簡介:
“本文為AI開發者揭秘如何在阿里云2核2G輕量級ECS服務器上,通過Ubuntu系統與Ollama框架實現Deepseek模型的高效部署。無需昂貴硬件,手把手教程涵蓋環境配置、資源優化及避坑指南,助力初學者用極低成本在云端跑通行業領先的大語言模型,解鎖輕量化服務器運行AI任務的無限可能!”
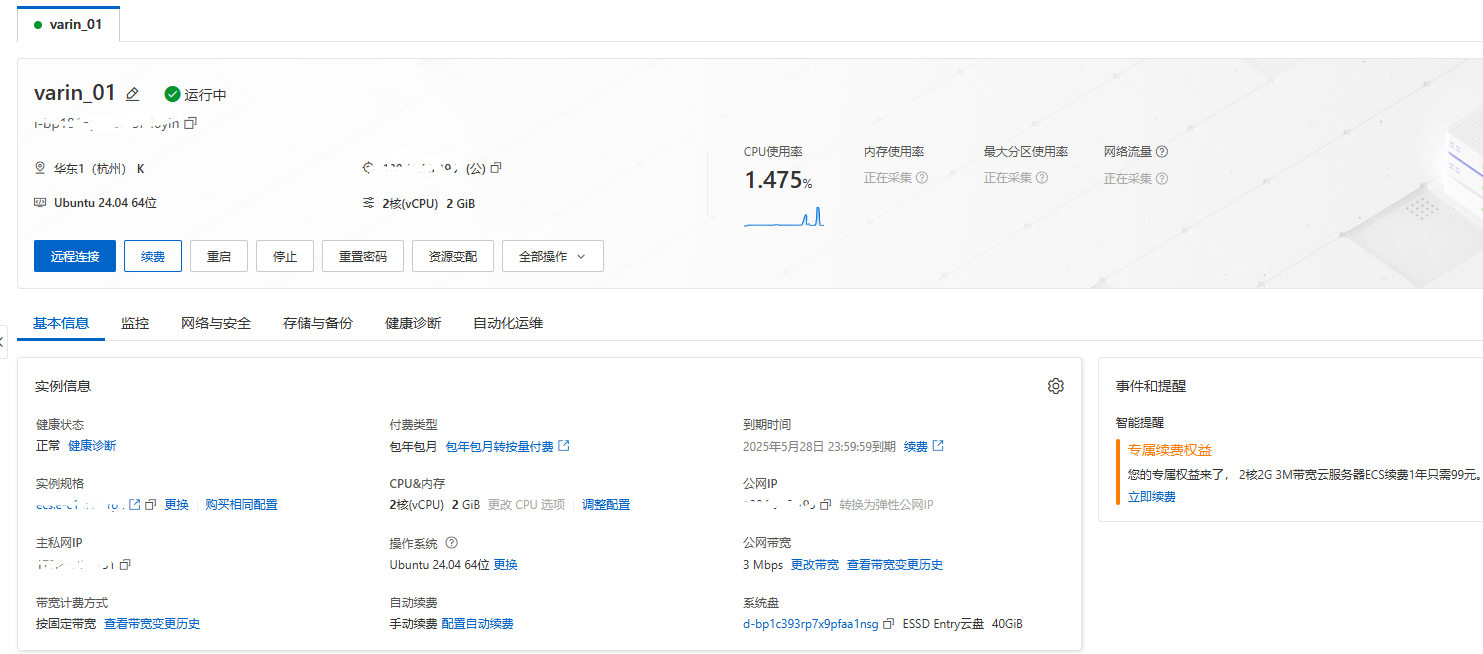
一、環境準備清單
服務器
服務器:Ubuntu 24.04 64位
CPU&內存:2核(CPU) & 2 GiB
ESSD Entry云盤:40GB

SSH軟件
MobaXterm_Personal_21.4
Deepseek版本
本教程選擇:DeepSeek-R1-Distill-Qwen-1.5B
官方推薦配置
DeepSeek R1 模型參數和顯存需求:
| 模型名稱 | 參數量 | 顯存需求 | 推薦顯卡型號(最低) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 4-6 GB | GTX 1660 Ti、RTX 2060 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | 12-16 GB | RTX 3060、RTX 3080 |
| DeepSeek-R1-Distill-Llama-8B | 8B | 16-20 GB | RTX 3080 Ti、RTX 3090 |
