在一個案例中,大表 100GB、小表 10GB,它們全都遠超廣播變量閾值(默認 10MB)。因為小表的尺寸已經超過 8GB,在大于 8GB 的數據集上創建廣播變量,Spark 會直接拋出異常,中斷任務執行,所以 Spark 是沒有辦法應用 BHJ 機制的。那我們該怎么辦呢?
先別急,我們來看看這個案例的業務需求。這個案例來源于計算廣告業務中的流量預測,流量指的是系統中一段時間內不同類型用戶的訪問量。這里有三個關鍵詞,第一個是“系統”,第二個是“一段時間”,第三個是“用戶類型”。時間粒度好理解,就是以小時為單位去統計流量。用戶類型指的是采用不同的維度來刻畫用戶,比如性別、年齡、教育程度、職業、地理位置。系統指的是流量來源,比如平臺、站點、頻道、媒體域名。在系統和用戶的維度組合之下,流量被細分為數以百萬計的不同“種類”。比如,來自 XX 平臺 XX 站點的在校大學生的訪問量,或是來自 XX 媒體 XX 頻道 25-45 歲女性的訪問量等等。
我們知道,流量預測本身是個時序問題,它和股價預測類似,都是基于歷史、去預測未來。在我們的案例中,為了預測上百萬種不同的流量,咱們得先為每種流量生成時序序列,然后再把這些時序序列喂給機器學習算法進行模型訓練。統計流量的數據源是線上的訪問日志,它記錄了哪類用戶在什么時間訪問了哪些站點。要知道,我們要構建的,是以小時為單位的時序序列,但由于流量的切割粒度非常細致,因此有些種類的流量不是每個小時都有訪問量的,如下圖所示。
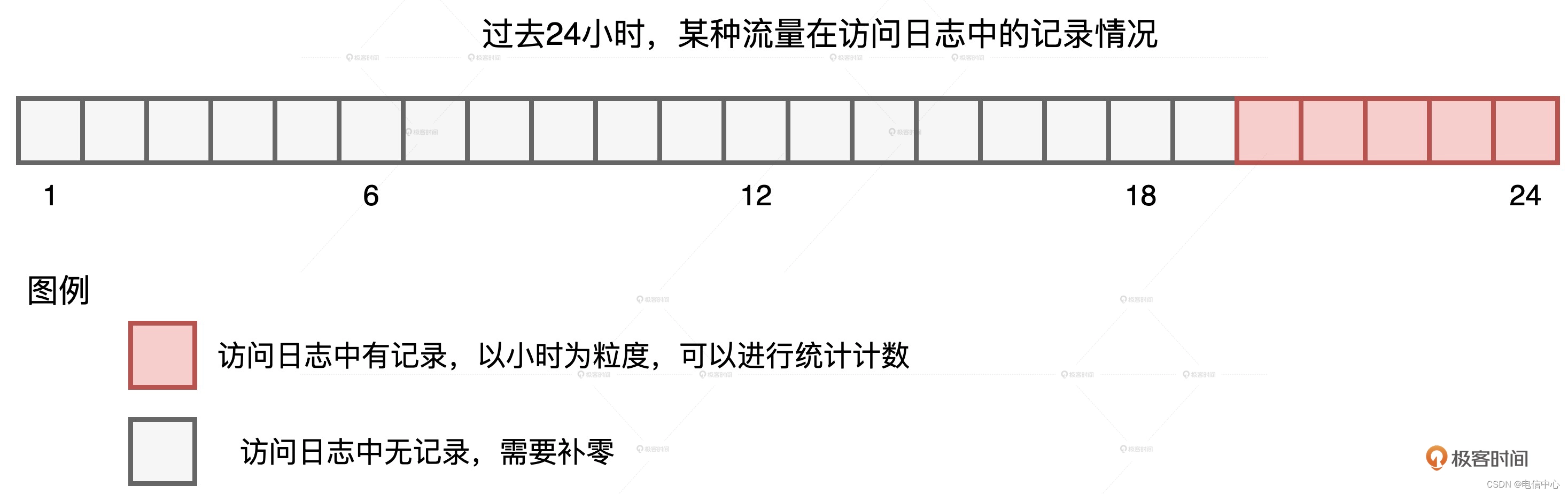
某種流量在過去24小時的記錄情況我們可以看到,在過去的 24 小時中,某種流量僅在 20-24 點這 5 個時段有數據記錄,其他時段無記錄,也就是流量為零。在這種情況下,我們就需要用“零”去補齊缺失時段的序列值。那么我們該怎么補呢?因為業務需求是填補缺失值,所以在實現層面,我們不妨先構建出完整的全零序列,然后以系統、用戶和時間這些維度組合為粒度,用統計流量去替換全零序列中相應位置的“零流量”。這個思路描述起來比較復雜,用圖來理解會更直觀、更輕松一些。
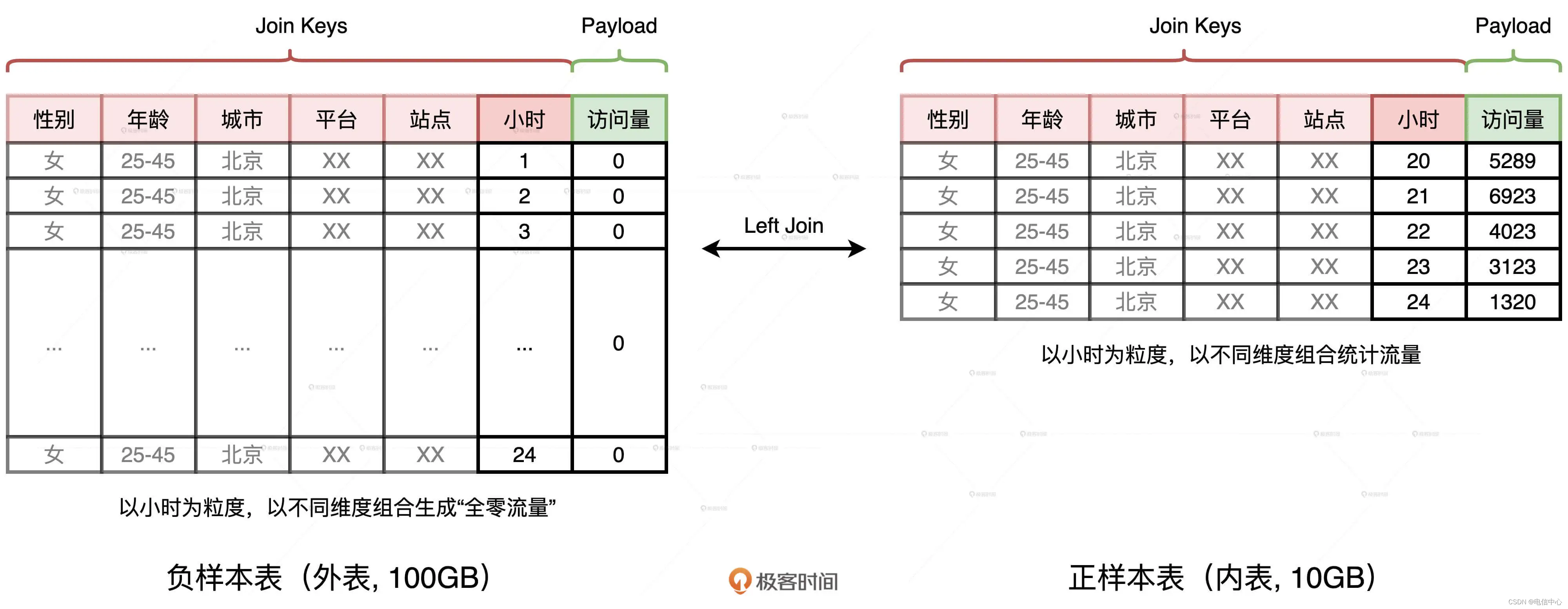
首先,我們生成一張全零流量表,如圖中左側的“負樣本表”所示。這張表的主鍵是劃分流量種類的各種維度,如性別、年齡、平臺、站點、小時時段等等。表的 Payload 只有一列,也即訪問量,在生成“負樣本表”的時候,這一列全部置零。
