文末有福利!
自《中共中央國務院關于構建數據基礎制度更好發揮數據要素作用的意見》發布以來,我國數據要素建設不斷深入,在國家數據局等 17 部門聯合印發的《“數據要素 ×” 三年行動計劃(2024 - 2026 年)》進一步明確 “建設高質量語料庫和基礎科學數據集,支持開展人工智能大模型開發和訓練”。
通過數據要素建設推動人工智能大模型發展,可以有效解決我國人工智能,特別是大模型研發所面臨的數據瓶頸,進一步發揮大模型對于世界知識數據的匯集和處理能力,創造更大的生產力,助力我國從數據經濟走向智能經濟新發展模式。
大模型是數據要素價值釋放的最短路徑,通過理解其訓練所使用的數據類型,可以更好理解大模型發揮價值的內在機制,破解對訓練數據常見的迷思和誤解。
01 訓練數據對大模型發展的重要性
業界認為,算法、算力與數據,是支撐大模型發展的三大基石。
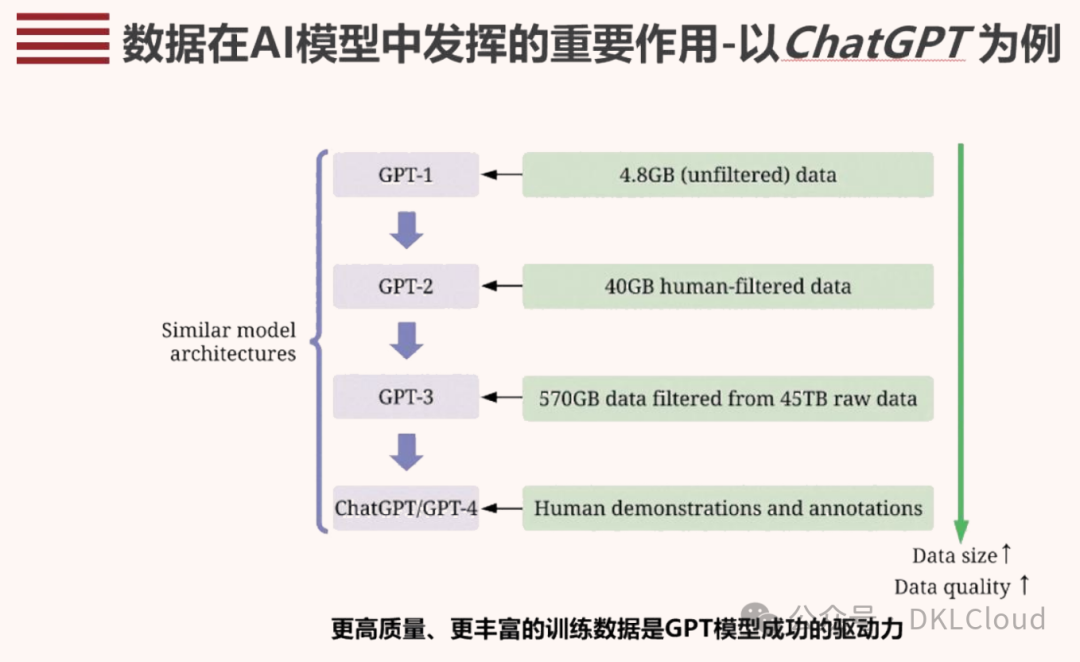
更高質量、更豐富的數據是以 GPT 為例的生成式人工智能大模型成功的驅動力。GPT 模型架構從第 1 代到第 4 代均較為相似,而用來訓練數據的數據規模和質量卻有很大的不同。
GPT-1 是由 4.8G 未過濾原始數據訓練,GPT-2 是由經人類過濾后的 40G 數據訓練,GPT-3是由從 45T 原始數據中過濾的 570G 數據訓練,而 chatGPT/GPT-4 則是在該基礎上又加入了高質量人類標注。
以吳恩達(Andrew Ng)為代表的學者觀點認為,人工智能是以數據為中心的,而不是以模型為中心。“有標注的高質量數據才能釋放人工智能的價值,如果業界將更多精力放在數據質量上,人工智能的發展會更快”。
02 模型訓練所需的數據類型
數據作為大模型訓練的基礎,它提供了大模型所必需的知識和信息。區別于以往搜索系統、個性化推薦等所需的大量用戶行為和偏好數據,隨著技術的演進,大模型所需的數據是對知識性內容有強需求,是一種新的類型。
2.1 訓練大語言模型的數據
大模型所需要的數據根據訓練的階段有所不同。以 ChatGPT 為代表的大語言模型(LLM)為例,其訓練過程分為預訓練(Pre-training)、監督微調(SFT)、基于人類反饋的強化學習(RLHF)三個階段,后兩部分又統稱為“對齊”(Alignment)階段。

