Google DeepMind團隊最近推出了Gemma,這是一個基于其先前Gemini模型研究和技術的開放模型家族。這些模型專為語言理解、推理和安全性而設計,具有輕量級和高性能的特點。

在Gemma模型推出之前,現有語言模型存在一些挑戰和局限性,主要體現在這些模型在理解語言、進行推理以及確保輸出內容的安全性方面,并沒有達到很高的水平。它們在處理一些需要深層次理解或創造性思維的任務時,可能無法給出非常準確或有用的答案。而且很多現有的大型模型對計算資源的要求很高,這導致它們在個人電腦或移動設備等資源受限的環境中難以運行。這限制了這些模型的普及和應用范圍,因為不是每個人都能訪問到高端的計算硬件。隨著語言模型被用于生成各種文本內容,如何確保這些內容的安全性和符合道德標準成為了一個重要問題。一些現有模型可能沒有很好地解決這個問題,有時可能會生成一些不恰當或有潛在危害的內容。
針對這些挑戰,Gemma模型的設計考慮了提高性能、優化部署效率和加強安全性。Gemma利用了最新的研究成果和技術,以期在語言理解和推理方面達到更高的水平,并且能夠在各種設備上運行,包括個人電腦和移動設備。Gemma在開發過程中采取了一系列措施來確保生成內容的安全性和可靠性,比如使用自動化技術和人工反饋來細致調整模型的行為。Gemma模型的關鍵特點如下:
- 兩種規模: 提供Gemma 2B和Gemma 7B兩種規模,每種規模都有預訓練和指令調整(instruction-tuned)的變體。
- 負責任的生成式AI工具包: 提供創建更安全AI應用的指導和工具。
- 跨框架支持: 為JAX、PyTorch和通過原生Keras 3.0的TensorFlow提供推理和監督式微調(SFT)的工具鏈。
- 易于部署: 模型可以在筆記本電腦、工作站或Google Cloud上運行,并可在Vertex AI和Google Kubernetes Engine (GKE)上輕松部署。
- 性能優化: 模型針對NVIDIA GPU和Google Cloud TPU等多AI硬件平臺進行了優化,確保行業領先的性能。
架構
Gemma模型最初由Vaswani等人在2017年提出,因其出色的處理序列數據的能力而廣受歡迎。它在8192個token的上下文長度上進行訓練,這個長度足以捕捉到復雜的語言結構和上下文信息,從而使得模型能夠更好地理解和生成語言。
在核心參數方面,Gemma模型采用了一些創新的技術來提升性能和效率。模型引入了多查詢注意力機制,這是一種注意力分配方式,它允許模型在處理信息時更加靈活。對于7B參數的模型,設計者選擇了多頭注意力,這是一種并行處理多個注意力查詢的方法,能夠增強模型處理復雜信息的能力。而對于規模較小的2B參數模型,則采用了多查詢注意力,這在小規模模型中已被證明同樣有效,有助于模型在資源受限的情況下保持較好的性能。
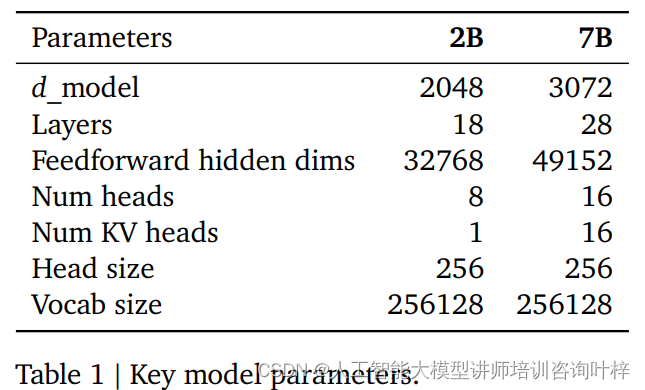
位置編碼是transformer模型中的關鍵組成部分,它使得模型能夠理解單詞在句子中的位置。Gemma模型采用了旋轉位置嵌入(RoPE),這是一種新穎的位置編碼方式,與傳統的絕對位置編碼相比,它通過旋轉機制能夠更有效地表達位置信息。RoPE還在輸入和輸出之間共享嵌入,這種做法不僅減少了模型的參數數量,還有助于模型在不同任務之間遷移知識。
激活函數在神經網絡中扮演著至關重要的角色,它為模型引入了非線性,使得模型能夠學習和模擬復雜的函數映射。Gemma模型采用了GeGLU激活函數的近似版本,這是一種改進的激活機制,相比于傳統的ReLU激活函數,GeGLU能夠更有效地捕捉數據中的復雜特征。
