目錄
案例背景
具體問題
1. 環境準備
小李的理解
知識點
2. 數據準備
2.1 導入必要的庫和數據集
小李的理解
知識點
2.2 數據集基本信息
小李的理解
知識點
注意事項
3. 數據預處理
3.1 劃分訓練集和測試集
小李的理解
知識點
注意事項
3.2 數據標準化
小李的理解
知識點
注意事項
4. 模型訓練
4.1 初始化和訓練邏輯回歸模型
運行結果
?編輯
小李的理解
知識點
注意事項
5. 模型評估
5.1 預測結果
小李的理解
知識點
注意事項
5.2 計算準確率
小李的理解
知識點
注意事項
5.3 混淆矩陣
小李的理解
知識點
注意事項
5.4 分類報告
小李的理解
知識點
注意事項
6. 結果可視化
6.1 繪制混淆矩陣
小李的理解
知識點
注意事項
完整代碼
結論


專欄:機器學習筆記
pycharm專業版免費激活教程見資源,私信我給你發
python相關庫的安裝:pandas,numpy,matplotlib,statsmodels
總篇:學習路線
第一卷:線性回歸模型
邏輯回歸(Logistic Regression)是一種適用于二分類問題的機器學習方法。本文將圍繞一個具體的乳腺癌檢測案例,詳細講解如何在PyCharm中使用邏輯回歸模型進行預測。我們將從數據準備、數據預處理、模型訓練、模型評估和結果可視化幾個方面進行詳細說明,并通過完整的代碼示例展示每個步驟。
案例背景
在本案例中,我們將使用經典的乳腺癌數據集(Breast Cancer Dataset)進行乳腺癌檢測預測。該數據集包含569個樣本,每個樣本有30個特征,并標記為良性(0)或惡性(1)。我們的目標是使用這些特征訓練一個邏輯回歸模型,預測新的樣本是良性還是惡性。
具體問題
我們需要解決以下幾個具體問題:
- 如何加載并理解乳腺癌數據集。
- 如何對數據進行預處理以適合邏輯回歸模型的訓練。
- 如何訓練邏輯回歸模型并進行預測。
- 如何評估模型的性能。
- 如何對結果進行可視化以便于解釋。
1. 環境準備
首先,確保你的開發環境中已經安裝了必要的Python庫:
pip install numpy pandas scikit-learn matplotlib seaborn
小李的理解
安裝庫是機器學習的基礎步驟。我們需要安裝一些流行的Python庫,如numpy、pandas、scikit-learn、matplotlib和seaborn,這些庫分別用于數值計算、數據處理、機器學習模型、繪圖和數據可視化。
知識點
- 庫的安裝:使用
pip install命令安裝所需的Python庫。- 常用庫:了解并熟悉常用的機器學習和數據處理庫。
2. 數據準備
2.1 導入必要的庫和數據集
我們使用scikit-learn庫中的乳腺癌數據集。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer# 加載數據集
data = load_breast_cancer()
X = data.data
y = data.target
小李的理解
scikit-learn提供了很多常用的數據集,load_breast_cancer()是用來加載乳腺癌數據集的方法。X是特征數據,y是目標標簽(0表示良性,1表示惡性)。
知識點
- 數據集加載:使用
scikit-learn中的方法加載內置數據集。- 特征與標簽:特征數據用于模型訓練,目標標簽用于分類。
2.2 數據集基本信息
將數據轉換為Pandas DataFrame格式以便查看和處理,并打印數據集的前幾行進行初步了解。
# 將數據轉換為DataFrame格式
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y# 查看數據集的基本信息
print("數據集前五行:\n", df.head())
print("\n數據集描述統計信息:\n", df.describe())
print("\n數據集信息:")
df.info()
運行結果?

