
論文地址:Dual Anchor Graph Fuzzy Clustering for Multiview Data | IEEE Journals & Magazine | IEEE Xplore
代碼地址:https://github.com/BBKing49/DAG_FC
摘要
多視角錨圖聚類近年來成為一個重要的研究領域,催生了多個高效的方法。然而,當前的多視角錨圖聚類方法仍然面臨三個主要挑戰。
首先,現實世界數據通常表現出不確定性和較差的可辨識性,導致直接從原始數據提取的錨圖質量較低,影響聚類效果。其次,大多數現有方法假設視角之間存在公共信息,并主要利用這些信息進行聚類,從而忽略了視角特有的信息。第三,如何進一步探索和利用所學習的錨圖以提升聚類性能仍然是一個開放性問題。
為了解決這些問題,本文提出了一種新的雙錨圖模糊聚類方法。首先,提出了一種基于矩陣分解的雙錨圖學習方法,以解決前兩個問題。該方法能夠提取各個視角的高度可辨識隱藏表示,并在此基礎上分別構建公共錨圖和特有錨圖。然后,為了解決第三個問題,本文提出了一種錨圖模糊聚類方法,通過協同學習機制充分利用和挖掘公共與特有錨圖。此外,構建了一種基于雙錨圖的模糊隸屬度結構保持機制,以進一步提升聚類性能。最后,引入負香農熵,自適應地調整各視角的權重。
在多個數據集上的大量實驗結果表明,該方法具有良好的聚類效果和有效性。
引言
隨著數字技術的進步,收集到的數據種類大幅增加。例如,在生物信息學領域,酶可以用序列信息和結構信息來表示;同樣,腫瘤也可以通過不同的醫學成像方式(如 CT 和 MRI 掃描)進行描述。在過去的十年里,如何構建高效的模型來處理這些多表示或多源數據已成為研究的重點。多視角聚類學習是一種強大的技術來處理這些數據,并基于該技術已發展出多種有效的方法。其中,基于圖的多視角子空間聚類方法是最重要的代表之一。該方法通過學習不同視角之間的公共相似性矩陣,并利用譜聚類算法來獲得最終的聚類結果。
