前面已經完成了Ollama的安裝并下載了deepseek大模型包,下面介紹如何與anythingLLM 集成
Windows環境下AnythingLLM安裝與Ollama+DeepSeek集成指南
一、安裝準備
1. 硬件要求
如上文說明
2. 前置條件
- 已安裝Ollama并下載DeepSeek模型(如
deepseek-r1:1.5b)
二、安裝AnythingLLM
方法一:桌面版安裝(推薦新手)
-
訪問官網下載安裝包
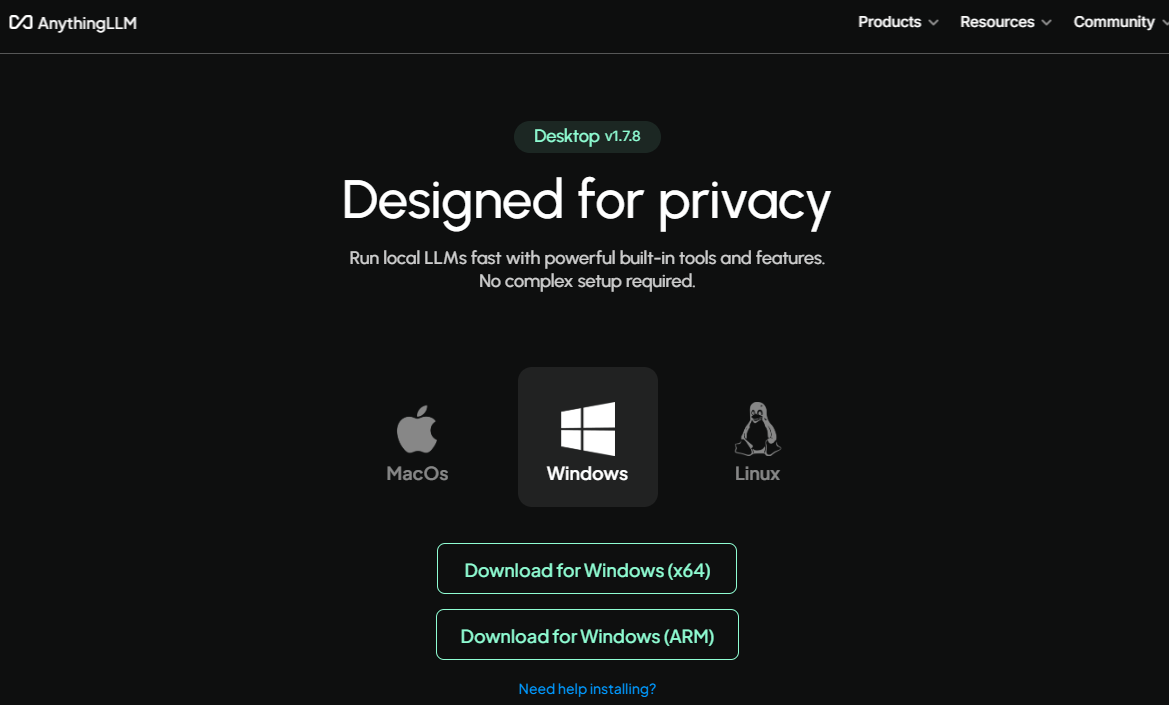
-
點擊安裝包AnythingLLMDesktop.exe進行安裝,注意自定義安裝路徑(避免C盤空間不足):
# 示例:命令行安裝到D盤 msiexec /i AnythingLLMDesktop.exe INSTALLDIR="D:\AI_Tools\AnythingLLM"
方法二:Docker部署(適合高級用戶/未驗證)
