在介紹緩存的false sharing之前,本文先介紹一下多核系統中緩存一致性是如何維護的。
目前主流的多核系統中的緩存一致性協議是MESI協議及其衍生協議。
MESI協議
MESI協議的4種狀態
MESI協議有4種狀態。MESI是4種狀態的首字母縮寫,緩存行的4種狀態分別如下。
(1)修改(Modified):表示數據只在本處理器的緩存中存在副本,數據是臟的,即數據被修改過,沒有寫回到內存。
(2)獨占(Exclusive):表示數據只在本處理器的緩存中存在副本,數據是干凈的,即副本和內存中的數據相同。
(3)共享(Shared):表示數據可能在多個處理器的緩存中存在副本,數據是干凈的,即所有副本和內存中的數據相同。
(4)無效(Invalid):表示緩存行中沒有存放數據。
MESI協議的消息
為了維護緩存一致性,處理器之間需要通信,MESI協議提供了以下消息。
(1)讀(Read):包含想要讀取的緩存行的物理地址。
(2)讀響應(Read Response):包含讀消息請求的數據。讀響應消息可能是由內存控制器發送的,也可能是由其他處理器的緩存發送的。如果一個處理器的緩存有想要的數據,并且處于修改狀態,那么必須發送讀響應消息。
(3)使無效(Invalidate):包含想要刪除的緩存行的物理地址。所有其他處理器必須從緩存中刪除對應的數據,并且發送使無效確認消息來應答。
(4)使無效確認(Invalidate Acknowledge):處理器收到使無效消息,必須從緩存中刪除對應的數據,并且發送使無效確認消息來應答。
(5)讀并且使無效(Read Invalidate):包含想要讀取的緩存行的物理地址,同時要求從其他緩存中刪除數據。它是讀消息和使無效消息的組合,需要接收者發送讀響應消息和使無效確認消息。
(6)寫回(Writeback):包含想要寫回到內存的地址和數據。
MESI協議的狀態轉換
緩存行狀態的轉換如下圖所示。
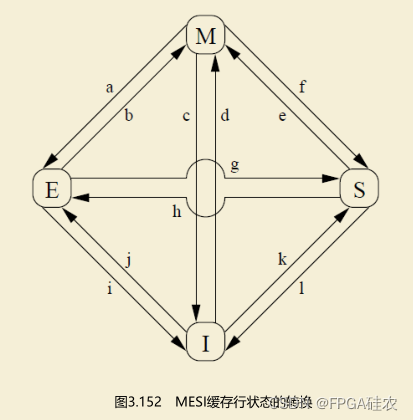
(1)轉換a,修改M到獨占E:處理器收到寫回消息,把緩存行寫回內存,但是緩存行保留數據。
(2)轉換b,獨占E到修改M:處理器寫數據到緩存行。
(3)轉換c,修改M到無效I:處理器收到“讀并且使無效”消息,發送讀響應消息和使無效確認消息,刪除本地副本(不需要寫回內存,因為發送“讀并且使無效”消息的處理器需要寫數據)。
(4)轉換d,無效I到修改M:處理器寫不在本地緩存中的數據,發送“讀并且使無效”消息,通過讀響應消息收到數據。處理器可以在收到所有其他處理器的使無效確認消息以后轉換到修改狀態M。
(5)轉換e,共享S到修改M:處理器寫數據,該數據在緩存中命中,則只需發送使無效消息,收到所有其他處理器的使無效確認消息以后轉換到修改狀態M。
(6)轉換f,修改M到共享S:其他處理器讀取緩存行,發送讀消息,本處理器收到讀消息后,寫回內存,保留一個只讀副本,發送讀響應消息。
(7)轉換g,獨占E到共享S:其他處理器讀取緩存行,發送讀消息,本處理器收到后發送讀響應消息,保留一個只讀副本。
(8)轉換h,共享S到獨占E:本處理器意識到很快需要寫數據,發送使無效消息,收到所有其他處理器的使無效確認消息以后轉換到獨占狀態E。
(9)轉換i,獨占E到無效I:其他處理器寫數據,發送“讀并且使無效”消息,本處理器收到消息后,發送讀響應消息和使無效確認消息。
(10)轉換j,無效I到獨占E:處理器寫不在本地緩存中的數據,發送“讀并且使無效”消息,收到讀響應消息和所有其他處理器的使無效確認消息后轉換到獨占狀態E,完成寫操作后轉換到修改狀態M。
(11)轉換k,無效I到共享S:處理器加載不在本地緩存中的數據,發送讀消息,收到讀響應消息后轉換到共享狀態S。
