先談論校驗方法,本人騰訊云大數據工程師。
1、hdfs的校驗
這個通常就是distcp校驗,hdfs通過distcp遷移到另一個集群,怎么校驗你的對不對。
有人會說,默認會有校驗CRC校驗。我們關閉了,為什么關閉?全量遷移,如果當前表再寫數據,開自動校驗就會失敗。數據量大(PB級)遷移流程是先遷移全量,后面在定時補最近幾天增量,再找個時間點,進行業務割接
那么怎么知道你遷移的hdfs是否有問題呢?
2個文件,一個是腳本,一個是需要校驗的目錄
data_checksum.py
# -*- coding: utf-8 -*-
# @Time : 2025/1/16 22:52
# @Author : fly-wlx
# @Email : xxx@163.com
# @File : data_compare.py
# @Software: PyCharmimport subprocess#output_file = 'data_checksum_result.txt'
def load_file_paths_from_conf(conf_file):file_list = []with open(conf_file, 'r') as file:lines = file.readlines()for line in lines:path = line.strip()if path and not path.startswith('#'): # 跳過空行和注釋full_path = f"{path}"file_list.append(full_path)return file_list#def write_sizes_to_file(filepath,source_namenode,source_checksum,target_namenode,target_checksum,status, output_file):
# with open(output_file, 'w') as file:
#file.write(f"{source_namenode}/{filepath},{source_checksum},{target_namenode}/{filepath},{target_checksum},{status}\n")def write_sizes_to_file(source_path, src_info, destination_path, target_info, status,output_file):with open(output_file, 'a') as file:file.write(f"{source_path},{src_info},{destination_path}, {target_info}, {status}\n")
def run_hadoop_command(command):"""運行 Hadoop 命令并返回輸出"""try:result = subprocess.check_output(command, shell=True, text=True)return result.strip()except subprocess.CalledProcessError as e:print(f"Command failed: {e}")return Nonedef get_hdfs_count(hdfs_filepath):"""獲取 HDFS 路徑的文件和目錄統計信息"""command = f"hadoop fs -count {hdfs_filepath}"output = run_hadoop_command(command)if output:parts = output.split()if len(parts) >= 3:dir_count, file_count, content_size = parts[-3:]return dir_count, file_count, content_sizereturn None, None, Nonedef get_hdfs_size(hdfs_filepath):"""獲取 HDFS 路徑的總文件大小"""command = f"hadoop fs -du -s {hdfs_filepath}"output = run_hadoop_command(command)if output:parts = output.split()if len(parts) >= 1:return parts[0]return Nonedef validate_hdfs_data(source_namenode, target_namenode,filepath):output_file = 'data_checksum_result.txt'source_path=f"{source_namenode}/{filepath}"destination_path = f"{target_namenode}/{filepath}""""校驗 HDFS 源路徑和目標路徑的數據一致性"""print("Fetching source path statistics...")src_dir_count, src_file_count, src_content_size = get_hdfs_count(source_path)src_total_size = get_hdfs_size(source_path)print("Fetching destination path statistics...")dest_dir_count, dest_file_count, dest_content_size = get_hdfs_count(destination_path)dest_total_size = get_hdfs_size(destination_path)src_info={}src_info["src_dir_count"] = src_dir_countsrc_info["src_file_count"] = src_file_count#src_info["src_content_size"] = src_content_sizesrc_info["src_total_size"] = src_total_sizetarget_info = {}target_info["src_dir_count"] = dest_dir_counttarget_info["src_file_count"] = dest_file_count#target_info["src_content_size"] = dest_content_sizetarget_info["src_total_size"] = dest_total_sizeprint("\nValidation Results:")if (src_dir_count == dest_dir_count andsrc_file_count == dest_file_count and# src_content_size == dest_content_size andsrc_total_size == dest_total_size):print("? Source and destination paths are consistent!")write_sizes_to_file(source_path, src_info, destination_path,target_info, 0,output_file)else:print("? Source and destination paths are inconsistent!")write_sizes_to_file(source_path, src_info, destination_path, target_info, 1,output_file)#print(f"Source: DIR_COUNT={src_dir_count}, FILE_COUNT={src_file_count}, CONTENT_SIZE={src_content_size}, TOTAL_SIZE={src_total_size}")#print(f"Destination: DIR_COUNT={dest_dir_count}, FILE_COUNT={dest_file_count}, CONTENT_SIZE={dest_content_size}, TOTAL_SIZE={dest_total_size}")# 設置源路徑和目標路徑
#source_path = "hdfs://namenode1:8020/"
#destination_path = "hdfs://namenode2:8020/path/to/destination"
# 定義源和目標集群的 namenode 地址
source_namenode = "hdfs://10.xx.xx.6:8020"
target_namenode= "hdfs://10.xx.xx.106:4007"def main():# 配置文件路徑和輸出文件路徑conf_file = 'distcp_paths.conf'# 定義源和目標集群的 namenode 地址# 設置源路徑和目標路徑#source_namenode = "hdfs://source-namenode:8020"#target_namenode = "hdfs://target-namenode:8020"# 文件列表file_paths = load_file_paths_from_conf(conf_file)# 對每個目錄進行校驗for filepath in file_paths:validate_hdfs_data(source_namenode, target_namenode, filepath)if __name__ == "__main__":main()# 執行校驗
#validate_hdfs_data(source_path, destination_path)distcp_paths.conf
/apps/hive/warehouse/xx.db/dws_ixx_features
/apps/hive/warehouse/xx.db/dwd_xx_df用法
直接python3 data_checksum.py(需要改為自己的)
他會實時打印對比結果,并且將結果生成到一個文件中(data_checksum_result.txt)

2、hive文件內容比對
最終客戶要的是任務的數據對得上,而不是管你遷移怎么樣,所以驗證任務的方式:兩邊同時跑同多個Hive任務流的任務,查看表數據內容是否一致。(因為跑出來的hdfs的文件大小由于mapreduce原因,肯定是不一致的,校驗實際數據一致就行了)
方法是先對比表字段,然后對比count數,然后將每行拼起來對比md5
涉及3個文件,單檢測腳本,批量入口腳本,需要批量檢測的表文件
check_script.sh
#!/bin/bash
#owner:clark.shi
#date:2025/1/22
#背景:用于hive從源端任務和目標端任務,兩邊跑完結果表的內容校驗(因為mapreduce和小文件不同,所以要用數據內容校驗)
# --用trino(presto)會更好,因為可以跨集群使用,目前客戶因為資源情況沒裝,此為使用hive引擎,將數據放到本地進行比對#輸入:源端表,目標表,分區名,分區值
#$0是腳本本身,最低從1開始#限制腳本運行內存大小,30gb
#ulimit -v 30485760#---注意,要保證,2個表的字段順序是一樣的(md5是根據順序拼接的)
echo "================"
echo "注意"
echo "要保證,2個表的字段順序是一樣的(md5是根據順序拼接的)"
echo "要保證,這2個表是存在的"
echo "要保證,雙端是可以互相訪問"
echo "要保證,2個hive集群的MD5算法相同"
echo "禁止表,一個分區數據量超過本地磁盤,此腳本會寫入本地磁盤(雙端數據),對比后刪除"
echo "注意,如果分區字段是數字不用加引號,如果是字符串需要加引號,搜partition_value,這里分區是int如20250122是沒有引號"
echo "================"a_table=$1
b_table=$2
partition_column=$3
partition_value=$4if [ $# -ne 4 ]; thenecho "錯誤:必須輸入 4 個參數,源端表,目標表,分區名,分區值"exit 1
fi#------------函數check_value() {# 第一個參數是布爾值,第二個參數是要 echo 的內容local value=$1local message=$2# 檢查第一個參數的值if [ "$value" == "false" ]; thenecho "校驗失敗:$message" >> rs.txtexit fi
}#-----------函數結束echo "需要對比表的數據內容是$a_table和$b_table--,需要對比分區$partition_column是$partition_value--"sleep 2
echo "===============開始校驗============="
#todo改成自己的,kerbers互信認證(也可以用ldap)
`kinit -kt /root/s_xx_tbds.keytab s_xx_tbds@TBDS-V12X10CS`#校驗字段類型
echo "1.開始校驗字段類型"#todo這里要改成自己的beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" -e "DESCRIBE $b_table" > 1_a_column.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" -e "DESCRIBE $a_table" > 1_b_column.txtif diff 1_a_column.txt 1_b_column.txt > /dev/null; thenecho "表結構一致"elseecho "表結構不一致"check_value false "$a_table和$b_table字段類型不一致"fi echo "------------1.表字段,校驗完畢,通過-------------"#校驗count數
