六、數據可視化—Wordcloud詞云(爬蟲及數據可視化)
也是一個應用程序
http://amueller.github.io/word_cloud/
Wordcloud詞云,在一些知乎,論壇等有這樣一些東西,要么做封面,要么做講解,進行分析,看起來有極客風的
分享一些可用于的詞云的圖標如下
https://blog.csdn.net/zhuxiao5/article/details/107096681
https://fontawesome.dashgame.com/
有遮罩的詞云,可以通過文字與輪廓合成一個有圖像的詞云,也可以根據圖片自身的私彩,生成詞云的
還可以使用圖標穿插
使用定制顏色
可以使用中文,形成分布
自己精簡,通過圖片的遮罩,形成自己詞云的效果
需要安裝jieba庫,當使用中文的時候,中文分詞工具
matplotlib庫
Wordcloud 庫可能裝不上,安裝失敗,使用另外的方法進行安裝,離線安裝
使用校園網,發現可以安裝Wordcloud,若安不上,可以使用離線模式
先升級pip 再離線安裝
http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
在下方的連接上,有非常多的關于python的擴展包
http://www.lfd.uci.edu/~gohlke/pythonlibs/
至此Wordcloud安裝完成后
#-*- codeing = utf-8 -*-
#@Time : 2020/11/27 14:17
#@Author : 招財進寶
#@File : testCloud.py
#@Software: PyCharmimport jieba #分詞(將一個句子分成很多個詞語)
from matplotlib import pyplot as plt #繪圖,數據可視化,點狀圖、柱狀圖等科學繪圖,和echarts不同,不是直接用于網站,而是生成圖片
from wordcloud import WordCloud #詞云,形成有遮罩效果的
from PIL import Image #用來做圖像處理的(官方默認)
import numpy as np #矩陣運算
import sqlite3 #數據庫#準備詞云所需的文字(值準備了字)
#先有詞,即從數據庫中得到詞
con = sqlite3.connect('movie.db')
cur = con.cursor()
#看要做那個詞云,字太多,估計也顯示不出來多少
sql = 'select instroduction from movie250' #注意拼寫是否有誤
data = cur.execute(sql)
text = ''
for item in data:text = text +item[0] #此處是將其連接成一個字符串#print(item[0])
#print(text) #此處是一個字符串了
希望讓人自由風華絕代一部美國近現代史怪蜀黍和小蘿莉不得不說的故事失去的才是永恒的 最美的謊言最好的宮崎駿,最好的久石讓 拯救一個人,就是拯救整個世界諾蘭給了我們一場無法盜取的夢永遠都不能忘記你所愛的人每個人都要走一條自己堅定了的路,就算是粉身碎骨 愛是一種力量,讓我們超越時空感知它的存在如果再也不能見到你,祝你早安,午安,晚安英俊版憨豆,高情商版謝耳朵小瓦力,大人生天籟
#關閉
cur.close()
con.close()#詞云是按照詞來進行統計的,這個使用jieba自動進行詞頻統計
cut = jieba.cut(text) #將一個字符串進行分割
#print(cut) #返回cut是一個對象<generator object Tokenizer.cut at 0x000002644AAECF48>
#' '.join(cut) 以指定字符串空格‘ ’作為分隔符,將 cut 中所有的元素(的字符串表示)合并為一個新的字符串
string = ' '.join(cut) #此處將其對象cut變成字符串,可在下方顯示
print(string) #此時可以打印如下
希望 讓 人 自由 風華絕代 一部 美國 近現代史 怪 蜀黍 和 小蘿莉 不得不 說 的 故事 失去 的 才 是 永恒 的 最美 的 謊言 最好 的 宮崎駿 , 最好 的 久 石 讓 拯救 一個 人 , 就是 拯救 整個 世界 諾蘭 給 了 我們 一場 無法 盜取 的 夢 永遠 都 不能 …
#可以自己找圖建議輪廓清晰,后面要是白色背景


