目錄
1. 簡介
2. 具體流程
2.1 校準激活
2.2?量化感知訓練
2.3?量化校準配置
2.4?quantization 函數
3. 總結
1. 簡介
想象一下,你有一個非常聰明的機器人朋友,它可以幫你做很多事情,比如預測天氣。但是,這個機器人的大腦(我們可以把它想象成一個神經網絡模型)需要很多能量和空間來思考(也就是進行計算和存儲數據)。現在,如果我們想讓這個機器人更小巧,更省電,還能快速做出預測,我們就需要采用一些特殂的技巧。
這時,Vitis AI 量化器就像一個魔法工具,它可以幫助機器人的大腦變得更高效。原來,機器人的大腦用一種非常詳細(32位浮點)的方式來記住信息,這種方式雖然精確,但是需要很多空間和能量。Vitis AI 量化器通過一種叫做“量化”的魔法,把這些詳細的信息轉換成更簡單(8位整數)的形式。這樣做雖然會讓信息變得不那么精確,但是我們可以通過一些技巧,讓機器人的預測能力幾乎不受影響。
這個魔法包括幾個步驟:
- 自定義操作檢查:先檢查一下機器人的大腦里是否有些特殊的思考方式是我們需要特別注意的。
- 量化:用魔法把復雜的信息變成簡單的形式。
- 校準:調整一下這個簡化后的大腦,確保它還能準確地做出預測。
- 微調:進一步調整和優化,讓機器人的大腦運行得更順暢。
- 模型轉換:最后,把這個優化后的大腦轉換成一種特殊的格式,這樣它就可以更容易地被部署到不同的地方,比如小巧的設備上。
通過這個過程,機器人的大腦變得更小,更省電,而且還能快速做出準確的預測。這樣,我們就可以把這個聰明的機器人帶到更多的地方去,讓它幫助更多的人。
2. 具體流程
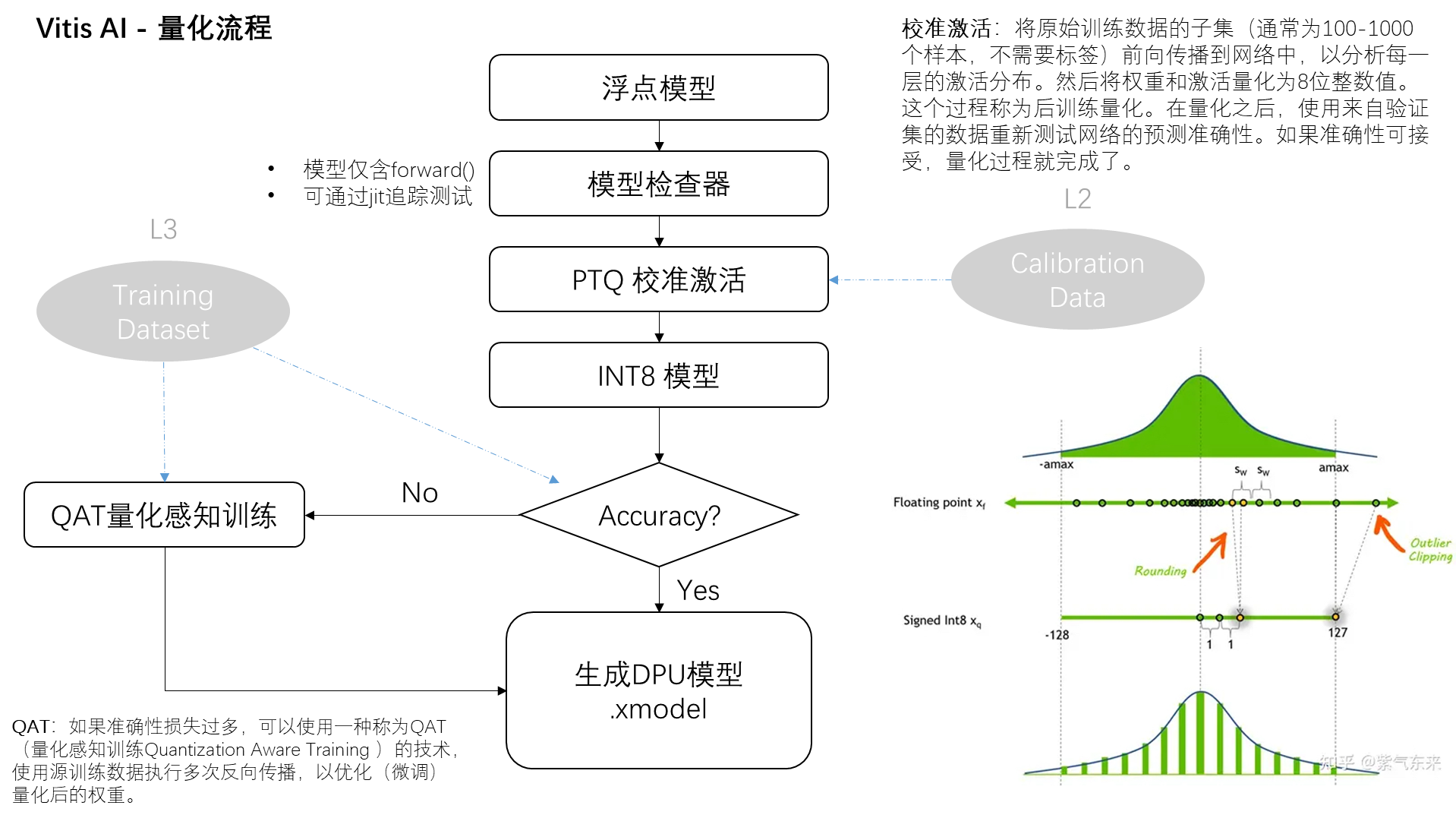
2.1 校準激活
當我們談論“校準激活”這個過程時,我們實際上在討論的是一個將神經網絡模型調整為更高效版本的關鍵步驟,這一步驟是在所謂的后訓練量化過程中進行的。讓我們一步一步地詳細解釋這個過程:
- 選擇數據樣本
首先,我們需要從原始的訓練數據中挑選出一個子集。這個子集不需要很大,通常包含100到1000個樣本,而且不需要樣本的標簽(即我們不需要知道這些數據的正確答案是什么)。這個子集的目的是幫助我們理解模型在處理不同數據時的行為模式。
- 前向傳播
接下來,我們將這個數據子集通過神經網絡進行前向傳播。前向傳播簡單來說,就是讓數據通過網絡的每一層,從輸入層開始,一直到輸出層。在這個過程中,網絡的每一層都會對數據進行一些計算和轉換,這些轉換是由該層的權重(即該層學習到的參數)和激活函數(一種特定的數學函數,用于決定神經元是否應該被激活)控制的。
- 分析激活分布
當數據通過網絡前向傳播時,我們會分析網絡中每一層的“激活分布”。激活分布基本上是指,在數據通過網絡層時,神經元輸出值的分布情況。這是非常重要的信息,因為它可以幫助我們了解數據是如何在網絡中流動的,以及每一層是如何對數據進行處理的。
- 量化權重和激活
一旦我們有了關于激活分布的信息,我們就可以開始將權重和激活值從32位浮點數轉換為8位整數值。這個過程稱為量化。通過量化,我們可以顯著減小模型的大小和計算需求,同時盡量保持模型的預測準確性不變。
2.2?量化感知訓練
QAT(Quantization-Aware Training,量化感知訓練)是一種特殊的神經網絡訓練方法,它在訓練過程中就考慮到了模型最終會被量化(即權重和激活值會被轉換成較低精度格式,如8位整數)的事實。通過這種方式,QAT旨在訓練出一個在量化后仍能保持高性能的模型。
QAT的工作原理
- 在傳統的訓練過程中,模型通常在浮點數(如32位浮點數)環境下進行訓練和優化。然而,當模型被量化(為了部署在資源受限的設備上)時,模型的性能可能會因為精度損失而下降。為了緩解這個問題,QAT采用了一種在訓練過程中就模擬量化效果的方法。