3.2 高質量數據的標準
3.2.1 高質量數據類型的三重不確定性
第一重不確定性來自于所需的語料種類,其類型是由人類對模型能力需求決定的,而能力需求又是根據需要模型所完成的任務而不斷演變。
回溯基礎大模型的發展歷程,在 2020 年左右,基于 Transformer 架構的 Google Meena,其目的是讓模型具有生成連貫且有意義內容的對話能力,因此對話文本被視為最重要的高質量數據。而隨著技術路線的演進,人們發現更通用的上下文理解是重點,因此書籍和科研論文等又被視為高質量數據。
通過提升其在訓練語料中的占比,可以增強模型從文本中捕捉長距離依賴的能力。隨著人們對通用人工智能的向往,對提升通用性能的北極星指標 - 推理能力有幫助的語料,又更加被重視。
一種是代碼數據,因為里面涉及大量If-Then-Else 等條件控制信息;另一種是教材,因為涉及了比較詳細的數學推理過程,和邏輯鏈高度相關。如果再拓展到行業模型,根據對模型能力的不同需求,語料類型更難以一一列舉。
比如,經人類標注的,由視覺相似性圖片構成的匹配對數據庫,可以作為高質量數據用于大模型在廣告領域的訓練,通過更好預測用戶需求實現對素材點擊率的優化。而通過收集人類駕駛員對稀有事件(比如駕駛過程中遇到的復雜路況、極端天氣、異常行為的人或車輛等場景)的應對數據,則可以更好訓練完全自動駕駛(FSD)模型在不同場景中的處理能力。
由此看出,由于生成式 AI 在技術演進和應用場景拓展中具有不確定性,模型對所需要語料類型也在發生變化,“高質量語料” 的類型和范圍也在不斷拓展。
04 合成數據作為解決訓練數據供給不足的新方案
4.1訓練數據供給不足帶來的思考
在生成式人工智能技術不斷發展的趨勢下,訓練數據來源是人們最關心的問題之一。上節以政府和社會力量的視角展開。
本節以已經使用的數據源和正在探索的新數據源視角展開。在已經使用的訓練語料中,有用于語言大模型訓練的文本數據,包括網頁信息、書籍、科研論文、知識百科、專業問答、代碼以及領域知識,也有用于多模態模型的圖片、視頻、音頻等媒體數據。
根據 Epoch AI 的估算,書籍、科研論文等高質量語言數據集可能會在2024 年前耗盡。人們正在積極探索新數據源,以緩解訓練語料可能面臨不足的問題。一種思路是將未數字化的知識數字化,如在最新發布的 Claude 3 中,提到了將大量未數字化的書籍和資料做數字化處理,成為模型可讀取的訓練語料。
還可利用機器感知數據,比如將無人車、無人機、其他智能硬件設備等生成的大量物理世界數據用于訓練。另一種思路是利用模型或算法,批量生成新數據,比如合成數據,然后利用它們訓練模型。近期,合成數據在大模型訓練和應用的話題引起了廣泛關注。
一方面,高質量的合成數據可以作為真實數據的補充和替代,模擬現實世界的復雜性和多樣性,被視為擴展模型學習范圍與能力的重要手段。
另一方面,合成數據的生成過程可能存在偏差或噪聲,導致其質量和真實性無法完全模擬客觀世界。
由此引出一系列值得深入討論的問題:對于合成數據的價值,它能否拓展大模型能力的邊界?又是否能替代真實數據,緩解優質數據供給不足的問題?
此外,合成數據能否通過對現有數據的深加工,將之前不能被用于訓練的數據轉化為可用,提升模型對數據利用的可能性?而對于合成數據的風險,人們也會擔憂是否會出現 “大模型自己產生數據進行自我訓練” 的循環,導致初始偏差被不斷放大,最終使模型失控?這種新數據源還會帶來哪些新風險?
4.2 合成數據的定義
合成數據是通過算法和數學模型創建的。首先建模真實數據的分布,然后在該分布上進行采樣,創建出新數據
集,模擬真實數據中的統計模式和關系。合成數據類似于數據的 “替身演員”,發揮補充或替代真實數據的作用。
在機器學習和人工智能領域,合成數據可以為模型提供訓練材料,幫助它們學習、理解和預測。需要注意的是,如果生成過程設計不當,合成數據也可能缺乏保真度,對客觀世界的模擬出現偏差。
4.3 合成數據的必要性
什么情況下會用到合成數據?本質原因是真實世界中獲取數據遇到困難。
一是真實世界中難以觀測,如罕見病或極端天氣等。利用合成數據可以設計比真實數據集更廣泛的情況,對 Corner Case 進行模擬,提升訓練數據集的全面性和多樣性,確保在處理邊緣案例時也有良好性能,提升模型泛化能力。
二是真實世界中數據獲取的成本高,如大模型對齊訓練中需要人類大量的高質量反饋。利用合成數據可以實現對齊流程自動化,幾乎不需人類標注,大幅節省成本,提高獲取效率。
三是數據獲取和處理涉及到真實世界中的個信甚至敏感信息,特別是醫療健康和金融領域。合成數據可以利用差分隱私對個體信息 “加噪聲” 等方法,模擬真實數據集的分布,而不模擬其中的真實個人信息,實現對個信去標識化。由此歸納出,合成數據具有全面性和多樣性、經濟高效、有利于隱私保護等優點。
4.4 合成數據的生成方法及分類
根據是否基于實際數據集生成,合成數據生成方法主要分為兩大類。
第一種是基于真實數據集構建的:人們會建立模型以捕獲真實數據的分布特性和結構特征,刻畫數據中的多變量關系和相互作用。然后從該模型中抽樣或生成合成數據。如果模型能很好地代表真實數據,那么合成數據將具有與真實數據相似的統計特性。以 ChatGPT 為例,它深入研究了人類寫的數十億例文本,分析了詞語之間的關系,并構建了一個模型來理解它們是如何組合在一起的。
在生成文本時,每一個單詞的選擇也都取決于它前一個單詞出現的統計概率。
第二種生成方法并不來源于真實數據,而是通過使用現有模型或者人類專業背景知識來創建。現有的模型可以是某個過程的統計模型,也可以是模擬模型。模擬可以通過游戲引擎等方法創建,如最近火爆的 Sora 文生視頻模型,里面用到了由游戲引擎