| DeepSeek-R1-Distill-Qwen-14B | 14B | 24-32 GB | RTX 3090、RTX 4090 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 48-64 GB | A100、H100 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 80-128 GB | A100、H100、MI250X |
二、Shell工具連接云服務器
- 點擊右上角的:Session
- 點擊SSH
- 輸入host和username點擊OK
- 輸入密碼即可




三、安裝Ollama
簡介:
Ollama 是一款專注于本地化AI模型運行與管理的開源工具,其核心功能在于實現模型的輕量化部署與全生命周期維護,通過容器化封裝與資源調度優化,顯著降低開發者在本地環境構建私有AI服務的技術門檻。
github地址:https://github.com/ollama/ollama
Linux版安裝
# Linxu安裝
curl -fsSL https://ollama.com/install.sh | sh
本地解壓版
由于網速的原因,很難將Linux版本的ollama下載下載,所以本文提供了tgz文件,從而實現解壓安裝。
網盤地址:https://pan.baidu.com/s/1mx_3R4NVjOSC9D8BaGdYHg?pwd=9eg7
- 步驟一:在服務器上建立一個空的文件夾,用來存放ollama文件
mkdir ollama
- 適用工具將壓縮包上傳到服務器上
工具:WinSCP-5.21.5-Setup
地址:https://pan.baidu.com/s/1mx_3R4NVjOSC9D8BaGdYHg?pwd=9eg7
