DCGAN生成漫畫頭像
通過示例代碼說明DCGAN網絡如何設置網絡、優化器、如何計算損失函數以及如何初始化模型權重。
GAN基礎原理
生成式對抗網絡(Generative Adversarial Networks,GAN)是一種生成式機器學習模型,是近年來復雜分布上無監督學習最具前景的方法之一。
最初,GAN由Ian J. Goodfellow于2014年發明,并在論文Generative Adversarial Nets中首次進行了描述,其主要由兩個不同的模型共同組成——生成器(Generative Model)和判別器(Discriminative Model):
-
生成器的任務是生成看起來像訓練圖像的“假”圖像;
-
判別器需要判斷從生成器輸出的圖像是真實的訓練圖像還是虛假的圖像。
GAN通過設計生成模型和判別模型這兩個模塊,使其互相博弈學習產生了相當好的輸出。
DCGAN原理
DCGAN(深度卷積對抗生成網絡,Deep Convolutional Generative Adversarial Networks)是GAN的直接擴展。不同之處在于,DCGAN會分別在判別器和生成器中使用卷積和轉置卷積層。
它最早由Radford等人在論文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中進行描述。判別器由分層的卷積層、BatchNorm層和LeakyReLU激活層組成。輸入是3x64x64的圖像,輸出是該圖像為真圖像的概率。生成器則是由轉置卷積層、BatchNorm層和ReLU激活層組成。輸入是標準正態分布中提取出的隱向量𝑧𝑧,輸出是3x64x64的RGB圖像。
數據準備與處理
from download import downloadurl = "https://download.mindspore.cn/dataset/Faces/faces.zip"path = download(url, "./faces", kind="zip", replace=True)構造網絡
當處理完數據后,就可以來進行網絡的搭建了。按照DCGAN論文中的描述,所有模型權重均應從mean為0,sigma為0.02的正態分布中隨機初始化。
生成器
生成器G的功能是將隱向量z映射到數據空間。由于數據是圖像,這一過程也會創建與真實圖像大小相同的 RGB 圖像。在實踐場景中,該功能是通過一系列Conv2dTranspose轉置卷積層來完成的,每個層都與BatchNorm2d層和ReLu激活層配對,輸出數據會經過tanh函數,使其返回[-1,1]的數據范圍內。
DCGAN論文生成圖像如下所示:
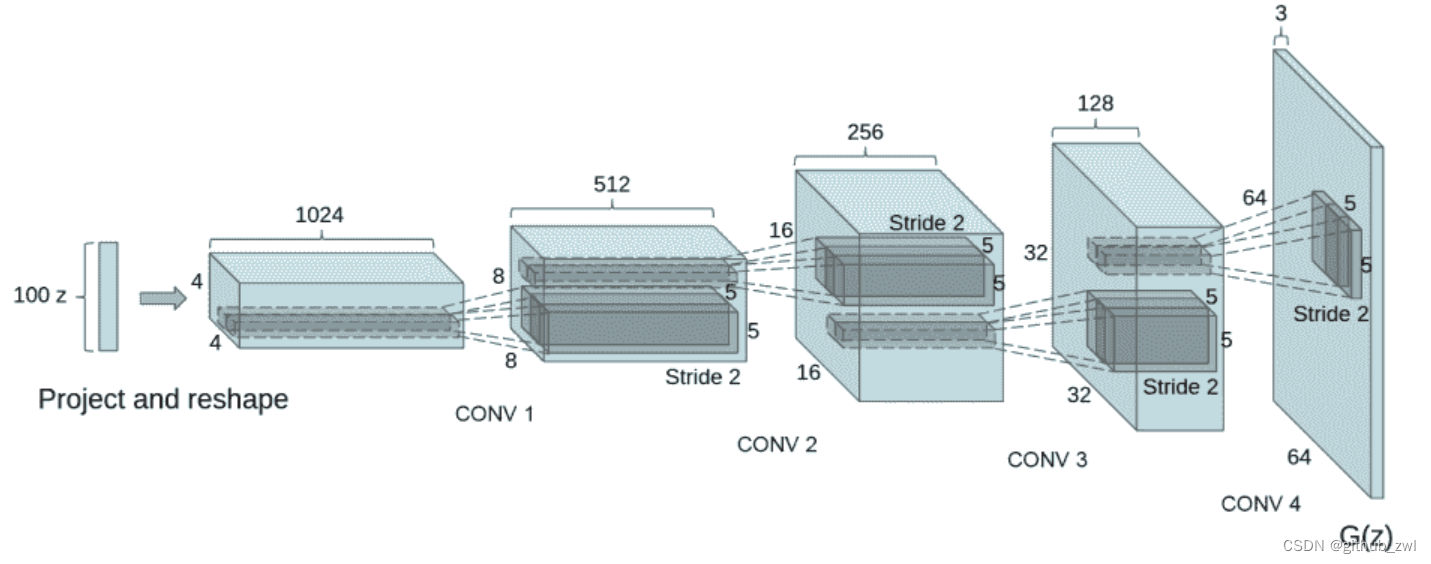
我們通過輸入部分中設置的nz、ngf和nc來影響代碼中的生成器結構。nz是隱向量z的長度,ngf與通過生成器傳播的特征圖的大小有關,nc是輸出圖像中的通道數。
判別器
如前所述,判別器D是一個二分類網絡模型,輸出判定該圖像為真實圖的概率。通過一系列的Conv2d、BatchNorm2d和LeakyReLU層對其進行處理,最后通過Sigmoid激活函數得到最終概率。
DCGAN論文提到,使用卷積而不是通過池化來進行下采樣是一個好方法,因為它可以讓網絡學習自己的池化特征。
模型訓練
損失函數
當定義了D和G后,接下來將使用MindSpore中定義的二進制交叉熵損失函數BCELoss。
優化器
這里設置了兩個單獨的優化器,一個用于D,另一個用于G。這兩個都是lr = 0.0002和beta1 = 0.5的Adam優化器。
訓練模型
訓練分為兩個主要部分:訓練判別器和訓練生成器。
-
訓練判別器
訓練判別器的目的是最大程度地提高判別圖像真偽的概率。按照Goodfellow的方法,是希望通過提高其隨機梯度來更新判別器,所以我們要最大化𝑙𝑜𝑔𝐷(𝑥)+𝑙𝑜𝑔(1?𝐷(𝐺(𝑧))𝑙𝑜𝑔𝐷(𝑥)+𝑙𝑜𝑔(1?𝐷(𝐺(𝑧))的值。
-
訓練生成器
如DCGAN論文所述,我們希望通過最小化𝑙𝑜𝑔(1?𝐷(𝐺(𝑧)))𝑙𝑜𝑔(1?𝐷(𝐺(𝑧)))來訓練生成器,以產生更好的虛假圖像。
在這兩個部分中,分別獲取訓練過程中的損失,并在每個周期結束時進行統計,將fixed_noise批量推送到生成器中,以直觀地跟蹤G的訓練進度。








)










