一、研究背景
舊金山是一個人口稠密、旅游業發達的城市,同時也是美國犯罪率較高的城市之一。隨著城市的不斷發展,犯罪行為的類型和頻率也在不斷變化,這對城市的治安管理和社會穩定構成了巨大的挑戰。近年來,數據科學技術的迅猛發展為犯罪行為的預測和預防提供了新的思路和工具。通過對大量歷史犯罪數據的分析,可以發現潛在的犯罪模式和趨勢,從而為警察部門和相關決策機構提供有價值的參考。舊金山犯罪分類研究的目標是利用機器學習和數據挖掘技術,對犯罪數據進行系統的分析和分類,以期能夠更準確地預測未來的犯罪行為,并制定更有效的防范措施。
二、研究意義
-
社會治安管理:通過對舊金山犯罪數據的深入分析,可以幫助警察部門更好地理解犯罪行為的分布和特點,從而優化警力配置,提高犯罪預防和打擊的效率。
-
公共安全保障:準確的犯罪預測可以為居民和游客提供更安全的生活和旅游環境,增強公眾的安全感和幸福感。
-
數據科學應用:該研究是數據科學在社會治理領域的一次重要嘗試,能夠展示機器學習和數據挖掘技術在實際應用中的巨大潛力,并為其他城市的犯罪預防提供借鑒和參考。
-
政策制定支持:通過對犯罪數據的分析,可以為政府和相關決策機構提供數據支持,幫助其制定更加科學和合理的治安管理政策。
三、實證分析
首先導入包 讀取數據集
代碼和數據
#imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time as systime
import datetime as dt
import string
import seaborn as sns
import matplotlib.colors as colors
