Java 持久層 API:JPA
- 1.Spring Data
- 1.1 主要模塊
- 1.2 社區模塊
- 2.JPA
- 3.使用 JPA
- 3.1 添加 JPA 和 MySQL 數據庫的依賴
- 3.2 配置數據庫連接信息
- 4.了解 JPA 注解和屬性
- 4.1 常用注解
- 4.2 映射關系的注解
- 4.3 映射關系的屬性
- 5.用 JPA 構建實體數據表
1.Spring Data
Spring Data 是 Spring 的一個子項目,旨在統一和簡化各類型數據的持久化存儲方式,而不拘泥于是關系型數據庫還是 NoSQL 數據庫。
無論是哪種持久化存儲方式,數據訪問對象(Data Access Objects,DAO)都會提供對對象的增加、刪除、修改和查詢的方法,以及排序和分頁方法等。
Spring Data 提供了基于這些層面的統一接口(如:CrudRepository、PagingAndSortingRepository),以實現持久化的存儲。
Spring Data 包含多個子模塊,主要分為主模塊和社區模塊。
1.1 主要模塊
| | |
|---|---|
| Spring Data Commons | 提供共享的基礎框架,適合各個子項目使用,支持跨數據庫持久化。 |
| Spring Data JDBC | 提供了對 JDBC 的支持,其中封裝了 JDBCTemplate。 |
| Spring Data JDBC Ext | 提供了對 JDBC 的支持,并擴展了標準的 JDBC,支持 Oracle RAD、高級隊列和高級數據類型。 |
| Spring Data JPA | 簡化創建 JPA 數據訪問層和跨存儲的持久層功能。 |
| Spring Data KeyValue | 集成了 Redis 和 Riak,提供多個常用場景下的簡單封裝,便于構建 key-value 模塊。 |
| Spring Data LDAP | 集成了 Spring Data repository 對 Spring LDAP 的支持。 |
| Spring Data MongoDB | 集成了對數據庫 MongoDB 支持。 |
| Spring Data Redis | 集成了對 Redis 的支持。 |
| Spring Data REST | 集成了對 RESTful 資源的支持。 |
| Spring Data for Apache Cassandra | 集成了對大規模、高可用數據源 Apache Cassandra 的支持。 |
| Spring Data for Apace Geode | 集成了對 Apache Geode 的支持。 |
| Spring Data for Apache Solr | 集成了對 Apache Solr 的支持。 |
| Spring Data for Pivotal GemFire | 集成了對 Pivotal GemFire 的支持。 |
1.2 社區模塊
| | |
|---|---|
| Spring Data Aerospike | 集成了對 Aerospike 的支持 |
| Spring Data ArangoDB | 集成了對 ArangoDB 的支持。 |
| Spring Data Couchbase | 集成了對 Couchbase 的支持。 |
| Spring Data Azure Cosmos DB | 集成了對 Azure Cosmos 的支持。 |
| Spring Data Cloud Datastore | 集成了對 Google Datastore 的支持 |
| Spring Data Cloud Spanner | 集成了對 Google Spanner 的支持。 |
| Spring Data DynamoDB | 集成了對 DynamoDB 的支持。 |
| Spring Data Elasticsearch | 集成了對搜索引擎框架 Elasticsearch 的支持。 |
| Spring Data Hazelcast | 集成了對 Hazelcast 的支持。 |
| Spring Data Jest | 集成了對基于 Jest REST client 的 Elasticsearch 的支持。 |
| Spring Data Neo4j | 集成了對 Neo4j 數據庫的支持。 |
| Spring Data Vault | 集成了對 Vault 的支持。 |
2.JPA
JPA(Java Persistence APl)是 Java 的持久化 API,用于對象的持久化。它是一個非常強大的 ORM 持久化的解決方案,免去了使用 JDBCTemplate 開發的編寫腳本工作。JPA 通過簡單約定好接口方法的規則自動生成相應的 JPQL 語句,然后映射成 POJO 對象。
