主從結構
MongoDB的高可用和別的中間件的高可用方案基本類似。比如在MySQL里,接觸了分庫分表和主從同步;在Redis里,Redis也有主從結構;在Kafka里,分區也是有主從結構的。
所以先介紹啟用了主從同步
我們的系統有一個關鍵組件 - MongoDB,但是在最開始的時候,MongoDB沒有啟用主從,是一個單節點的。因此每年總會有一兩次,MongoDB崩潰不可用。所以我把MongoDB改成了主從同步,最開始的時候業務量不多,為了節省成本,我們用了推薦的配置一主兩從。這種改變的好處是:當主節點崩潰后,從節點可以選舉出一個新的主節點。
直接說用了幾個主從節點,如果問到主從同步的話,回答oplog的內容。
引入仲裁節點
另一種思路是引入仲裁節點,所謂仲裁節點是指這個節點參與主從集群的主節點選舉,但是只參與投票,類似于Elasticsearch里的僅投票節點。
這種機制在別的中間件也見過了,這類節點的好處在于它們只參與投票,也就是只關心主從選舉,所以只需要很少的資源就可以運行起來
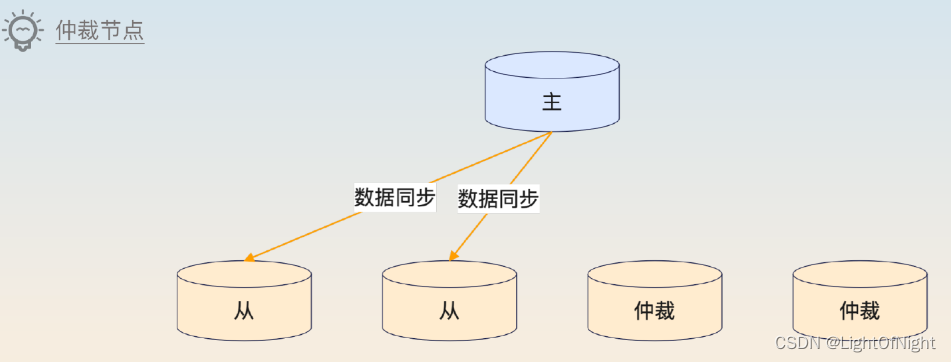
最開始的時候,我們只是部署了一主兩從,兩個從節點都會同步數據。后面為了進一步提高可用性,引入了仲裁節點。這些仲裁節點被部署在輕量級的服務器上,成本非常低。在引入了這些仲裁節點后,就算有一個從節點崩潰了,整個集群也基本沒什么影響,因為這個時候還是有足夠的節點可以投票
啟用主從模式的配置服務器
我們MongoDB最開始部署的時候,配置服務器并沒有啟用主從模式,畢竟當時想節省資源。但是后面發現,配置服務器這個對集群的影響太大了,一旦不可用,整個集群就基本不可用了。這種情況下,我們只好引入了主從結構的配置服務器。目前配置服務器本身就有一主兩從。
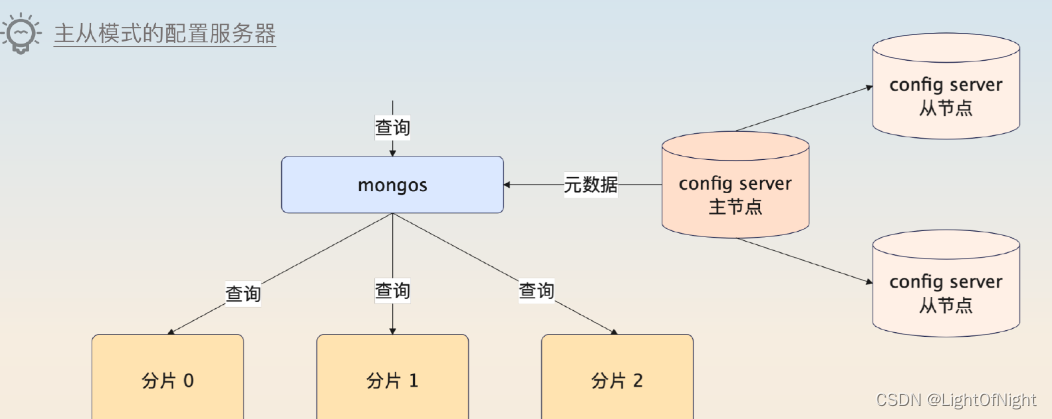
雖然主節點還是存在崩潰的可能,但是在主節點崩潰之后會有主從選舉。更加重要的是,在主節點崩潰之后,整個配置服務集群還是可讀的。而我們也知道,在一個 MongoDB 集群里面,元數據也是讀多寫少的。兩者一結合,整個 MongoDB 集群的可用性就提高了。
多數據中心的主從結構
在MongoDB里有一個推薦的架構
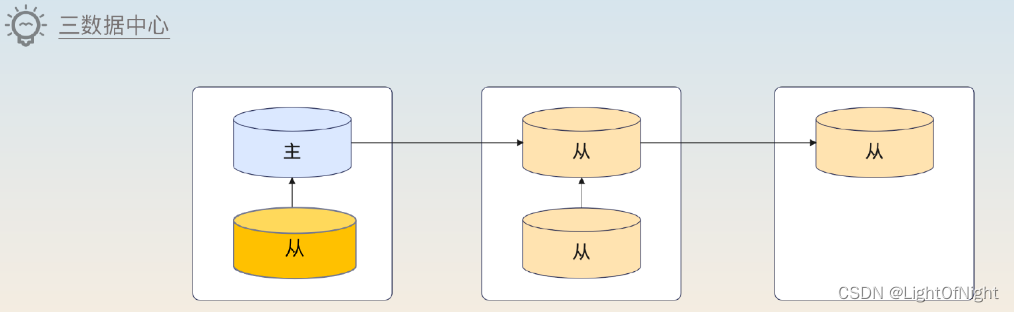
不過整除來說,大部分公司沒那么多資源部署,一個簡化版本就是用兩個數據中心,部署一主三從或兩從。