%matplotlib inlinetrain=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')?查看數據集類型
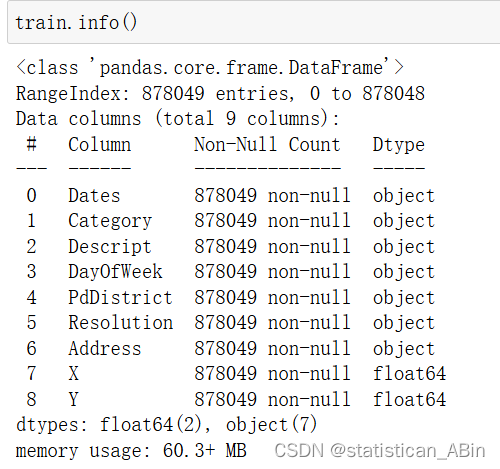
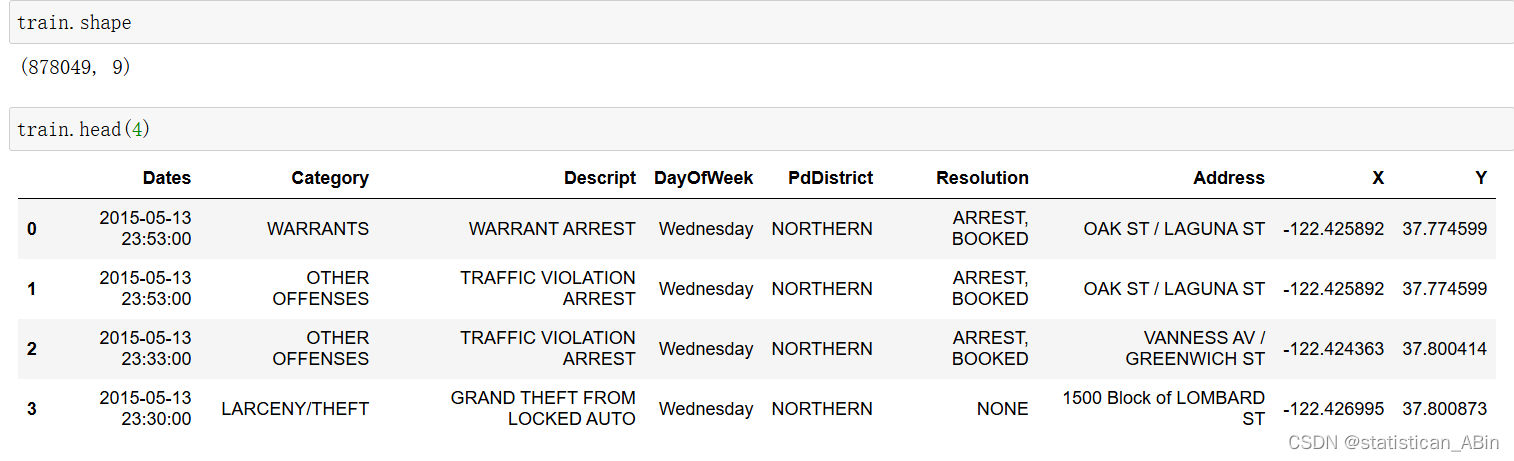
查看數據集的形狀和具體的前4行
查看其缺失情況
train.isnull().sum()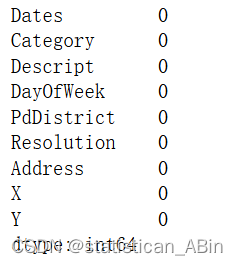
發現不存在缺失值
通過groupby().size()方法返回分組后的統計結果
cate_group = train.groupby(by='Category').size()
cate_group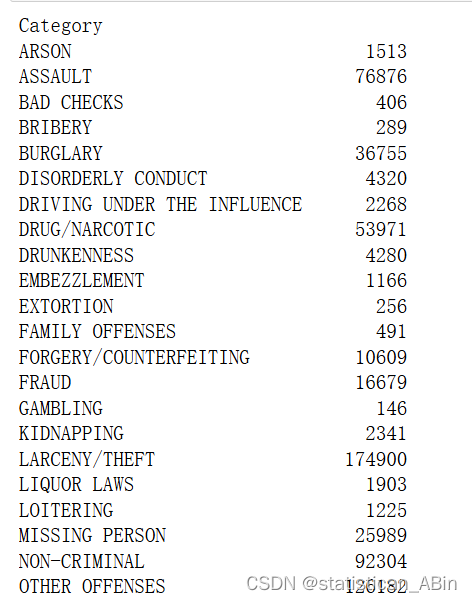
分析一下目標分類共有多少種類型
cat_num = len(cate_group.index)
cat_num![]() ?
?
還挺多
接下來可視化特征
cate_group.index = cate_group.index.map(string.capwords)
cate_group.sort_values(ascending=False,inplace=True)
cate_group.plot(kind='bar',logy=True,figsize=(15,10),color=sns.color_palette('coolwarm',cat_num))
plt.title('No. of Crime types',fontsize=20)
plt.show()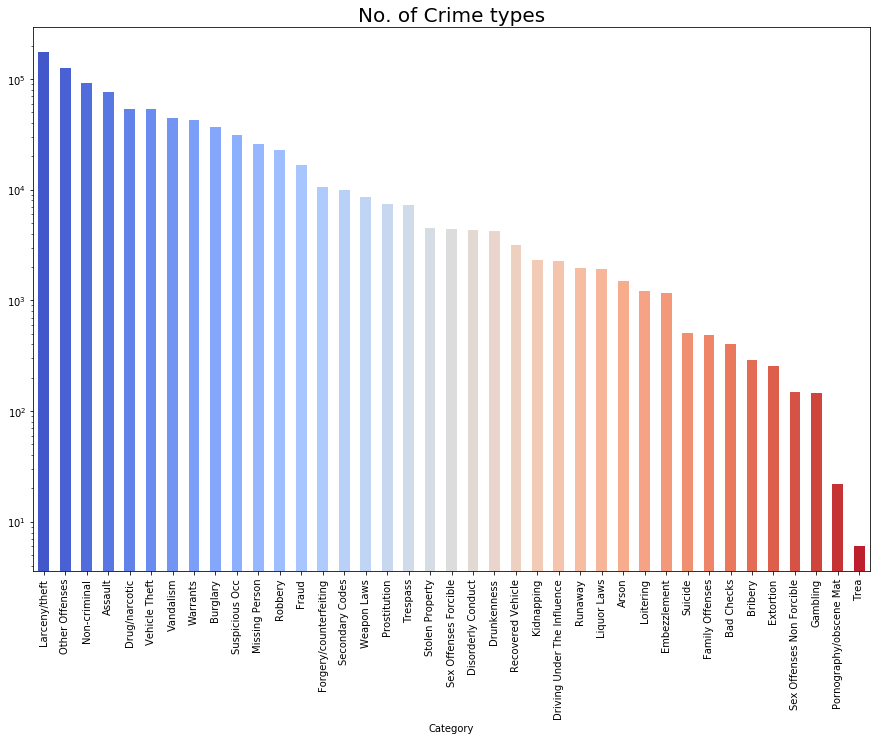 ?
?
