概述
情感分類是自然語言處理中的經典任務,是典型的分類問題。本節使用MindSpore實現一個基于RNN網絡的情感分類模型,實現如下的效果:
輸入: This film is terrible
正確標簽: Negative
預測標簽: Negative輸入: This film is great
正確標簽: Positive
預測標簽: Positive數據準備
本節使用情感分類的經典數據集IMDB影評數據集,數據集包含Positive和Negative兩類,下面為其樣例:
| Review | Label |
|---|---|
| "Quitting" may be as much about exiting a pre-ordained identity as about drug withdrawal. As a rural guy coming to Beijing, class and success must have struck this young artist face on as an appeal to separate from his roots and far surpass his peasant parents' acting success. Troubles arise, however, when the new man is too new, when it demands too big a departure from family, history, nature, and personal identity. The ensuing splits, and confusion between the imaginary and the real and the dissonance between the ordinary and the heroic are the stuff of a gut check on the one hand or a complete escape from self on the other. | Negative |
| This movie is amazing because the fact that the real people portray themselves and their real life experience and do such a good job it's like they're almost living the past over again. Jia Hongsheng plays himself an actor who quit everything except music and drugs struggling with depression and searching for the meaning of life while being angry at everyone especially the people who care for him most. | Positive |
此外,需要使用預訓練詞向量對自然語言單詞進行編碼,以獲取文本的語義特征,本節選取Glove詞向量作為Embedding。
數據下載模塊
為了方便數據集和預訓練詞向量的下載,首先設計數據下載模塊,實現可視化下載流程,并保存至指定路徑。數據下載模塊使用requests庫進行http請求,并通過tqdm庫對下載百分比進行可視化。此外針對下載安全性,使用IO的方式下載臨時文件,而后保存至指定的路徑并返回。
tqdm和requests庫需手動安裝,命令如下:pip install tqdm requests
%%capture captured_output
# 實驗環境已經預裝了mindspore==2.2.14,如需更換mindspore版本,可更改下面mindspore的版本號
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14# 查看當前 mindspore 版本
!pip show mindsporeimport os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path# 指定保存路徑為 `home_path/.mindspore_examples`
cache_dir = Path.home() / '.mindspore_examples'def http_get(url: str, temp_file: IO):"""使用requests庫下載數據,并使用tqdm庫進行流程可視化"""req = requests.get(url, stream=True)content_length = req.headers.get('Content-Length')total = int(content_length) if content_length is not None else Noneprogress = tqdm(unit='B', total=total)for chunk in req.iter_content(chunk_size=1024):if chunk:progress.update(len(chunk))temp_file.write(chunk)progress.close()def download(file_name: str, url: str):"""下載數據并存為指定名稱"""if not os.path.exists(cache_dir):os.makedirs(cache_dir)cache_path = os.path.join(cache_dir, file_name)cache_exist = os.path.exists(cache_path)if not cache_exist:with tempfile.NamedTemporaryFile() as temp_file:http_get(url, temp_file)temp_file.flush()temp_file.seek(0)with open(cache_path, 'wb') as cache_file:shutil.copyfileobj(temp_file, cache_file)return cache_path完成數據下載模塊后,下載IMDB數據集進行測試(此處使用華為云的鏡像用于提升下載速度)。下載過程及保存的路徑如下:
imdb_path = download('aclImdb_v1.tar.gz', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')
imdb_path'/home/nginx/.mindspore_examples/aclImdb_v1.tar.gz'加載IMDB數據集
下載好的IMDB數據集為tar.gz文件,我們使用Python的tarfile庫對其進行讀取,并將所有數據和標簽分別進行存放。原始的IMDB數據集解壓目錄如下:
├── aclImdb│ ├── imdbEr.txt│ ├── imdb.vocab│ ├── README│ ├── test│ └── train│ ├── neg│ ├── pos...
