簡介
近年來,人工智能(AI)技術的進步極大地改變了人類與機器的互動方式,特別是在語音處理領域。阿里巴巴通義實驗室最近開源了一個名為FunAudioLLM的語音大模型項目,旨在促進人類與大型語言模型(LLMs)之間的自然語音交互。FunAudioLLM包含兩個核心模型:SenseVoice和CosyVoice,分別負責語音理解和語音生成。
SenseVoice:語音理解模型
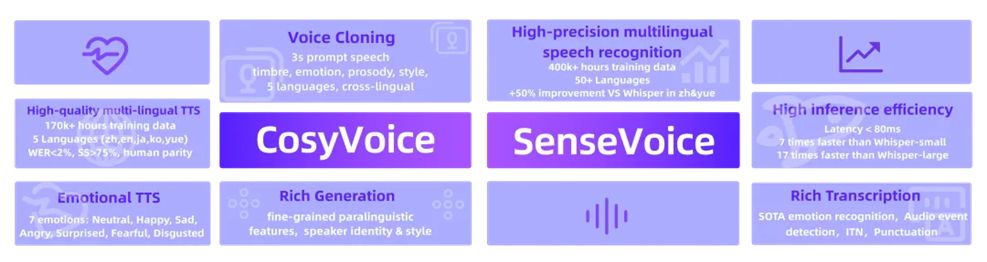
SenseVoice是一個功能強大的語音理解模型,支持多種語音處理任務,包括自動語音識別(ASR)、語言識別(LID)、語音情緒識別(SER)和音頻事件檢測(AED)。其主要特點包括:
- 多語言支持:SenseVoice支持超過50種語言的語音識別。
- 低延遲:SenseVoice-Small模型具有極低的推理延遲,比Whisper-small快5倍以上,比Whisper-large快15倍以上,適用于實時語音交互應用。
- 高精度:SenseVoice-Large模型在高精度語音識別方面表現出色,適用于需要高精度識別的應用。
- 豐富的語音理解功能:包括情緒識別和音頻事件檢測,為復雜的語音交互應用提供支持。
CosyVoice:語音生成模型
CosyVoice是一個功能強大的語音生成模型,可以生成自然流暢的語音,并支持多種語言、音色、說話風格和說話人身份的控制。其主要特點包括:
- 多語言語音生成:支持中文、英文、日語、粵語和韓語等多種語言的語音生成。
- 零樣本學習:可以通過少量參考語音進行語音克隆。
- 跨語言語音克隆:可以將語音克隆到不同的語言中。
- 情感語音生成:可以生成情感豐富的語音,如快樂、悲傷、憤怒等。
- 指令遵循:可以通過指令文本控制語音輸出的各個方面,如說話人身份、說話風格和副語言特征。
訓練數據
- SenseVoice:使用了約40萬小時的多語言語音數據,并通過開源的音頻事件檢測(AED)和語音情緒識別(SER)模型生成偽標簽,構建了一個包含大量豐富語音識別標簽的數據集。
- CosyVoice:使用了多種語言的語音數據集,并通過專門的工具進行語音檢測、信噪比(SNR)估計、說話人分割和分離等操作,以提高數據質量。
實驗結果
FunAudioLLM在多個語音理解和生成任務上取得了優異的性能:
- 多語言語音識別:SenseVoice在大多數測試集上優于Whisper模型,特別是在低資源語言上表現更佳。
- 語音情緒識別:在7個流行的情緒識別數據集上表現出色,無需微調即可獲得高準確率。
- 音頻事件檢測:能夠識別語音中的音頻事件,如音樂、掌聲和笑聲。
- 語音生成質量:CosyVoice在內容一致性和說話人相似度方面表現出色,生成的語音與原始語音高度一致。
應用場景
FunAudioLLM的SenseVoice和CosyVoice模型可以應用于多個場景,包括:
- 語音翻譯:將輸入語音翻譯成目標語言,并生成目標語言的語音。
- 情感語音聊天:識別輸入語音的情緒和音頻事件,并生成與情緒相符的語音。
- 交互式播客:根據實時世界知識和內容生成播客腳本,并使用CosyVoice合成語音。
- 有聲讀物:分析文本中的情感和角色,并使用CosyVoice合成具有豐富情感的有聲讀物。
局限性
盡管FunAudioLLM在多個方面表現出色,但仍存在一些局限性:
- 低資源語言:SenseVoice在低資源語言上的語音識別準確率較低。
- 流式識別:SenseVoice不支持流式語音識別。
- 語言支持:CosyVoice支持的語言數量有限。
- 情感和風格推斷:CosyVoice需要明確的指令才能生成特定情緒和風格的語音。
- 唱歌:CosyVoice在唱歌方面表現不佳。
- 端到端訓練:FunAudioLLM的模型不是與LLMs端到端訓練的,這可能會引入誤差傳播。
總的來說,FunAudioLLM在語音理解和生成方面展現了強大的能力,為語音交互應用提供了新的可能性。通過開源,阿里巴巴希望能夠促進社區的參與和進一步發展。
高性價比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0712_shemei


:程序控制積木篇—短跑比賽)




)


的完整安裝教程)







)
![[激光原理與應用-114]:南京科耐激光-激光焊接-焊中檢測-智能制程監測系統IPM介紹 - 18 - 產品宣傳、介紹、產品價值、幫助客戶解決的問題](http://pic.xiahunao.cn/[激光原理與應用-114]:南京科耐激光-激光焊接-焊中檢測-智能制程監測系統IPM介紹 - 18 - 產品宣傳、介紹、產品價值、幫助客戶解決的問題)