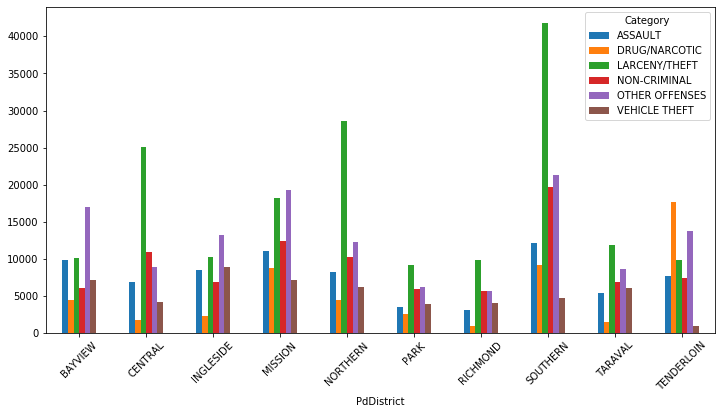
接下來查看各區犯罪率
dis_group.index = dis_group.index.map(string.capwords)
dis_group.sort_values(ascending=True,inplace=True)
dis_group.plot(kind='barh',figsize=(15,10),fontsize=10,color=sns.color_palette('coolwarm',10))
plt.title('Frequncy. of crimes by district',fontsize=20)
plt.show()?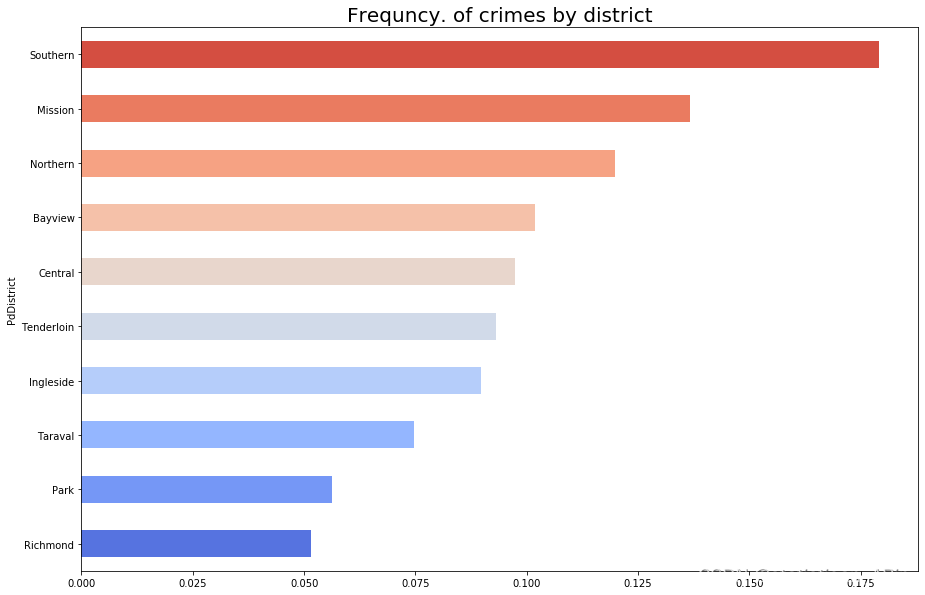
接下來將犯罪情況用時間來分別展示
?
plt.figure(figsize=(8,19))year_group = train.groupby('year').size()
plt.subplot(311)
plt.plot(year_group.index[:-1],year_group[:-1],'ks-')
plt.xlabel('year')month_group = train.groupby('month').size()
plt.subplot(312)
plt.plot(month_group,'ks-')
plt.xlabel('month')day_group = train.groupby('day').size()
plt.subplot(313)
plt.plot(day_group,'ks-')
plt.xlabel('day')plt.show()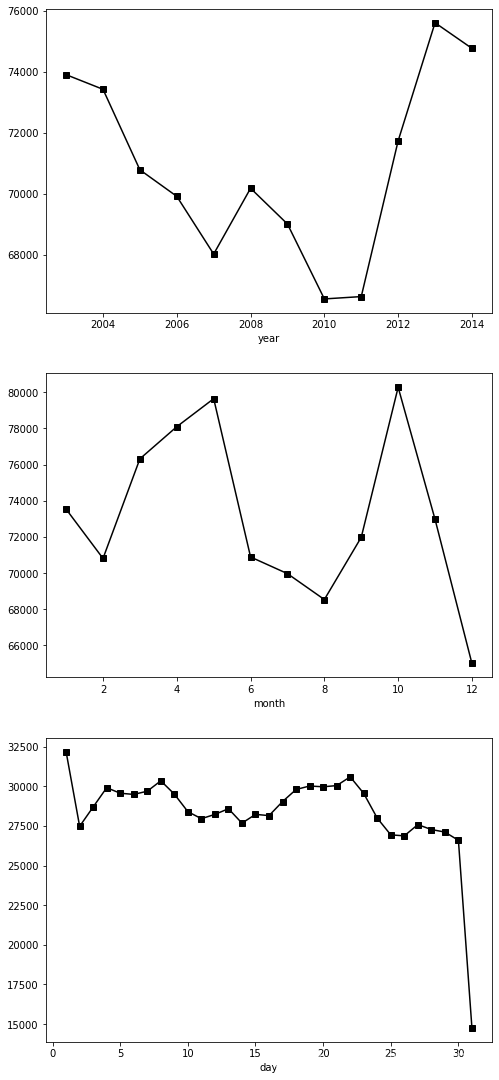 ?
?