echo "2.開始count校驗"beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" -e "select count(*) from $b_table where $partition_column=$partition_value" > 2_a_count.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" -e "select count(*) from $a_table where $partition_column=$partition_value" > 2_b_count.txtif diff 2_a_count.txt 2_b_count.txt > /dev/null; thenecho "數據行一致"elseecho "數據行不一致"check_value false "$a_table和$b_table的數據行不一致"fiecho "------------2.數據行,校驗完畢,通過-------------"#拼接每一行的值,作為唯一值,創建2個臨時表
echo "3.生成每條數據唯一標識"#1.獲取表列名#使用awk,去除第一行字段名,,刪除#字號以及他后面的內容(一般是分區的描述),根據分隔符|取第一列數據,去掉空的行beeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" --outputformat=dsv -e "DESCRIBE $a_table" |awk 'NR > 1' |awk '!/^#/ {print} /^#/ {exit}'|awk 'BEGIN {FS="|"} {print $1}'|awk 'NF > 0' > 3_table_field_name.txt#2.拼接表列名,生成md5的表 (第一步已經檢測過雙方的表結構了,這里用同一個拼接字段即可)# 使用 while 循環逐行讀取文件內容name_fields=""while IFS= read -r line; doif [ -z "$name_fields" ]; thenname_fields="$line"elsename_fields="$name_fields,$line"fidone < "3_table_field_name.txt"echo "$name_fields"#將每行數據進行拼接,并且生成含一個字段的md5表md5_sql="SELECT distinct(MD5(CONCAT($name_fields))) AS md5_value "a_md5_sql="$md5_sql from (select * from dim_user_profile_df where $partition_column=$partition_value limit 100)a;"b_md5_sql="$md5_sql from $a_table where $partition_column=$partition_value;"echo "a表的sql是:$a_md5_sql"echo "b表的sql是:$b_md5_sql"#源端是生產環境,這里做了特殊處理,源端就取100條(沒使用order by rand(),客戶主要是檢測函數,order by 會占用他們集群資源)beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" --outputformat=dsv -e "$a_md5_sql" > 4_a_md5_data.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" --outputformat=dsv -e "$b_md5_sql" > 4_b_md5_data.txt#3.(由于不是同集群,需要下載到本地,再進行導入--如果耗費資源時長太長,再導入到hive,否則直接shell腳本搞定)# 設置large_file和small_file的路徑large_file="4_b_md5_data.txt"small_file="4_a_md5_data.txt"# 遍歷small_file中的每一行while IFS= read -r line; do# 檢查line是否存在于large_file中if grep -qxF "$line" "$large_file"; then# 如果line存在于large_file中,輸出1#echo "1"a=1else# 如果line不存在于large_file中,輸出2echo "2"check_value false "$a_table和$b_table抽樣存在數據內容不一致"fidone < "$small_file"echo echo "------------3.數據內容,校驗完畢,通過-------------"
#抽樣核對md5(取數據時已抽樣,否則數據太大容易跑掛生產環境)
input_file.txt需要校驗的表文件
源端表名,目標端表名,分區字段(寫1級分區就可以),分區值
ods_xxnfo_di ods_xxnfo_dii dt 20250106
ods_asxx_log_di ods_asxx_log_dii dt 20250106
ods_xxog_di ods_xxog_di dt 20250106
dwd_xxx dwd_xxx dt 20250106
run.sh
#!/bin/bash# 設置文件路徑
input_file="input_file.txt"# 遍歷文件中的每一行
while IFS= read -r line; do# 調用另一個腳本并傳遞當前行的參數echo $line./check_script.sh $line# 在每次執行完后間隔一小段時間,避免系統過載(可選)sleep 1
done < "$input_file"使用方法
sh run.sh(需要把check_scripe和run里的內容改成自己的哈)
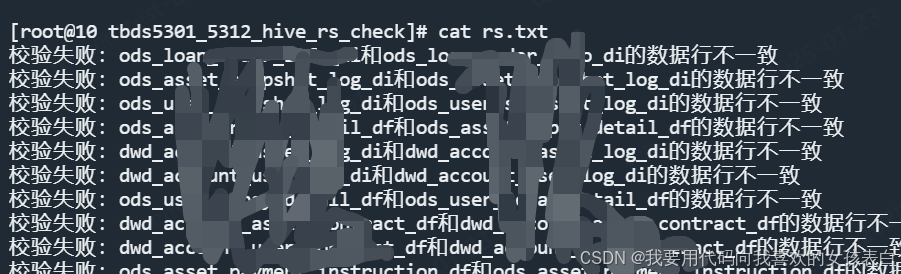
他會把不通過的,生成一個rs.txt













實用系統框架構建初探(上.文章部分))
)


,適合目標檢測、分割等,全網獨發)
![[ Spring ] Spring Cloud Gateway 2025 Comprehensive Overview](http://pic.xiahunao.cn/[ Spring ] Spring Cloud Gateway 2025 Comprehensive Overview)