- 模擬量化:在訓練過程中,QAT通過在前向傳播和反向傳播時模擬權重和激活值的量化效果,使模型“意識到”其將在低精度環境中運行。這意味著模型的訓練不僅要考慮如何最小化誤差,還要學會在量化帶來的限制條件下保持性能。
- 微調和優化:通過這種訓練方式,模型可以在量化的約束下學習到更魯棒的特征表示。此外,訓練過程中還可以對量化操作進行微調和優化,比如調整量化參數(比如量化的比例因子),以進一步減小量化帶來的誤差。
- 減少性能損失:最終,通過QAT訓練的模型在被量化到低精度格式后,其性能損失會比傳統訓練后直接量化的模型小很多。這意味著可以在保持較高預測精度的同時,享受量化帶來的好處(如模型尺寸更小,推理速度更快,功耗更低)。
QAT的優勢
- 高效的模型部署:通過QAT,可以更有效地將深度學習模型部署到資源受限的硬件上,如移動設備、嵌入式系統等。
- 性能和精度的平衡:QAT提供了一種有效的方法來平衡模型的性能和精度,使得在量化后的模型仍能保持接近其原始浮點數模型的預測精度。
- 加速推理過程:由于量化后的模型有更小的模型尺寸和更快的推理速度,QAT有助于加速模型的推理過程,使其更適合實時應用場景。
2.3?量化校準配置
量化校準配置文件的目錄在?config_file = "./configs/mix_precision_config.json"
| 配置名 | 解釋 | 選項 |
| convert_relu6_to_relu | 是否將ReLU6轉換為ReLU | true、false |
| include_cle | 是否使用跨層均衡(cross layer equalization) | true、false |
| include_bias_corr | 是否使用偏差校正 | true、false |
| keep_first_last_layer_accuracy | 是否跳過對第一層和最后一層進行量化(未啟用) | FALSE |
| keep_add_layer_accuracy | 是否跳過對"add"層進行量化(未啟用) | FALSE |
| target_device | 部署量化模型的設備 | DPU、CPU、GPU |
| quantizable_data_type | 模型中要進行量化的張量類型 | |
| datatype | 用于量化的數據類型 | int、bfloat16、float16、float32 |
| bit_width | 用于量化的比特寬度 | |
| method | 用于校準量化的方法 | maxmin、percentile、entropy、mse、diffs |
| round_mode | 量化過程中的舍入方法 | half_even、half_up、half_down、std_round |
| symmetry | 是否使用對稱量化 | true、false |
| per_channel | 是否使用通道級別的量化 | true、false |
| signed | 是否使用有符號量化 | true、false |
| narrow_range | 是否對有符號量化使用對稱整數范圍 | true、false |
| scale_type | 量化過程中使用的尺度類型 | float、poweroftwo |
| calib_statistic_method | 如果使用多批次數據獲得不同的尺度,用于選擇一個最優尺度的方法 | modal、max、mean、median |
2.4?quantization 函數
使用PyTorch框架和Xilinx Vitis AI量化工具(通過pytorch_nndct模塊)的一個示例:
# 創建量化器對象,并獲取量化模型
from pytorch_nndct.apis import torch_quantizer
quantizer = torch_quantizer(quant_mode, model, (dummy_input), device=device, quant_config_file=config_file, target=target)
