《易經》:“初九:潛龍勿用”。潛龍的意思是隱藏,陽氣潛藏,陽爻位于最下方稱為“初九”,龍潛于淵,是學而未成的階段,此時需要打好基礎。
而模塊一我們就是講解推薦系統有關的概念、基礎數據體系搭建、埋點上報、用戶和物品畫像、標簽挖掘、AB 測試系統等各基礎知識,助你快速了解互聯網業務場景及推薦系統的作用。
這一講作為模塊一的第一講,有必要先來了解一下個性化流量分發體系的整個搭建流程。
在課程開始之前,我們先看一個例子:
在日常生活中,打開 58 同城網站時,我們可能會遇到以下情形:
-
和好友同時打開 App,發現我倆的首頁金剛區本地服務的圖標和文字不一樣?
-
搜索“小區搬家”,發現首頁搜索框里的推薦詞也發生了變化。

58 同城怎么知道我需要什么樣的本地服務?為什么搜索框里的推薦詞也發生了變化?這就涉及這一講要講的內容——個性化流量分發體系。
以平臺是否掌控整體流量分配情況為依據,我們把個性化流量分發體系的模式分為中心化模式和去中心化模式。為了方便你理解,我們再拿 58 同城舉例(主要看下中心化模式)。我們知道 58 同城 App 首頁有搜索框、分類宮格式導航、部落信息輪播、頭條欄目、猜你喜歡推薦等業務模塊,流量就是通過這樣的設計模式從首頁中心化分配到其他各個業務模塊。
相信你對個性化流量分發體系已經有了初步了解,接下來我們繼續揭開它的真面目。
個性化流量分發體系
那到底什么是個性化流量分發體系呢?個性化流量分發體系是通過、策略手段來平衡用戶體驗和商業目標。在這個過程中,我們需要把用戶的訪問流量合理分配到各個流量利用區,促進流量利用最大化,或者說獲得流量最大限度轉化,最終提升流量價值,從而達到戰略意圖。因此,個性化流量分發體系的本質就是對整個產品的用戶行為路徑進行優化。
在個性化流量分發體系搭建過程中,數據是非常重要的資產,也是驅動決策的燃料。這里提及的數據,主要指的是基本信息、顯式反饋、隱式反饋這三種。
-
基本信息:主要指用戶的性別/年齡/地區、物品的分類/款式/重量等。
-
