一、前言
? ? ? ? 接續上一篇文章,這個部分主要分析代碼框架的實現細節和設計理念。
基于RK3588的YOLO多線程推理多級硬件加速引擎框架設計(項目總覽和加速效果)-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146542002?spm=1001.2014.3001.5501
https://blog.csdn.net/plmm__/article/details/146542002?spm=1001.2014.3001.5501
二、框架分析
? ? ? ? 在原作者的基礎上,我增加了命令行的參數解析、多態視頻讀取引擎、硬件視頻解碼、RGA 硬件圖像縮放,色彩空間轉換,以及部分代碼優化和內存管理調整。
1、命令行參數解析
? ? ? ? 使用?ConfigParser 類封裝,便于移植:

頭文件 parse_config.hpp:
#ifndef _PARSE_CONFIG_HPP_
#define _PARSE_CONFIG_HPP_#include <iostream>
#include <string>
#include <SharedTypes.hpp>/* 定義配置解析類 */
class ConfigParser {public:// 輸入格式int input_format; // 顯示幫助信息void print_help(const std::string &program_name) const;// 打印配置信息void printConfig(const AppConfig &config) const;// 解析命令行參數AppConfig parse_arguments(int argc, char *argv[]) const;private:// 私有成員(如果有需要可以添加)};#endif
? ? ? ? 這里的?AppConfig 是參數列表結構體,定義在全項目的共享頭文件 Shared_Types.hpp?中:
/* 定義命令行參數結構體 */
struct AppConfig {// 在屏幕顯示 FPSbool screen_fps = false;// 在終端打印 FPSbool print_fps = false;// 是否使用openclbool opencl = true;// 是否打印命令行參數bool verbose = false;// 視頻加載引擎,默認為 ffmpegint read_engine = READ_ENGINE::EN_FFMPEG;// 輸入格式,默認為視頻int input_format = INPUT_FORMAT::IN_VIDEO;// 硬件加速,默認為 RGAint accels_2d = ACCELS_2D::ACC_RGA;// 線程數,默認為1int threads = 1;// rknn 模型路徑string model_path = "";// 輸入源 string input = "";// 解碼器,默認為 h264_rkmppstring decodec = "h264_rkmpp";
};源文件較大,這里僅放一個長短命令解析的部分截圖:

? ? ? ? 各位可根據自己喜好,修改參數列表,我比較喜歡設置默認值,直接執行可執行文件時,只需要傳遞必要的參數。
2、多態視頻讀取引擎
? ? ? ? 原作者使用 OpenCV 進行視頻讀取和取幀操作,為了保留 OpenCV 的讀取,我使用多態的方式可以靈活選擇 OpenCV 和 FFmpeg 兩種方式進行讀取。本節均只介紹頭文件中的接口,具體實現較長,還請讀者移步 Github 。整體框架為:
(1)?Reader(基類)?
定義了視頻讀取操作的通用接口(如 open、close、readFrame 等)。
作為所有具體讀取器(如 FFmpegReader、OpencvReader 等)的基類,利用多態性實現運行時動態選擇具體的實現類。
#ifndef READER_H
#define READER_H#include <string>
#include "opencv2/core.hpp"/*** @Description: 基類引擎* @return {*}*/
class Reader {
public:// 析構虛函數virtual ~Reader() = default;/* 純虛函數接口 */virtual void openVideo(const std::string& filePath) = 0;virtual bool readFrame(cv::Mat& frame) = 0;virtual void closeVideo() = 0;
};#endif // READER_H(2)?FFmpegReader 或 OpencvReader(Reader 的子類)?