為了提高聚類效果,研究者們提出了不同的改進策略。例如,基于多核方法,Zhou 等人提取了不同視角之間的一致性相似性矩陣用于聚類建模;基于自表示學習,Cao 等人提取了各個視角的相似性矩陣,并引入Hilbert-Schmidt 獨立性準則來增強相似性矩陣的多樣性,最終將這些矩陣融合為一個公共相似性矩陣以進行譜聚類。此外,為了解決不完整多視角數據的問題,Xu 等人將潛在表示學習和公共相似性矩陣學習統一到一個過程當中。此外,為了提取高可辨識性的公共圖,Liang 等人和 Cai 等人分別探索了不同視角之間的一致性和不一致性,并去除不一致信息,融合一致信息構建公共圖進行聚類。
然而,現有的基于圖的多視角聚類方法仍然存在計算成本較高的問題。例如,在計算相似性矩陣、執行譜聚類以及離散化譜嵌入時需要較長的計算時間。為了降低計算成本,近年來研究人員提出了多種錨圖(anchor graph)方法,其高效性使其成為研究熱點。這些方法的基本思路是:從多視角數據中選擇或學習代表性錨點實例,并基于這些錨點生成錨圖進行聚類。
目前,已有多種基于錨圖的建模框架。例如,Kang 等人提出的方法通過預訓練一組聚類中心作為錨點,并為每個視角學習錨圖,最終通過后處理將其融合為公共表示;Zhang 等人則提出了一種更具靈活性的方法,該方法學習多組錨點實例并構建多級錨圖,同時設計了一種多錨點融合機制,以高效地融合這些錨圖。此外,Wang 等人在 Kang 等人的基礎上,提出了一種新的錨點匹配機制和錨圖融合框架,以進一步提升聚類性能。
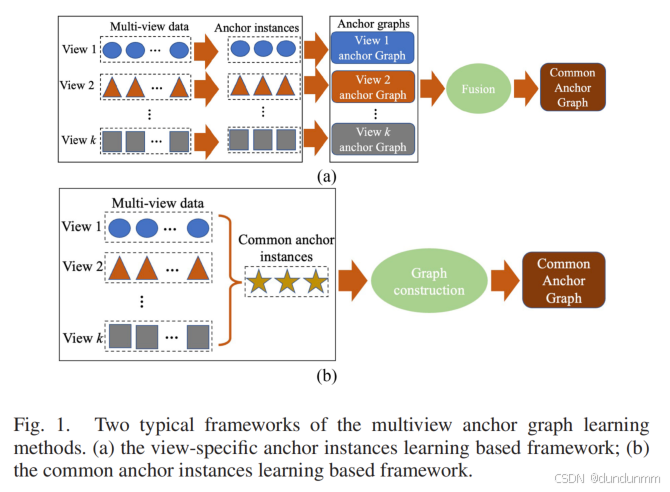
盡管現有的錨圖方法取得了一定的進展,但仍然面臨以下挑戰:
-
直接從原始數據構建錨圖的魯棒性問題:原始數據通常包含噪聲和錯誤,直接構造的錨圖可能缺乏可辨識性,進而影響聚類效果。因此,需要設計更魯棒的錨圖學習方法。
-
公共信息和特有信息的兼顧問題:現有方法通常僅關注公共錨圖或分別構建所有視角的特有錨圖并后期融合,但多視角數據同時包含公共信息和特有信息,現有方法無法同時利用這兩類信息。因此,如何同時探索公共和特有錨圖成為提升聚類性能的關鍵問題。
-
錨圖聚類方法的優化問題:當前方法通常直接在錨圖上執行傳統的單視角聚類方法,尚缺乏針對錨圖的更有效的聚類策略,這限制了聚類性能的進一步提升。
本文貢獻
針對上述問題,本文提出了一種雙錨圖模糊聚類方法,其核心創新點包括:
-
提出了一種新的多視角雙錨圖學習方法,該方法不僅統一了隱藏表示學習和錨圖學習,還能夠同時挖掘公共信息和特有信息。
-