# 拉取鏡像(國內鏡像加速)
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/mintplexlabs/anythingllm# 啟動容器(修改存儲路徑)
docker run -d -p 3000:3000 -v D:/anythingllm_storage:/app/server/storage mintplexlabs/anythingllm
三、集成Ollama與DeepSeek
- 啟動AnythingLLM
- **Settings > LLM 配置:
- LLM Provider:
Ollama - Base URL:
http://127.0.0.1:11434(Ollama默認端口) - Model: 選擇已下載的
deepseek-r1:1.5b
- LLM Provider:
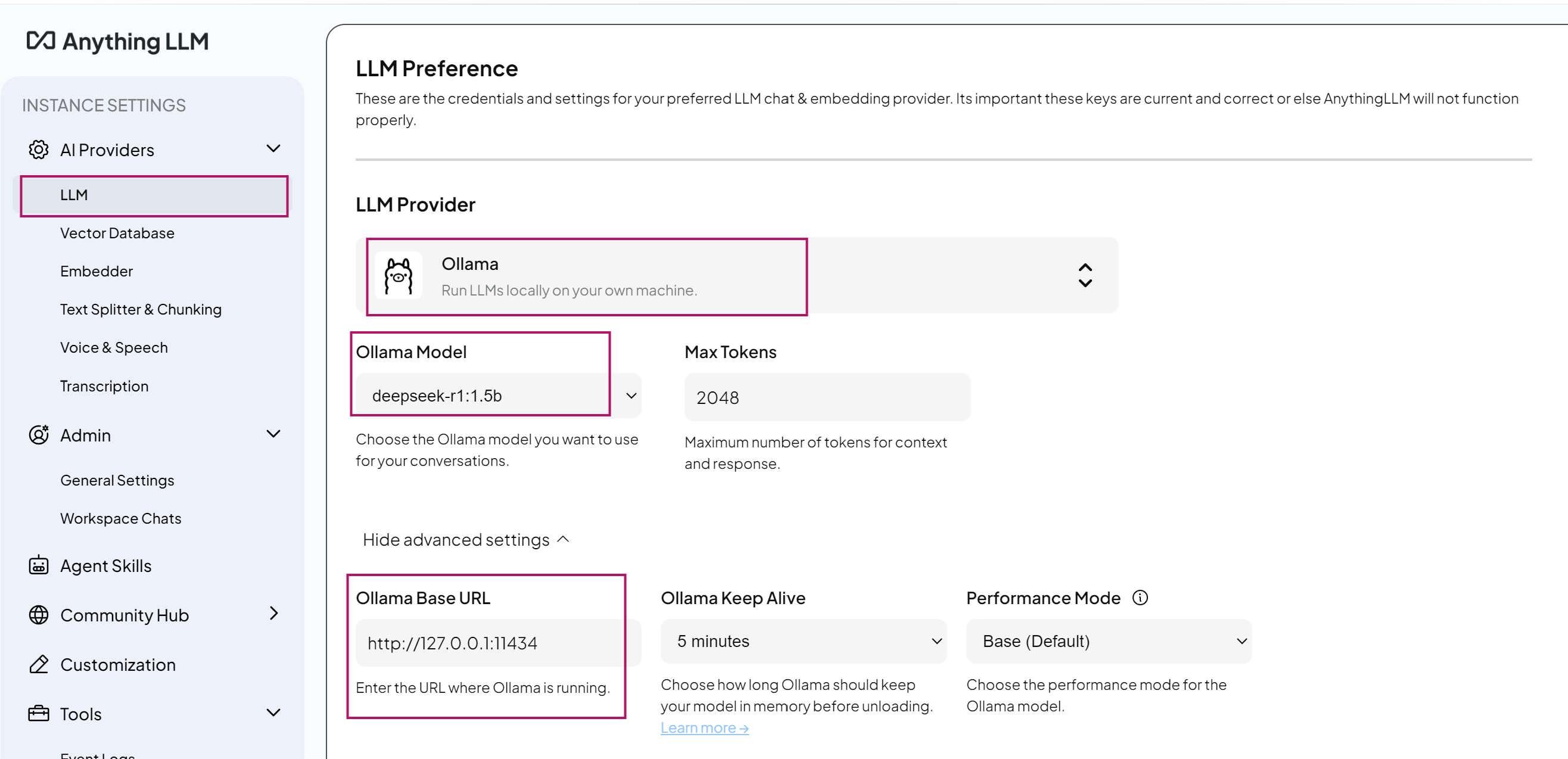
- 中文界面設置(可選):
- 左下角設置圖標Settings > Customization > Language選擇
Chinese

- 左下角設置圖標Settings > Customization > Language選擇
四、關鍵參數配置
1. 模型推理參數
| 參數 | 推薦值 | 技術說明 | 配置路徑 |
|---|---|---|---|
| ?Temperature | 0.2-0.5 | 控制生成隨機性(技術文檔0.2,創意寫作0.5) | Workspace Settings >Chat Settings |
| ?Max Tokens | 4096-8960 | 是單次回復的最大長度, 需≤模型上下文窗口 | Settings>LLM |
| ?Top P | 0.85-0.95 | 核采樣閾值,高于0.9可能產生幻覺 | 需通過API或Modelfile設置 |
