份
export HADOOP_USER_NAME=hadoopsqoop import \--verbose \--driver org.postgresql.Driver \--connect jdbc:postgresql://192.168.10.66:5432/postgres \--username "root" \--password "0818" \--table "table_name2" \--target-dir /user/sqoop \--delete-target-dir \-m 1
:::tip java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils 異常修復
# 拋出:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils 異常
# 解決辦法:添加 commons-lang-2.6 版本,3版本不支持。
cd $SQOOP_HOME/lib
wget https://repo1.maven.org/maven2/commons-lang/commons-lang/2.6/commons-lang-2.6.jar
:::
成功頁面 如下:
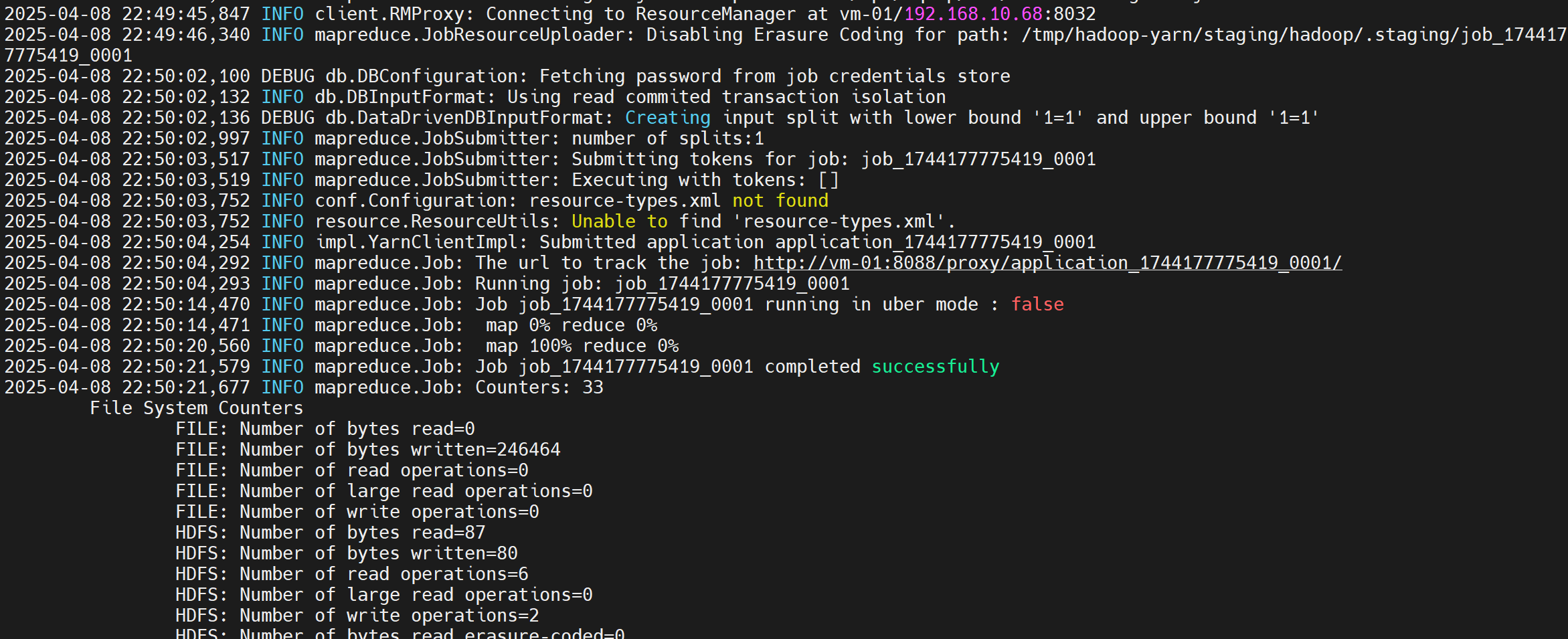
- 下載 hadoop 中的文件,查看數據:
# 將導入成功的數據下載下來
$ hdfs dfs -get /user/sqoop /opt/temp/
$ ls
data.csv sqoop
$ cat part-m-00000 # 數據內容
1,1,1,1,1
1,2,3,4,5
1,1,1,1,1
1,2,3,4,5
1,1,1,1,1
1,2,3,4,5
1,1,1,1,1
1,2,3,4,5
三、Sqoop 整體流程
-
生成代碼:Sqoop 根據目標數據庫表的結構,生成相應的 Java 類,用于序列化和反序列化數據。
-
編譯和打包:生成的 Java 類會被編譯并打包成一個可執行的 JAR 文件。
-
提交作業:Sqoop 將該 JAR 文件作為一個 MapReduce 作業提交給 YARN。
-
任務執行:YARN 根據集群的資源情況,分配資源并啟動 MapReduce 作業的各個任務(Mapper)。每個 Mapper 通過 JDBC 從 MySQL 中讀取數據,并將數據寫入 HDFS。








)
)
與非邏輯視圖(JSON、Excel、PDF、XML)詳解及示例)
-- 功能介紹)
)