提出了一種基于錨圖的多視角模糊聚類方法,通過構建模糊隸屬度結構保持機制和引入負香農熵,充分利用雙錨圖提升聚類性能。
-
在多個多視角數據集上的實驗驗證了所提出方法的有效性。
模型
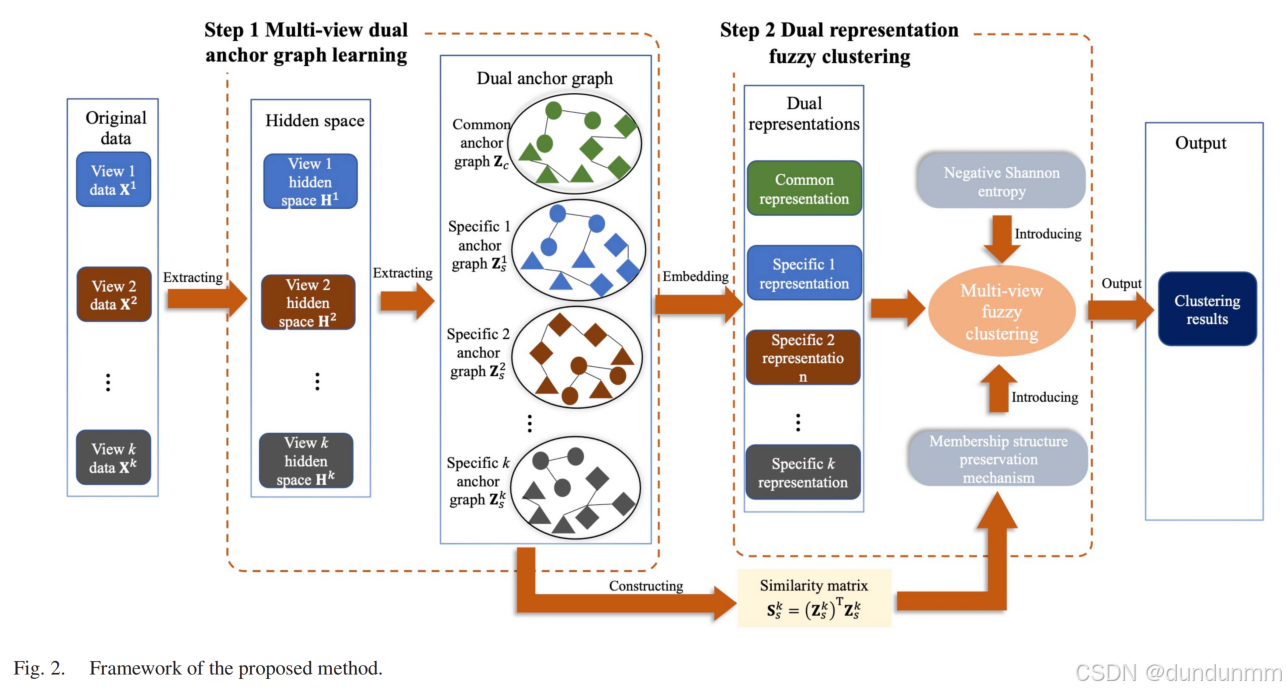
A. 提出方法的框架
為了解決引言中提出的三個問題和挑戰,本節提出了一種新的高效聚類方法,其框架如圖 2 所示。該方法包括兩個主要步驟:第一步是基于矩陣分解的多視角雙錨點圖學習,第二步是基于雙錨點圖的協同學習模糊聚類。
在第一步中,為了確保提取的錨點圖具有良好的可區分性,首先引入矩陣分解來凈化原始數據并提取每個視角的隱藏表示。同時,為了充分挖掘多視角數據,通過專門設計的雙錨點圖學習機制,提取隱藏表示之間的公共錨點圖以及每個隱藏表示的特定錨點圖。此外,隱藏表示學習和雙錨點圖學習被整合到一個優化過程中,使這兩個部分能夠相互促進學習。
隨后,在第二步中,為了充分利用雙錨點圖,引入了一種新的基于多視角模糊聚類的方法,并通過協同學習提升聚類性能。此外,設計了一種成員結構保持機制,進一步增強聚類效果。
B. 多視角雙錨點圖學習
為了解決前面提到的如何設計更穩健的錨點圖學習方法以及如何同時挖掘多視角數據中的公共和特定信息這兩個問題,本節提出了一種雙錨點圖學習框架,并定義其優化目標函數如下:
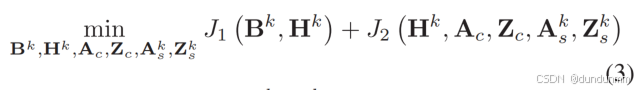
其中:
-
第一項 J1(Bk,Hk)通過引入矩陣分解來凈化原始多視角數據。
-
第二項 J2(Hk,Ac,Zc,Aks,Zks)負責提取雙錨點圖。
現有的多視角錨點圖學習方法大致可分為兩類:
-
直接學習公共錨點實例 并構建公共錨點圖。
-
分別學習每個視角的錨點實例和錨點圖,然后在后處理階段將所有錨點圖融合成一個公共表示。
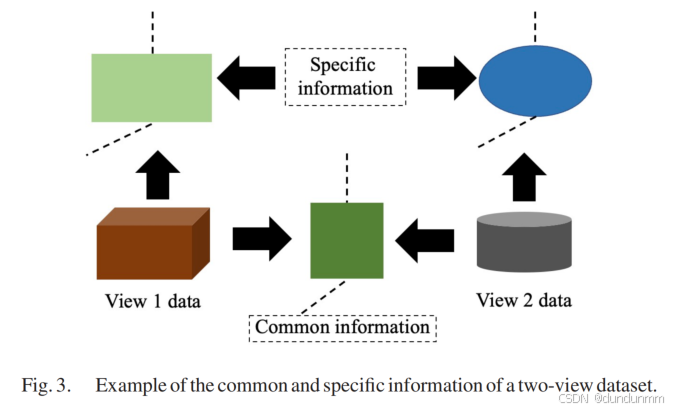
然而,這兩類方法都存在一個局限性:無法充分挖掘多視角數據的潛在信息。研究【17】、【18】表明,多視角數據通常同時包含跨視角共享的公共信息以及每個視角獨有的特定信息,如圖 3 所示。因此,本研究借鑒這一思想,在優化目標的第二項中創新性地同時提取公共錨點圖和特定錨點圖,以充分挖掘多視角數據。

創新性