JPA 是一個規范化接口,封裝了 Hibernate 的操作作為默認實現,讓用戶不通過任何配置即可完成數據庫的操作。JPA、Spring Data 和 Hibernate 的關系如下圖所示。

Hibernate 主要通過 hibernate-annotation、hibernate-entitymanager 和 hibernate-core 三個組件來操作數據。
hibernate-annotation:是 Hibernate 支持 annotation 方式配置的基礎,它包括標準的 JPAannotation、Hibernate 自身特殊功能的 annotation。hibernate-core:是 Hibernate 的核心實現,提供了 Hibernate 所有的核心功能。hibernate-entitymanager:實現了標準的 JPA,它是 hibernate-core 和 JPA 之間的適配器,它不直接提供 ORM 的功能,而是對 hibernate-core 進行封裝,使得 Hibernate 符合 JPA 的規范。
如果要 JPA 創建《Java 的數據庫連接模板:JDBCTemplate》中 “2.2 新建實體類” 里的實體,可使用以下代碼來實現。
@Data
@Entity
public class User {private int id;@Id// id 的自增由數據庫自動管理@GeneratedValue(strategy = GenerationType.IDENTITY)private String username;private String password;
}
對比 JPA 與 JDBCTemplate 創建實體的方式可以看出:JPA 的實現方式簡單明了,不需要寫映射(支持自定義映射),只需要設置好屬性即可。id 的自增由數據庫自動管理,也可以由程序管理,其他的工作 JPA 自動處理好了。
3.使用 JPA
要使用 JPA,只要加入它的 Starter 依賴,然后配置數據庫連接信息。
3.1 添加 JPA 和 MySQL 數據庫的依賴
下面以配置 JPA 和 MySQL 數據庫的依賴為例,具體配置見以下代碼:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope>
</dependency>
3.2 配置數據庫連接信息
Spring Boot 項目使用 MySQL 等關系型數據庫,需要配置連接信息,可以在 application.properties 文件中進行配置。以下代碼配置了與 MySQL 數據庫的連接信息:
spring.datasource.url=jdbc:mysql://127.0.0.1/book?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC&useSSL=true
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql= true
spring.datasource.username:要填寫的數據庫用戶名。spring.datasource.password:要填寫的數據庫密碼。spring.jpa.show-sql:開發工具的控制臺是否顯示 SQL語句,建議打開。spring.jpa.properties.hibernate.hbm2ddl.auto:hibernate 的配置屬性,其主要作用是自動創建、更新、驗證數據庫表結構。該參數的幾種配置如下表所示。
| | |
|---|---|
create | 每次加載 Hibernate 時都會刪除上一次生成的表,然后根據 Model 類再重新生成新表,哪怕沒有任何改變也會這樣執行,這會導致數據庫數據的丟失。 |
create-drop | 每次加載 Hibernate 時會根據 Model 類生成表,但是 sessionFactory 一旦關閉,表就會自動被刪除。 |
update | 最常用的屬性。第一次加載 Hibernate 時會根據 Model 類自動建立表的結構(前提是先建立好數據庫)。以后加載 Hibernate 時,會根據 Model 類自動更新表結構,即使表結構改變了,但表中的數據仍然存在,不會被刪除。要注意的是,當部署到服務器后,表結構是不會被馬上建立起來的,要等應用程序第一次運行起來后才會建立。Update 表示如果 Entity 實體的字段發生了變化,那么直接在數據庫中進行更新。 |
