世界由形形色色的角色構成,每個角色都擁有獨特的知識、經驗、興趣、個性和職業,他們共同制造了豐富多元的知識與文化。
所謂術業有專攻,比如AI科學家專注于構建LLMs,醫務工作者們共建龐大的醫學知識庫,數學家們則偏愛數學公式與定理推導。
LLMs中也是如此,不同的知識是由不同的人類角色創建或者使用。因此在提示中加入角色描述如“你是一個xxx的計算機科學家”會極大提高模型響應準確度。
這一思路也可以用于構建合成數據。騰訊AI lab提出了一種新穎的(基于角色驅動的數據合成方法。即只需在數據合成提示中添加角色描述,就能引導LLM朝著相應的視角生成獨特的合成數據。

由于幾乎任何LLM的應用場景都可以關聯到特定的人格,只要構建一個全面的角色集合,就能實現大規模的全方位合成數據生成。為此作者構建了10億個角色,創建了Persona Hub(角色倉庫),里面包含“搬家公司的司機”、“化學動力學研究員”、“對音頻處理感興趣的音樂家”等多樣化的角色。并在大規模數學和邏輯推理問題生成、指令生成、知識豐富的文本生成、游戲NPC以及工具(功能)開發等場景中創建豐富且多樣化的合成數據:

通過對合成數據的微調,7B的模型在某些任務上甚至與gpt-4-turbo-preview的性能相當!
論文標題:
Scaling Synthetic Data Creation with 1,000,000,000 Personas
論文鏈接:
https://arxiv.org/pdf/2406.20094
github鏈接:
https://github.com/tencent-ailab/persona-hub
構建Persona Hub
作者提出兩種可擴展的方法來從海量網絡數據中生成多樣化的Persona Hub:Text-to-Persona(文本到角色)和Persona-to-Persona(角色到角色)。
文本到角色
具有特定專業經驗和文化背景的人在閱讀和寫作時往往展現出獨特的興趣。
通過分析特定文本,能夠推斷出可能對某段文本感興趣或創作該文本的特定人物。鑒于網絡上的文本數據極為豐富且多樣,因此只需簡單地提示LLM,即可從海量的網絡文本中提煉出廣泛的人物集合。如下圖所示:
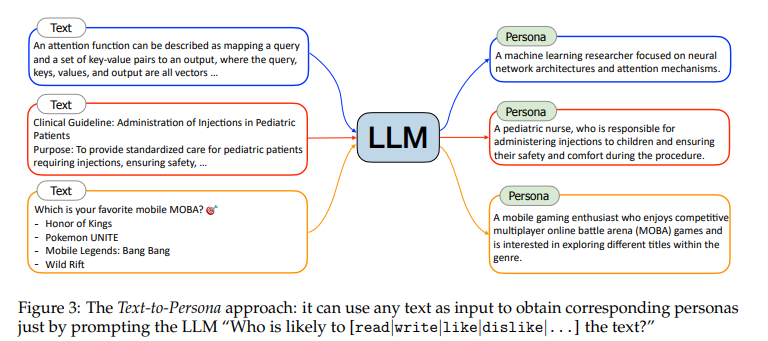
對于"attention函數描述為將查詢和一組鍵-值對映射到輸出,其中查詢、鍵、值和輸出都是向量…"這樣一段文本,“一位計算機科學家”對其感興趣的可能性較大,而更細粒度人物則可以是“專注于神經網絡架構和注意力機制的機器學習研究者”。
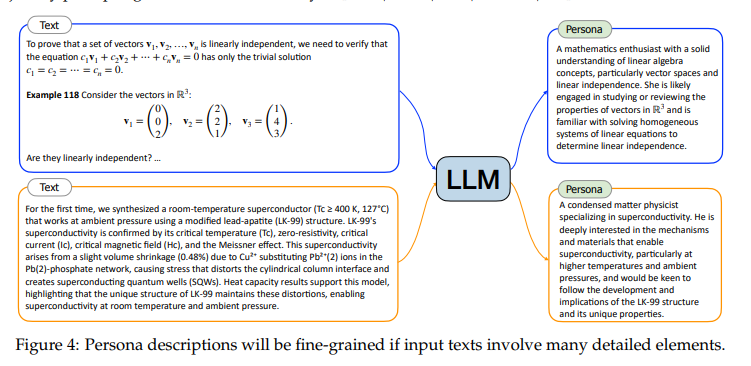
除了通過提示指定人物描述的粒度外,輸入文本的內容也會直接影響人物描述的詳盡程度。如下圖所示,當輸入文本包含豐富的細節元素,如數學教科書的內容或關于超導的深入學術論文時,生成的人物描述往往會更加具體和細致。
角色到角色
Text-to-Persona是一種高度可擴展的方法,能夠生成幾乎涵蓋各個領域的角色。但是,對于網絡上曝光較少或不易被文本分析捕獲的角色,如兒童、乞丐以及電影幕后工作人員,它可能存在局限性。為了彌補這一不足,作者提出從Text-to-Persona生成的角色中衍生出更多元化的新角色。
通過提示““誰與給定的角色關系密切?””,如下圖所示,“兒科護士”可能與“患病兒童”、“醫藥公司代表”等有聯系。
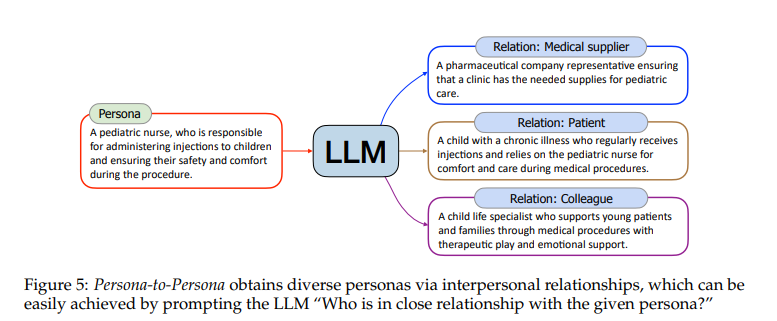
根據六度分隔理論:“你和世界上任何一個陌生人之間,最多只需要通過六個人就能建立聯系”。作者對通過Text-to-Persona獲取的每個角色進行六輪關系擴展,從而進一步豐富了角色庫。
通過以上方式獲得在獲得數十億個角色后,通過MinHash(根據角色描述的n-gram特征進行去重)與使用文本嵌入模型計算相似性兩種方式去重,過濾低質量的角色描述,最后得1,015,863,523個角色。
角色驅動的數據合成
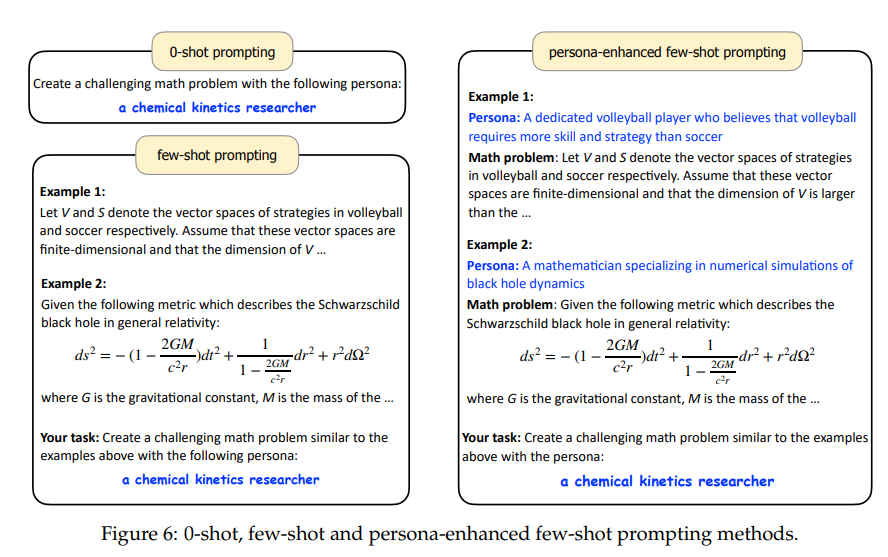
角色倉庫構建完畢夠,作者將人物角色融入到數據合成提示的適當位置,輕松地生成規模達億級的多樣化合成數據。為此,提出了三種角色驅動的數據合成提示方法:0-shot, few-shot and 角色增強的 few-shot提示,如下圖所示:
合成數據創建示例
數學問題
數據創建
當提示LLM創建數學問題時,加入角色會讓模型生成與該角色相關的問題。如下圖所示:當提供語言學家的人格時,模型會生成與計算語言學相關的數學問題。

