code:CVPR 2024
MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
[CVPR 2024] MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis - 知乎
?Abstract
我們提出了一個多實例生成(Multi-Instance Generation, MIG)任務,在一個圖像中同時生成具有不同控件的多個實例。給定一組預定義的坐標及其相應的描述,任務是確保生成的實例準確地位于指定位置,并且所有實例的屬性都符合其相應的描述。這擴大了當前單實例生成研究的范圍,將其提升到一個更通用和實用的維度。受分而治之思想的啟發,我們引入了一種名為多實例生成控制器(MIGC)的創新方法來解決MIG任務的挑戰。最初,我們將MIG任務分解為幾個子任務,每個子任務都涉及單個實例的著色。為了保證每個實例的精確著色,我們引入了一個實例增強注意機制。最后,我們聚合了所有陰影實例,以提供在穩定擴散(SD)中準確生成多個實例所需的信息。為了評估生成模型在MIG任務上的執行情況,我們提供了一個COCO-MIG基準以及一個評估管道。在提出的COCO-MIG基準以及各種常用基準上進行了大量實驗。評估結果說明了我們的模型在數量、位置、屬性和交互方面的卓越控制能力。
Introduction
在具有不同控件的一個圖像中同時生成多個實例的更實際的情況很少被探索。
Challenges in MIG.?MIG不僅要求實例遵守用戶給出的描述和布局,而且還確保所有實例之間的全局對齊。將這些信息直接納入SD常常導致失敗。一方面,當前的文本編碼器(如CLIP)難以區分每個單一屬性和包含多個屬性的提示。另一方面,穩定擴散中的Cross-Attention層缺乏對位置的控制能力,導致在指定區域內生成多個實例時存在困難。
Multi-Instance Generation Controller (MIGC)?將MIG分解為多個子任務,然后將這些子任務的結果組合在一起。雖然SD在MIG中的直接應用仍然是一個挑戰,但單實例生成中突出的SD能力可以促進這一任務。如圖
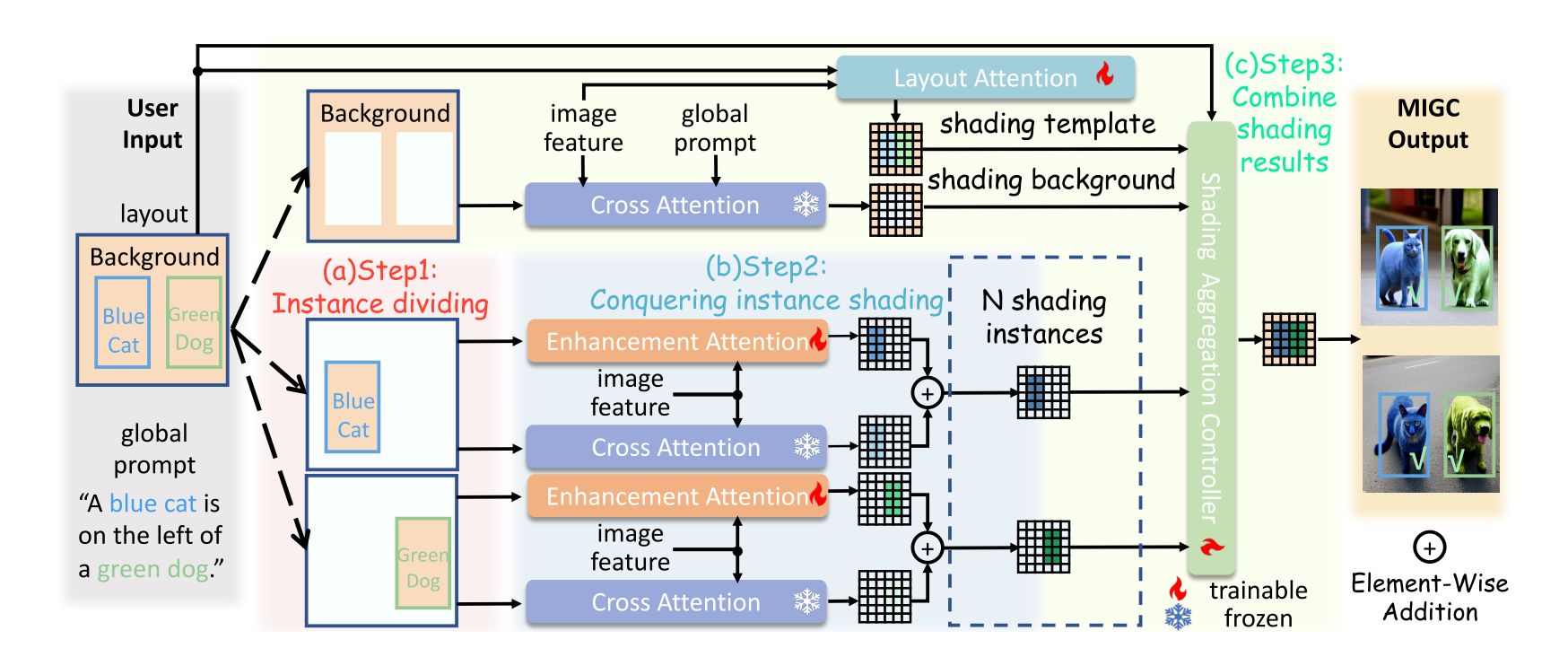
MIGC包括三個步驟:
1)Divide: MIGC僅在sd的Cross-Attention層中將mig分解為多個instanceshading子任務,加快每個子任務的分辨率,使生成的圖像更加和諧。
2)Conquer:MIGC使用增強注意層(Enhancement Attention Layer)來增強通過凍結的交叉注意(Cross-Attention)獲得的著色結果,確保每個實例的著色成功。
3)Combine:MIGC通過Layout Attention層獲得遮陽模板,然后將其與遮陽背景和遮陽實例一起輸入到遮陽聚合控制器中,從而獲得最終的遮陽結果。