quant_model = quantizer.quant_modelloss_fn = torch.nn.CrossEntropyLoss().to(device)
val_loader, _ = load_data(…)if finetune == True:ft_loader, _ = load_data(…)if quant_mode == 'calib':quantizer.fast_finetune(evaluate, (quant_model, ft_loader, loss_fn))elif quant_mode == 'test':quantizer.load_ft_param()acc1_gen, acc5_gen, loss_gen = evaluate(quant_model, val_loader, loss_fn)if quant_mode == 'calib':quantizer.export_quant_config()
if deploy:quantizer.export_torch_script()quantizer.export_onnx_model()quantizer.export_xmodel()
?代碼的主要功能和步驟包括:
- 創建量化器對象:使用torch_quantizer函數創建一個量化器對象,這個對象用于管理模型的量化過程。這里需要指定量化模式(quant_mode),可以是calib(校函量化模式)或test(測試量化模型性能模式),模型本身,一個虛擬輸入(dummy_input)用于模型推理,以及其他配置如設備(device),量化配置文件(quant_config_file)和目標平臺(target)。
- 獲取量化模型:通過量化器對象的quant_model屬性獲取量化后的模型。這個模型將用于后續的校準、微調和評估。
- 加載數據:加載驗證數據集(val_loader),如果需要微調(finetune為True),也會加載微調數據集(ft_loader)。
- 微調和校準:如果設置了微調,根據量化模式執行相應的操作。在calib模式下,使用fast_finetune方法進行快速微調,以優化模型的量化參數;在test模式下,使用load_ft_param方法加載已經微調過的參數。
- 評估量化模型性能:使用evaluate函數評估量化模型在驗證數據集上的性能,包括準確率(acc1_gen和acc5_gen)和損失(loss_gen)。
- 導出量化配置和模型:如果是calib模式,使用export_quant_config方法導出量化配置。此外,如果設置了部署(deploy為True),則會導出用于部署的模型,包括Torch Script(export_torch_script)、ONNX模型(export_onnx_model)和Xilinx特定的xmodel(export_xmodel)。
3. 總結
在當今技術快速發展的時代,我們追求的不僅是智能設備的高性能,同時也強調其能效和便攜性。Vitis AI量化器便是在這樣的背景下應運而生的一個工具,它通過將神經網絡模型的數據精度從32位浮點數降低到8位整數,極大地縮減了模型的體積和計算需求,而通過精心設計的校準和微調過程,又能確保模型的預測準確性基本不受影響。這一過程不僅包括了校準激活、量化感知訓練等關鍵步驟,還提供了詳細的量化校準配置和實用的量化函數,以適應不同的部署需求。通過這種方式,Vitis AI量化器使得深度學習模型能夠更加輕松地被部署到資源受限的設備上,無論是在移動設備、嵌入式系統還是其他平臺,都能夠實現快速、高效的智能計算,為用戶帶來更加豐富和流暢的體驗。


)

)










,可能會遇到表被鎖定的問題。)