數據集已分割為train和test兩部分,且每部分包含neg和pos兩個分類的文件夾,因此需分別train和test進行讀取并處理數據和標簽。
import re
import six
import string
import tarfileclass IMDBData():"""IMDB數據集加載器加載IMDB數據集并處理為一個Python迭代對象。"""label_map = {"pos": 1,"neg": 0}def __init__(self, path, mode="train"):self.mode = modeself.path = pathself.docs, self.labels = [], []self._load("pos")self._load("neg")def _load(self, label):pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))# 將數據加載至內存with tarfile.open(self.path) as tarf:tf = tarf.next()while tf is not None:if bool(pattern.match(tf.name)):# 對文本進行分詞、去除標點和特殊字符、小寫處理self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r")).translate(None, six.b(string.punctuation)).lower()).split())self.labels.append([self.label_map[label]])tf = tarf.next()def __getitem__(self, idx):return self.docs[idx], self.labels[idx]def __len__(self):return len(self.docs)?完成IMDB數據加載器后,加載訓練數據集進行測試,輸出數據集數量:
imdb_train = IMDBData(imdb_path, 'train')
len(imdb_train)25000將IMDB數據集加載至內存并構造為迭代對象后,可以使用mindspore.dataset提供的Generatordataset接口加載數據集迭代對象,并進行下一步的數據處理,下面封裝一個函數將train和test分別使用Generatordataset進行加載,并指定數據集中文本和標簽的column_name分別為text和label:
import mindspore.dataset as dsdef load_imdb(imdb_path):imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)return imdb_train, imdb_test加載IMDB數據集,可以看到imdb_train是一個GeneratorDataset對象。
imdb_train, imdb_test = load_imdb(imdb_path)
imdb_train<mindspore.dataset.engine.datasets_user_defined.GeneratorDataset at 0xfffece2a5be0>加載預訓練詞向量
預訓練詞向量是對輸入單詞的數值化表示,通過nn.Embedding層,采用查表的方式,輸入單詞對應詞表中的index,獲得對應的表達向量。 因此進行模型構造前,需要將Embedding層所需的詞向量和詞表進行構造。這里我們使用Glove(Global Vectors for Word Representation)這種經典的預訓練詞向量, 其數據格式如下:
| Word | Vector |
|---|---|
| the | 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 ... |
| , | 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 ... |
我們直接使用第一列的單詞作為詞表,使用dataset.text.Vocab將其按順序加載;同時讀取每一行的Vector并轉為numpy.array,用于nn.Embedding加載權重使用。具體實現如下:
import zipfile