(12)轉換l,共享S到無效I:其他處理器寫本地緩存中的數據,發送使無效消息,本處理器收到后,把緩存行的狀態轉換為無效,發送使無效確認消息。
false sharing偽共享
false sharing概念
定義:當多線程修改互相獨立的變量時,如果這些變量共享同一個緩存行,就會無意中影響彼此的性能,這就是偽共享。
Cache和內存之間交換數據的最小粒度不是字節,而是稱為cache line的一塊固定大小的區域,緩存行是內存交換的實際單位。緩存行是2的整數冪個連續字節,一般為32~256個字節,最常見的緩存行大小是64個字節。
在寫多線程代碼時,為了避免使用鎖,通常會采用這樣的數據結構:根據線程的數目,安排一個數組, 每個線程一個項,互相不沖突。從邏輯上看這樣的設計無懈可擊,但是實踐的過程可能會發現有些場景下非但沒提高執行速度,反而性能會很差。
問題在于cpu的Cache Line,當多線程修改互相獨立的變量時,如果這些變量共享同一個緩存行,就會無意中影響彼此的性能,這就是偽共享,即false-sharing。
例如,在Intel Core 2 Duo處理器平臺上,L2 cache是由兩個core共享的,而L1 data cache是分開的,由兩個core分別存取。cache line的大小是64 Bytes。假設有個全局共享結構體變量f由2個線程A和B共享讀寫,該結構體一共8個字節同時位于同一條cache line上。
struct foo {int x;int y;
};
若此時兩個線程一個讀取f.x另一個讀取f.y,即便兩個線程的執行是在獨立的cpu core上的,實際上結構體對象f被分別讀入到兩個CPUs的cache line中且該cache line 處于shared狀態。若此時在核心1上運行的線程A想更新變量X,同時核心2上的線程B想要更新變量Y,則:
如果核心1上線程A優先獲得了所有權,線程A修改f.x會使該CPU core 1上的這條cache line將變為modified狀態,另一個CPU core 2上對應的cache line將變成invalid狀態;此時若線程B馬上讀取f.y,為了確保cache一致性,B所在CPU核上的相應cache line的數據必須被更新;當核心2上線程B優先獲得了所有權然后執行更新操作,核心1就要使自己對應的緩存行失效。這會來來回回的經過L3緩存,影響性能。如果互相競爭的核心位于不同的插槽,就要額外橫跨插槽連接,若讀寫的次數頻繁,將增大cache miss的次數,嚴重影響系統性能。
雖然在memory的角度這兩種訪問是隔離的,但是由于錯誤的緊湊地放在了一起,使得兩個變量處于同一個緩存行中。每個線程都要去競爭緩存行的所有權來更新變量。可見,false sharing會導致多核處理器上對于緩存行Cache Line的寫競爭,造成嚴重的系統性能下降,有人將偽共享描述成無聲的性能殺手,因為從代碼中很難看清楚是否會出現偽共享。
false-sharing避免方法
把每個項湊齊Cache Line的長度,即可實現隔離,雖然這不可避免的會浪費一些內存。
- 對于共享數組而言,增大數組元素的間隔使得由不同線程存取的數組元素位于不同的Cache Line上,使一個核上的Cache line修改不會影響其它核;或者在每個線程中創建全局數組的本地拷貝,然后執行結束后再寫回全局數組,此方法比較粗暴不優雅。
- 對于共享結構體而言,使每個結構體成員變量按照Cache Line大小(一般64B)對齊。可能需要使用#pragma宏。

![[數據集][目標檢測]螺絲螺母檢測數據集VOC+YOLO格式2400張2類別](http://pic.xiahunao.cn/[數據集][目標檢測]螺絲螺母檢測數據集VOC+YOLO格式2400張2類別)












實驗)

)