Benchmark for MIG.?為了評估生成模型在MIG任務上的表現,提出了一個基于COCO數據集的COCOMIG基準,該基準要求生成模型同時實現對位置、屬性和數量的強控制。
貢獻:
1)為了促進視覺生成的發展,提出了MIG任務,以解決學術和工業領域的普遍挑戰。同時,提出了COCO-MIG基準來評估生成模型固有的MIG能力。
2)受分而治之原則的啟發,引入了一種新的MIG方法,通過改進MIG能力來增強預訓練的SD。
3)在三個基準上進行了大量的實驗,顯著超過了以前的SOTA方法。
Related work
Text-to-Image Generation
Layout-to-Image Generation
由于文本不能精確控制生成實例的位置。一些layout -to- image方法[6 Training-free layout control with cross-attention guidance.,32 Guided image synthesis via initial image editing in diffusion model.,34 Glide: Towards photorealistic image generation and editing with text-guided diffusion models,49 Boxdiff,61 Layoutdiffusion]擴展了預訓練的T2I模型,將布局信息整合到生成中,實現對實例位置的控制。
Method
Preliminaries
Stable diffusion?CLIP?text encoder
Attention layers.?R表示輸出殘差
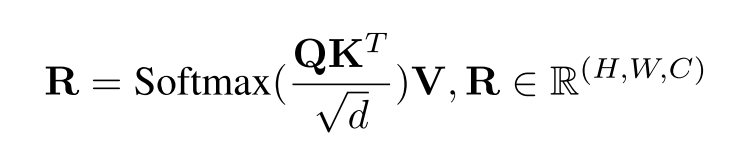
Overview
Problem Definition?在多實例生成(Multi-Instance Generation, MIG)中,用戶將給生成模型全局提示符P,實例布局邊界框B = {b1,…, bN},其中bi = [xi 1, yi 1, xi 2, yi 2],對應描述D = {d1,…,dn}。根據用戶提供的輸入,模型需要生成一個圖像I,其中框bi內的實例應遵循實例描述di,并確保所有實例的全局對齊。
Difficulties in MIG.?在處理多實例提示時,SD與屬性泄漏作斗爭,即1)文本泄漏。由于CLIP編碼器中使用了因果注意掩碼,后一個實例令牌可能會出現語義混淆。2)空間泄漏。交叉注意缺乏精確的位置控制,并且實例會影響彼此區域的生成。
Motivation.?分而治之是一個古老而明智的想法。它首先將一個復雜的任務分解成若干個較簡單的子任務,然后分別征服這些子任務,最后將子任務的解組合起來得到原任務的解。這個想法非常適用于米格戰斗機。例如,對于大多數T2I模型來說,MIG是一項復雜的任務,而單實例生成是一個更簡單的子任務,T2I模型可以很好地解決。基于這一思想,提出了我們的MIGC,它擴展了SD,具有更強的MIG能力。
Divide MIG into Instance Shading Subtasks