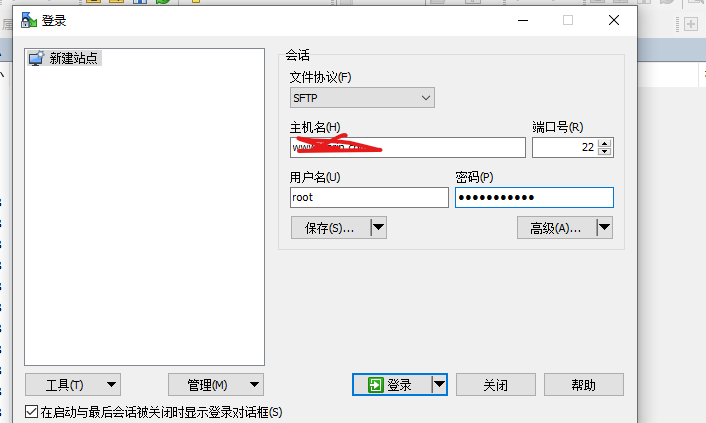
打開軟件后,輸入服務器的ip、用戶名、密碼
上傳完成

# 解壓命令
# tar -zxvf
sudo -zxvf ollama-linux-amd64.tgz
# 將解壓后ollama文件夾的bin目錄中的ollama復制到 /usr/bin中
cp bin/ollama /usr/bin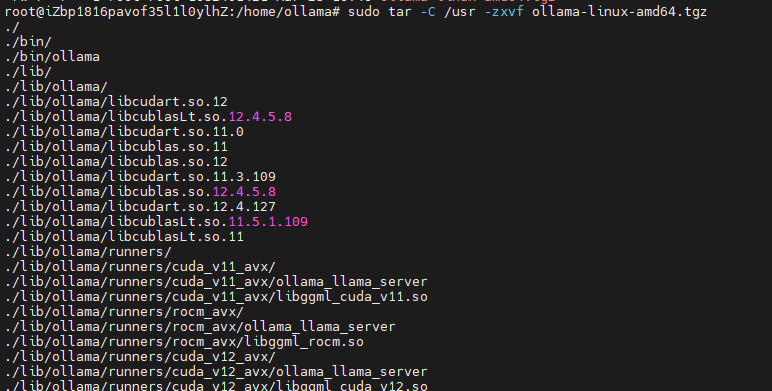
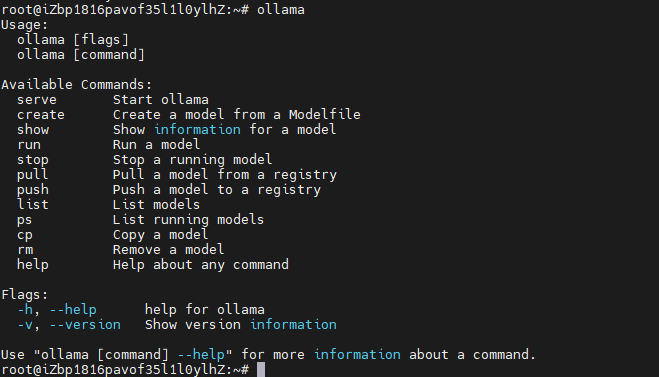
# 測試是否安裝成功,出現命令幫助表示為ollama安裝成功
ollama
使用魔塔社區安裝(建議使用)
官網安裝教程:https://www.modelscope.cn/models/modelscope/ollama-linux
- 首先要安裝支持大模型支持的環境:ModelScope Notebook
官網安裝教程:https://modelscope.cn/notebook/share/ipynb/4a85790f/ollama-installation.ipynb
注意點:安裝該平臺需要服務器上有python和pip的環境
- 安裝python和pip
sudo apt install python3
sudo apt install pip
- 安裝ModelScope Notebook
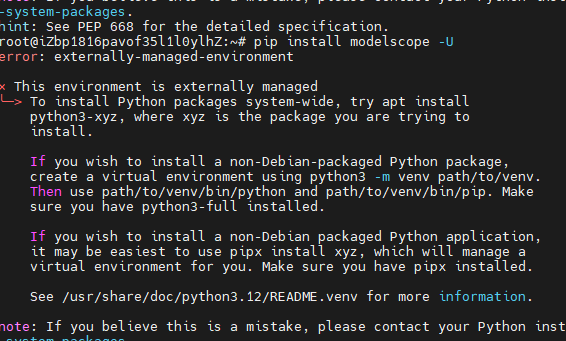
# 本教程在使用此命令時,會發生錯誤
pip install modelscope -U
解決方案:
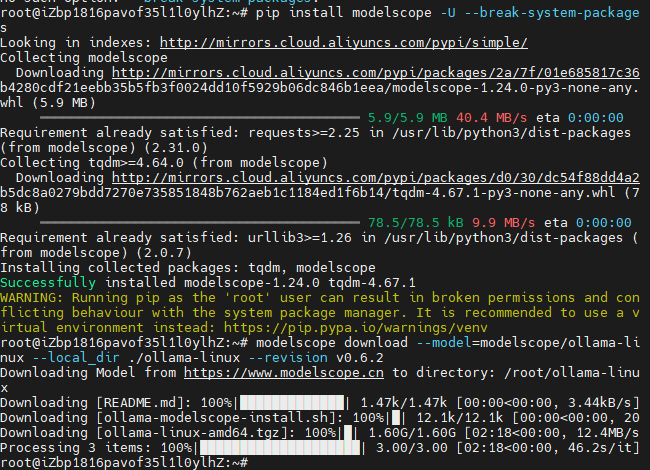
# 強制安裝,無視風險pip install modelscope -U --break-system-package s.
# 以下為安裝成功的截圖
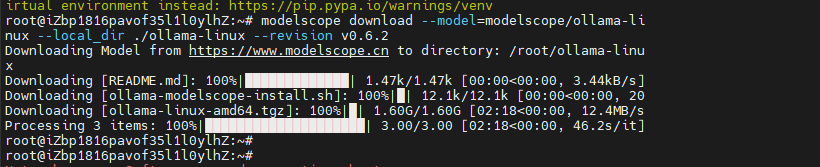
- 從ModelScope上下載Ollama安裝包
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.6.2
- 安裝ollama
cd ollama-linux && sudo chmod +x ./ollama-modelscope-install.sh && ./ollama-modelscope-install.sh
# 查看版本號
ollama --version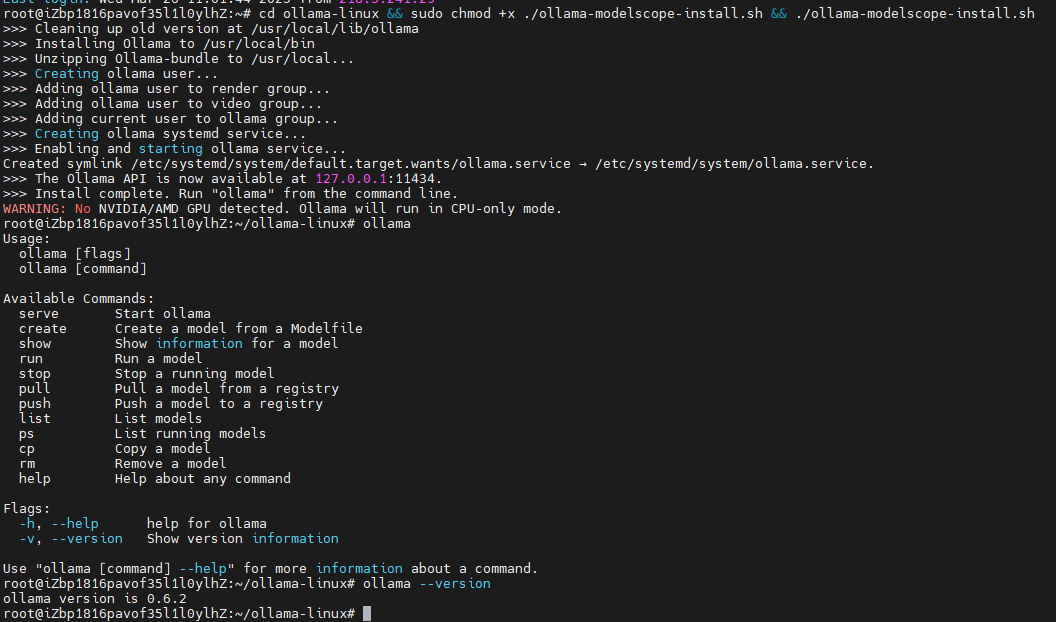
- 啟動ollama
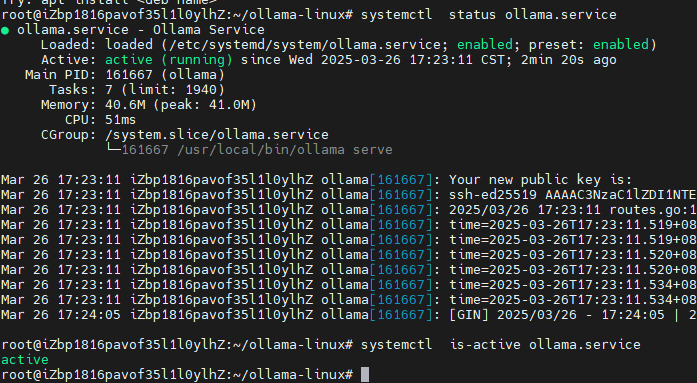
systemctl start ollama.service
# 查看服務活動狀態
systemtcl status ollama.servicesystemctl is-active ollama.servie
啟動Ollama(魔塔安裝或直接安裝可忽略此步驟)
# 檢測是否啟動 active 為啟動;inactive為未啟動systemctl is-active ollama.serviesystemctl status ollama.service
# 啟動systemctl start ollama.service
# 啟動命令:
systemctl start ollama.service
# 結果:發現并不存在ollama.service

創建ollama.service文件(魔塔安裝或直接安裝可忽略此步驟)
- 建一個新的服務文件 /etc/systemd/system/ollama.service
切換到/etc/systemd/system
創建ollama.service
cd /etc/systemd/system
vim ollama.service
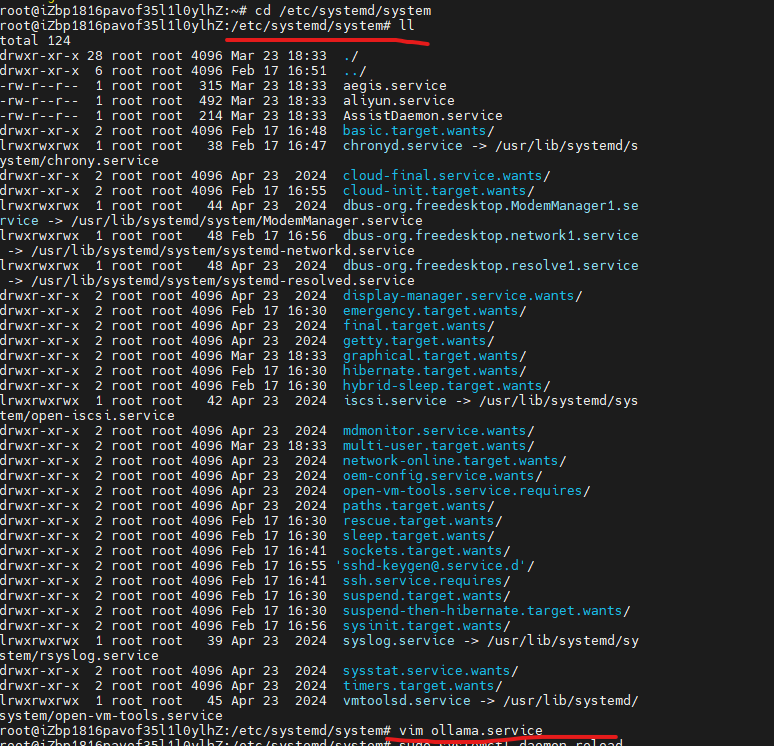
- 文件內容格式