img = Image.open(r'.\static\assets\img\tree.jpg') #打開遮罩圖片
img_arry = np.array(img) #將圖片轉換為數組,有了數組即可做詞云的封裝了
wc = WordCloud(background_color='white', #背景必須是白色mask = img_arry, #傳入遮罩的圖片,必須是數組font_path = "STXINGKA.TTF" #設置字體,(字體如何找,可以在C:/windows/Fonts中找到名字)
)
#
wc.generate_from_text(string) #從哪個文本生成wc,這個文本必須是切好的詞
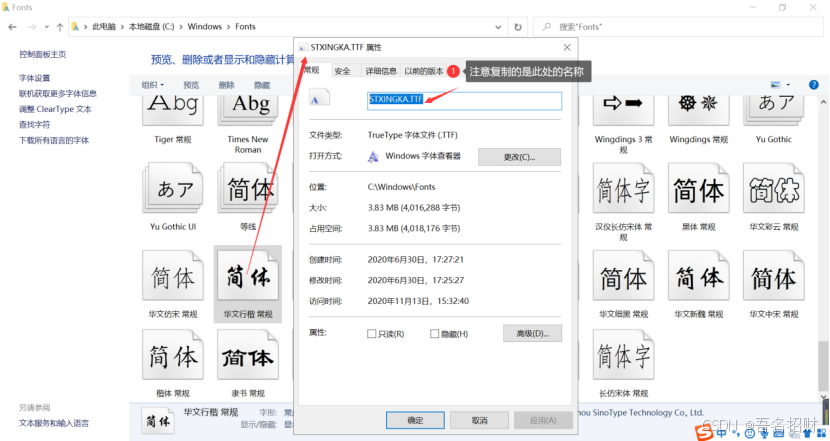
注意要使用中文的字體,否則下方顯示圖片上,會顯示不出中文
#繪制圖片
fig = plt.figure(1) #1表示第一個位置繪制
plt.imshow(wc) #按照wc詞云的規格顯示
plt.axis('off') #是否顯示坐標軸,不顯示(單一圖片)
plt.show() #顯示生成的詞云圖片
顯示結果如下

#plt.show() #顯示生成的詞云圖片(在保存的時候,此處要注釋)
plt.savefig(r'.\static\assets\img\treeWord.jpg',dpi=500) #輸出詞云圖片到文件,默認清晰度是400,這里設置500可能有點高
保存的圖片如下:

所有的源代碼如下
#-*- codeing = utf-8 -*-
#@Time : 2020/11/27 14:17
#@Author : 招財進寶
#@File : testCloud.py
#@Software: PyCharmimport jieba #分詞(將一個句子分成很多個詞語)
from matplotlib import pyplot as plt #繪圖,數據可視化,點狀圖、柱狀圖等科學繪圖,和echarts不同,不是直接用于網站,而是生成圖片
from wordcloud import WordCloud #詞云,形成有遮罩效果的
from PIL import Image #用來做圖像處理的(官方默認)
import numpy as np #矩陣運算
import sqlite3 #數據庫#準備詞云所需的文字(值準備了字)
#先有詞,即從數據庫中得到詞
con = sqlite3.connect('movie.db')
cur = con.cursor()
#看要做那個詞云,字太多,估計也顯示不出來多少
sql = 'select instroduction from movie250' #注意拼寫是否有誤
data = cur.execute(sql)
text = ''
for item in data:text = text +item[0] #此處是將其連接成一個字符串#print(item[0])
#print(text) #此處是一個字符串了
#關閉
cur.close()
con.close()#分詞
#詞云是按照詞來進行統計的,這個使用jieba自動進行詞頻統計
cut = jieba.cut(text) #將一個字符串進行分割
#print(cut) #返回cut是一個對象<generator object Tokenizer.cut at 0x000002644AAECF48>
string = ' '.join(cut) #此處將其對象cut變成字符串,可在下方顯示,#' '.join(cut) 以指定字符串空格‘ ’作為分隔符,將 cut 中所有的元素(的字符串表示)合并為一個新的字符串
#print(string) #此時可以打印如下
print(len(string)) #5589個詞,要對這些詞進行統計#可以自己找圖建議輪廓清晰
img = Image.open(r'.\static\assets\img\tree.jpg') #打開遮罩圖片
img_arry = np.array(img) #將圖片轉換為數組,有了數組即可做詞云的封裝了
wc = WordCloud(background_color='white', #背景必須是白色mask = img_arry, #傳入遮罩的圖片,必須是數組font_path = "STXINGKA.TTF" #設置字體,(字體如何找,可以在C:/windows/Fonts中找到名字)
)
#
wc.generate_from_text(string) #從哪個文本生成wc,這個文本必須是切好的詞#繪制圖片
fig = plt.figure(1) #1表示第一個位置繪制
plt.imshow(wc) #按照wc詞云的規格顯示
plt.axis('off') #是否顯示坐標軸,不顯示(單一圖片)
#plt.show() #顯示生成的詞云圖片
plt.savefig(r'.\static\assets\img\treeWord.jpg',dpi=400) #輸出詞云圖片到文件,默認清晰度是400,這里設置500可能有點高有關WordCloud的配置如下,具體可以看相關課件
WordCloud個參數的含義:
font_path : string #字體路徑,需要展現什么字體就把該字體路徑+后綴名寫上,如:font_path
= '黑體.ttf'
width : int (default=400) #輸出的畫布寬度,默認為400像素
height : int (default=200) #輸出的畫布高度,默認為200像素
prefer_horizontal : flfloat (default=0.90) #詞語水平方向排版出現的頻率,默認 0.9 (所以詞語垂
直方向排版出現頻率為 0.1 )
mask : nd-array or None (default=None) #如果參數為空,則使用二維遮罩繪制詞云。如果
mask 非空,設置的寬高值將被忽略,遮罩形狀被 mask 取代。除全白(#FFFFFF)的部分將不會
繪制,其余部分會用于繪制詞云。如:bg_pic = imread('讀取一張圖片.png'),背景圖片的畫布一
定要設置為白色(#FFFFFF),然后顯示的形狀為不是白色的其他顏色。可以用ps工具將自己要
顯示的形狀復制到一個純白色的畫布上再保存,就ok了。
scale : flfloat (default=1) #按照比例進行放大畫布,如設置為1.5,則長和寬都是原來畫布的1.5倍
min_font_size : int (default=4) #顯示的最小的字體大小
font_step : int (default=1) #字體步長,如果步長大于1,會加快運算但是可能導致結果出現較大
的誤差
max_words : number (default=200) #要顯示的詞的最大個數
stopwords : set of strings or None #設置需要屏蔽的詞,如果為空,則使用內置的STOPWORDS
background_color : color value (default=”black”) #背景顏色,如background_color='white',背
景顏色為白色
max_font_size : int or None (default=None) #顯示的最大的字體大小
mode : string (default=”RGB”) #當參數為“RGBA”并且background_color不為空時,背景為透明
relative_scaling : flfloat (default=.5) #詞頻和字體大小的關聯性
color_func : callable, default=None #生成新顏色的函數,如果為空,則使用 self.color_func
regexp : string or None (optional) #使用正則表達式分隔輸入的文本
collocations : bool, default=True #是否包括兩個詞的搭配
colormap : string or matplotlib colormap, default=”viridis” #給每個單詞隨機分配顏色,若指定
color_func,則忽略該方法
random_state : int or None #為每個單詞返回一個PIL顏色
fig = plt.figure(1) #新建一個名叫 Figure1的畫圖窗口
plt.imshow(wc) #顯示圖片,同時也顯示其格式
plt.axis('off') # 是否顯示x軸、y軸下標
#plt.show() #顯示生成合成圖片
plt.savefig(path+'\\new.png',dpi=500) #保存合成圖片,dpi是設定分辨率,默認為400
fifit_words(frequencies) #根據詞頻生成詞云
generate(text) #根據文本生成詞云
generate_from_frequencies(frequencies[, ...]) #根據詞頻生成詞云
generate_from_text(text) #根據文本生成詞云
process_text(text) #將長文本分詞并去除屏蔽詞(此處指英語,中文分詞還是需要自己用別的庫
先行實現,使用上面的 fifit_words(frequencies) )
recolor([random_state, color_func, colormap]) #對現有輸出重新著色。重新上色會比重新生成
整個詞云快很多
to_array() #轉化為 numpy array
to_fifile(fifilename) #輸出到文件







的區別探究)




(11.10制訂進度計劃))