Instance shading subtasks in Cross-Attention space.?交叉注意是文本和圖像特征在SD中相互作用的唯一途徑,輸出決定了生成的內容,這看起來像是對圖像特征的著色操作。在這個觀點中,MIG任務可以定義為對圖像特征進行正確的多實例著色,subtask可以定義為找到滿足以下條件的單實例著色結果Ri:
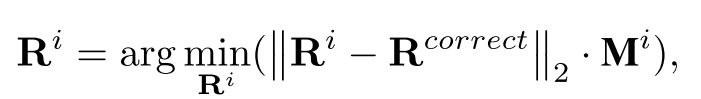
其中Rcorrect表示客觀存在的正確特征,Mi是根據框bi生成的實例掩碼,框區域內的值設為1,其余位置設為0。也就是說,每一個底紋實例在其對應的區域都應該有正確的文本語義。
每個子任務的目標是找到最優的實例特征著色結果Ri,使其在掩碼Mi(框內為1,其余為0)區域內盡可能接近客觀正確的特征Rcorrect,通過最小化L2范數實現
Two benefits of division in the Cross-Attention space.?
1)征服效率更高:對于N個實例生成,MIGC只在Cross-Attention層上征服N個子任務,而不是整個Unet網絡,效率更高;
2)更和諧地組合:與網絡最終輸出的組合相比,在中間層組合子任務增強了生成圖像的整體凝聚力。
Conquer Instance Shading
Shading stage 1: shading results of Cross-Attention.?
預訓練的交叉注意會注意到高注意權重的區域,并根據文本語義進行著色。如圖圖所示,MIGC使用被遮擋的Cross-Attention輸出作為第一個著色結果:
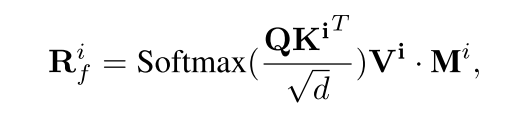
其中Ki和Vi由di的文本嵌入得到,Q由圖像特征映射得到。下標?f(代表“first stage”)
?Two issues of Cross-Attention shading results.?
1)實例合并。根據上述方程,對于具有相同描述的兩個實例,它們在Cross-Attention層會得到相同的K和V。如果它們的盒子很接近甚至重疊,網絡將很容易合并兩個實例;
2)實例丟失。從初始編輯方法可以看出,SD的初始噪聲在很大程度上決定了生成圖像的布局,即特定區域寧愿生成特定實例,也不愿生成特定實例。如果初始噪聲不傾向于根據方框bi中的描述di生成實例,則Ri f較弱,導致實例丟失。
Grounded phrase token for solving instance merge.?
為了識別具有相同描述但不同框的實例,MIGC將每個實例的文本標記擴展為文本和位置標記的組合。如圖圖(a)所示,MIGC首先將邊界框信息投影到傅里葉嵌入中,然后使用MLP層獲得位置令牌。MIGC將文本標記與位置標記連接起來以獲得基礎短語標記:
![]() [·] represents the concatenation.
[·] represents the concatenation.