(Unity、Unreal Engine 5 等)合成的視頻數據作為訓練集,以提高生成質量。根據用于訓練的 AI 類型,可以將合成數據分為應用于生成式 AI 和判別式 AI 訓練兩類。應用于生成式 AI 訓練的通常有媒體合成數據,即由模型和算法合成的視頻、圖像或聲音。文本合成數據,即在自然語言處理中由模型生成的文本。而判別式 AI 訓練(分類或回歸)所需的通常是表格合成數據,類似真實生活中數據記錄或表格的合成數據。
4.5 合成數據在模型訓練中的作用
基礎大模型訓練所需的數據類型包含兩大類,一是用于預訓練的世界知識,二是用于對齊的數據。合成數據作為真實數據的一種替代,現階段雖然在預訓練占比不高,但未來發展潛力巨大,可作為一個 “新物種” 密切關注;目前合成數據多應用于提升對齊階段的數據獲取效率,增強模型安全和可靠性。
4.5.1 預訓練語料的新物種
模型預訓練階段是通過大量無監督學習構建基礎能力,掌握世界的規律。大語言模型需要各類世界知識,包括網頁、書籍、新聞、代碼等;而多模態又需要視頻、圖片、音頻等語料。那么合成數據作為新物種,能對模型的訓練語料起到哪些補充作用呢?
首先,合成數據可應用于多模態數據的生成。最近火爆的 Sora 文生視頻大模型,里面用到了大量由游戲引擎合成的視頻數據作為訓練集,以提高生成質量。此外,利用模擬器生成的多模態場景數據還廣泛應用于具身智能機器人、自動駕駛、AI for Science 等場景的訓練。
利用模擬模型生成多模態數據可以更好滿足模型對訓練數據差異化的需求,例如通過有效 “過采樣”(隨機復制少數樣例以增大它們的規模)罕見事件或災難性事件,以確保模型能夠針對更廣泛的輸入保持魯棒性。
而伴隨生成式人工智能走向更通用,模型訓練將不僅從文字中學習,也會從聲音、圖片和視頻中學習,就更需要多模態的訓練數據。因此,我們判斷通過合成的多模態數據進行訓練的需求還會持續且大幅增加。
其次,合成數據還可應用于高價值領域知識的生成。核心是合成數據能通過對現有數據的深加工,將之前不能被用于訓練的數據轉化為可用,提升模型對數據利用的可能性。例如工業制造領域,利用合成數據,可以把生產、制造等工藝流程相關的原始數據,結合行業知識圖譜,轉化為可供大模型學習的工業語料,以緩解行業語料短缺的問題。
該過程分為三步:一是將原始數據(Data)轉變為信息(Information):即將非自然語言描述的內容(如工藝生產中的操作行為或時序數據)轉化為大模型可讀的結構化信息(操作記錄)。
二是將信息提煉為知識(Knowledge):僅有操作記錄并不能直接提供有效知識,但將多條結構化信息與行業的知識圖譜、專家經驗相結合,可以產出有價值的行業知識(如在什么溫度下應該如何操作,好處是什么)。
三是將得到的知識泛化:利用大模型的推理能力,將相對單一的知識進行多樣性拓展,積累更豐富的行業語料。由此看出,大模型可以利用原始數據、信息、知識等不同層次的內容,打通數據利用的模式。我們判斷,通過合成數據拓展對數據利用的可能性,生成領域知識的趨勢是 “精”,即對語料質量要求高,且是不可或缺的。