繼承自 Reader 基類。
實現了基類中定義的虛函數,具體使用 FFmpeg 或 OpenCV 庫提供的函數來處理視頻操作。
在初始化時,可能配置和加載與讀取器相關的資源或參數。
#ifndef FFMPEGREADER_H
#define FFMPEGREADER_H#include <iostream>
#include "Reader.hpp"
#include "preprocess.h"
#include "SharedTypes.hpp"#include <opencv2/opencv.hpp>
extern "C" {
#include <libavutil/frame.h>
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libavutil/avutil.h>
#include <libswscale/swscale.h>
#include <libavutil/imgutils.h>
}/*** @Description: FFmpeg 引擎* @return {*}*/
class FFmpegReader : public Reader {
public:FFmpegReader(const string& decodec, const int& accels_2d);~FFmpegReader() override;void openVideo(const std::string& filePath) override;bool readFrame(cv::Mat& frame) override;void closeVideo() override;// 獲取視頻信息void print_video_info(const string& filePath);int getWidth() const;int getHeight() const;AVRational getTimeBase() const;double getFrameRate() const;private:string decodec; // 解碼器int accels_2d; // 2D 硬件加速類型AVFormatContext *formatContext = nullptr; // 輸入文件的上下文AVCodecContext *codecContext = nullptr; // 解碼器上下文const AVCodec* codec = nullptr; // 解碼器int videoStreamIndex = -1; // 視頻流的索引AVStream *video_stream; // 視頻流AVFrame *tempFrame = nullptr; // 臨時幀(用于解碼)AVPacket *packet = nullptr; // 數據包int NV12_to_BGR(cv::Mat& bgr_frame);int FFmpeg_yuv420sp_to_bgr(cv::Mat& bgr_frame);void AV_Frame_To_CVMat(cv::Mat& nv12_mat);
};#endif // FFMPEGREADER_H#ifndef OPENCVREADER_H
#define OPENCVREADER_H#include "Reader.hpp"
#include <iostream>
#include <opencv2/opencv.hpp>/*** @Description: Opencv 引擎* @return {*}*/
class OpencvReader : public Reader {
public:OpencvReader();~OpencvReader() override;void openVideo(const std::string& filePath) override;bool readFrame(cv::Mat& frame) override;void closeVideo() override;private:cv::VideoCapture videoCapture; // OpenCV 視頻捕獲對象
};#endif // OPENCVREADER_H(3)VideoReader(中間件)?
提供給 main 函數或其他上層模塊使用的接口。
負責根據配置或輸入動態選擇并實例化合適的 Reader 子類(如 FFmpegReader 或 OpencvReader)。
封裝了對具體 Reader 實例的管理,簡化了上層模塊對視頻讀取操作的調用。
#ifndef VIDEOREADER_H
#define VIDEOREADER_H#include <memory>
#include <string>#include "SharedTypes.hpp"
#include "Reader.hpp"/*** @Description: 視頻讀取器* @return {*}*/
class VideoReader {
public:VideoReader(const AppConfig& config);~VideoReader();/* 以下禁止拷貝和允許移動兩部分實現:1、提高性能;2、管理獨占資源;3、現代C++鼓勵使用移動語義和智能指針等工具來管理資源。 */// 禁止拷貝構造和拷貝賦值VideoReader(const VideoReader&) = delete;VideoReader& operator=(const VideoReader&) = delete;// 允許移動構造和移動賦值VideoReader(VideoReader&&) = default;VideoReader& operator=(VideoReader&&) = default;/* 函數接口 */bool readFrame(cv::Mat &frame); // 讀取一幀void Close_Video(); // 關閉視頻private:// 使用智能指針管理資源,這里只是聲明, ?沒有申請內存std::unique_ptr<Reader> reader_ptr; // 加載引擎void Init_Load_Engine(const int& engine, const string& decodec, const int& accels_2d);
};#endif // VIDEOREADER_H(4)?main 函數
使用 VideoReader 提供的統一接口來操作視頻,無需關心底層使用了哪種具體的讀取器實現。
創建?VideoReader:
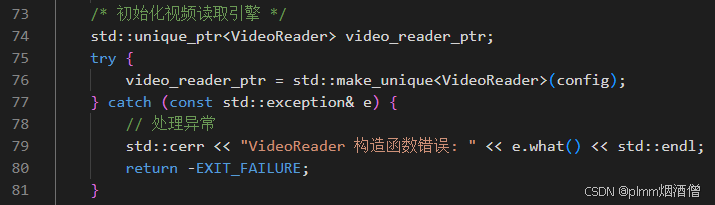
讀取幀:
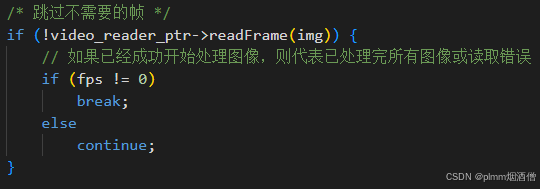
3、硬件視頻解碼
? ? ? ? 這部分主要由 FFmpeg 實現,通過 FFmpeg 來調用 Rkmpp 解碼器。這里需要注意,FFmpeg 不是官方源碼,而是 rockchip 版本的 ffmpeg-rockchip,來自?nyanmisaka 大佬的項目:
nyanmisaka/ffmpeg-rockchip: FFmpeg with async and zero-copy Rockchip MPP & RGA support![]() https://github.com/nyanmisaka/ffmpeg-rockchip????????專門針對瑞芯微的?Rockchip MPP & RGA 進行適配和優化,可以在編譯時開啟 rkmpp 解碼支持和 RGA 過濾器支持。編譯方法移步:
https://github.com/nyanmisaka/ffmpeg-rockchip????????專門針對瑞芯微的?Rockchip MPP & RGA 進行適配和優化,可以在編譯時開啟 rkmpp 解碼支持和 RGA 過濾器支持。編譯方法移步:
編譯支持 RKmpp 和 RGA 的 ffmpeg 源碼_ffmpeg支持mpp-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146188927?spm=1001.2014.3001.5501? ? ? ? 代碼部分就是常規的 FFmpeg 進行視頻解碼,我這里分為了兩部分:打開視頻文件和讀取視頻幀。
https://blog.csdn.net/plmm__/article/details/146188927?spm=1001.2014.3001.5501? ? ? ? 代碼部分就是常規的 FFmpeg 進行視頻解碼,我這里分為了兩部分:打開視頻文件和讀取視頻幀。
打開視頻文件
/*** @Description: 打開視頻文件* @param {string} &filePath: * @return {*}*/
void FFmpegReader::openVideo(const std::string& filePath) {/* 分配一個 AVFormatContext */formatContext = avformat_alloc_context();if (!formatContext)throw std::runtime_error("Couldn't allocate format context");/* 打開視頻文件 */// 并讀取頭部信息,此時編解碼器尚未開啟if (avformat_open_input(&formatContext, filePath.c_str(), nullptr, nullptr) != 0)throw std::runtime_error("Couldn't open video file");/* 讀取媒體文件的數據包以獲取流信息 */if (avformat_find_stream_info(formatContext, nullptr) < 0)throw std::runtime_error("Couldn't find stream information");/* 查找視頻流 AVMEDIA_TYPE_VIDEO */// -1, -1,意味著沒有額外的選擇條件,返回值是流索引videoStreamIndex = av_find_best_stream(formatContext, AVMEDIA_TYPE_VIDEO, -1, -1, nullptr, 0);if (videoStreamIndex < 0)throw std::runtime_error("Couldn't find a video stream");/* 查找解碼器 */codec = avcodec_find_decoder_by_name(this->decodec.c_str());if (!codec)throw std::runtime_error("Decoder not found");/* 初始化編解碼器上下文 */ codecContext = avcodec_alloc_context3(codec);if (!codecContext)throw std::runtime_error("Couldn't allocate decoder context");/* 獲取視頻流,它包含了視頻流的元數據和參數 */video_stream = formatContext->streams[videoStreamIndex];/* 復制視頻參數到解碼器上下文 */ if (avcodec_parameters_to_context(codecContext, video_stream->codecpar) < 0)throw std::runtime_error("Couldn't copy decoder context");/* 自動選擇線程數 */codecContext->thread_count = 0;/* 打開編解碼器 */ if (avcodec_open2(codecContext, codec, nullptr) < 0)throw std::runtime_error("Couldn't open decoder");/* 分配 AVPacket 和 AVFrame */ tempFrame = av_frame_alloc();packet = av_packet_alloc();if (!tempFrame || !packet)throw std::runtime_error("Couldn't allocate frame or packet");
}????????其中下面的代碼需要注意:
/* 自動選擇線程數 */codecContext->thread_count = 0;這個變量主要用于設置?FFmpeg 工作線程數量,0 代表自動選擇,具體的實驗可以看這篇文章:
解決 FFmpeg 使用 C/C++ 接口時,解碼沒有 shell 快的問題(使用多線程)-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146523965?spm=1001.2014.3001.5501
https://blog.csdn.net/plmm__/article/details/146523965?spm=1001.2014.3001.5501
讀取視頻幀
/*** @Description: 讀取一幀* @param {Mat&} frame: 取出的幀* @return {*}*/