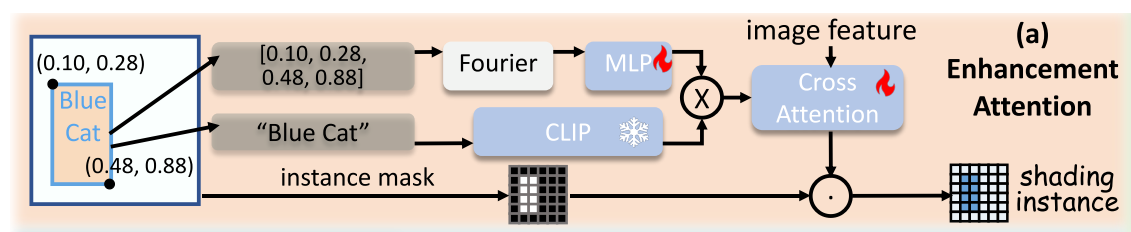
文本與位置信息結合,生成唯一標識符:
-
邊界框?bi?通過傅里葉嵌入編碼位置特征。
-
MLP 生成位置令牌,與 CLIP 文本令牌拼接
區分相同描述但不同位置的實例,避免鍵值共享導致的合并。
Shading stage 2: Enhancement Attention for solving instance missing.
如圖圖所示,MIGC使用可訓練的增強-注意(EA)層來增強陰影結果。具體而言,如圖圖(a)所示,EA在獲得扎根短語令牌后,使用新的可訓練的CrossAttention層獲得增強的著色結果,并將其添加到第一個著色結果Ri f中:
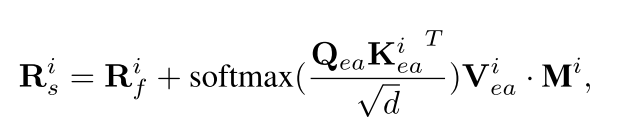
其中Ki ea和Vi ea由grounded phrase tokenGi得到,Qea由圖像特征映射得到。
在訓練期間,由于Mi保證了精確的空間定位,EA輸出的實例著色結果只影響正確的區域,因此EA很容易學習:無論圖像特征是什么,EA都應該進行增強的著色,以滿足di的文本語義,解決實例缺失的問題。最后,MIGC將增強后的結果Ri s作為子任務的解。

Combine Shading Results
Global prompt residual as shading background.?
獲得n個實例的著色結果作為著色前景,MIGC的下一步是獲得著色背景。如圖(c)所示,MIGC利用全局提示符P以類似方程(3)的方式獲得遮陽背景結果Rbg,背景掩碼為Mbg,其中包含實例的位置賦值為0,而所有其他位置均標記為1。

Layout Attention residuals as shading template.?
在著色實例{R1s, . . . ,RNs }和shading background Rbg之間存在一定的間隙。因為它們的遮陽過程是獨立的。為了橋接這些遮陽結果并最小化差距,MIGC需要根據圖像特征映射的信息學習遮陽模板。如圖2所示,在MIGC中使用布局注意層來實現上述目標。如圖3(b)所示,布局注意的表現與自注意力機制相似,實例掩碼Minst = {Mbg,M1, . . . ,MN}用于構造注意力掩模:
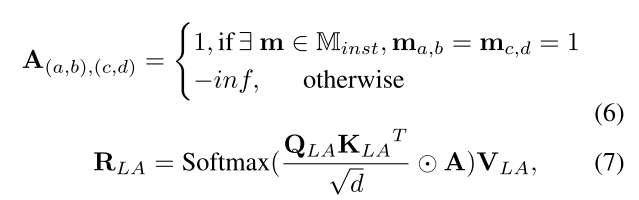 ⊙ represents the Hadamard product
⊙ represents the Hadamard product
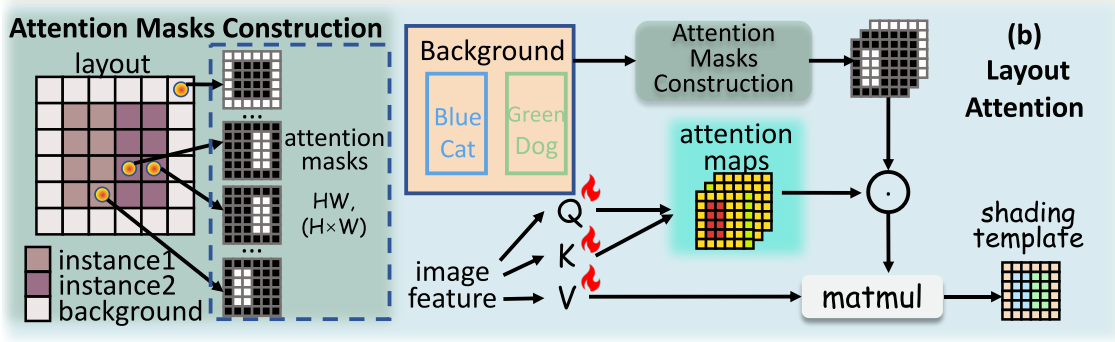

A∈R((H,W),(H,W))表示注意掩碼,其中A(a,b)(c,d)決定像素(a,b)是否應該關注像素(c,d)。構造的注意掩碼A保證了一個像素只能關注同一實例區域內的其他像素,避免了實例間的屬性泄漏。

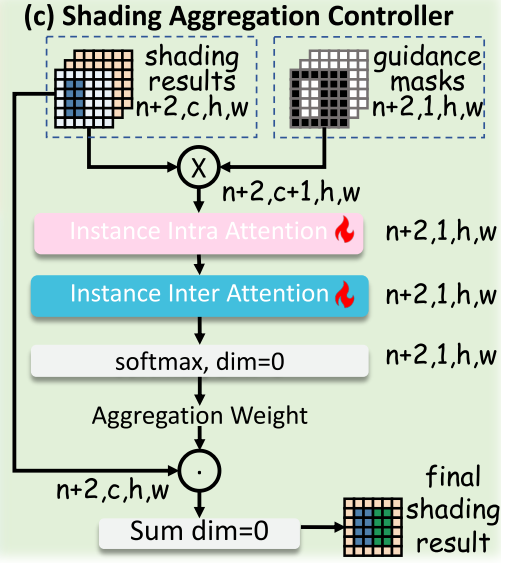
Shading Aggregation Controller for the final fusion.
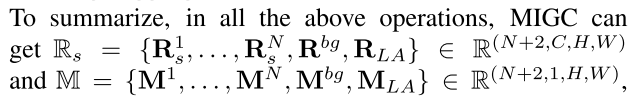
其中MLA為RLA對應的全1制導掩碼。為了動態地聚合生成過程中不同時間步長的著色結果,提出了Shading Aggregation Controller(SAC)。如圖3(c)所示,SAC依次執行實例內注意和間注意,并通過softmax函數對每個空間像素上的著色結果賦予聚合權和為1,從而得到最終的著色。


Summary
Training Loss.??original denoising loss :
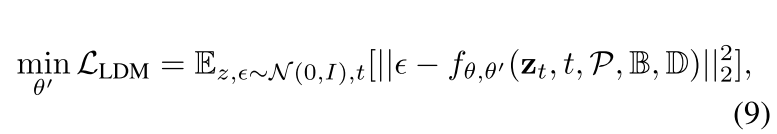
其中,θ表示預訓練穩定擴散的凍結參數,θ′表示MIGC參數。
此外,為了將生成的實例約束在其區域內,防止在背景中產生額外的對象,設計了抑制損失來避免背景區域的高關注權:
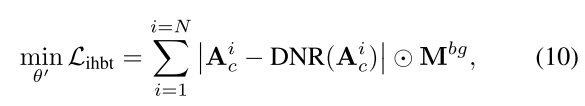
其中?DNR(?)為背景區域去噪操作(如平均濾波)。
其中Ai表示Unet解碼器凍結的16 × 16交叉注意層中第i個實例的注意圖,DNR(·)表示背景區域的去噪(例如使用平均操作)。
-
約束實例注意力圖?Aci?在背景掩碼?Mbg(實例區域為0,背景為1)區域內保持低權重。
最終訓練損失設計如下:
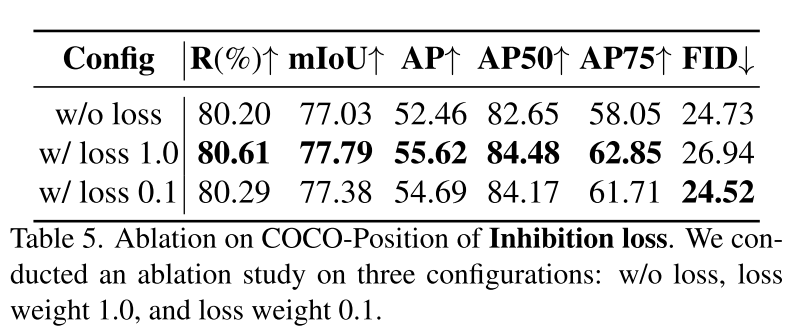
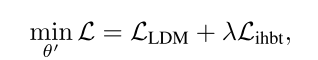 the loss weight λ as 0.1.