import numpy as npdef load_glove(glove_path):glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')if not os.path.exists(glove_100d_path):glove_zip = zipfile.ZipFile(glove_path)glove_zip.extractall(cache_dir)embeddings = []tokens = []with open(glove_100d_path, encoding='utf-8') as gf:for glove in gf:word, embedding = glove.split(maxsplit=1)tokens.append(word)embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))# 添加 <unk>, <pad> 兩個特殊占位符對應的embeddingembeddings.append(np.random.rand(100))embeddings.append(np.zeros((100,), np.float32))vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)embeddings = np.array(embeddings).astype(np.float32)return vocab, embeddings由于數據集中可能存在詞表沒有覆蓋的單詞,因此需要加入<unk>標記符;同時由于輸入長度的不一致,在打包為一個batch時需要將短的文本進行填充,因此需要加入<pad>標記符。完成后的詞表長度為原詞表長度+2。
下面下載Glove詞向量,并加載生成詞表和詞向量權重矩陣。
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
len(vocab.vocab())400002使用詞表將the轉換為index id,并查詢詞向量矩陣對應的詞向量:
idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
idx, embedding(0,array([-0.038194, -0.24487 , 0.72812 , -0.39961 , 0.083172, 0.043953,-0.39141 , 0.3344 , -0.57545 , 0.087459, 0.28787 , -0.06731 ,0.30906 , -0.26384 , -0.13231 , -0.20757 , 0.33395 , -0.33848 ,-0.31743 , -0.48336 , 0.1464 , -0.37304 , 0.34577 , 0.052041,0.44946 , -0.46971 , 0.02628 , -0.54155 , -0.15518 , -0.14107 ,-0.039722, 0.28277 , 0.14393 , 0.23464 , -0.31021 , 0.086173,0.20397 , 0.52624 , 0.17164 , -0.082378, -0.71787 , -0.41531 ,0.20335 , -0.12763 , 0.41367 , 0.55187 , 0.57908 , -0.33477 ,-0.36559 , -0.54857 , -0.062892, 0.26584 , 0.30205 , 0.99775 ,-0.80481 , -3.0243 , 0.01254 , -0.36942 , 2.2167 , 0.72201 ,-0.24978 , 0.92136 , 0.034514, 0.46745 , 1.1079 , -0.19358 ,-0.074575, 0.23353 , -0.052062, -0.22044 , 0.057162, -0.15806 ,-0.30798 , -0.41625 , 0.37972 , 0.15006 , -0.53212 , -0.2055 ,-1.2526 , 0.071624, 0.70565 , 0.49744 , -0.42063 , 0.26148 ,-1.538 , -0.30223 , -0.073438, -0.28312 , 0.37104 , -0.25217 ,0.016215, -0.017099, -0.38984 , 0.87424 , -0.72569 , -0.51058 ,-0.52028 , -0.1459 , 0.8278 , 0.27062 ], dtype=float32))數據集預處理
通過加載器加載的IMDB數據集進行了分詞處理,但不滿足構造訓練數據的需要,因此要對其進行額外的預處理。其中包含的預處理如下:
- 通過Vocab將所有的Token處理為index id。
- 將文本序列統一長度,不足的使用
<pad>補齊,超出的進行截斷。
這里我們使用mindspore.dataset中提供的接口進行預處理操作。這里使用到的接口均為MindSpore的高性能數據引擎設計,每個接口對應操作視作數據流水線的一部分,詳情請參考MindSpore數據引擎。 首先針對token到index id的查表操作,使用text.Lookup接口,將前文構造的詞表加載,并指定unknown_token。其次為文本序列統一長度操作,使用PadEnd接口,此接口定義最大長度和補齊值(pad_value),這里我們取最大長度為500,填充值對應詞表中<pad>的index id。
除了對數據集中
text進行預處理外,由于后續模型訓練的需要,要將label數據轉為float32格式。