此外,添加角色并不影響提示的靈活性,仍然可以輕松地在提示中指定我們所需數學問題的焦點或難度。
數學能力評估
整個評估過程首先從Persona Hub中選取了31,090,000個角色,并借助GPT-4的0-shot提示方法,根據這些角色生成了1,090,000道全新的數學問題,全程未參考MATH等基準數據集中的實例,僅使用GPT-4為這些問題生成了答案。
測試集分為域內和域外,其中域內為從合成數據中隨機抽取20,000道,域外測試集選用經典的評測集MATH。
使用剩下的1,070,000道數學問題微調Qwen2-7B,并在上述兩個測試集上評估其貪心解碼輸出。
下表展示了域內評估結果。可以看到,借助107萬個合成數學問題,微調模型Qwen2-7B實現了近80%的準確率,超越了所有開源大語言模型。

另外再MATH基準上進行評測發現,合成數據微調的7B模型也取得了64.9的好成績!并超過了超越gpt-4-turbo-preview(1106/0125)的性能! 而且文本在數據合成或訓練過程中并未使用MATH數據集的任何實例,顯示出該方法的優越性.
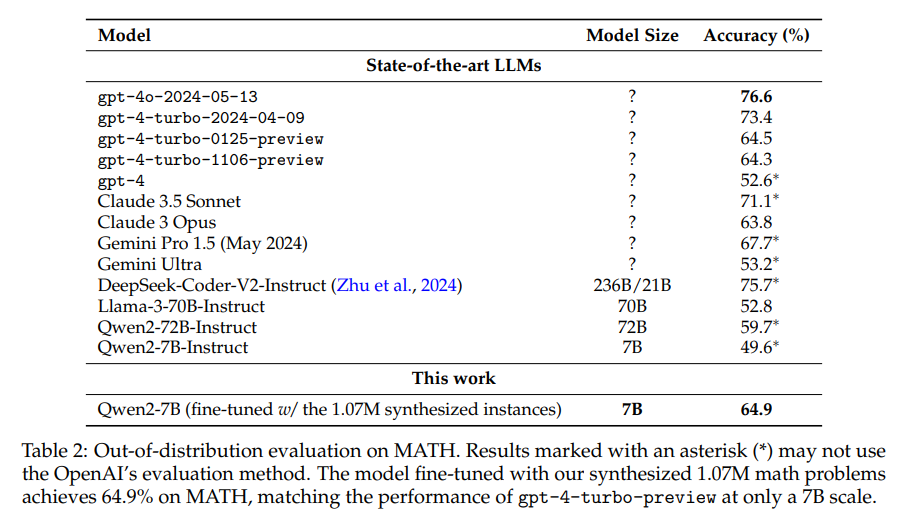
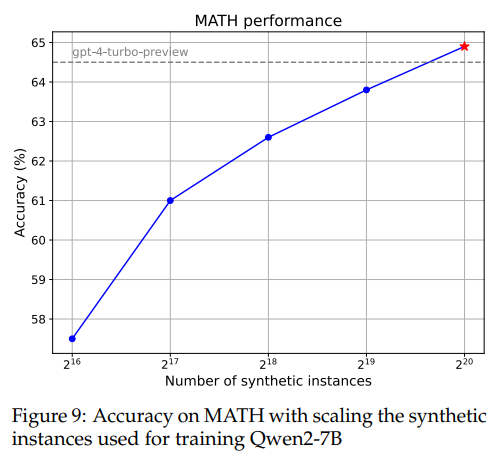
下圖還展示了模型在訓練不同規模合成數學問題后在MATH數據集上的性能。其性能趨勢大體上與規模法則相符。
邏輯推理問題
同樣基于角色驅動方法合成的典型邏輯推理問題,如下圖所示:

此外,作者還展示了幾個以“弱智吧”風格創建的邏輯推理問題。

所有示例都表明,只要能夠清晰描述要創建的邏輯推理問題的要求,就可以使用多種角色來引導LLM生成不僅滿足要求,而且與角色高度相關的多樣化邏輯推理問題,連“弱智吧”風格的問題也能輕松應對。
指令生成任務
還可以利用Persona Hub模擬各種用戶,理解他們對LLM的請求,從而生成多樣化的指令。如下圖所示。這對于提升LLM的指令遵循和對話能力非常有價值。此外甚至可以采用類似的方法,從Persona Hub中選擇兩個角色,讓LLM扮演兩個角色,模擬兩個真實人之間的對話。