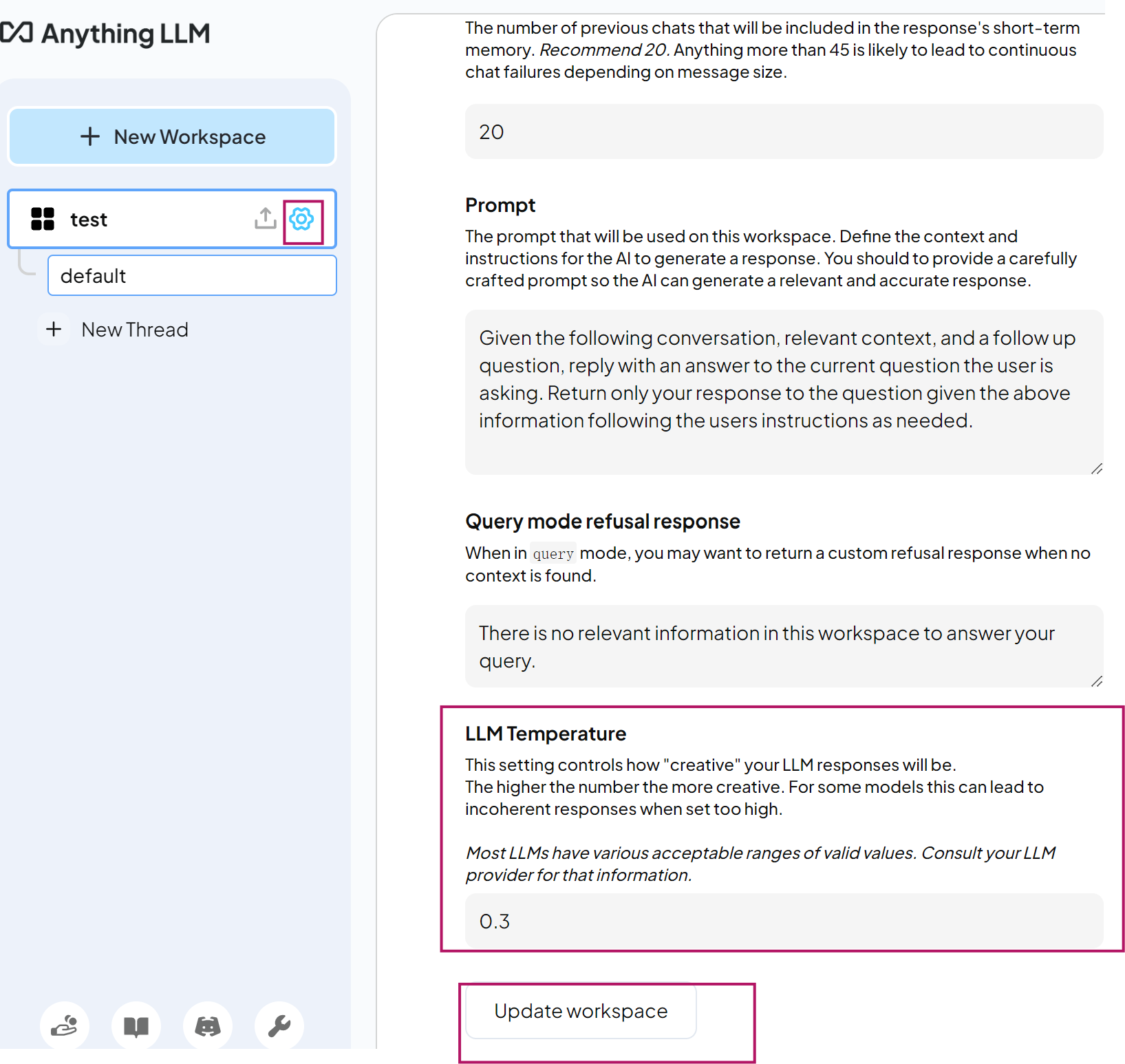
Max Tokens超限問題:
一般推薦如下,:
- 簡短回答:50-200 tokens
- 段落生成:200-1000 tokens
- 長文寫作:2000-5000 tokens
主流DeepSeek模型max tokens參考
| 模型名稱 | 最大上下文 | 默認輸出限制 | 適用場景 |
|---|---|---|---|
| DeepSeek-V3 | 128K | 4K | 長文檔處理、復雜推理 |
| DeepSeek-R1-7B | 32K | 4K | 通用問答、代碼生成 |
| DeepSeek-R1-1.5B | 16K | 2K | 輕量級任務、邊緣設備 |
- 設置值≤模型metadata中的"context length"
2. 知識庫相關參數
| 參數 | 推薦值 | 作用原理 | 配置位置 |
