前言
AI新時代,提高了生產力且能幫助用戶快速解答問題,現在用的比較多的是Openai、Claude,為了保證個人隱私數據,所以嘗試本地(Mac M3)搭建Llama模型進行溝通。
Gpt4all
安裝比較簡單,根據 GitHub - nomic-ai/gpt4all: GPT4All: Run Local LLMs on Any Device. Open-source and available for commercial use. 下載客戶端軟件即可,打開是這樣的:

然后選擇并下載模型文件,這里以Llama為例:

下載模型文件完,選擇模型文件則可以進行對話了:


也可以利用基于 nomic-embed-text嵌入模型,把文檔轉成向量方便語義檢索和匹配。選擇文檔所在的目錄:

然后對話中選擇對應的文檔即可:

如果文件太大,需要在設置適當添加token大小,太大也不好,處理會慢且機器會卡死:


gpt4all使用起來還是比較方便的,但是有幾個缺點:有些能在huggingface.co搜到的模型在gpt4all上面搜不到、退出應用后聊天記錄會消失。
幫助網安學習,全套資料S信免費領取:
① 網安學習成長路徑思維導圖
② 60+網安經典常用工具包
③ 100+SRC分析報告
④ 150+網安攻防實戰技術電子書
⑤ 最權威CISSP 認證考試指南+題庫
⑥ 超1800頁CTF實戰技巧手冊
⑦ 最新網安大廠面試題合集(含答案)
⑧ APP客戶端安全檢測指南(安卓+IOS)
Ollama
安裝也很方便,下載 https://ollama.com/download/Ollama-darwin.zip ,然后運行如下命令即可啟動Llama:
ollama run llama3.2

為了方便圖形化使用,可以借助 GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 完整圖形化的使用,啟動也很簡單,直接使用官方倉庫中的命令即可:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
然后訪問本地的3000端口即可:

open-webui的原理也比較簡單,Ollama啟動后會在本地監聽11434端口,open-webui也是利用這個端口來和Ollama通信完成的圖形化使用。 open-webui還可以多選模型一起回答:
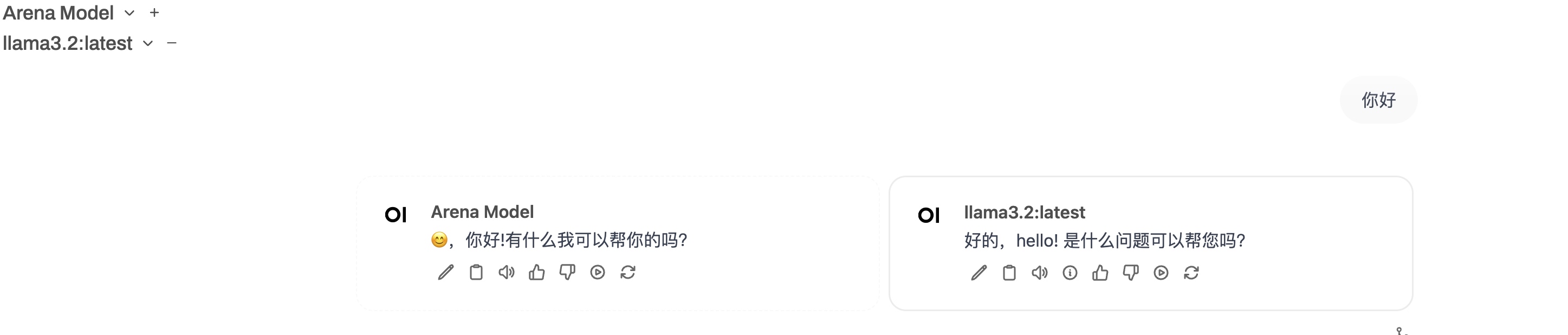
整體測試下來,發現Llama3.2對于文檔分析差點意思,給他提供一個pdf文檔,也看不出個啥來。但是上面的gpt4all,然后通過nomic-embed-text模型嵌入后好點。
總結
本文演示了通過不同手段來運行Llama模型,來達到本地使用LLM的目的。






)








![*【每日一題 基礎題】 [藍橋杯 2023 省 B] 飛機降落](http://pic.xiahunao.cn/*【每日一題 基礎題】 [藍橋杯 2023 省 B] 飛機降落)

緩存)

