技術點目錄
- 第一章、智能體(Agent)入門
- 第二章、基于字節Coze 構建智能體(Agent)
- 第三章、基于其他平臺構建智能體(Agent)
- 第四章、國內外智能體(Agent)經典案例詳解
- 第五章、大語言模型應用開發框架LangChain入門
- 第六章、基于LangChain的大模型API接入
- 第七章、基于LangChain的智能體(Agent)開發
- 第八章、開源大語言模型及本地部署
- 第九章、從0到1搭建第一個大語言模型
- 第十章、大語言模型優化
- 了解更多
———————————————————————————————————————
在 AI 智能體的開發與應用中,如何讓智能體獲取準確且最新的知識是一個關鍵問題。檢索增強生成(RAG)技術的出現,為解決這一難題提供了有效途徑,它通過結合大語言模型和外部知識檢索,極大地強化了 AI 智能體的知識儲備和回答能力。
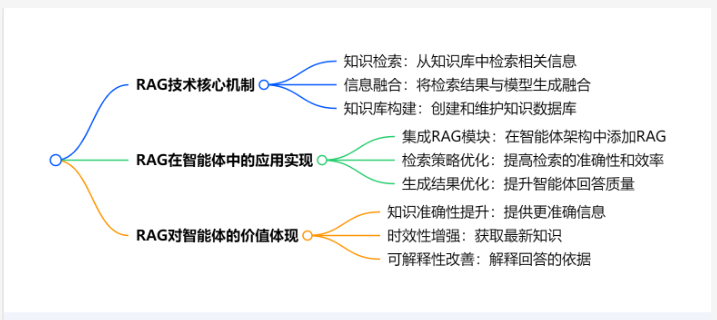
RAG 技術核心機制
RAG 技術的核心之一是知識檢索。它利用向量數據庫等技術,將文本數據轉化為向量形式存儲,當智能體接收到問題時,通過計算向量相似度,從知識庫中快速檢索出相關信息。例如,使用 FAISS 向量數據庫,將大量的新聞文章存儲為向量,當用戶詢問關于某一事件的信息時,能迅速找到相關文章。信息融合是 RAG 的另一個關鍵環節,將檢索到的信息與大語言模型的生成能力相結合。智能體不再單純依賴模型的預訓練知識,而是根據檢索結果生成更準確、更有針對性的回答。知識庫構建也至關重要,需要收集、整理和更新知識數據,確保知識庫的完整性和準確性。比如,構建一個醫療知識庫,包含疾病癥狀、治療方法等信息。
RAG 在智能體中的應用實現
在智能體架構中集成 RAG 模塊,首先要選擇合適的 RAG 框架或工具,如 LangChain 就提供了方便的 RAG 集成功能。通過配置相關參數,將知識庫與大語言模型連接起來。優化檢索策略可以提高檢索的準確性和效率,比如采用語義檢索、多關鍵詞檢索等方式,結合關鍵詞權重調整,使檢索結果更符合用戶需求。在生成結果優化方面,根據檢索到的信息,對大語言模型的輸入進行調整,引導模型生成更優質的回答。例如,在問答系統中,將檢索到的文本作為上下文提供給模型,讓模型基于這些信息生成答案。
RAG 對智能體的價值體現
RAG 技術顯著提升了智能體知識的準確性。由于引入了外部知識庫的檢索,智能體能夠獲取更精確的信息,避免了單純依賴模型預訓練知識可能出現的錯誤。時效性方面,RAG 使智能體可以實時獲取最新知識。比如在金融領域,智能體可以及時檢索到最新的股票行情、財經新聞等信息,為用戶提供最新的市場動態。在可解釋性上,RAG 也有很大改善,因為智能體的回答是基于檢索到的具體信息,能夠清晰地解釋回答的依據,增強用戶對智能體的信任。
檢索增強生成(RAG)技術通過獨特的核心機制,在智能體中的有效應用,為 AI 智能體帶來了知識準確性、時效性和可解釋性等多方面的提升,使其在各種應用場景中更具優勢。
第一章、智能體(Agent)入門
1、智能體(Agent)概述(什么是智能體?智能體的類型和應用場景、典型的智能體應用,如:Google Data Science Agent等)
2、智能體(Agent)與大語言模型(LLM)的關系
3、智能體(Agent)的五種能力(記憶、規劃、工具、自主決策、推理)
4、多智能體(Multi-Agent)協作
5、智能體(Agent)構建的基本步驟
6、案例
第二章、基于字節Coze 構建智能體(Agent)
1、Coze平臺概述
2、(實操)從0到1搭建第一個智能體(Agent)
3、(實操)智能體(Agent)基礎設置(多Agent模式、對話流模式、LLM模型設置、提示詞撰寫等)
4、(實操)為智能體(Agent)添加技能(插件、工作流、觸發器、卡片等)
5、(實操)為智能體(Agent)添加知識(知識庫介紹、添加知識庫、知識庫檢索與召回等)
6、(實操)為智能體(Agent)添加記憶(創建和使用變量、數據庫、長期記憶的開啟、修改和刪除等)
7、(實操)提升智能體(Agent)的對話體驗(設置開場白、快捷指令等)
8、(實操)智能體(Agent)的預覽、調試與發布
9、案例
第三章、基于其他平臺構建智能體(Agent)
1、(實操)基于百度平臺構建智能體
2、(實操)基于智譜清言平臺構建智能體
3、(實操)基于通義千問平臺構建智能體