顯式反饋:一般指用戶對物品的真實評分,這類數據的特點是用戶操作成本高,數據量小,更真實。
-
隱式反饋:一般指除直接評分以外的若干用戶行為數據,包括點擊、加購、收藏、購買、瀏覽時長等,這類數據特點是用戶操作成本低、數據量大、具有一定的不真實性。用戶行為數據還可以進一步通過聚合、梳理形成用戶的行為表現數據(如活躍度、回訪、復購情況等)。
而個性化流量分發的過程,其實就是先對基本數據和反饋數據進行加工,再利用加工結果進行決策的過程。在數據流轉的過程中,個性化流量分發體系被劃分為數據采集層、數據加工層、數據決策層、效用評價層這 4 層。
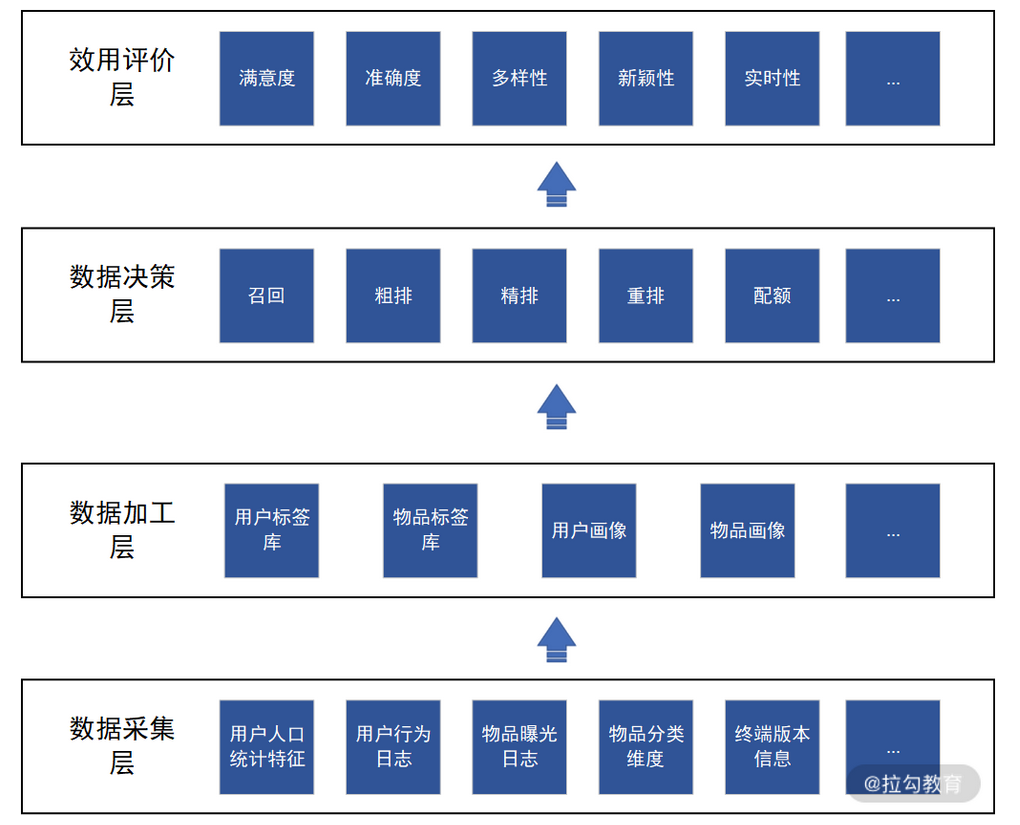
個性化流量分發體系架構
從上圖可知,在數據采集階段,我們的主要工作是全面了解產品和用戶。在數據加工階段,我們的主要工作是對用戶和物品分門別類。在數據決策階段,我們的主要工作是驅動分發方案和產品優化,這也是搜索和推薦等產品的工程和算法能力輸出階段。在效用評價階段,我們的主要工作是評估流量分發的效果并形成數據反饋。
接下來我們著重講解在數據采集階段,我們都需要做哪些工作?
特殊說明:數據加工階段的內容我們將在 02 講和 03 講中著重講解,效用評價階段的內容在 04 講中著重說明,而數據決策階段因為是推薦系統的核心,也是本專欄的重中之重,所以會放在模塊二、三、四、五中進行深度說明。
數據采集階段
《道德經》中說“九層之臺,起于累土”,數據采集階段作為后面三個階段的基礎,雖然它不涉及復雜算法,但這個階段的工作內容相對細碎且容易出錯,因此我們有必要從細微處著手,先把地基打牢。
在實際業務中,如果我們擁有海量數據,但是采集的數據質量很差,那么此時就算使用再好的算法也是“巧婦難為無米之炊”,并會使得后面三個階段徒勞無功。由此可見,數據采集階段的意義重大。
在數據采集階段,它的最大價值是規范、高效、準確地獲取海量數據,以此保證數據的準確性,防止數據出現偏差。
下面,我們通過一張圖了解整個數據采集流程,以及在這個階段我們需要做哪些工作。