Description 是服務的簡單描述。
After 指定了在哪個服務啟動后啟動此服務。
Type 定義了服務進程的啟動類型,simple 表示啟動主進程。
User 指定運行服務的用戶,本文用的是root ,你也可以用其他賬戶。
WorkingDirectory 設置服務的工作目錄,本文用的/root,你也可以切換成其他用戶目錄。
ExecStart 指定啟動服務的命令。命令位置為:/usr/bin/ollama 中的serve
Restart 指定服務崩潰時的重啟策略。
RestartSec 設置重啟服務前等待的時間。
WantedBy 指定了服務所在的 target,multi-user.target 表示多用戶系統。
[Unit]
Description=Ollama Service
After=network.target[Service]
Type=simple
User=root
WorkingDirectory=/root
ExecStart=/usr/bin/ollama serve
Restart=on-failure
RestartSec=30[Install]
WantedBy=multi-user.target# 修改完后,切換到vim的命令格式輸入:qw保存
# 步驟1: 按Esc
# 步驟2::wq
- 重新加載服務單元文件
命令解釋:
在修改了某個服務單元文件后,想要讓更改生效,所以需要執行這個命令。需要明確的是,當用戶修改的是/etc/systemd/system/下的服務文件時,應該使用daemon-reload。但如果修改的是systemd本身的配置文件比如system.conf,則需要用daemon-reexec,
sudo systemctl daemon-reload
再次啟動ollama(此步驟為離線包安裝步驟)
# 查看服務狀態
systemctl status ollama.service
systemctl is-active ollama.service
# 啟動
systemctl start ollama.service
# 設置服務開機自啟動
systemctl enable ollama.service
當前的服務狀態圖:(已啟動)
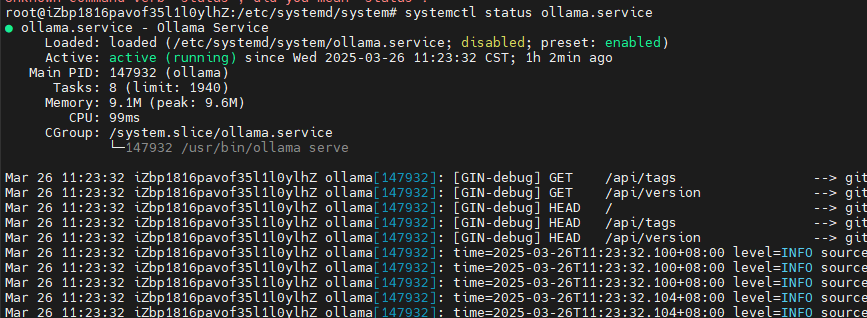

開機自啟動