總體而言,該方法在數據凈化、隱藏錨點圖學習和聚類劃分三個方面對多視角聚類做出了貢獻,具體如下:
首先,盡管近年來已有一些多視角錨點圖學習方法被提出,但幾乎所有現有方法都是直接從原始數據中提取錨點圖,而原始數據通常包含噪聲和錯誤。這可能會削弱學習到的錨點圖的可區分性,進而影響后續聚類任務的性能。因此,開發能夠結合表示學習以凈化原始數據并提高錨點圖質量的新型錨點圖學習方法至關重要。在本研究中,我們引入矩陣分解并將其創新性地與錨點圖學習融合,使這兩個部分能夠相互作用、共同優化。
其次,如圖 1 所示,現有方法通常采用兩種策略:
-
分別學習每個視角的獨立錨點實例矩陣,然后構造公共錨點圖用于聚類。
-
直接學習一個共享的錨點實例矩陣,用于所有視角的錨點圖構建。
然而,這兩種方法的共同缺陷是:它們僅關注視角間的公共信息,而忽略了每個視角的特定信息。然而,已有研究【18】表明,在聚類過程中,公共信息與特定信息同樣重要。因此,開發一種能夠同時提取公共和特定錨點圖的多視角錨點圖學習方法至關重要。為此,我們提出了一種新機制,同時挖掘公共錨點圖和特定錨點圖,使后續聚類任務能夠充分利用雙錨點圖信息,從而提升聚類性能。實驗結果進一步驗證了該機制的有效性。
最后,現有的多視角錨點圖學習方法通常使用SVD提取公共表示,并在此基礎上采用單視角聚類方法(如 K-means)進行聚類。然而,本研究提出的方法同時提取公共和特定錨點圖。盡管可以將這些錨點圖組合后采用上述傳統方法進行聚類,但這一策略可能會忽略二者之間的一致性和互補性信息。因此,設計高效的雙錨點圖聚類方法是關鍵。考慮到模糊聚類(fuzzy clustering)在處理數據不確定性方面表現優異,并且具有較強的聚類能力【26】, 本研究基于其提出了一種新的雙錨點圖模糊聚類方法。此外,為了進一步利用雙錨點圖并提升聚類效果,我們設計了一種模糊成員結構保持機制,用于優化錨點圖的聚類表現。實驗結果進一步證明了所提出方法的有效性。
綜上所述,本研究在多視角聚類領域的多個方面做出了重要貢獻。
實驗
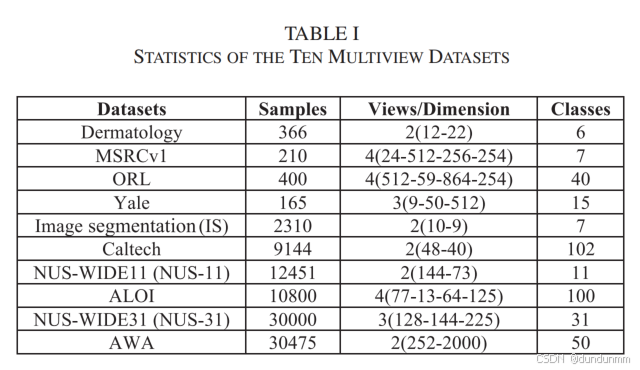

雙錨點圖在多視圖中主要用于同時挖掘公共信息和特定信息,提升數據的可區分性,從而提高聚類的準確性和魯棒性。



)







)

)




)