我們公司本身業務規模比較大,對MongoDB的依賴也很嚴重,所以我們還部署了多數據中心的主從結構。有兩個數據中心(可以同域,可以異地),其中一個數據中心,部署了一主一從,另外一個數據中心部署了兩個從節點。萬一一個數據中心崩潰了,另一個數據中心也還是可用的。

在主從選舉的時候,我們也會傾向于選擇和主節點在同一個數據中心的從節點,也就是圖里面深黃色的從節點。因為正常來說,同一個數據中心內部的從節點,數據會比較新。
同時為了保證在主從選舉的時候優先選擇同一個數據中心的節點,我們還調整了從節點的優先級。
在整個主從結構都面完了之后,你進一步總結一下。
基本上目前主流的這種大型中間件,在提高可用性上用的方法無外乎就是分片和主從結構。除了 MongoDB,類似的還有 Redis、Elasticsearch、Kafka。
引入分片
分片既可以提高可用性,也可以提高性能。在MongoDB里,引入分片比關系型數據庫簡單很多,可以直接說在開發新業務的時候就啟用了分片功能
隨著業務的增長,后面使用MongoDB的時候,都要求開啟分片功能,來進一步提高可用性的性能。
另一種思路是為已有的數據添加分片功能。
最后也要總結下
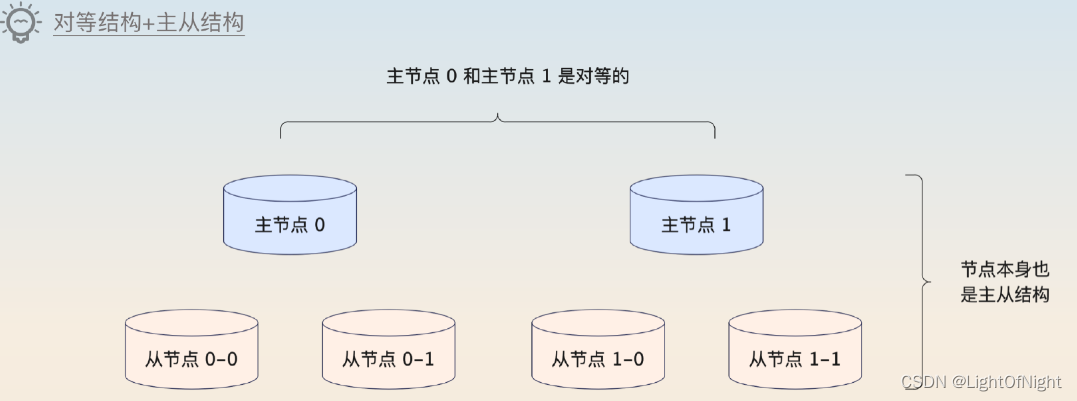
目前來說,支持大數據高并發的中間件基本上也有類似的分片功能。或者說,這一類的中間件明面上都是對等結構,而對等結構里面的每一個“節點”又是一個主從集群。就算是關系型數據庫的分庫分表,也可以看作是這種對等結構 + 主從結構的模式。
調整寫入語義
寫入語義的調整一般有兩種思路,一是朝著可用性的角度調整,另一個是朝著性能的角度調整。
以可用性為例
最開始的時候,我們遇到過一個 Bug,就是數據寫入到 MongoDB 之后,偶爾會出現數據丟失的問題。因為之前我在 Kafka 上也遇到過類似的問題,所以我就懷疑是不是寫入語義沒做好。然后我就去排查,果然有發現,在這個數據丟失的場景下,Write Concern 的 w 取值不是默認的 majority,而是 1,也就是說只需要主節點寫入就可以。 很明顯,在這種情況下,萬一寫入之后主節點崩潰了,那么從節點就算被提升成主節點,也沒有這一條數據。所以,后面我就把這個改回了 majority。同時我還去排查了一個 j 參數,確認設置成了 true。這樣一來,數據就不太可能丟失了。










,可能會遇到表被鎖定的問題。)








