文章目錄
- Concepts
- Embedding
- Encoder
- Decoder
- Self-Attention matric calculation
- Final Linear and Softmax Layer
- Loss function
- 參考
學一下已經問鼎中原七年之久的Transformer
Concepts
開始拆積木!

Embedding
Encoder
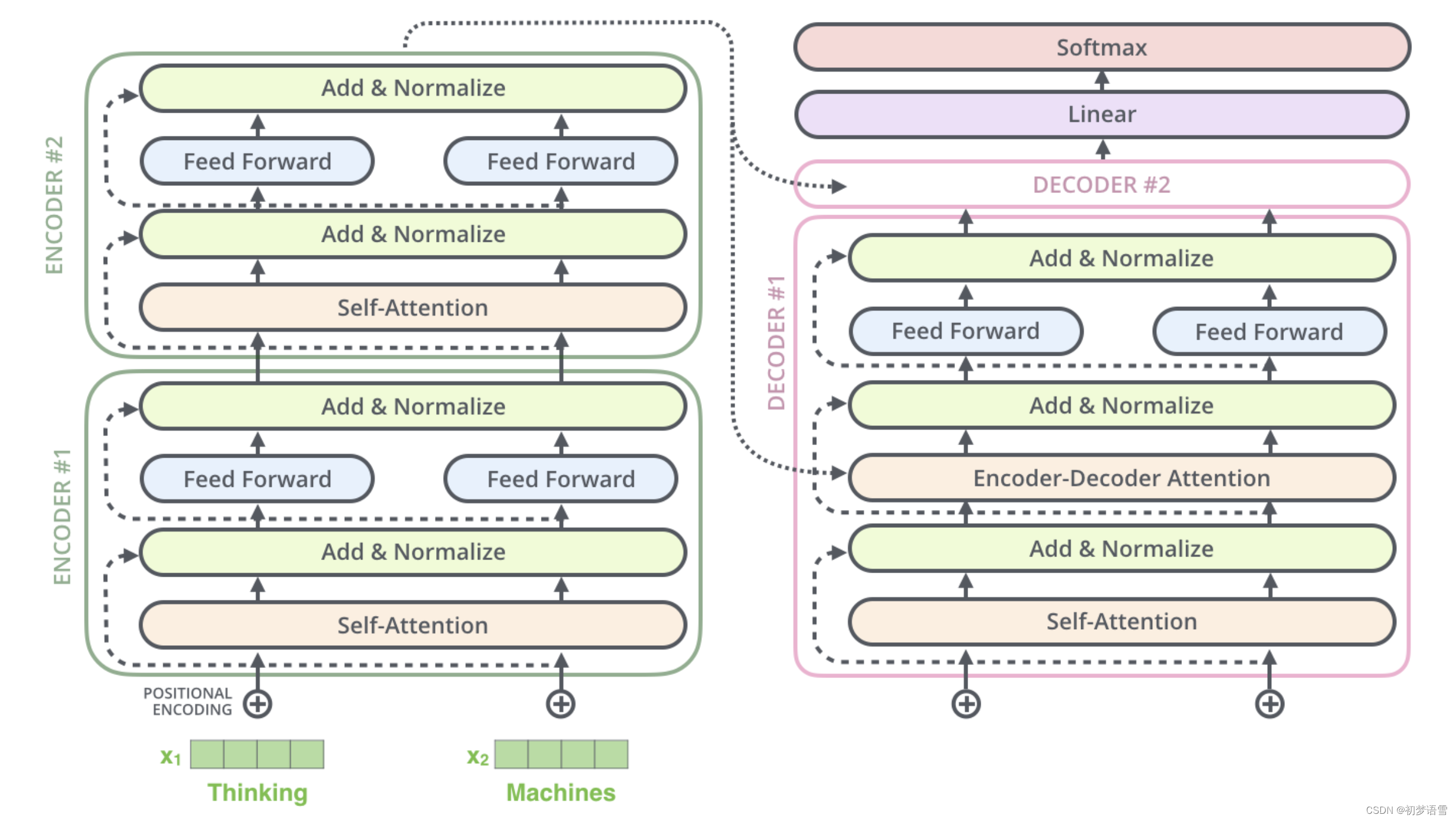
Decoder
Self-Attention matric calculation

Final Linear and Softmax Layer
這一塊輸出的非常非常長的vector叫做logits vector,又是一個不好翻譯的專有詞匯。
在圖像分類的領域里,這里的Linear+Softmax就是Classifier;
Loss function

不管是連續的還是離散的,反正下面這一堆概率就是probability distribution(我之前一直以為是像高中那樣的高斯曲線圖才叫這個distribution),其實分布也不一定非要符合什么規律,毫無規律也可以;

參考
The Illustrated Transformer
Transformer通俗筆記:從Word2Vec、Seq2Seq逐步理解到GPT、BERT
The Annotated Transformer 非常完整的一份代碼



