為了穩定訓練過程,Gemma模型使用了RMSNorm,這是一種歸一化技術,它對每個transformer子層的輸入進行歸一化處理。這種歸一化有助于防止訓練過程中的梯度爆炸或消失問題,從而使得模型能夠更穩定地學習,并提高最終性能。
訓練
Google DeepMind選擇使用TPUv5e作為訓練的核心硬件,TPUv5e是一種特別為機器學習任務設計的高性能張量處理單元。與傳統的CPU和GPU相比,TPU專為優化計算性能和能源效率而設計,尤其適合于處理大規模的深度學習模型。
在Gemma模型的訓練中,TPUv5e被部署在一個復雜的2D網絡結構中,每個pod包含256個芯片。這種配置允許模型在多個芯片上并行處理數據,極大地提高了計算速度和處理能力。對于7B參數的模型,訓練過程使用了16個pods,這意味著總共有4096個TPUv5e芯片被用于訓練,這是一個非常龐大的計算資源,能夠處理和訓練具有數十億參數的復雜模型。
對于較小的2B參數模型,預訓練過程則使用了2個pods,共計512個TPUv5e芯片。盡管使用的芯片數量較少,但這仍然是一個相當大的計算規模,足以支持模型的快速預訓練。
在訓練過程中,模型分片和數據復制技術被用來進一步提高效率。模型分片是指將模型的不同部分分布到不同的芯片上進行處理,這樣可以并行地更新模型的參數,加速訓練過程。數據復制則是在不同的芯片上復制數據,確保每個芯片都有獨立的數據副本進行計算,這有助于減少數據傳輸的延遲,提高計算效率。
Gemma模型的訓練還借助了Jax和Pathways的編程范式。Jax是一個用于高性能機器學習研究的Python庫,它允許研究人員以一種簡潔和高效的方式表達復雜的神經網絡模型。Pathways則是一個用于構建和部署大規模機器學習應用的框架,它提供了一種簡化的開發流程,使得處理像Gemma這樣的大型模型變得更加容易。
Gemma模型的預訓練涉及到使用大量的文本數據來訓練模型,以便模型能夠理解和生成自然語言。在這個過程中,Gemma模型使用了來自網絡文檔、數學和代碼領域的數據,這些數據主要是英文的。具體來說,2B參數的模型被訓練了3萬億個token,而7B參數的模型則訓練了6萬億個token,這樣的數據量為模型提供了豐富的語言信息和模式。
與Gemini模型不同,Gemma模型在設計時并沒有采用多模態技術,也就是說,它沒有結合文本之外的其他類型的數據,如圖像或視頻。此外,Gemma也沒有專門針對多語言任務進行訓練,這與一些旨在實現多語言理解最先進的性能的模型有所區別。Gemma模型的設計選擇反映了DeepMind團隊專注于英文文本數據,以實現在特定領域的深度理解和生成能力。
在預訓練數據的選擇和處理上,Gemma模型的團隊采取了謹慎的措施。他們對數據集進行了過濾,目的是減少模型可能生成不良或不安全話語的風險。這包括去除那些可能引發爭議或不適當的內容,確保模型在生成文本時能夠符合安全和道德標準。
預訓練過程中特別注意了個人身份信息和其他敏感數據的過濾。這是因為數據中的個人信息如果被模型學習并在未來生成的文本中使用,可能會引發隱私泄露和安全問題。通過過濾掉這些敏感信息,Gemma模型旨在保護用戶的隱私,并遵守數據保護的相關法律法規。
過濾過程不僅涉及到簡單的規則和啟發式方法,還可能包括更復雜的模型驅動的分類器,這些分類器能夠識別并排除有害或低質量的內容。此外,為了進一步確保模型的安全性和可靠性,過濾后的數據還會經過詳盡的評估和測試,以檢查是否存在潛在的問題。
指令調整
在Gemma模型的開發過程中,指令調整是一個關鍵步驟,旨在提升模型對用戶指令的理解和執行能力。這個過程主要通過兩種方法實現:監督式微調(SFT)和基于人類反饋的強化學習(RLHF)。

