模擬退火算法優點
1、以一定的概率接受惡化解
模擬退火算法(SA)在搜索策略上與傳統的隨機搜索方法不同,它不僅引入了適當的隨機因素,而且還引入了物理系統退火過程的自然機理。這種自然機理的引入使模擬退火算法在迭代過程中不僅接受使目標函數變“好”的試探點,而且還能以一定的概率接受使目標函數值變“差”的試探點,迭代中出現的狀態是隨機產生的,并不強求后一狀態一定優于前一狀態,接受概率隨著溫度的下降而逐漸增大。
2、引進算法控制參數T
將優化過程分成各個階段,并決定各個階段下隨機狀態的取舍標準,接受函數由Metropolis算法給出一個簡單的數學模型。
模擬退火算法的兩個重要步驟是:一是在每個控制參數T下,由前迭代點出發,產生鄰近的隨機狀態,由T確定的接受準則決定此新狀態的取舍;二是緩慢降低控制參數T,提高接收準則,直至T->0,狀態鏈穩定于優化問題的最優狀態,提高模擬退火算法全局最優解的可靠性。
3、使用對象函數值進行搜索
傳統搜索算法不僅需要利用目標函數值,而且往往需要目標函數的導數值等其它一些輔助信息,能確定搜索方向,當這些信息不存在時,算法就失效了。而模擬退火算法僅使用由目標函數變換來的適應度函數值,就可確定進一步的搜索方向和搜索范圍,無需其它的輔助信息。
4、搜索復雜區域
模擬退火算法最善于搜索復雜地區,從中找出期望值高的區域,在求解簡單問題上效率并不高。
模擬退火算法缺點
1、求解時間太長。
在變量多、目標函數復雜時,為了得到一個好的近似解, 控制參數T需要從一個較大的值開始, 并在每一個溫度值T下執行多次Metropolis 算法, 因此迭代運算速度慢。
2、算法性能與初始值有關及參數敏感。
溫度T的初值和減小步長較難確定。如果T的初值選擇較大, 減小步長太小, 雖然最終能得到較好的解, 但算法收斂速度太慢;如果T 的初值選擇較小,減小步長過大, 很可能得不到全局最優解。
3、搜索過程中由于執行概率接受環節而遺失當前遇到的最優解。
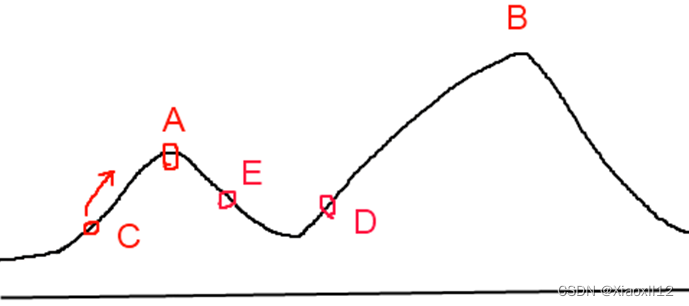
爬山算法與模擬退火算法比較
- 爬山算法:假設C點為當前解,爬山算法搜索到A點這個局部最優解就會停止搜索,因為在A點無論向那個方向小幅度移動都不能得到更優的解。
- 模擬退火其實也是一種貪心算法,但是它的搜索過程引入了隨機因素,以一定的概率來接受一個比當前解要差的解,因此有可能會跳出這個局部的最優解,達到全局的最優解。模擬退火算法在搜索到局部最優解A后,會以一定的概率接受到E的移動。也許經過幾次這樣的不是局部最優的移動后會到達D點,于是就跳出了局部最大值A。


)



)


:從云端許可管理到硬件加密狗的創新)


)



)

)