小李的理解
我們使用pandas庫將數據轉換為DataFrame格式,這樣可以方便地查看和處理數據。使用head()查看數據的前幾行,使用describe()查看數據的描述統計信息,使用info()查看數據的基本信息,包括每列的數據類型和非空值數量。
知識點
- DataFrame:
pandas的核心數據結構,類似于電子表格,可以方便地操作和分析數據。- 數據描述:通過
head()、describe()和info()方法快速了解數據的基本情況。
注意事項
- 數據完整性:在加載數據時,確保數據沒有缺失值。本數據集沒有缺失值。
- 數據類型:特征值都是浮點型,而目標值是整數型。邏輯回歸適用于這些數據類型。
3. 數據預處理
3.1 劃分訓練集和測試集
將數據集劃分為訓練集和測試集,以便后續模型的訓練和評估。
from sklearn.model_selection import train_test_split# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 打印訓練集和測試集的大小
print(f'訓練集樣本數: {X_train.shape[0]}')
print(f'測試集樣本數: {X_test.shape[0]}')
?運行結果
小李的理解
我們將數據集分為訓練集和測試集,訓練集用于訓練模型,測試集用于評估模型的性能。train_test_split函數將數據按70%訓練集和30%測試集的比例進行劃分,并使用random_state=42保證每次運行結果一致。
知識點
- 數據劃分:使用
train_test_split函數將數據集分為訓練集和測試集。- 隨機種子:
random_state參數保證結果的可重復性。
注意事項
- 隨機種子:
random_state=42保證每次運行結果一致,方便調試和復現。- 測試集比例:通常使用70%的數據進行訓練,30%的數據進行測試,但具體比例可以根據實際情況調整。
3.2 數據標準化
由于不同特征的取值范圍不同,需要對數據進行標準化處理,使每個特征的取值范圍相同。
from sklearn.preprocessing import StandardScaler# 數據標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 打印標準化后的部分數據
print(f'標準化后的訓練數據前五行:\n {X_train[:5]}')
?運行結果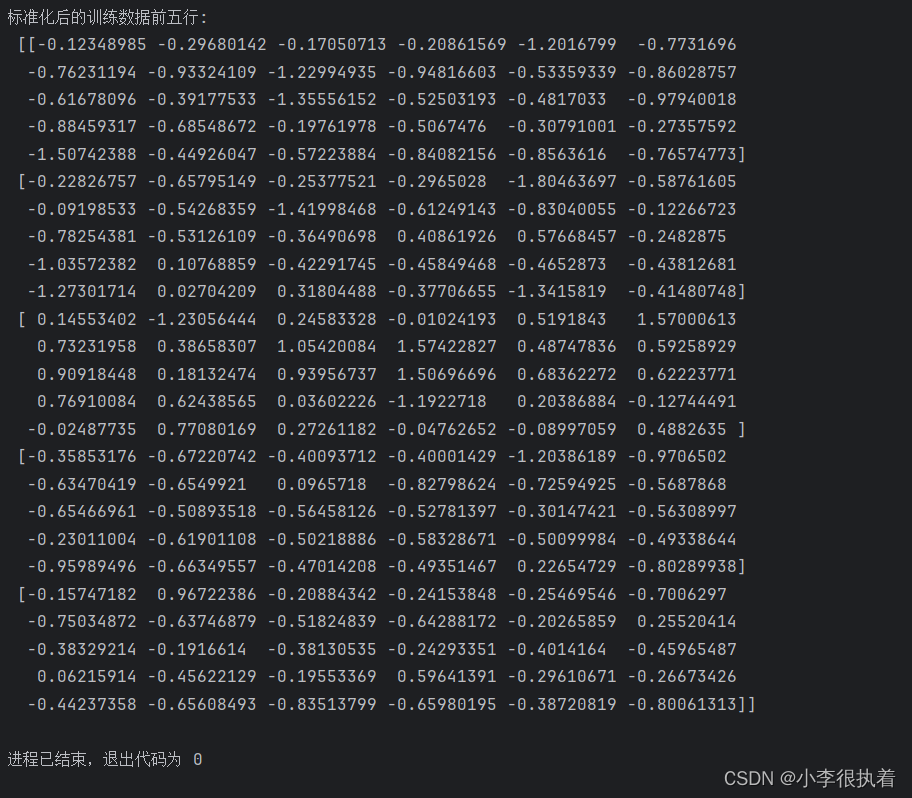
小李的理解
標準化是將每個特征縮放到均值為0、標準差為1的范圍內,這樣可以消除不同特征之間的量綱差異,使模型訓練更加穩定。我們使用StandardScaler進行標準化,只對訓練數據擬合,然后對訓練和測試數據進行轉換。
知識點
- 標準化:使用
StandardScaler將數據標準化,以消除特征之間的量綱差異。- 數據泄漏:在標準化時,只對訓練數據進行擬合,然后對訓練和測試數據進行轉換。
注意事項
- 標準化方法:我們使用
StandardScaler將每個特征縮放到均值為0、標準差為1的范圍內。- 數據泄漏:在標準化時,我們僅對訓練數據擬合(fit),然后對訓練和測試數據進行轉換(transform),以避免數據泄漏。
4. 模型訓練
4.1 初始化和訓練邏輯回歸模型
使用scikit-learn庫中的邏輯回歸模型對訓練數據進行擬合。
from sklearn.linear_model import LogisticRegression# 初始化邏輯回歸模型
model = LogisticRegression(max_iter=10000)# 訓練模型
model.fit(X_train, y_train)# 打印模型的訓練結果
print("邏輯回歸模型訓練完成")
運行結果