在SFT階段,Gemma模型接受了大量文本合成的英語提示響應對的訓練。這些數據對由基礎模型生成的可能響應和測試模型生成的實際響應組成。通過這種方式,模型學習如何根據給定的指令生成更加準確和有用的回答。SFT的目的是通過直接的監督學習,讓模型更好地掌握如何遵循指令和生成合適的輸出。
SFT階段還包括了對模型輸出的人類評估。在這一過程中,人類評估員會根據模型生成的回答質量和相關性提供反饋。這些反饋被用來進一步指導和優化模型,使其更符合人類的偏好和期望。
RLHF階段則采用了一種更為互動的方法來提升模型性能。在這個階段,模型的表現通過人類提供偏好來評估,即人類評估員會對比模型生成的不同回答,并選擇他們認為更好的一個。這些偏好信息被用來訓練一個獎勵模型,該模型能夠捕捉到人類對模型輸出的滿意度。然后,這個獎勵模型指導Gemma模型通過強化學習算法進行優化,以生成更符合人類期望的輸出。
在指令調整過程中,數據的質量和安全性至關重要。過濾機制被用來清除那些可能包含個人信息、不安全內容或有毒輸出的數據。確保了模型在訓練過程中不會被不良數據影響,同時也保護了用戶的隱私和安全。

過濾還涉及到去除錯誤的自我識別數據,即那些可能導致模型錯誤理解自身身份或功能的信息。此外,任何重復的例子也會被過濾掉,以避免模型過度擬合特定的數據模式,從而影響其泛化能力。
評估
Gemma模型的評估不僅涵蓋了自動化的基準測試,還包括了人類評估研究,以確保模型的實際應用能夠滿足用戶的期望和需求。
在自動化基準測試方面,Gemma模型接受了廣泛的測試,包括物理推理、社會推理、問題回答、編程、數學、常識推理、語言建模、閱讀理解等多個領域。例如,在數學問題解決方面,Gemma模型在GSM8K和MATH基準測試中表現出色,顯示出其強大的分析和解決問題的能力。此外,在編程任務的MBPP基準測試中,Gemma模型也超越了其他開放模型,顯示了其在代碼生成和理解方面的高超技巧。
人類偏好評估是評估過程中的另一個重要部分。Gemma模型的最終版本被提交給人類評估員,與現有的其他模型如Mistral v0.2 7B Instruct模型進行了比較。在一系列約1000個提示的測試中,這些提示旨在讓模型執行創意寫作任務、編程和遵循指令,Gemma 7B IT模型以61.2%的正面勝率勝過Mistral v0.2 7B Instruct,而Gemma 2B IT模型的勝率為45%。在測試基本安全協議的約400個提示中,Gemma 7B IT模型的勝率為63.5%,Gemma 2B IT模型的勝率為60.1%。
為了確保評估的全面性和公正性,Gemma模型的評估使用了與Gemini模型相同的方法論,并盡可能地模仿了Mistral技術報告中的評估方法。這些評估包括了ARC、CommonsenseQA、Big Bench Hard和AGI Eval等基準測試。由于許可限制,Gemma模型無法在LLaMA-2上運行評估,因此只能引用之前報告的指標。
在安全性方面,Gemma模型同樣進行了嚴格的測試。通過與類似規模的開放模型進行比較,Gemma 1.1 IT模型在多個標準安全基準測試中的表現出色,在6個測試中勝過競爭對手。此外,Gemma模型在人類并行評估中也展現出了優勢。
為了評估模型對訓練數據的記憶能力,Gemma模型還經過了記憶評估測試。測試結果顯示,Gemma模型對英文網絡內容的記憶率相當低,這表明模型并沒有簡單地記憶訓練數據,而是能夠進行更深入的理解和推理。

通過這些綜合評估,Gemma模型證明了自己在各種任務中的高性能和可靠性,同時也展示了其在安全性和抗記憶性方面的優勢。這些評估結果為Gemma模型的進一步開發和應用提供了堅實的基礎,并為用戶提供了對其性能和能力的深入了解。
技術報告:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
使用地址:https://ai.google.dev/gemma



![[我靠升級逆襲成為大師]韓漫日漫無刪減完整版,免費在線觀看漫畫](http://pic.xiahunao.cn/[我靠升級逆襲成為大師]韓漫日漫無刪減完整版,免費在線觀看漫畫)

:Nuitka庫)




)






--perception:elevation_map_loader/euclidean_cluster)
299)
)