|---|---|---|---|
| ?Chunk Size | 512-1000 | 文本分塊大小(技術文檔512,長文本1000) | Settings > Text splitter&Chunking |
| ?Chunk Overlap | 20%-30% | 防止關鍵信息被切斷(如512塊設128重疊) | 同上 |
| ?Similarity Threshold | 75%-85% | 越高檢索越精準(低于60%可能引入噪聲) | Workspace Settings > Vector Database |
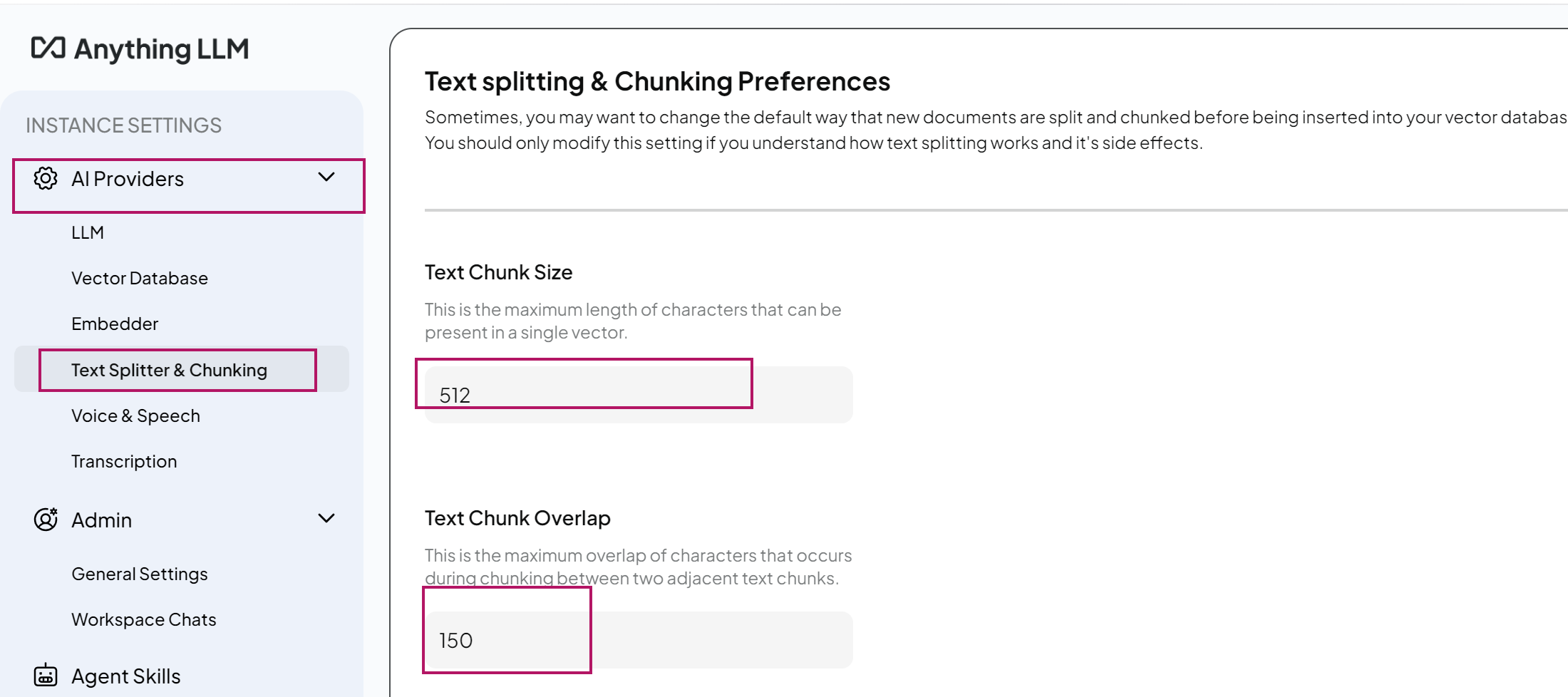

3. 向量模型配置(必需)
# 下載嵌入模型(推薦BGE-M3)
ollama pull bge-m3
在AnythingLLM中設置:
- Embedder Provider:
Ollama - Embedding Model:
bge-m3
4. 文檔處理參數
| 參數 | 技術說明 | 推薦值 |
|---|---|---|
| Max Embedding Length | 需≤向量模型context_length(如bge-m3支持8192) | 512 |
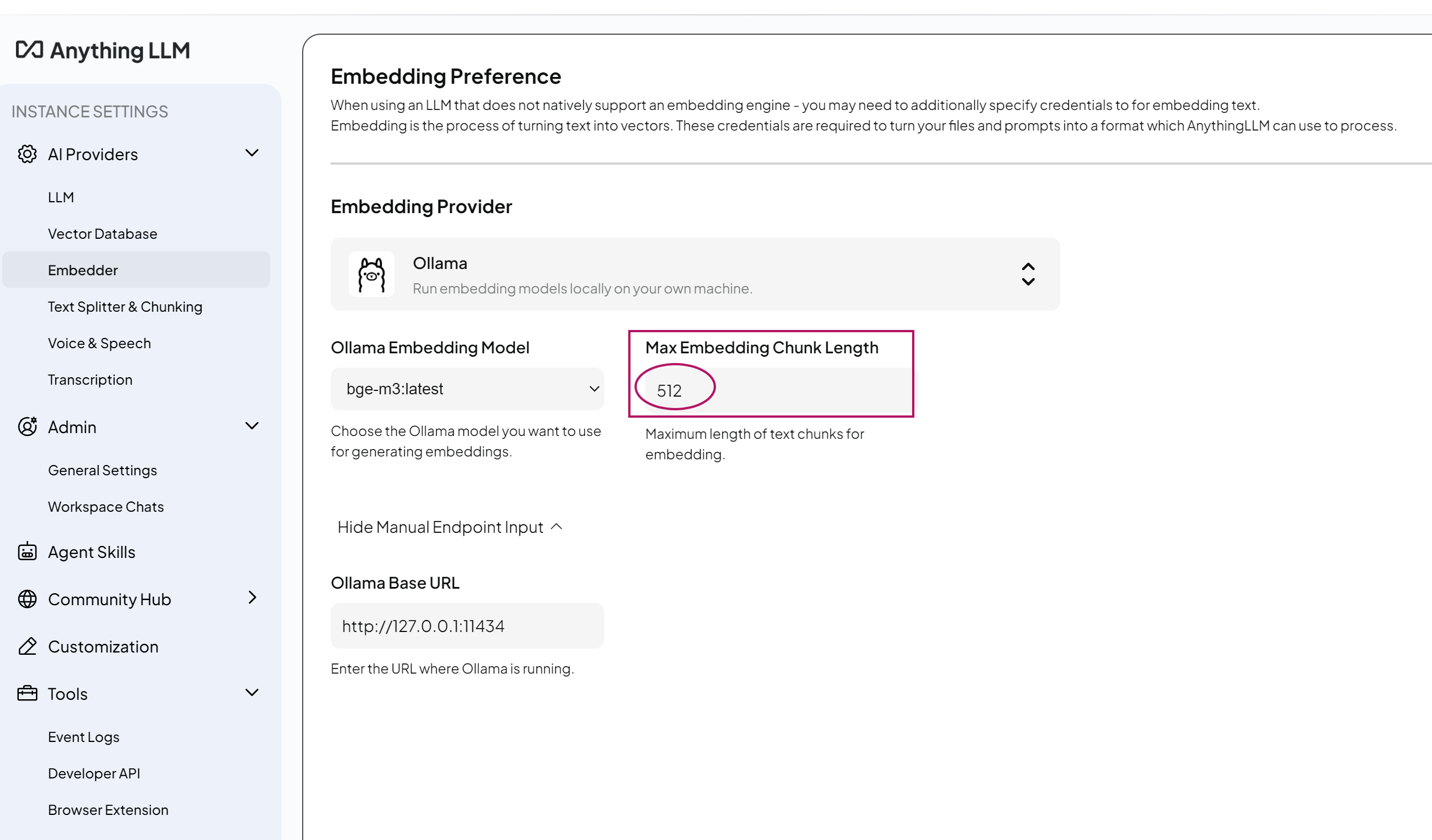
五、知識庫功能實現
1. 文檔上傳
支持格式:PDF/DOCX/TXT/Markdown等
- 進入工作區點擊
Upload - 拖拽文件或選擇本地文檔
- 點擊
Save and Embed進行向量化,(機器性能不好的話,會法輪長轉,建議用純文本進行測試) - 把文檔釘住
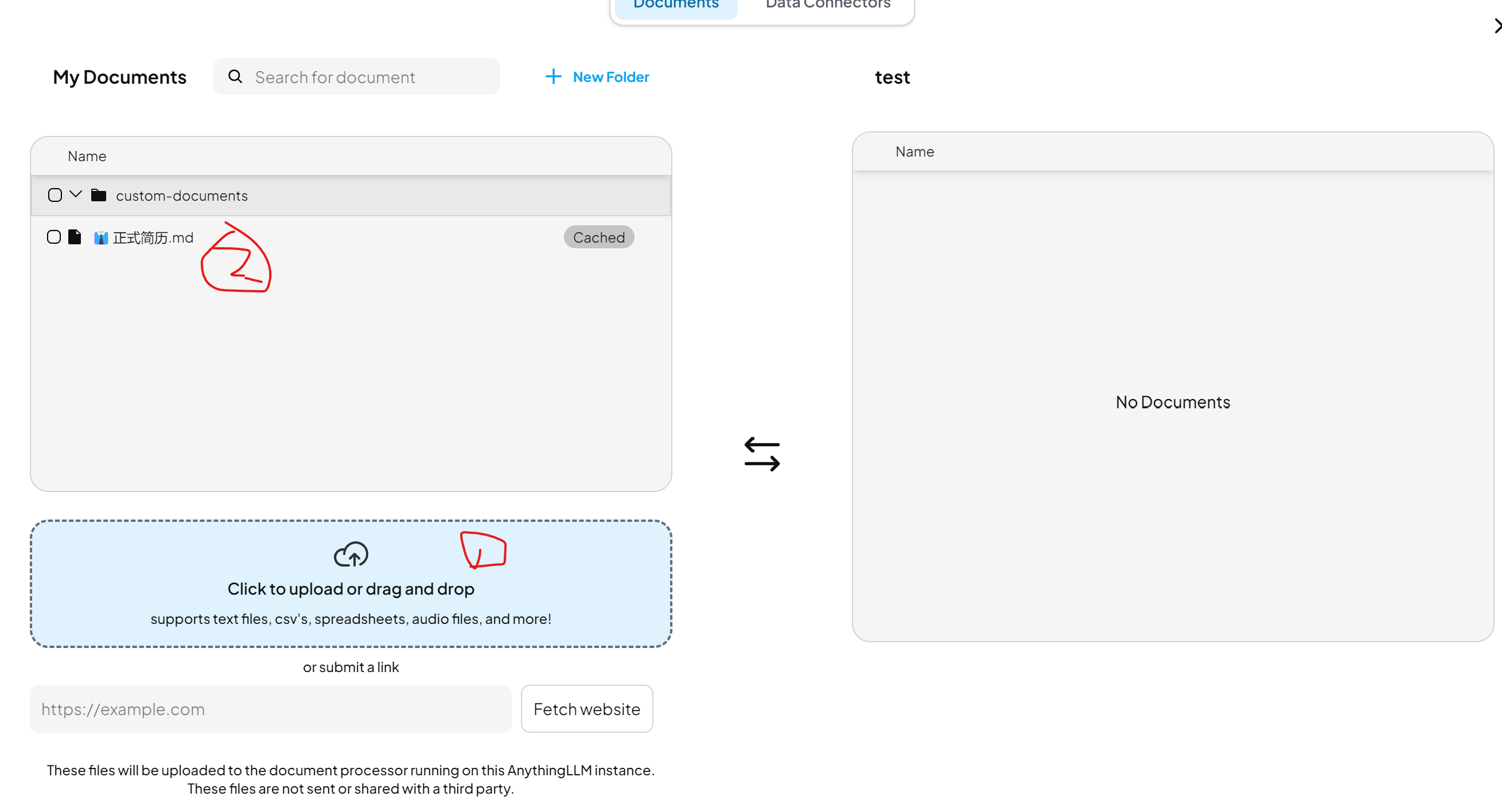
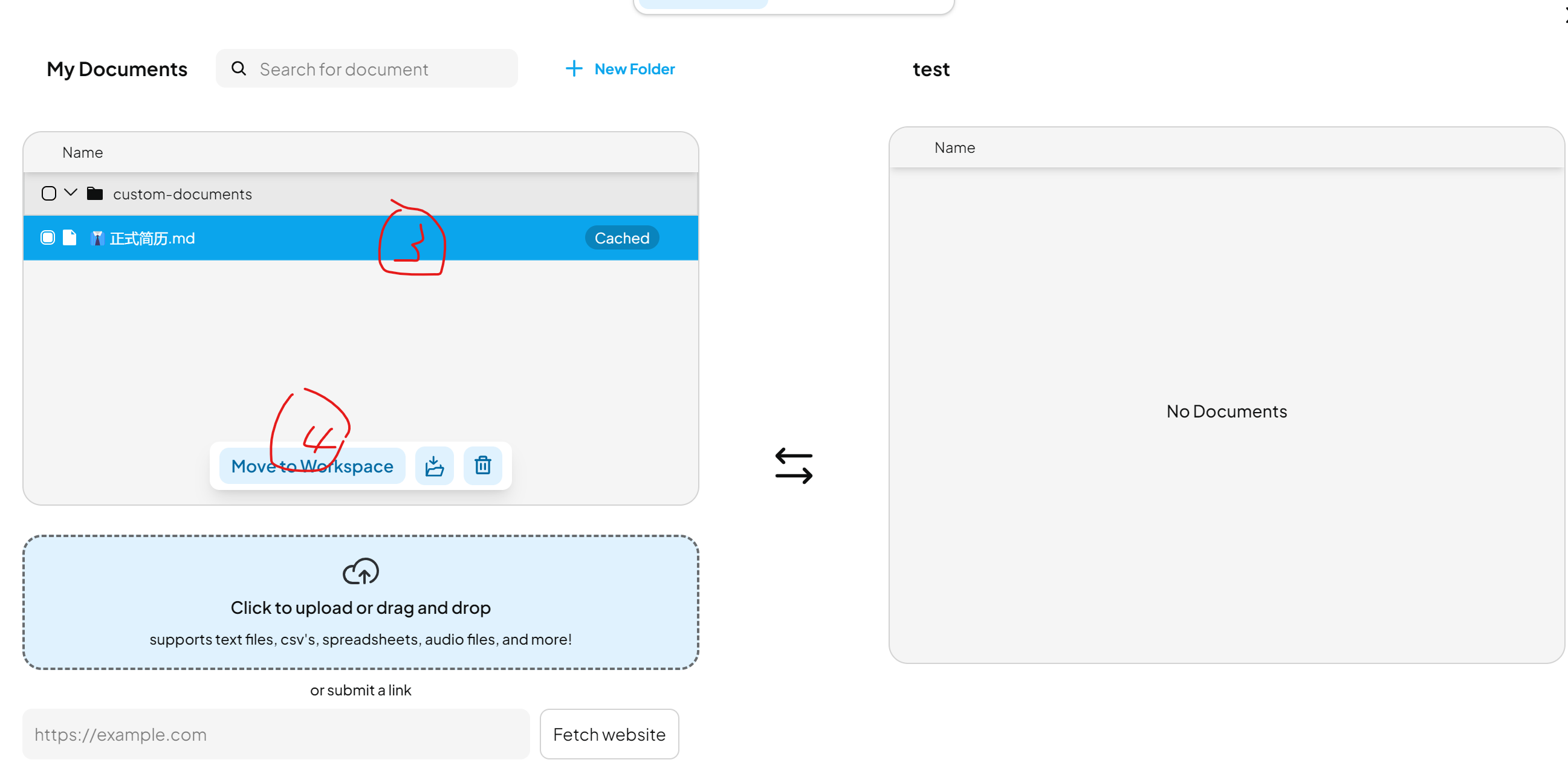