小李的理解
我們使用LogisticRegression類來初始化邏輯回歸模型,并設置最大迭代次數為10000,以確保模型能夠收斂。然后,我們使用訓練數據擬合模型。
知識點
- 邏輯回歸模型:
LogisticRegression類用于初始化邏輯回歸模型。- 最大迭代次數:
max_iter參數用于設置模型的最大迭代次數,以確保模型能夠收斂。
注意事項
- 最大迭代次數:
max_iter=10000確保模型能夠收斂,即使數據集較大或特征較多。- 默認參數:初學者可以先使用默認參數,之后可以嘗試調整參數以優化模型性能。
5. 模型評估
5.1 預測結果
使用訓練好的模型對測試集進行預測。
# 預測
y_pred = model.predict(X_test)# 打印預測結果的前十個
print(f'預測結果前十個: {y_pred[:10]}')
?運行結果

小李的理解
我們使用predict方法對測試數據進行預測,得到每個樣本的預測標簽。然后,我們打印預測結果的前十個樣本。
知識點
- 模型預測:使用
predict方法對測試數據進行預測。- 預測標簽:
predict方法返回每個樣本的預測標簽。
注意事項
- 預測輸出:
predict方法輸出每個樣本的預測標簽。- 預測概率:可以使用
predict_proba方法獲取每個樣本屬于每個類別的概率。
5.2 計算準確率
計算模型在測試集上的準確率。
from sklearn.metrics import accuracy_score# 計算準確率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
?運行結果
小李的理解
準確率是模型正確預測的樣本數占總樣本數的比例,是評估模型性能的一個重要指標。
知識點
- 準確率:使用
accuracy_score函數計算模型的準確率。- 模型評估:準確率是評估模型性能的一個重要指標。
注意事項
- 準確率定義:準確率是正確預測的樣本數占總樣本數的比例。
- 適用場景:對于類別不平衡的問題,僅使用準確率可能會導致誤導,應結合其他指標。
5.3 混淆矩陣
生成并打印混淆矩陣,混淆矩陣可以直觀地顯示模型的分類性能。
from sklearn.metrics import confusion_matrix# 混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
?運行結果