bool FFmpegReader::readFrame(cv::Mat& frame) {// 讀取幀/*if (av_read_frame(formatContext, packet) < 0) {return false; // 沒有更多幀}*/while (av_read_frame(formatContext, packet) >= 0) {if (packet->stream_index != videoStreamIndex) {av_packet_unref(packet);continue;}break;}// 如果是視頻流if (packet->stream_index != videoStreamIndex) {cerr << "Not a video stream: " << packet->stream_index << " != " << videoStreamIndex << endl;av_packet_unref(packet);return false; // 不是視頻流}// 發送數據包到解碼器if (avcodec_send_packet(codecContext, packet) < 0) {std::cerr << "Failed to send packet to decoder" << std::endl;av_packet_unref(packet);return false; // 發送數據包失敗}// 接收解碼后的幀if (avcodec_receive_frame(codecContext, tempFrame) < 0) {std::cerr << "Failed to receive frame from decoder" << std::endl;av_packet_unref(packet);return false;}// 成功讀取一幀,保存在 tempFrame 中// 將幀數據轉換為 cv::Mat BGR 格式if (this->NV12_to_BGR(frame) != 0) {std::cerr << "Failed to convert YUV420SP to BGR" << std::endl;av_packet_unref(packet);return false;}// 釋放數據包av_packet_unref(packet);return true; // 處理完成
}????????av_read_frame 函數在實測過程中發現開頭幾幀取出后不是視頻流,因此直接使用 while 跳過。在成功取出幀后,會保存在?tempFrame 中,為?AVFrame 格式,色彩空間為 NV12,由解碼器決定,我使用 h264_rkmpp 解碼器,默認輸出是 NV12。
4、RGA 硬件加速
? ? ? ? 目前主要有三個地方使用到了圖像的縮放和格式轉換的操作,并且三個操作是前后關系,分別是上一節取出視頻幀后要將 NV12 轉為 BGR888,轉為 YOLO 輸入的 RGB888,以及輸入尺寸的修改。
NV12 轉為 BGR888
????????由于需要保持接口的通用性,與 OpenCV 取幀保持一致(OpenCV 解碼后為 BGR888 格式), 并且數據傳輸使用 OpenCV 的 cv::Mat 對象進行圖像傳輸,所以在取出幀后進行了顏色空間的轉換,并改用 cv::Mat 進行保存:
/*** @Description: 轉換格式,NV12 轉 BGR* 該函數內有三種轉換方式:* 1. FFmpeg SwsContext 軟件轉換 * 2. OpenCV 軟件轉換,可啟用 opencl(目前區別不大)* 3. RGA 硬件加速轉換* @param {Mat&} frame: * @return {*}*/
int FFmpegReader::NV12_to_BGR(cv::Mat& bgr_frame) {if (tempFrame->format != AV_PIX_FMT_NV12) {return -EXIT_FAILURE; // 格式錯誤}// 設置輸出幀的尺寸和格式,防止地址無法訪問bgr_frame.create(tempFrame->height, tempFrame->width, CV_8UC3);#if 0 // 方式1:使用 FFmpeg SwsContext 軟件轉換return this->FFmpeg_yuv420sp_to_bgr(bgr_frame);
#endif// 創建一個完整的 NV12 數據塊(Y + UV 交錯)cv::Mat nv12_mat(tempFrame->height + tempFrame->height / 2, tempFrame->width, CV_8UC1);// 將 AVFrame 內的數據,轉換為 OpenCV Mat 格式保存this->AV_Frame_To_CVMat(nv12_mat);// 硬件加速if (this->accels_2d == ACCELS_2D::ACC_OPENCV) {// 方式2:使用 OpenCV 軟件轉換cv::cvtColor(nv12_mat, bgr_frame, cv::COLOR_YUV2BGR_NV12);return EXIT_SUCCESS;} else if (this->accels_2d == ACCELS_2D::ACC_RGA) {// 方式3:使用 RGA 硬件加速轉換return RGA_yuv420sp_to_bgr((uint8_t *)nv12_mat.data, tempFrame->width, tempFrame->height, bgr_frame);}elsereturn -EXIT_FAILURE;
}? ? ? ? 這個函數可以使用三種方式進行轉換,分別是:
1. FFmpeg SwsContext 軟件轉換
2. OpenCV 軟件轉換
3. RGA 硬件轉換
????????三種轉換方式的源碼較多,可在項目源碼中查看。根據目前實測的結果(只針對當前轉換函數),SwsContext 轉換一次耗時約 20ms,RGA 約 2-5ms,OpenCV 約 2-4ms。RGA 轉換接口可能和我的接口調用方式有關,還有優化的空間,平均值甚至不如 OpenCV。
轉為 YOLO 輸入的 RGB888
? ? ? ? 這里的轉換操作是放在了推理線程中,理論上是在多線程進行:
// YOLO 推理需要 RGB 格式,后處理需要 BGR 格式// 即使前處理時提前轉換為 RGB,后處理部分任然需要轉換為 BGR,需要在本函數中保留兩種格式if (this->config.accels_2d == ACCELS_2D::ACC_OPENCV) {cv::cvtColor(orig_img, rgb_img, cv::COLOR_BGR2RGB);}else if (this->config.accels_2d == ACCELS_2D::ACC_RGA) {if (RGA_bgr_to_rgb(orig_img, rgb_img) != 0) {cout << "RGA_bgr_to_rgb error" << endl;return cv::Mat();}}else {cout << "Unsupported 2D acceleration" << endl;return cv::Mat();}? ? ? ? 在原作者轉換邏輯的基礎上,我增加了 OpenCV 和 RGA 的選擇。注釋中也說明了為什么需要 BGR 轉 RGB 這一步,這也和 cv::Mat 對象的默認格式有關,cv::imshow 顯示時也是需要數據為 BGR,與 YOLO 的輸入格式相反。