數據采集流程
從圖中可知,數據采集流程包括數據需求梳理、埋點規范制定、埋點實施、數據上報、生成數據表、數據驗收等流程。而在數據采集之前,我們的首要工作是數據需求梳理、埋點規范構建、埋點位置梳理。
(1)數據需求梳理
在真實業務中,數據需求的來源一般都比較廣,除推薦系統的需求外,還包括營銷、畫像、廣告、標簽等需求。
面對諸多需求時,我們不僅需要構建靈活的數據埋點上報規范,還要滿足業務的現有需求,更重要的是要為將來可能出現的需求留出擴展空間。這就要求我們將條理化的業務指標體系(即數據需求)梳理成具體實施需求,而解決該問題的關鍵在于下面三個步驟。
步驟一:確認事件與變量
事件指的是我們需要分析的數據來源,最終它是一個結果性指標,比如支付成功。而變量指的是事件的維度或屬性,比如用戶性別、商品的種類。
這里我們可以將事件視為產品中的操作,例如加入購物車、支付成功,然后將變量視為描述事件的屬性,比如不同商品的加購次數中,商品名稱就是變量。
特殊說明:如果從不同的角度定位一個問題,事件和變量都會發生改變,這就要求我們基于數據需求,找到事件與變量之間搭配的最優解。
步驟二:明確事件的觸發時機
在這個過程中,我們需要思考什么時候才是記錄事件的合理時機,因為不同的時機其分享成功率也不一樣,同時不同的觸發時機將帶來不同的數據口徑。例如分享成功事件面臨用戶點擊微信發生分享動作、用戶分享后跳轉到相應頁面這 2 個時機。因此,數據使用者需要明確事件的觸發時機。
時機的選擇沒有對錯之分,我們根據具體的業務需求來制定即可。
步驟三:明確實施優先級
在實際業務中,業務部門必須基于業務指標明確實施埋點的優先級,因為開發部門不可能一次性完成大量事件的埋點。比如電商業務中,我們應該優先實施購買流程這個關鍵事件,與此沖突的其他事件都應該往后排序。
而且在實際業務中,我們往往需要考慮技術實現成本。如果技術實現成本不一致,我們應該優先落實能夠最快落地的,以確保技術的準確性,比如有的埋點需要跨越多個接口;而如果技術實現成本相同則應該優先實施業務數據價值更高的。
(2)埋點規范制定
舉個例子:某工程師給雙十一活動頁面命名時,采用的是拼音與英文相結合的方式,而這種不規范的埋點會讓實施人員產生混淆,最終出現錯誤埋點。埋點規范的價值就在于幫助我們快速理解業務需求,并高效落地埋點方案。
在埋點規范制定過程中,我們通常需要遵循以下三點原則:
-
上報內容格式清晰、簡單,目標易于統計和使用;
-
各端各推薦位置上報的請求曝光內容、可見曝光內容、點擊內容、自動播放格式統一;
-
所有推薦的內容類型編號,業務需要進行統一編排和維表維護,從請求曝光——>可見曝光——>點擊——>落地頁這四個階段均需要保持一致。
(3)埋點實施
埋點規范是埋點實施的前置約束,在埋點實施時,我們需要嚴格按照埋點規范實施埋點,其中,需要注意三個要點。
-
明確事件上報的條件:比如請求曝光時,我們在埋點規范中明確注明請求成功后立即上報還是在曝光頁面停留超過一定時長后再上報等問題。
-
明確字段參數的數據源:通常埋點同學對數據敏感度差,為了防止數據取錯,就要求我們與埋點同學一起明確每個參數的正確取數位置。
-
數據采集流程:數據上報后,為方便數據倉庫同學高效、便捷地處理日志,我們需要明確每種數據的格式,因為非標準的格式會耗費大量的時間和精力處理格式。
(4)數據上報
埋點完備且上報的數據經過數據倉庫處理后就可以直接被應用了。
(5)數據統計
數據統計是非常重要、非常基礎的數據應用,例如推薦系統的轉化率指標( CTR),它是通過點擊數/可見曝光數來計算的。在這個公式中,我們發現如果沒有點擊事件和可見曝光事件的數據埋點,就不可能產生 CTR 這個數據,推薦系統的效果也就很難量化評估。
(6)埋點驗收
在埋點驗收階段,我們需要驗收所有推薦位 置、每個位置下的所有參數、每個參數的數據格式。除此之外,我們還需要將不同數據進行連接,把不同系統的數據以報表的形式展現,并對數據的有效性和準確性進行驗證。
最后,我們總結一下數據采集的整個流程:首先,我們需要對收集哪些數據進行需求梳理,并建立埋點規范;其次,依據埋點規范實施數據埋點;然后,接收實際上報的數據,并落入數據倉庫;緊接著,在數據倉庫中生成滿足業務需求的數據表;最后,對數據埋點進行驗收。
本節總結
學到這里,你已經了解了流量分發的四個階段和數據采集階段的完整流程啦,棒棒噠~
《道德經》中說“重為輕根,靜為躁君。是以圣人終日行不離輜重。”在流量分發體系中,數據就是這個系統的輜重,而數據驅動思維方式是每個推薦算法工程師必備的思維方式。
根據這種思維方式,我們可以快速獲取產品改進的分析流程:首先,確定個人分析目標,從數據規模、數據分布等角度介入發現問題;其次,確定需要分析的數據,將數據細化到數據分析指標,預估數據的有效閾值;然后,尋找并獲取評估數據的渠道,得到自己想要的原始數據;接著,對數據進行合理加工和分析,得出分析結論;最后,對得到的結果進行合理分析,指導推薦迭代。
這里插播一道思考題:你還知道哪些流量分發手段呢?歡迎你在留言區進行互動、交流,分享你的個人看法。
另外,如果你覺得本專欄有價值,歡迎分享給更多好友~

)

)










,可能會遇到表被鎖定的問題。)