the loss weight λ as 0.1.
Implementation Details.
只在UNet的中間層(即8 × 8)和最低分辨率的解碼器層(即16 × 16)部署MIGC,這在很大程度上決定了生成圖像的布局和語義信息[6,33]。在其他交叉注意層中,使用全局提示來進行全局著色。使用COCO 2014培訓MIGC。為了獲得實例描述及其邊界框,使用stanza拆分全局提示符,并使用ground - dino模型檢測實例。基于預訓練的SDv1.4訓練MIGC。使用恒定學習率為1e?4的AdamW優化器,在40個V100 gpu,每個VRAM為16GB的情況下,訓練300個epoch,批大小為320,需要15個小時。對于推理,使用EulerDiscreteScheduler[22]和50個示例步驟,并在前25個步驟中使用MIGC。選擇CFG刻度為7.5。
Experiments
Benchmarks?
三個基準上評估模型的性能:COCO-MIG、COCO-Position和DrawBench。使用8個種子為每個提示符生成圖像。
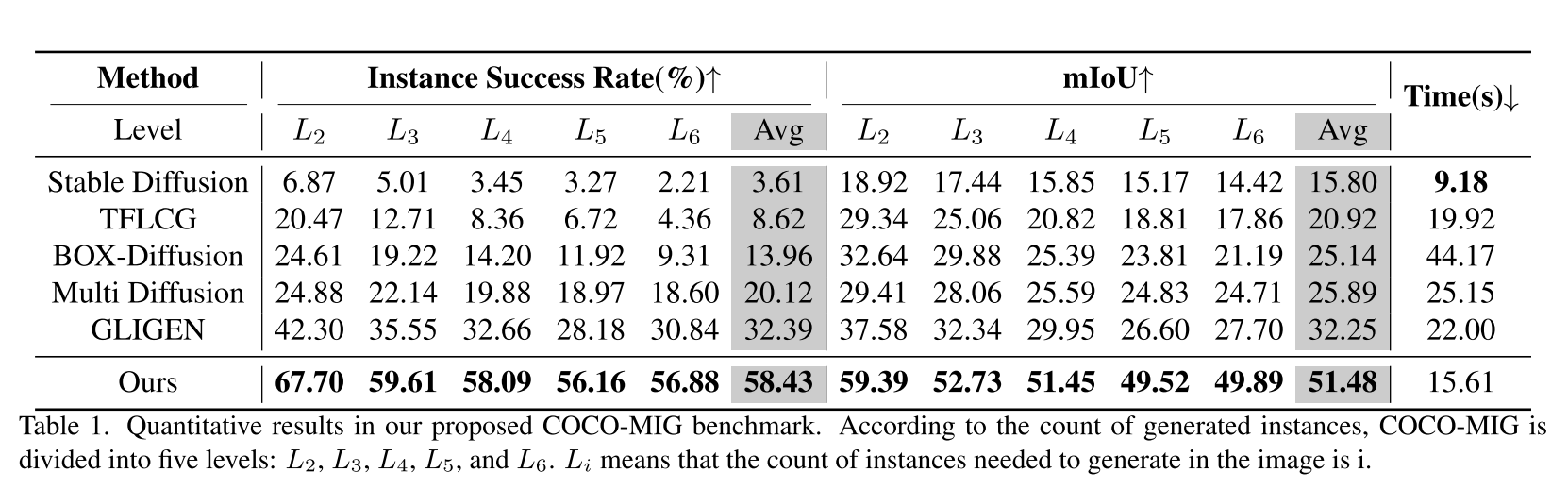
In COCO-MIG?注意位置、顏色和數量。為了構建數據集,隨機采樣800張COCO圖像,并在保持原始布局的同時為每個實例分配一種顏色。此外,以“a <attr1><obj1>和a <attr2> <obj2>和a…”的格式重構全局提示符。根據生成圖像中的實例數量將該基準分為五個級別。每種方法將生成6400張圖像。
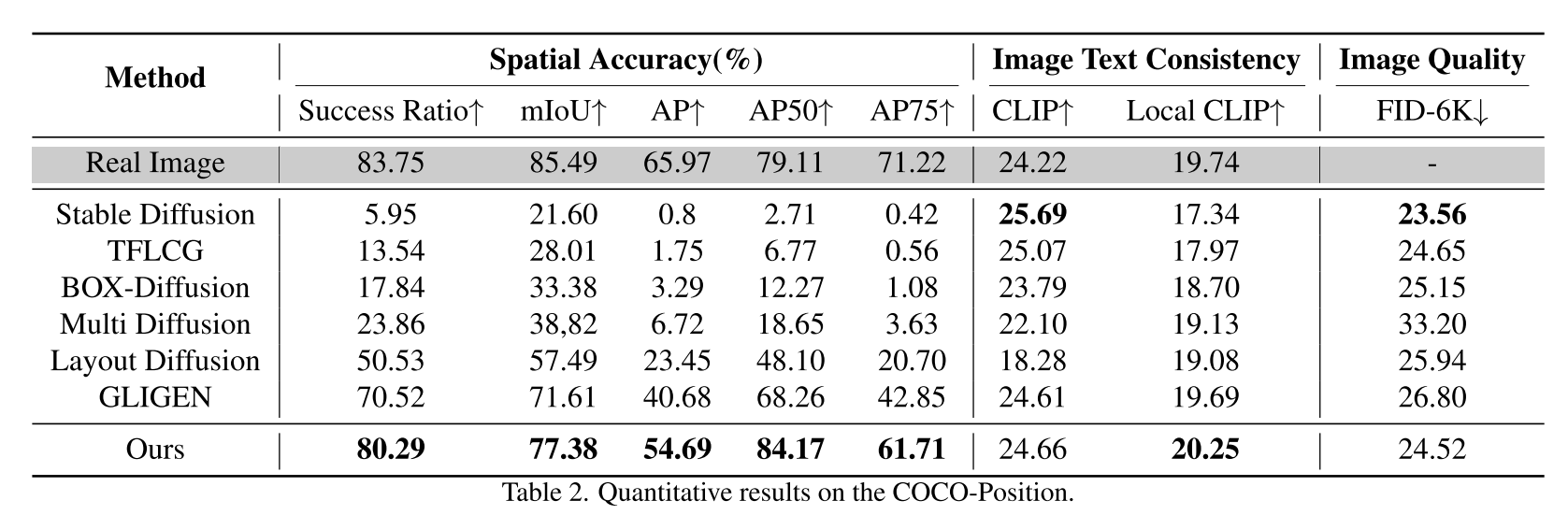
In COCO-Position?采樣了800張圖片,使用標題作為全局提示,標簽作為實例描述,邊界框作為布局來生成6400張圖片。