輸入尺寸的修改
? ? ? ? 即輸入圖像的 resize:
// 圖像縮放if (orig_img.cols != width || orig_img.rows != height){// 如果需要縮放,再對 resized_img 申請大小,節約內存開銷resized_img.create(height, width, CV_8UC3);if (this->config.accels_2d == ACCELS_2D::ACC_OPENCV){// 打包模型輸入尺寸cv::Size target_size(width, height);float min_scale = std::min(scale_w, scale_h);scale_w = min_scale;scale_h = min_scale;letterbox(rgb_img, resized_img, pads, min_scale, target_size, this->config.opencl);}else if (this->config.accels_2d == ACCELS_2D::ACC_RGA){ret = RGA_resize(rgb_img, resized_img);if (ret != 0) {cout << "resize_rga error" << endl;}}else {cout << "Unsupported 2D acceleration" << endl;return cv::Mat();}inputs[0].buf = resized_img.data;}else{inputs[0].buf = rgb_img.data;}????????上面與瑞芯微官方的 YOLO demo 是一樣的,我對 letterbox 函數內部做了 OpenCL 的一個修改:
void letterbox_with_opencl(const cv::Mat &image, cv::UMat &padded_image, BOX_RECT &pads, const float scale, const cv::Size &target_size, const cv::Scalar &pad_color) {// 將輸入圖像轉換為 UMatcv::UMat uImage = image.getUMat(cv::ACCESS_READ);// 調整圖像大小cv::UMat resized_image;cv::resize(uImage, resized_image, cv::Size(), scale, scale);if (uImage.empty()) {std::cerr << "Error: uImage is empty." << std::endl;return;}if (resized_image.empty()) {std::cerr << "Error: resized_image is empty." << std::endl;return;}// 計算填充大小int pad_width = target_size.width - resized_image.cols;int pad_height = target_size.height - resized_image.rows;pads.left = pad_width / 2;pads.right = pad_width - pads.left;pads.top = pad_height / 2;pads.bottom = pad_height - pads.top;// 在圖像周圍添加填充cv::copyMakeBorder(resized_image, padded_image, pads.top, pads.bottom, pads.left, pads.right, cv::BORDER_CONSTANT, pad_color);
}/*** @Description: OpenCV 圖像預處理* @return {*}*/
void letterbox(const cv::Mat &image, cv::Mat &padded_image, BOX_RECT &pads, const float scale, const cv::Size &target_size, bool Use_opencl, const cv::Scalar &pad_color)
{// 圖像數據檢查if (image.empty()) {std::cerr << "Error: Input image is empty." << std::endl;return;}// 調整圖像大小cv::Mat resized_image;if (Use_opencl){// 預處理圖像cv::UMat U_padded_image;letterbox_with_opencl(image, U_padded_image, pads, scale, target_size, pad_color);// 將處理后的圖像從 GPU 內存復制回 CPU 內存(如果需要顯示)// padded_image = U_padded_image.getMat(cv::ACCESS_READ);// padded_image = std::move(U_padded_image.getMat(cv::ACCESS_READ));padded_image = U_padded_image.getMat(cv::ACCESS_READ).clone(); // 深拷貝return ;}cv::resize(image, resized_image, cv::Size(), scale, scale);// 計算填充大小int pad_width = target_size.width - resized_image.cols;int pad_height = target_size.height - resized_image.rows;pads.left = pad_width / 2;pads.right = pad_width - pads.left;pads.top = pad_height / 2;pads.bottom = pad_height - pads.top;// 在圖像周圍添加填充cv::copyMakeBorder(resized_image, padded_image, pads.top, pads.bottom, pads.left, pads.right, cv::BORDER_CONSTANT, pad_color);
}
????????使用?cv::UMat 對象來調用 OpenCL 進行 resize 的并行計算。
5、其他
還有一些 C 語言的接口,我封裝為了類的形式,雖然犧牲了一些性能,不過為了項目的通用性和可維護性,很多都使用 C++ 的語法替換掉了,比如加載模型的函數:
原始的 C 函數:
static unsigned char *load_data(FILE *fp, size_t ofst, size_t sz)
{unsigned char *data;int ret;data = NULL;if (NULL == fp){return NULL;}ret = fseek(fp, ofst, SEEK_SET);if (ret != 0){printf("blob seek failure.\n");return NULL;}data = (unsigned char *)malloc(sz);if (data == NULL){printf("buffer malloc failure.\n");return NULL;}ret = fread(data, 1, sz, fp);return data;
}static unsigned char *load_model(const char *filename, int *model_size)
{FILE *fp;unsigned char *data;fp = fopen(filename, "rb");if (NULL == fp){printf("Open file %s failed.\n", filename);return NULL;}fseek(fp, 0, SEEK_END);int size = ftell(fp);data = load_data(fp, 0, size);fclose(fp);*model_size = size;return data;
}改用更便捷的方式,并且內存的申請放到了函數外,由調用者進行管理,提高內存維護的便捷性:
/*** @Description: 獲取文件大小* @param {string&} filename: * @return {size_t}: 返回字節數,失敗返回0*/
static size_t get_file_size(const std::string& filename) {// std::ios::ate:打開文件后立即將文件指針移動到文件末尾(at end)std::ifstream ifs(filename, std::ios::binary | std::ios::ate);if (!ifs.is_open())return 0;// 通過文件尾定位獲取大小size_t size = ifs.tellg();ifs.close();return size;
}/*** @Description: 加載文件數據* @param {ifstream&} ifs: * @param {size_t} offset: * @param {unsigned char*} buffer: * @param {size_t} size: * @return {*}*/
static bool load_data(std::ifstream& ifs, size_t offset, unsigned char* buffer, size_t size) {if (!ifs.is_open()) {std::cerr << "File stream not open" << std::endl;return false;}// 定位到指定位置ifs.seekg(offset, std::ios::beg);if (ifs.fail()) {std::cerr << "Seek failed at offset " << offset << std::endl;return false;}ifs.read(reinterpret_cast<char*>(buffer), size);// ifs.gcount():返回實際讀取的字節數if (ifs.gcount() != static_cast<std::streamsize>(size)) {std::cerr << "Read failed, expected " << size << " bytes, got " << ifs.gcount() << std::endl;return false;}return true;
}/*** @Description: 加載模型* @param {string} &filename: * @param {unsigned char} *buffer: * @param {size_t&} buffer_size: * @return {*}*/
static bool load_model(const std::string &filename, unsigned char *buffer, const size_t& buffer_size) {// std::ios::binary:以二進制模式打開文件std::ifstream ifs(filename, std::ios::binary);if (!ifs){std::cerr << "Failed to open: " << filename << std::endl;return false;}if (buffer_size == 0){std::cerr << "Failed to open: " << filename << std::endl;return false;}return load_data(ifs, 0, buffer, buffer_size);
}三、總結
? ? ? ? 以上就是我做的一些修改的粗略描述,具體細節我也都在代碼中做了注釋。希望這個項目可以幫到有需要硬件解碼,以及正在學習 RGA 接口的小伙伴。各位讀者有任何修改意見,歡迎與我聯系,代碼會放至Gitee 和 Github,我有空也會持續完善優化:
Gitee:
YOLO_RKNN_Acceleration_Program: YOLO multi-threaded and hardware-accelerated inference framework based on RKNN![]() https://gitee.com/lrf1125962926/yolo_rknn_acceleration_programGithub:
https://gitee.com/lrf1125962926/yolo_rknn_acceleration_programGithub:
1125962926/YOLO_RKNN_Acceleration_Program: YOLO multi-threaded and hardware-accelerated inference framework based on RKNN![]() https://github.com/1125962926/YOLO_RKNN_Acceleration_Program
https://github.com/1125962926/YOLO_RKNN_Acceleration_Program
—— 貪心)



 流提取運算符的重載和const成員)










)