4、(實操)基于豆包平臺構建智能體
5、案例
第四章、國內外智能體(Agent)經典案例詳解
1、斯坦福小鎮:生成式智能體(Generative Agents)
2、ByteDance Research推出的論文檢索智能體
3、Google Data Science Agent
4、AutoGPT:通過自然語言的需求描述執行自動化任務
5、OpenAI推出的首個智能體(Agent):Operator
6、案例
第五章、大語言模型應用開發框架LangChain入門
1、LangChain平臺概述(LangChain框架的核心功能與特點)
2、(實操)LangChain安裝與使用
3、(實操)LangChain的核心組件:Models(模型)、Prompts(提示詞)、Indexes(索引)、Chains(鏈)、Agents(智能體)、Memory(記憶)
4、案例
第六章、基于LangChain的大模型API接入
1、(實操)在LangChain 中使用OpenAI大語言模型
2、(實操)在LangChain 中使用文心一言大語言模型
3、(實操)在LangChain 中使用DeepSeek大語言模型
4、(實操)在LangChain 中使用智譜清言大語言模型
5、(實操)在LangChain 中使用本地開源大語言模型
6、案例
第七章、基于LangChain的智能體(Agent)開發
1、使用LangChain構建Agent的使用流程
2、(實操)LangChain的配置與管理
3、(實操)LangChain提示詞模板(PromptTemplate)的創建與調用
4、(實操)利用LLMRequestsChain類實現從互聯網獲取信息(查詢天氣等)
5、(實操)LangChain鏈式請求的創建與調用
6、(實操)LangChain讓AI記住你說過的話
7、案例
第八章、開源大語言模型及本地部署
1、開源大語言模型簡介(開源大語言模型的基本概念、開源大語言模型與閉源大語言模型的對比)
2、(實操)開源大語言模型(Llama3、Mistral、Phi3、Qwen2、DeepSeek等)下載與使用
3、(實操)使用Docker部署開源大語言模型(Docker的基本概念、Docker的核心組件與功能、Docker的安裝與配置、在Docker中部署Llama3等開源大語言模型)
4、(實操)使用Open-WebUI構建Web可視化交互(類似ChatGPT)的開源大語言模型對話系統(Open-WebUI的基本概念與功能、Open-WebUI的下載與安裝、配置一個用于對話系統的Open-WebUI)
5、案例
第九章、從0到1搭建第一個大語言模型
1、(實操)數據集構建(數據集的收集與處理、從互聯網上收集文本數據、數據清洗與標注、常用的數據集格式,如:CSV、JSON、TXT等)
2、(實操)大語言預訓練模型的選擇(預訓練模型的優勢、常見的預訓練模型,如:GPT、BERT等、從Hugging Face等平臺下載預訓練模型)
3、(實操)大語言模型的訓練(模型訓練的基本步驟、訓練過程中的監控與調試)
4、(實操)大語言模型的優化(常見訓練參數,如:學習率、批次大小等、參數調整與優化技巧、優化訓練參數以提高模型性能)
5、(實操)大語言模型的推理(模型推理與模型訓練的區別、提高推理速度的技巧、從輸入到輸出的完整推理流程)
6、(實操)大語言模型的部署與應用(模型部署的基本流程、部署環境的配置與管理)
7、案例
第十章、大語言模型優化
1、檢索增強生成(RAG)技術詳解(RAG的基本原理、RAG在大語言模型中的作用和優勢、RAG的系統架構、RAG檢索結果與生成結果相結合的方法、RAG知識庫的構建方法)
2、向量數據庫簡介與向量檢索技術詳解(使用向量數據庫進行快速檢索)
3、文本嵌入(Text Embedding)技術概述(常用的文本嵌入模型、使用GPT API)
4、(實操)基于RAG的問答系統設計
5、微調(Fine-Tuning)技術詳解(微調的基本原理、微調在大語言模型中的作用、準備一個用于微調的數據集、常見的微調方法,如PEFT、LoRA等、不同任務的微調策略、微調過程中的常見問題與解決方案)
6、(實操)微調一個預訓練的GPT模型
7、量化技術詳解(量化的基本概念、量化在模型優化中的重要性、量化的不同方法,如:靜態量化、動態量化、混合量化等、量化處理的步驟)
8、案例
了解更多
V頭像



)












)


)