本教程將拆解什么是嵌入模型、為什么它們在NLP中如此重要,并提供一個簡單的Python實戰示例。

分詞器將原始文本轉換為token和ID,而嵌入模型則將這些ID映射為密集向量表示。二者合力為LLMs的語義理解提供動力。圖片來源:[https://tzamtzis.gr/2024/coding/tokenization-by-andrej-karpathy/]
什么是嵌入模型?
在LLMs的語境中,嵌入模型是一種神經網絡,旨在將文本(如單詞、短語、句子)表示為連續向量空間中的密集向量。這些向量表示能捕捉文本項之間的語義關系,是現代NLP系統的基石。
例如:
- "king"和"queen"這兩個詞的嵌入向量可能在向量空間中非常接近。
- "king"和"man"之間的向量關系可能與"queen"和"woman"之間的關系類似。
想象完這些語義關系在向量空間中的樣子后,我們可能會認為單詞直接變成了這些能保留語義關系的向量。這種想法在討論LLM處理流程中的令牌時可能會引起一些混淆。讓我們稍微澄清一下關于分詞的內容。
分詞器和嵌入模型有什么區別?
在使用BERT、GPT等大語言模型(LLMs)時,經常會遇到兩個關鍵概念:分詞器和嵌入模型。雖然它們相關,但在處理單詞的流程中扮演著不同的角色。
LLMs處理原始文本的一般流程如下:
- 原始輸入文本:我們輸入給模型的純文本(例如“我愛機器學習”)。
- 分詞器:將原始文本拆分為更小的單元(令牌)并將其轉換為數字ID。
- 嵌入模型:將這些數字令牌ID映射到連續向量空間中的密集向量表示,捕捉語義含義。
- Transformer模型:使用自注意力層處理嵌入并生成預測(如下一個單詞、情感、分類等)。
現在我們對流程中的分詞器和嵌入模型有了更清晰的認識,讓我們進一步明確什么是分詞器,什么是嵌入模型。
什么是分詞器?
分詞器是流程中的第一個組件,負責:
- 將文本拆分為令牌:一個令牌可以是一個單詞、子詞甚至是一個字符。例如,句子“我愛機器學習”可能被分詞為:
['我', '愛', '機器', '學習']
- 將令牌轉換為ID:每個令牌被映射到模型詞匯表中的唯一數字ID。例如:
['我', '愛', '機器', '學習'] → [101, 2173, 5956, 3627]
分詞器使用預定義的詞匯表(在模型訓練期間構建)以確保訓練和推理之間的一致性。分詞器通常采用以下技術:
- WordPiece(BERT使用):將罕見詞拆分為更小的子詞單元。例如,“unbelievable”可能被分詞為
["un", "##believable"],其中##表示子詞。 - 字節對編碼(BPE)(GPT使用):類似于WordPiece,但編碼方式不同。
推薦觀看Andrej Karpathy的這個視頻:https://youtu.be/zduSFxRajkE?si=KGKPLninpxnHu3jN
什么是嵌入模型?
嵌入模型在分詞之后發揮作用,其職責是:
- 將令牌ID轉換為密集向量:每個令牌ID被映射到連續向量空間中的一個固定大小的向量(例如,BERT-base的向量大小為768)。這些向量稱為嵌入。
- 捕捉語義含義:生成的嵌入表示令牌的含義,使得相似的單詞或令牌在向量空間中更接近。
例如:
- "king"和"queen"這兩個詞的嵌入向量可能非常接近。
- 子詞如“un”和“##believable”可能組合成“unbelievable”的有意義嵌入。
嵌入模型本質上是一個查找表,但它也可以編碼上下文信息(例如,在BERT等模型中,嵌入是上下文感知的)。
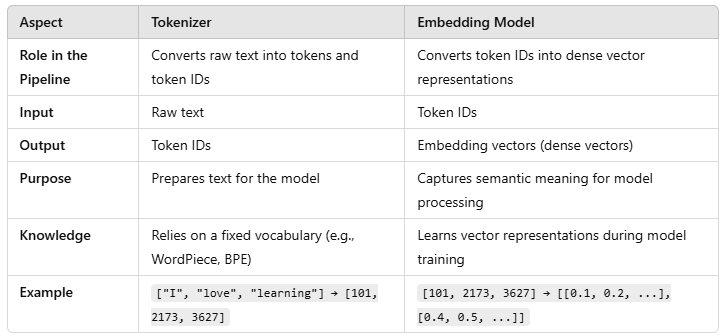
分詞器和嵌入模型如何協同工作
讓我們在LLM流程的更大背景下連接分詞器和嵌入模型:
- 分詞器:分詞器為模型準備輸入文本。例如:
輸入文本:"我愛機器學習"
分詞器輸出:[101, 2173, 5956, 3627]
這里,[101, 2173, ...]是令牌ID。
2. 嵌入模型:令牌ID隨后傳遞給嵌入層,將其轉換為密集向量表示:
令牌ID:[101, 2173, 5956, 3627]
嵌入向量:[[0.1, 0.2, ...], [0.4, 0.5, ...], ...]
這些向量在訓練期間學習,表示每個令牌的含義。
3. Transformer層:嵌入通過Transformer層(如自注意力)處理,計算上下文表示并生成預測。
為什么這種區分很重要?
理解分詞器和嵌入模型之間的區別至關重要,因為:
- 分詞器定制:在特定領域任務(如法律或醫學文本)中,可能需要自定義分詞器來處理專業術語(如“訴訟”、“MRI掃描”)。
- 預訓練嵌入:你可以微調嵌入層以適應你的領域。例如,在醫學文本上訓練的嵌入與在一般新聞文章上訓練的嵌入會有顯著差異。
- 錯誤調試:下游任務中的問題通常源于分詞問題,如詞匯表外(OOV)單詞或次優的分詞策略。
一個類比來澄清概念
將LLM想象成一個工廠:
- 分詞器:分詞器就像原材料處理器,將文本拆分為工廠可以處理的單元。
- 嵌入模型:嵌入模型是生產線上的第一臺機器,將這些原材料轉換為中間產品(密集向量),供工廠的其他部分處理。
沒有分詞器,嵌入模型就不知道要處理什么。沒有嵌入模型,Transformer層就沒有有意義的輸入。
分詞器和嵌入模型的實戰示例
from transformers import AutoTokenizer, AutoModel# 第一步:加載分詞器和模型
tokenizer 

)
—— 貪心)



 流提取運算符的重載和const成員)










)
