
RAG是什么
“RAG”(Retrieval-Augmented Generation)是一種結合了檢索(Retrieval)和生成(Generation)的人工智能技術,它在大模型中被需要的原因包括:
知識豐富性: 大模型通過RAG可以訪問大量的外部知識庫,這有助于提高模型回答問題的準確性和深度。
實時信息獲取: 由于大模型通常是在大量數據上預訓練的,它們可能不包含最新的信息。RAG可以通過檢索最新的數據來彌補這一點。
減少偏見和錯誤: 通過檢索可靠的信息源,RAG有助于減少模型生成的偏見或錯誤信息。
提高泛化能力: RAG可以使模型在面對未見過的問題或領域時,通過檢索相關信息來提高其泛化能力。
應對長尾問題: 對于那些低頻或非常規的問題,RAG可以通過檢索來提供更加準確的答案,而不需要模型在訓練數據中直接學習到。
RAG是一種強大的技術,它通過結合檢索和生成的優勢,使得大模型能夠提供更加準確、豐富和及時的信息。隨著技術的發展,RAG在大模型中的應用將繼續擴展,以滿足不斷增長的復雜性和多樣性需求。
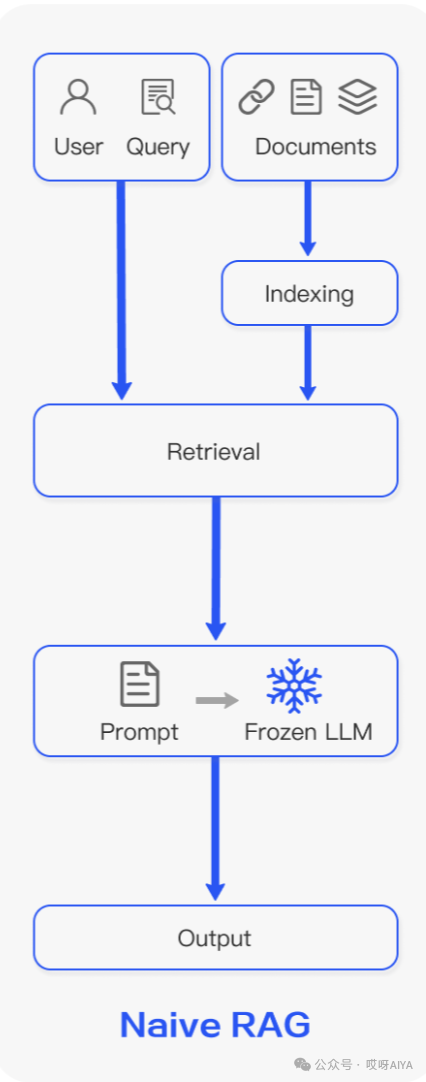
基礎的RAG任務包含以下模塊,包括:數據讀取處理,Index,檢索,prompt拼接,大模型推理。如下圖所示:
環境搭建
在搭建RAG系統中,我們將使用到以下包:
pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
數據讀取
我們使用 WebBaseLoader模塊處理數據,它采用urllib從 Web URL 加載 HTML 并使用BeautifulSoup解析出文本。
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://data.eastmoney.com/report/zw_stock.jshtml?encodeUrl=35LdZWW1ERIe7AWLlyVZFHptPNDUH2qN4gEfzUIhYsc=", "https://data.eastmoney.com/report/zw_stock.jshtml?encodeUrl=OPw8X34UDWQq6g0u70KgHW6e5Ad8C5kc3TYV6t9BZsw=", "https://data.eastmoney.com/report/zw_stock.jshtml?encodeUrl=OPw8X34UDWQq6g0u70KgHbx8/qX6gdD4f6j3/4IEWIA=" ), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("detail-header", "newsContent") # 根據網頁信息不同調整需要保留的字段 ) ),
)
blog_docs = loader.load() # 數據讀取
文本切塊
我們將文檔拆分為 512 個字符的塊,塊之間有 128個字符的重疊。重疊有助于降低當前文本與其相關的上下文分離的概率。我們使用 RecursiveCharacterTextSplitter ,它將使用常用分隔符(如換行符)遞歸拆分文檔,直到每個塊的大小合適。

創建索引(Indexing)
這個模塊首先創建一個向量模塊向量模型可以隨意選擇,后面將介紹怎么選擇向量模型,本篇采用了OpenAIEmbeddings();然后創建一個向量庫,用于儲存文本和文本向量:

創建檢索器
構建一個檢索器,用于通過向量相似度檢索片段,檢索召回是整個系統的關鍵,決定了結果的上限:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6}))# 測試一下檢索的片段
retrieved_docs = retriever.invoke("東方財富營收是多少")
len(retrieved_docs)
創建模型
在這個部分,我們將創建兩個模塊,一是PROMPT模板,這個是根據任務來確定,相同的模型一個好的prompt會得到更好的結果;二是大模型模塊,這個是整個系統的中央大腦,決定著整個系統是否智能,例子中使用的gpt-3.5-turbo

RAG生成流程
前面已經構建好了索引、檢索器、PROMPT模板和大模型,現在我們需要將整個過程組合起來:

至此,我們完成了一個簡單的RAG系統搭建,根據PROMPT的不同,我們可以針對我們的知識庫做不同的任務,可以是問答、也可以是創作;通過知識庫的輔助,我們的結果會更加的精確。
如果對內容有什么疑問和建議可以私信和留言,也可以添加我加入大模型交流群,一起討論大模型在創作、RAG和agent中的應用。
好了,這就是我今天想分享的內容。如果你對大模型應用感興趣,別忘了點贊、關注噢~
如何學習大模型 AI ?
由于新崗位的生產效率,要優于被取代崗位的生產效率,所以實際上整個社會的生產效率是提升的。
但是具體到個人,只能說是:
“最先掌握AI的人,將會比較晚掌握AI的人有競爭優勢”。
這句話,放在計算機、互聯網、移動互聯網的開局時期,都是一樣的道理。
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。

第一階段(10天):初階應用
該階段讓大家對大模型 AI有一個最前沿的認識,對大模型 AI 的理解超過 95% 的人,可以在相關討論時發表高級、不跟風、又接地氣的見解,別人只會和 AI 聊天,而你能調教 AI,并能用代碼將大模型和業務銜接。
- 大模型 AI 能干什么?
- 大模型是怎樣獲得「智能」的?
- 用好 AI 的核心心法
- 大模型應用業務架構
- 大模型應用技術架構
- 代碼示例:向 GPT-3.5 灌入新知識
- 提示工程的意義和核心思想
- Prompt 典型構成
- 指令調優方法論
- 思維鏈和思維樹
- Prompt 攻擊和防范
- …
第二階段(30天):高階應用
該階段我們正式進入大模型 AI 進階實戰學習,學會構造私有知識庫,擴展 AI 的能力。快速開發一個完整的基于 agent 對話機器人。掌握功能最強的大模型開發框架,抓住最新的技術進展,適合 Python 和 JavaScript 程序員。
- 為什么要做 RAG
- 搭建一個簡單的 ChatPDF
- 檢索的基礎概念
- 什么是向量表示(Embeddings)
- 向量數據庫與向量檢索
- 基于向量檢索的 RAG
- 搭建 RAG 系統的擴展知識
- 混合檢索與 RAG-Fusion 簡介
- 向量模型本地部署
- …
第三階段(30天):模型訓練
恭喜你,如果學到這里,你基本可以找到一份大模型 AI相關的工作,自己也能訓練 GPT 了!通過微調,訓練自己的垂直大模型,能獨立訓練開源多模態大模型,掌握更多技術方案。
到此為止,大概2個月的時間。你已經成為了一名“AI小子”。那么你還想往下探索嗎?
- 為什么要做 RAG
- 什么是模型
- 什么是模型訓練
- 求解器 & 損失函數簡介
- 小實驗2:手寫一個簡單的神經網絡并訓練它
- 什么是訓練/預訓練/微調/輕量化微調
- Transformer結構簡介
- 輕量化微調
- 實驗數據集的構建
- …
第四階段(20天):商業閉環
對全球大模型從性能、吞吐量、成本等方面有一定的認知,可以在云端和本地等多種環境下部署大模型,找到適合自己的項目/創業方向,做一名被 AI 武裝的產品經理。
- 硬件選型
- 帶你了解全球大模型
- 使用國產大模型服務
- 搭建 OpenAI 代理
- 熱身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地計算機運行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何優雅地在阿里云私有部署開源大模型
- 部署一套開源 LLM 項目
- 內容安全
- 互聯網信息服務算法備案
- …
學習是一個過程,只要學習就會有挑戰。天道酬勤,你越努力,就會成為越優秀的自己。
如果你能在15天內完成所有的任務,那你堪稱天才。然而,如果你能完成 60-70% 的內容,你就已經開始具備成為一名大模型 AI 的正確特征了。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】







:Mat詳解)





抽獎組件封裝——轉盤抽獎)