5.現在可以開始用你上傳的文件作為知識庫進行問答了。

六、性能優化建議
1. GPU加速(NVIDIA顯卡)
# 設置環境變量
setx OLLAMA_GPU_LAYERS 40 # 40層GPU推理(根據顯存調整)
setx CUDA_VISIBLE_DEVICES "GPU-UUID" # 通過nvidia-smi -L查詢
2. 內存鎖定(大內存設備)
setx OLLAMA_USE_MLOCK 1 # 防止內存換頁
七、常見問題解決
-
模型加載失敗:
- 檢查Ollama服務是否運行:
ollama serve - 驗證模型是否存在:
ollama list
- 檢查Ollama服務是否運行:
-
響應速度慢:
- 降低
Max Tokens值至2048 - 減少同時處理的文檔數量
- 降低
技術文檔問答配置(參考)
# 保存為tech_config.yaml
temperature: 0.2
max_tokens: 6144
chunk_size: 512
chunk_overlap: 128
similarity_threshold: 85%
embedder: bge-m3-zh
主流DeepSeek模型max tokens參考
| 模型名稱 | 最大上下文 | 默認輸出限制 | 適用場景 |
|---|---|---|---|
| DeepSeek-V3 | 128K | 4K | 長文檔處理、復雜推理 |
| DeepSeek-R1-7B | 32K | 4K | 通用問答、代碼生成 |
| DeepSeek-R1-1.5B | 16K | 2K | 輕量級任務、邊緣設備 |
注意事項:
- 實際可用max tokens = 模型上限 - 輸入tokens
- 中文場景下1 token≈1.5漢字,計算時需預留20%緩沖
- 超出限制會導致截斷,建議通過流式輸出處理長內容





)










介紹)

基礎知識2)