小李的理解
混淆矩陣是一個矩陣,用來評價分類模型的性能。矩陣的每一行表示實際類別,每一列表示預測類別。
知識點
- 混淆矩陣:使用
confusion_matrix函數生成混淆矩陣。- 矩陣解讀:混淆矩陣的每一行表示實際類別,每一列表示預測類別。
注意事項
- 混淆矩陣解讀:
- 左上(TP):正確預測為正類的數量
- 右上(FP):錯誤預測為正類的數量
- 左下(FN):錯誤預測為負類的數量
- 右下(TN):正確預測為負類的數量
- 評估模型:通過混淆矩陣可以計算精確度、召回率等指標。
5.4 分類報告
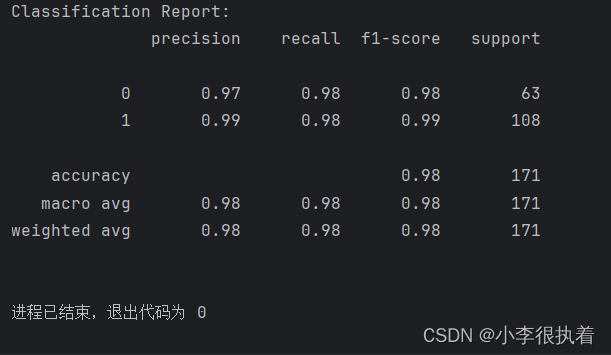
生成并打印分類報告,報告包括精確度、召回率和F1分數等指標。
from sklearn.metrics import classification_report# 分類報告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)
?運行結果
小李的理解
分類報告提供了每個類別的精確度、召回率和F1分數,以及整體的宏平均(macro avg)和加權平均(weighted avg)指標。這些指標可以幫助我們更全面地評估模型的性能。
知識點
- 分類報告:使用
classification_report函數生成分類報告。- 評估指標:分類報告包括精確度、召回率和F1分數等指標。
注意事項
- 精確度(Precision):預測為正類的樣本中實際為正類的比例。
- 召回率(Recall):實際為正類的樣本中被正確預測為正類的比例。
- F1分數(F1-score):精確度和召回率的調和平均數,綜合考慮模型的準確性和召回能力。
6. 結果可視化
6.1 繪制混淆矩陣
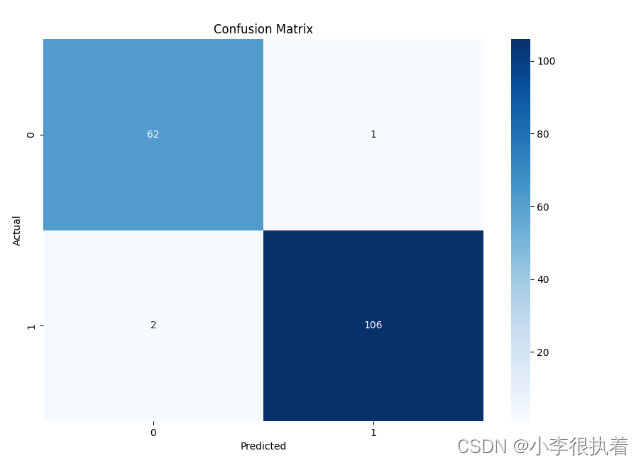
使用Seaborn庫對混淆矩陣進行可視化。
import matplotlib.pyplot as plt
import seaborn as sns# 繪制混淆矩陣
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
?可視化結果
小李的理解
通過繪制混淆矩陣,我們可以直觀地看到模型的分類效果。seaborn庫提供了簡潔的繪圖方法,使得可視化更加美觀和易于理解。
知識點
- 數據可視化:使用
seaborn庫進行數據可視化。- 混淆矩陣圖:通過繪制混淆矩陣圖,可以直觀地展示模型的分類效果。
注意事項
- 圖像解釋:混淆矩陣圖表提供了直觀的分類性能展示。
- 顏色選擇:可以根據需要調整顏色映射,以便于區分不同類別。
完整代碼
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns# 1. 加載數據集
data = load_breast_cancer()
X = data.data
y = data.target# 2. 數據準備
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y# 查看數據集的基本信息
print("數據集前五行:\n", df.head())
print("\n數據集描述統計信息:\n", df.describe())
print("\n數據集信息:")
df.info()# 3. 數據預處理
# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 打印訓練集和測試集的大小
print(f'訓練集樣本數: {X_train.shape[0]}')
print(f'測試集樣本數: {X_test.shape[0]}')# 數據標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 打印標準化后的部分數據
print(f'標準化后的訓練數據前五行:\n {X_train[:5]}')# 4. 模型訓練
# 初始化邏輯回歸模型
model = LogisticRegression(max_iter=10000)# 訓練模型
model.fit(X_train, y_train)# 打印模型的訓練結果
print("邏輯回歸模型訓練完成")# 5. 模型評估
# 預測
y_pred = model.predict(X_test)# 打印預測結果的前十個
print(f'預測結果前十個: {y_pred[:10]}')# 計算準確率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')# 混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)# 分類報告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)# 6. 結果可視化
# 繪制混淆矩陣
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
?
結論
通過本文的講解,在PyCharm中使用邏輯回歸模型進行乳腺癌檢測的預測。從數據準備、數據預處理、模型訓練到結果評估與可視化,提供了詳細的步驟和代碼示例。通過這些步驟,你可以掌握如何應用邏輯回歸模型進行疾病預測,并根據模型的評估結果優化和改進模型。?







:HyperLogLog)




)




)