知識豐富文本生成
除了能夠生成增強LLMs指令調優的合成指令外,也可以輕松地創建有益于預訓練和后訓練的豐富知識的純文本。如下圖,提示LLM使用從Persona Hub中采樣的角色,撰寫Quora文章。

創建游戲NPC
Persona Hub還能大量創建游戲中的NPC。將游戲的背景和世界觀信息提供給LLM,LLM就能將Persona Hub中的人物(通常是現實世界中的人物)投影到游戲世界中的角色上。
比如為游戲《魔獸世界》創建游戲NPC:

《天涯明月刀》的NPC:

工具開發
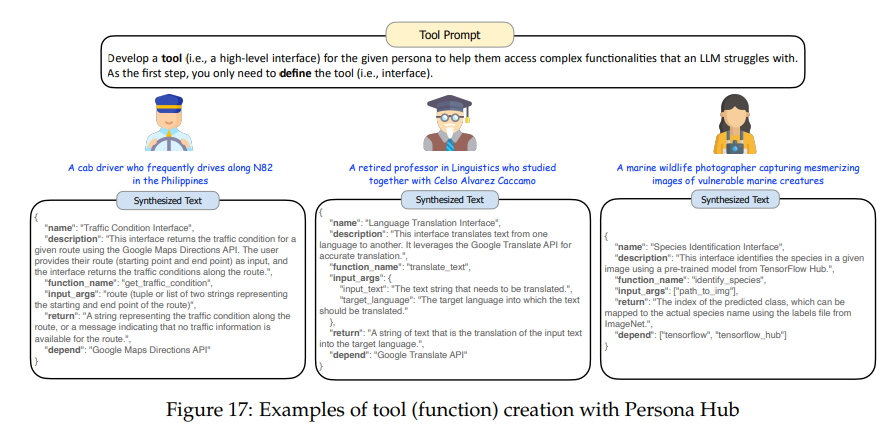
使用Persona Hub來預測用戶可能需要的工具,以提前構建這些工具(功能)。當真實用戶提出類似請求時,LLM可以直接調用這些預構建的工具來返回結果,而無需每次都從頭開始構建工具。
如下圖所示,為不同角色需要的工具定義接口,然后輕松轉換為代碼,(例如,出租車司機需要查看交通狀況),從而極大地擴展了LLM提供的服務范圍。

Persona Hub的影響與挑戰
Persona Hub帶來的優勢
范式轉變:
傳統上,LLM主要用于處理數據,而數據創建主要由人類完成。引入Persona Hub后,LLM不僅可以處理數據,還可以從多種角度創建新數據。雖然LLM目前尚不能完全替代人類的數據創建任務,但其能力不斷進步,未來可能完全承擔數據創建任務。
現實模擬:
Persona Hub可以通過10億個角色模擬大量現實世界個體的需求和行為。這可以幫助公司預測用戶反應、政府預見公眾反應,并緩解在線服務中的冷啟動問題。角色中心還可以用于虛擬社會的測試,為新政策和社會動態提供無風險的實驗場。
全面記憶訪問:
-
Persona Hub有助于全面訪問LLM的知識,通過多樣化的查詢生成合成數據。
-
雖然目前Persona Hub和LLM的能力有限,但隨著改進,未來可能實現幾乎無損地提取LLM的全面記憶。
倫理問題
訓練數據的安全性:
-
Persona Hub可能會帶來訓練數據安全性問題,因為通過LLM合成的數據本質上是其訓練數據的一種形式。
-
大規模提取LLM的記憶可能會導致其他LLM的知識、智能和能力被復制,威脅最強大LLM的主導地位。
誤導信息和假新聞:
-
合成數據可能會加劇誤導信息和假新聞的問題,多樣化角色的寫作風格增加了檢測難度。
-
數據污染問題可能會扭曲研究結果和公眾信息。
結論
本文提出了一種新穎的角色驅動數據合成方法,并推出了Persona Hub,一個包含10億個角色的集合,展示了其在多種場景下促進合成數據創建的潛力,可能為發掘LLM的超級智能提供一種新途徑。





)
)


)






)