import mindspore as mslookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)?完成預處理操作后,需將其加入到數據集處理流水線中,使用map接口對指定的column添加操作。
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])由于IMDB數據集本身不包含驗證集,我們手動將其分割為訓練和驗證兩部分,比例取0.7, 0.3。
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])最后指定數據集的batch大小,通過batch接口指定,并設置是否丟棄無法被batch size整除的剩余數據。
調用數據集的
map、split、batch為數據集處理流水線增加對應操作,返回值為新的Dataset類型。現在僅定義流水線操作,在執行時開始執行數據處理流水線,獲取最終處理好的數據并送入模型進行訓練。
imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)模型構建
完成數據集的處理后,我們設計用于情感分類的模型結構。首先需要將輸入文本(即序列化后的index id列表)通過查表轉為向量化表示,此時需要使用nn.Embedding層加載Glove詞向量;然后使用RNN循環神經網絡做特征提取;最后將RNN連接至一個全連接層,即nn.Dense,將特征轉化為與分類數量相同的size,用于后續進行模型優化訓練。整體模型結構如下:
nn.Embedding -> nn.RNN -> nn.Dense
這里我們使用能夠一定程度規避RNN梯度消失問題的變種LSTM(Long short-term memory)做特征提取層。下面對模型進行詳解:
Embedding
Embedding層又可稱為EmbeddingLookup層,其作用是使用index id對權重矩陣對應id的向量進行查找,當輸入為一個由index id組成的序列時,則查找并返回一個相同長度的矩陣,例如:
embedding = nn.Embedding(1000, 100) # 詞表大小(index的取值范圍)為1000,表示向量的size為100
input shape: (1, 16) # 序列長度為16
output shape: (1, 16, 100)
這里我們使用前文處理好的Glove詞向量矩陣,設置nn.Embedding的embedding_table為預訓練詞向量矩陣。對應的vocab_size為詞表大小400002,embedding_size為選用的glove.6B.100d向量大小,即100。
RNN(循環神經網絡)
循環神經網絡(Recurrent Neural Network, RNN)是一類以序列(sequence)數據為輸入,在序列的演進方向進行遞歸(recursion)且所有節點(循環單元)按鏈式連接的神經網絡。下圖為RNN的一般結構:
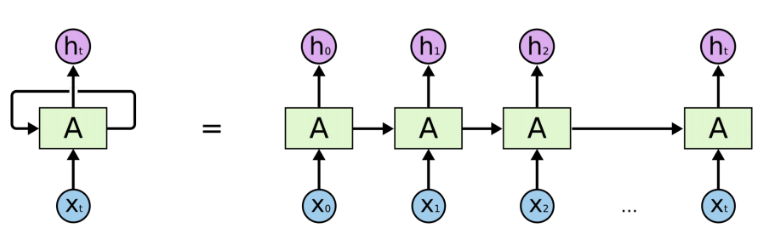
圖示左側為一個RNN Cell循環,右側為RNN的鏈式連接平鋪。實際上不管是單個RNN Cell還是一個RNN網絡,都只有一個Cell的參數,在不斷進行循環計算中更新。
由于RNN的循環特性,和自然語言文本的序列特性(句子是由單詞組成的序列)十分匹配,因此被大量應用于自然語言處理研究中。下圖為RNN的結構拆解:
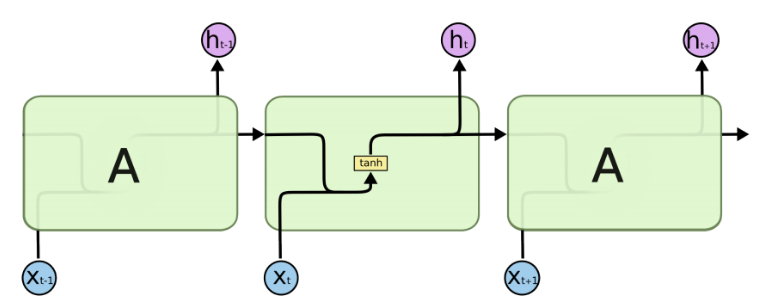
RNN單個Cell的結構簡單,因此也造成了梯度消失(Gradient Vanishing)問題,具體表現為RNN網絡在序列較長時,在序列尾部已經基本丟失了序列首部的信息。為了克服這一問題,LSTM(Long short-term memory)被提出,通過門控機制(Gating Mechanism)來控制信息流在每個循環步中的留存和丟棄。下圖為LSTM的結構拆解:
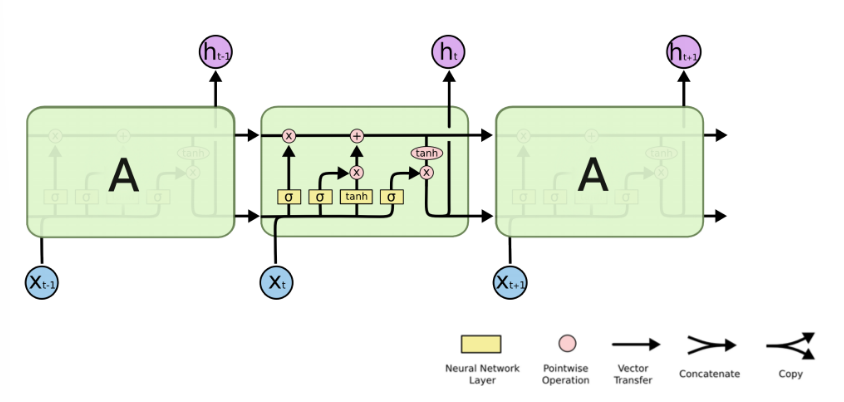
本節我們選擇LSTM變種而不是經典的RNN做特征提取,來規避梯度消失問題,并獲得更好的模型效果。下面來看MindSpore中nn.LSTM對應的公式:
?0:𝑡,(?𝑡,𝑐𝑡)=LSTM(𝑥0:𝑡,(?0,𝑐0))?0:𝑡,(?𝑡,𝑐𝑡)=LSTM(𝑥0:𝑡,(?0,𝑐0))
這里nn.LSTM隱藏了整個循環神經網絡在序列時間步(Time step)上的循環,送入輸入序列、初始狀態,即可獲得每個時間步的隱狀態(hidden state)拼接而成的矩陣,以及最后一個時間步對應的隱狀態。我們使用最后的一個時間步的隱狀態作為輸入句子的編碼特征,送入下一層。
Time step:在循環神經網絡計算的每一次循環,成為一個Time step。在送入文本序列時,一個Time step對應一個單詞。因此在本例中,LSTM的輸出?0:𝑡?0:𝑡對應每個單詞的隱狀態集合,?𝑡?𝑡和𝑐𝑡𝑐𝑡對應最后一個單詞對應的隱狀態。
Dense