四、Deepseek內存需求對比表(推理模式)
| 模型規模 | 數據類型 | 理論參數內存 | 實際顯存估算(含激活值) | 推薦顯存配置 |
|---|---|---|---|---|
| 1.5B | FP16 | 3 GiB | 3.6-4.5 GiB | 6-8 GB |
| Int8 | 1.5 GiB | 1.95-2.4 GiB | 4 GB+ | |
| 7B | FP16 | 14 GiB | 16.8-21 GiB | 24 GB |
| Int8 | 7 GiB | 8.4-10.5 GiB | 12 GB+ | |
| 13B | FP16 | 26 GiB | 31.2-39 GiB | 40 GB+ |
| Int8 | 13 GiB | 15.6-19.5 GiB | 24 GB+ | |
| 33B | FP16 | 66 GiB | 79.2-99 GiB | 多卡并行 |
| Int8 | 33 GiB | 39.6-49.5 GiB | 48 GB+ | |
| 70B | FP16 | 140 GiB | 168-210 GiB | 多卡并行 |
| Int8 | 70 GiB | 84-105 GiB | 多卡并行 |
五、內存不足解決方案-虛擬內存
因為我們的云服務器只有2G的內存,所以將虛擬內存作為解決方案

? 技術定義
虛擬內存(Swap)是通過將磁盤空間模擬為內存使用的技術,當物理內存不足時,系統會將非活躍內存頁暫存至磁盤交換區。
? 核心運行機制
物理內存(2GB) ←→ 交換分區/文件(如12GB)│└─ 內核通過分頁算法自動管理熱數據
虛擬內存的優劣對比
| 優勢 | 劣勢 |
|---|---|
| 內存擴展:突破物理內存限制 | 性能損失:磁盤I/O速度比內存慢100-1000倍 |
| 防OOM:避免程序崩潰 | 硬件損耗:SSD頻繁寫入降低壽命 |
| 成本低:無需硬件升級 | 安全風險:交換文件可能泄漏敏感數據 |
| 彈性配置:按需調整大小 | 響應延遲:交換抖動(Thrashing)導致卡頓 |
? 搭建模型使用虛擬內存優劣對比分析表
| 優勢 | 劣勢 |
|---|---|
| ?** 突破硬件限制**:總可用內存達14GB(2+12) | ?** 性能斷崖下降**:推理速度可能從3.2 tokens/s降至0.3-0.8 tokens/s |