validate | 每次加載 Hibernate 時,會驗證數據庫的表結構,只會和數據庫中的表進行比較,不會創建新表,但是會插入新值。 |
4.了解 JPA 注解和屬性
4.1 常用注解
| | |
|---|---|
| @Entity | 聲明類為實體 |
| @Table | 聲明表名,@Entity 和 @Table 注解一般一塊使用,如果表名和實體類名相同,那么 @Table 可以省略 |
| @Basic | 指定非約束明確的各個字段 |
| @Embedded | 用于注釋屬性,表示該屬性的類是嵌入類(@embeddable 用于注釋 Java 類的,表示類是嵌入類) |
| @Id | 指定的類的屬性,一個表中的主鍵 |
| @GeneratedValue | 指定如何標識屬性可以被初始化,如 @GeneratedValue(strategy=GenerationType.SEQUENCE, generator="repair_seq"),表示主鍵生成策略是 sequence,還有 Auto、Identity、Native 等 |
| @Transient | 表示該屬性并非一個數據庫表的字段的映射,ORM 框架將忽略該屬性。如果一個屬性并非數據庫表的字段映射,就務必將其標示為 @Transient,即它是不持久的,為虛擬字段 |
| @Column | 指定持久屬性,即字段名。如果字段名與列名相同,則可以省略。使用方法,如 @Column(length=11, name="phone", nullable=false, columnDefinition="varchar(11) unique comment '電話號碼'") |
| @SequenceGenerator | 指定在 @GeneratedValue 注解中指定的屬性的值。它創建一個序列 |
| @TableGenerator | 在數據庫生成一張表來管理主鍵生成策略 |
| @AccessType | 這種類型的注釋用于設置訪問類型。如果設置 @AccessType(FIELD),則可以直接訪問變量,并且不需要使用 Getter 和 Setter 方法,但必須為 public 屬性。如果設置 @AccessType(PROPERTY),則通過 Getter 和 Setter 方法訪問 Entity 的變量 |
| @UniqueConstraint | 指定的字段和用于主要或輔助表的唯一約束 |
| @ColumnResult | 可以參考使用 select 子句的 SQL 查詢中的列名 |
| @NamedQueries | 指定命名查詢的列表 |
| @NamedQuery | 指定使用靜態名稱的查詢 |
| @Basic | 指定實體屬性的加載方式,如 @Basic(fetch=FetchType.LAZY) |
| @Jsonignore | 作用是 JSON 序列化時將 Java Bean 中的一些屬性忽略掉,序列化和反序列化都受影響 |
4.2 映射關系的注解
| | |
|---|---|
| @JoinColumn | 指定一個實體組織或實體集合。用在 多對一 和 一對多 的關聯中 |
| @OneToOne | 定義表之間 一對一 的關系 |
| @OneToMany | 定義表之間 一對多 的關系 |
| @ManyToOne | 定義表之間 多對一 的關系 |
| @ManyToMany | 定義表之間 多對多 的關系 |
4.3 映射關系的屬性
| | |
|---|---|
targetEntity | 表示默認關聯的實體類型,默認為當前標注的實體類。 |
cascade | 表示與此實體一對一關聯的實體的級聯樣式類型,以及當對實體進行操作時的策略。在定義關系時經常會涉及是否定義 Cascade(級聯處理)屬性,如果擔心級聯處理容易造成負面影響,則可以不定義。它的類型包括 CascadeType.PERSIST(級聯新建)、CascadeType.REMOVE(級聯刪除)、CascadeType.REFRESH(級聯刷新)、CascadeType.MERGE(級聯更新)、CascadeType.ALL(級聯新建、更新、刪除、刷新)。 |
fetch | 該實體的加載方式,包含 LAZY 和 EAGER。 |
optional | 表示關聯的實體是否能夠存在 null 值。默認為 true,表示可以存在 null 值。如果為 false,則要同時配合使用 @JoinColumn 標記。 |
mappedBy | 雙向關聯實體時使用,標注在不保存關系的實體中。 |
JoinColumn | 關聯指定列。該屬性值可接收多個 @JoinColumn。用于配置連接表中外鍵列的信息。@JoinColumn 配置的外鍵列參照當前實體對應表的主鍵列。 |