在經過LSTM編碼獲取句子特征后,將其送入一個全連接層,即nn.Dense,將特征維度變換為二分類所需的維度1,經過Dense層后的輸出即為模型預測結果。
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniformclass RNN(nn.Cell):def __init__(self, embeddings, hidden_dim, output_dim, n_layers,bidirectional, pad_idx):super().__init__()vocab_size, embedding_dim = embeddings.shapeself.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)self.rnn = nn.LSTM(embedding_dim,hidden_dim,num_layers=n_layers,bidirectional=bidirectional,batch_first=True)weight_init = HeUniform(math.sqrt(5))bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)def construct(self, inputs):embedded = self.embedding(inputs)_, (hidden, _) = self.rnn(embedded)hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)output = self.fc(hidden)return output損失函數與優化器
完成模型主體構建后,首先根據指定的參數實例化網絡;然后選擇損失函數和優化器。針對本節情感分類問題的特性,即預測Positive或Negative的二分類問題,我們選擇nn.BCEWithLogitsLoss(二分類交叉熵損失函數)。
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
loss_fn = nn.BCEWithLogitsLoss(reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr)訓練邏輯
在完成模型構建,進行訓練邏輯的設計。一般訓練邏輯分為一下步驟:
- 讀取一個Batch的數據;
- 送入網絡,進行正向計算和反向傳播,更新權重;
- 返回loss。
下面按照此邏輯,使用tqdm庫,設計訓練一個epoch的函數,用于訓練過程和loss的可視化。
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return lossgrad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)def train_step(data, label):loss, grads = grad_fn(data, label)optimizer(grads)return lossdef train_one_epoch(model, train_dataset, epoch=0):model.set_train()total = train_dataset.get_dataset_size()loss_total = 0step_total = 0with tqdm(total=total) as t:t.set_description('Epoch %i' % epoch)for i in train_dataset.create_tuple_iterator():loss = train_step(*i)loss_total += loss.asnumpy()step_total += 1t.set_postfix(loss=loss_total/step_total)t.update(1)評估指標和邏輯
訓練邏輯完成后,需要對模型進行評估。即使用模型的預測結果和測試集的正確標簽進行對比,求出預測的準確率。由于IMDB的情感分類為二分類問題,對預測值直接進行四舍五入即可獲得分類標簽(0或1),然后判斷是否與正確標簽相等即可。下面為二分類準確率計算函數實現:
def binary_accuracy(preds, y):"""計算每個batch的準確率"""# 對預測值進行四舍五入rounded_preds = np.around(ops.sigmoid(preds).asnumpy())correct = (rounded_preds == y).astype(np.float32)acc = correct.sum() / len(correct)return acc有了準確率計算函數后,類似于訓練邏輯,對評估邏輯進行設計, 分別為以下步驟:
- 讀取一個Batch的數據;
- 送入網絡,進行正向計算,獲得預測結果;
- 計算準確率。
同訓練邏輯一樣,使用tqdm進行loss和過程的可視化。此外返回評估loss至供保存模型時作為模型優劣的判斷依據。