Drawbench?是一個具有挑戰性的T2I基準。使用GPT4[15,35]提取所有實例描述并生成每個提示符的布局。總共使用64個提示,其中25個與顏色有關,19個與計數有關,20個與位置有關,最終生成512張圖像。
Evaluation Metrics
Position Evaluation.?使用groundingdino來檢測每個實例,并計算檢測盒和真實值盒之間的最大IoU。如果上述IoU高于閾值t=0.5,將其標記為正確生成的位置。
Attribute Evaluation.?對于Position correct Generated實例,使用ground - sam模型[25,29]對其進行分割,并計算目標顏色在HSV顏色空間中的百分比。如果上述百分比超過閾值S=0.2,將其表示為完全正確生成。
Metrics on COCO-MIG.?主要測量實例Success Rate和mIoU。成功率計算每個實例完全正確生成的概率,mIoU計算所有實例的最大IoU的平均值。注意,如果顏色屬性不正確,將IoU值設置為0。
Metrics on COCO-Position?使用Success Rate、mIoU和ground - dino AP評分來衡量空間精度。成功率表示一個圖像中的所有實例是否正確生成位置。此外,還使用了初始化距離(FID)[16]來評估圖像質量。為了測量圖像-文本一致性,使用CLIP分數和Local CLIP分數[1]。
Metrics on DrawBench.?評估與位置相關的圖像的成功率,并通過檢查每個圖像中的所有實例是否正確生成位置來計數。對于顏色相關的圖像,檢查是否所有的實例都是完全正確生成的。除了自動評估之外,還進行了手動評估。
Baselines
與SOTA布局到圖像的方法比較:Multi-Diffusion[3]、Layout Diffusion[61]、GLIGEN[26]、TFLCG[6]和Box-Diffusion[49]。