JoinTable | 兩張表通過中間的關聯表建立聯系時使用,即多對多關系。 |
PrimaryKeyJoinColumn | 主鍵關聯。在關聯的兩個實體中直接使用注解 @PrimaryKeyJoinColumn 注釋。 |
懶加載 LAZY 和實時加載 EAGER 的目的是,實現關聯數據的選擇性加載。
- 懶加載 是一種延遲加載策略,即在真正需要訪問對象的屬性時,才從數據庫中加載數據。當 Hibernate 在查詢數據庫時遇到關聯對象(如一對多、多對一、多對多等關系),并不會立即加載關聯對象的數據,而只會加載主鍵 ID。只有當程序真正需要訪問關聯對象的屬性時,Hibernate 才會發出 SQL 語句去加載數據。這種策略的優點在于,如果程序并不需要訪問關聯對象的所有屬性,那么就可以節省數據庫訪問的開銷,提高程序性能。但是,如果在使用懶加載的對象后關閉了 Session,那么在訪問其關聯對象的屬性時,就會拋出 LazyInitializationException 異常,因為 Hibernate 需要在 Session 的作用范圍內才能發出 SQL 語句加載數據。
- 實時加載 是一種積極加載策略,即在加載一個對象時,會立即加載與其關聯的所有對象。當 Hibernate 在查詢數據庫時遇到關聯對象,會立即發出 SQL 語句加載關聯對象的數據,并將其全部加載到內存中。這種策略的優點在于,程序可以隨時訪問關聯對象的屬性,而無需擔心 Session 是否已經關閉。但是,如果關聯對象的數據量很大,那么就會消耗大量的內存,并可能導致性能下降。
在 Spring Data JPA 中,要控制 Session 的生命周期,否則會出現 could not initialize proxy [xxxx#18] - no Session 錯誤。可以在配置文件中配置以下代碼來控制 Session 的生命周期:
spring.jpa.open-in-view=true
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
5.用 JPA 構建實體數據表
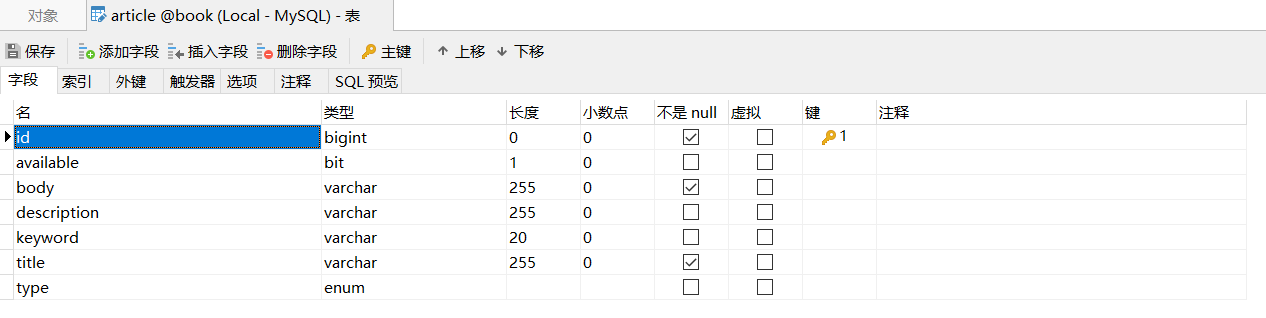
下面通過實例來體驗如何通過 JPA 構建對象/關系映射的實體模型。
package com.example.demo.entity;import lombok.Data;import javax.persistence.*;
import javax.validation.constraints.NotEmpty;
import javax.validation.constraints.Size;
import java.io.Serializable;
import java.util.Arrays;
import java.util.List;@Entity
@Data
public class Article implements Serializable {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private long id;@Column(nullable = false, unique = true)@NotEmpty(message = "標題不能為空")private String title;@Column(columnDefinition = "enum('圖','圖文','文')")private String type;private Boolean available = Boolean.FALSE;@Size(min = 0, max = 20)private String keyword;@Size(max = 255)private String description;@Column(nullable = false)private String body;@Transientprivate List keywordlists;public List getKeywordlists() {return Arrays.asList(this.keyword.trim().split("|"));}public void setKeywordlists(List keywordlists) {this.keywordlists = keywordlists;}
}
如果想創建虛擬字段,則通過在屬性上加注解 @Transient 來解決。
運行項目后會自動生成數據表。完成后的數據表如下圖所示。
:HyperLogLog)




)




)








VP補題題解(48th))