在進行evaluate時,使用的模型是不包含損失函數和優化器的網絡主體; 在進行evaluate前,需要通過
model.set_train(False)將模型置為評估狀態,此時Dropout不生效。
def evaluate(model, test_dataset, criterion, epoch=0):total = test_dataset.get_dataset_size()epoch_loss = 0epoch_acc = 0step_total = 0model.set_train(False)with tqdm(total=total) as t:t.set_description('Epoch %i' % epoch)for i in test_dataset.create_tuple_iterator():predictions = model(i[0])loss = criterion(predictions, i[1])epoch_loss += loss.asnumpy()acc = binary_accuracy(predictions, i[1])epoch_acc += accstep_total += 1t.set_postfix(loss=epoch_loss/step_total, acc=epoch_acc/step_total)t.update(1)return epoch_loss / total模型訓練與保存
前序完成了模型構建和訓練、評估邏輯的設計,下面進行模型訓練。這里我們設置訓練輪數為5輪。同時維護一個用于保存最優模型的變量best_valid_loss,根據每一輪評估的loss值,取loss值最小的輪次,將模型進行保存。為節省用例運行時長,此處num_epochs設置為2,可根據需要自行修改。
num_epochs = 2
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')for epoch in range(num_epochs):train_one_epoch(model, imdb_train, epoch)valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)if valid_loss < best_valid_loss:best_valid_loss = valid_lossms.save_checkpoint(model, ckpt_file_name)可以看到每輪Loss逐步下降,在驗證集上的準確率逐步提升。
模型加載與測試
模型訓練完成后,一般需要對模型進行測試或部署上線,此時需要加載已保存的最優模型(即checkpoint),供后續測試使用。這里我們直接使用MindSpore提供的Checkpoint加載和網絡權重加載接口:1.將保存的模型Checkpoint加載到內存中,2.將Checkpoint加載至模型。
load_param_into_net接口會返回模型中沒有和Checkpoint匹配的權重名,正確匹配時返回空列表。
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)([], [])?對測試集打batch,然后使用evaluate方法進行評估,得到模型在測試集上的效果。
imdb_test = imdb_test.batch(64)
evaluate(model, imdb_test, loss_fn)自定義輸入測試
最后我們設計一個預測函數,實現開頭描述的效果,輸入一句評價,獲得評價的情感分類。具體包含以下步驟:
- 將輸入句子進行分詞;
- 使用詞表獲取對應的index id序列;
- index id序列轉為Tensor;
- 送入模型獲得預測結果;
- 打印輸出預測結果。
具體實現如下:
score_map = {1: "Positive",0: "Negative"
}def predict_sentiment(model, vocab, sentence):model.set_train(False)tokenized = sentence.lower().split()indexed = vocab.tokens_to_ids(tokenized)tensor = ms.Tensor(indexed, ms.int32)tensor = tensor.expand_dims(0)prediction = model(tensor)return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]?最后我們預測開頭的樣例,可以看到模型可以很好地將評價語句的情感進行分類。
predict_sentiment(model, vocab, "This film is terrible")'Negative'predict_sentiment(model, vocab, "This film is great")'Positive'



】 測試)



)

)