| ?** 防OOM崩潰**:可支撐約512 tokens上下文 | ?** SSD壽命風險**:模型運行時可能產生15-30GB/日的寫入量(SSD壽命約300TBW) |
| ?** 零硬件成本**:僅需磁盤空間 | ?** 響應不可靠**:P99延遲可能超過5秒 |
| ?** 快速部署**:30分鐘內完成配置 | ?** 功能閹割**:需關閉attention優化等特性 |
? 詳細構建步驟(Ubuntu系統)
1. 創建12GB Swap文件
# 使用快速分配(需fallocate支持)
sudo fallocate -l 12G /swapfile
# 傳統方式(若無fallocate):
# sudo dd if=/dev/zero of=/swapfile bs=1G count=12 status=progress# 設置權限
sudo chmod 600 /swapfile# 格式化為Swap
sudo mkswap /swapfile# 立即啟用
sudo swapon /swapfile
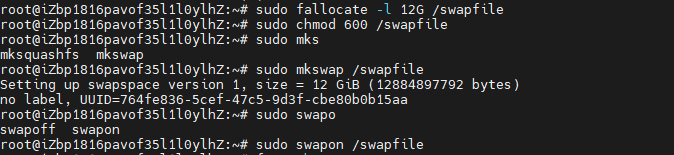
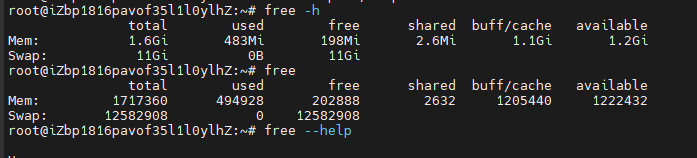
2. 查詢內存分配
free -h
swapon --show

3. 云服務器持久化配置
- 永久生效:通過修改 /etc/fstab,系統每次啟動時會自動掛載 /swapfile作為 Swap 空間。
- 避免手動重復配:解決臨時 Swap 配置(如 swapon /swapfile)在重啟后失效的問題。
- 安全性:追加寫入(-a)確保不破壞原有配置,但仍建議提前備份 /etc/fstab
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab

六、下載Deepseek模型
官網地址:https://ollama.com/library/deepseek-r1:1.5b
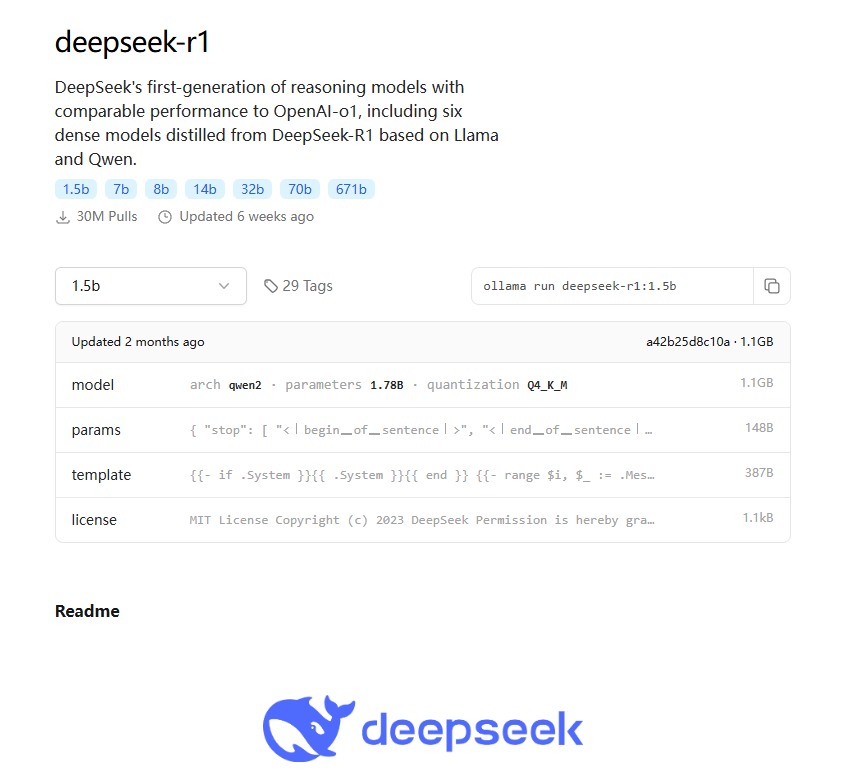
# 下載模型并直接運行模型:
ollama run deepseek-r1:1.5b
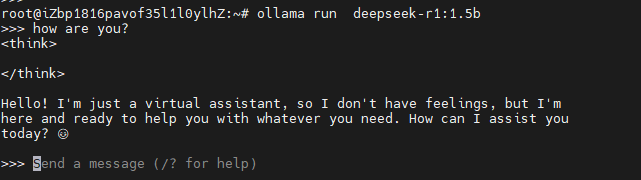


















.zip)