由于布局擴散不能控制顏色,只在COCO-Position上運行它。在Drawbench中,還將本方法與SOTA T2I的一些方法進行了比較:stable diffusion v1.4[40], AAE[5],Structure Diffusion[14]。所有方法都使用官方代碼和默認配置執行。
Quantitative Results
COCO-MIG.?
COCO-Position.
DrawBench.

Qualitative Results


Analysis of Shading Aggregation Controller
用50個步驟生成每個圖像,在前25個步驟中使用MIGC。圖6顯示了T=50、40和30時SAC聚集權值(即T=50表示第一步)。在早期的時間步驟中,SAC將更多的權重分配給前景中的EA層的著色實例,而將更多的權重分配給背景中的LA層的著色模板。在之后的時間步長中,SAC逐漸增加了對背景中全局上下文的關注。

Ablation Study
消融主要由四個部分組成:(1) Enhancement Attention Layer. (2) Layout Attention Layer. (3) Shading Aggregation Controller. (4) The inhibition loss.在COCO-Position和COCO-MIG上進行了實驗。
Shading Aggregation Controller.?
Enhancement Attention Layer.
Layout Attention Layer.

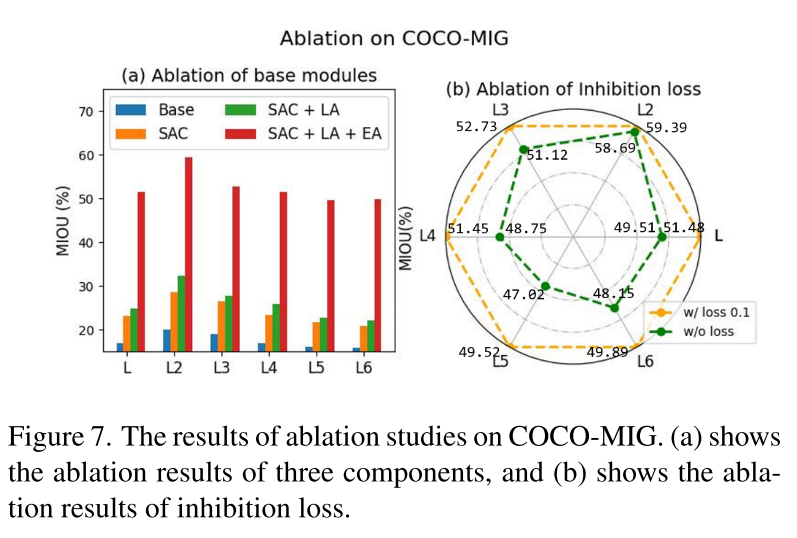
Inhibition Loss.
Qualitative Results.


——模板匹配、打包、圖像的旋轉)













:系統拆分)


】Sliding Window Maximum)