因為大模型只有在預訓練中學習過領域知識,才能在后期利用行業語料進行 SFT 訓練時激發出更好的效果,更容易應用于垂直領域。綜上,我們認為合成數據作為預訓練語料的新物種,發展潛力巨大,特別是在多模態數據和領域知識生成方面值得密切關注。
4.5.2 提升對齊語料獲取效率的加速器
對齊數據以人類高質量反饋為主,包含監督微調階段和基于人類反饋的強化學習。
此方法主要在以下幾方面遇到問題:一是數據獲取的成本更高,二是人類評估的準確性和一致性,三是模型通常選擇避免回答敏感和有爭議的問題,降低模型的整體效用。如果引入合成數據作為真實數據的補充和替代,能否緩解這些問題呢?合成數據最大的優勢是可以大幅提升對齊數據的獲取效率,“如果掌握了合成數據技術,對齊的成本可能會降低好幾個數量級,或用一樣的投入產生更大數量級的數據,競爭格局就會發生變化”。這種對合成數據的應用是

“從人工智能反饋中進行強化學習(RLAIF)”。通常是用一個較大規模模型產出合成數據,生成指令及輸入和輸出樣本,過濾掉無效或重復信息,自動化微調出性能較好的小模型,全過程中幾乎無需人類標注。
這不僅大幅降低了標注成本,也能緩解人工對齊導致模型對敏感問題拒答的情況。例如斯坦福大學發布的 70 億參數對話大模型Alpaca,正是采用此類自我指導(Self-instruct)方法,用 OpenAI 的 API 自動生成指令數據進行微調。還有一種基于 RLAIF 新思路探索,希望在不引入外部模型的前提下實現自動化微調。
例如自我對局(Self-play),在滿足一定條件時,利用合成數據進行自我對抗微調(t+1 代的模型嘗試將 t 代模型的輸出與真人的輸出區分開),得到了比 RLHF 更好的效果。再如 Claude3 用到的憲法式 AI,讓 AI 系統在遵循預先設定的原則下,使用模型自身生成的反饋和修正意見來進行自我改進,得到一個既能生成無害內容,又不規避有害問題的模型。
同時另一種對合成數據的應用是 “從人類和人工智能反饋中進行強化學習(RLHAIF)”,該方法整合了人類和 AI 元素以提供監督。有研究表明,在利用 AI 協助人類評估模型有效性時,模型生成的批評有助于人類發現可能錯過的缺陷,提高人類評估的準確性。
那么,如何系統的去學習大模型LLM?
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
作為一名熱心腸的互聯網老兵,我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。
但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
所有資料 ?? ,朋友們如果有需要全套 《LLM大模型入門+進階學習資源包》,掃碼獲取~

篇幅有限,部分資料如下:
👉LLM大模型學習指南+路線匯總👈
💥大模型入門要點,掃盲必看!

💥既然要系統的學習大模型,那么學習路線是必不可少的,這份路線能幫助你快速梳理知識,形成自己的體系。

👉大模型入門實戰訓練👈
💥光學理論是沒用的,要學會跟著一起做,要動手實操,才能將自己的所學運用到實際當中去,這時候可以搞點實戰案例來學習。

👉國內企業大模型落地應用案例👈
💥《中國大模型落地應用案例集》 收錄了52個優秀的大模型落地應用案例,這些案例覆蓋了金融、醫療、教育、交通、制造等眾多領域,無論是對于大模型技術的研究者,還是對于希望了解大模型技術在實際業務中如何應用的業內人士,都具有很高的參考價值。 (文末領取)

💥《2024大模型行業應用十大典范案例集》 匯集了文化、醫藥、IT、鋼鐵、航空、企業服務等行業在大模型應用領域的典范案例。

👉LLM大模型學習視頻👈
💥觀看零基礎學習書籍和視頻,看書籍和視頻學習是最快捷也是最有效果的方式,跟著視頻中老師的思路,從基礎到深入,還是很容易入門的。 (文末領取)

👉640份大模型行業報告👈
💥包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

👉獲取方式:
這份完整版的大模型 LLM 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】
😝有需要的小伙伴,可以Vx掃描下方二維碼免費領取🆓














:HyperLogLog)




)