接下來展示每周的犯罪情況
week_group.T.plot(figsize=(12,8))#行列互換后畫圖
plt.xlabel('hour of day',size=15)
plt.ylabel('Number of crimes',size=15)
plt.show()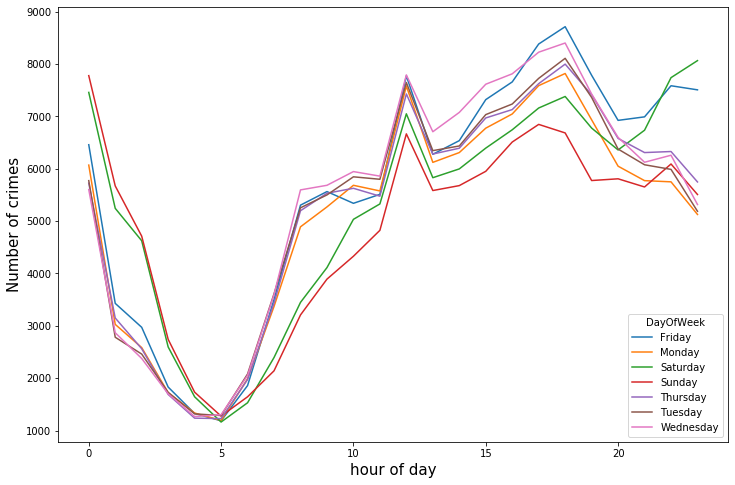
接下來查看犯罪種類
tmp = train[train['Category'].map(string.capwords).isin(top6)]
tmp_group = tmp.groupby(['Category','hour']).size()
tmp_group = tmp_group.unstack()
tmp_group.T.plot(figsize=(12,6),style='o-')
plt.show()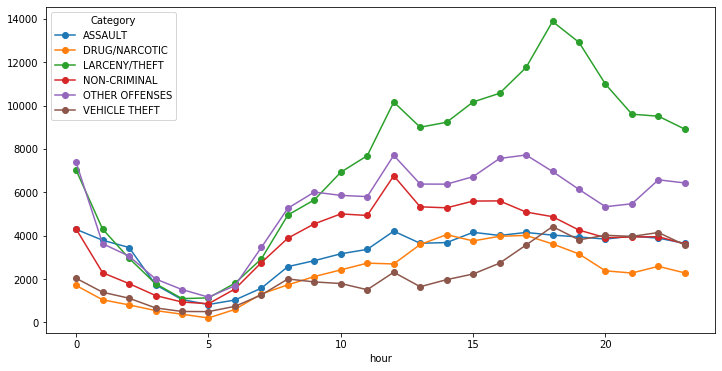 ?
?
接下來對測試集的Dates做同樣的處理
test['date'] = pd.to_datetime(test['Dates'])
test['year'] = test.date.dt.year
test['month'] = test.date.dt.month
test['day'] = test.date.dt.day
test['hour'] = test.date.dt.hour
test.info()?準備開始機器學習
#加入所有特征
training,valid,y_train,y_valid = train_test_split(full[:train.shape[0]],target,train_size=0.7,random_state=0)分別使用三種機器學習模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import log_loss
from sklearn.naive_bayes import BernoulliNB
import timeLR = LogisticRegression(C=0.1)
lrstart = time.time()
LR.fit(training, y_train)
lrcost_time = time.time()-lrstart
predicted = np.array(LR.predict_proba(valid))
print("邏輯回歸log損失為 %f" %(log_loss(y_valid, predicted)))
print('邏輯回歸建模耗時 %f 秒' %(lrcost_time)) ?
?
params = [12, 13, 14, 15, 16]
clf = RandomForestClassifier(n_estimators=30)start_time = time.time()for par in params:clf.set_params(max_depth=par)clf.fit(training, y_train)predicted = clf.predict_proba(valid)loss = log_loss(y_valid, predicted)print("隨機森林 log 損失為 %.4f" % loss)?
NB = BernoulliNB()
nbstart = time.time()
NB.fit(training,y_train)
nbcost_time = time.time()-nbstart
predicted = np.array(NB.predict_proba(valid))?
四、結論
本研究通過對舊金山的犯罪數據進行分析和分類,展示了數據科學技術在犯罪預防和社會治理中的應用潛力。研究結果表明,犯罪行為具有一定的時空分布規律,可以通過歷史數據進行有效預測。這不僅為警察部門的日常工作提供了有力支持,也為公眾安全提供了保障。此外,該研究還進一步證明了數據科學在解決實際問題中的重要作用和廣泛前景。未來,隨著技術的不斷進步和數據的進一步積累,犯罪預測的精度和實用性將會不斷提高,從而為建設更加安全和諧的社會貢獻力量


:從云端許可管理到硬件加密狗的創新)


)



)

)