然后,我們以同樣的維度組合統計日志中的訪問量,就可以得到圖中右側的“正樣本表”。不難發現,兩張表的 Schema 完全一致,要想獲得完整的時序序列,我們只需要把外表以“左連接(Left Outer Join)”的形式和內表做關聯就好了。具體的查詢語句如下:
//左連接查詢語句
select t1.gender, t1.age, t1.city, t1.platform, t1.site, t1.hour, coalesce(t2.access, t1.access) as access
from t1 left join t2 on
t1.gender = t2.gender and
t1.age = t2.age and
t1.city = t2.city and
t1.platform = t2.platform and
t1.site = t2.site and
t1.hour = t2.hour
使用左連接的方式,我們剛好可以用內表中的訪問量替換外表中的零流量,兩表關聯的結果正是我們想要的時序序列。“正樣本表”來自訪問日志,只包含那些存在流量的時段,而“負樣本表”是生成表,它包含了所有的時段。因此,在數據體量上,負樣本表遠大于正樣本表,這是一個典型的“大表 Join 小表”場景。
盡管小表(10GB)與大表(100GB)相比,在尺寸上相差一個數量級,但兩者的體量都不滿足 BHJ 的先決條件。因此,Spark 只好退而求其次,選擇 SMJ(Shuffle Sort Merge Join)的實現方式。我們知道,SMJ 機制會引入 Shuffle,將上百 GB 的數據在全網分發可不是一個明智的選擇。那么,根據“能省則省”的開發原則,我們有沒有可能“省去”這里的 Shuffle 呢?
要想省去 Shuffle,我們只有一個辦法,就是把 SMJ 轉化成 BHJ。你可能會說:“都說了好幾遍了,小表的尺寸 10GB 遠超廣播閾值,我們還能怎么轉化呢?”辦法總比困難多,我們先來反思,關聯這兩張表的目的是什么?目的是以維度組合(Join Keys)為基準,用內表的訪問量替換掉外表的零值。那么,這兩張表有哪些特點呢?首先,兩張表的 Schema 完全一致。其次,無論是在數量、還是尺寸上,兩張表的 Join Keys 都遠大于 Payload。
那么問題來了,要達到我們的目的,一定要用那么多、那么長的 Join Keys 做關聯嗎?答案是否定的。在上一講,我們介紹過 Hash Join 的實現原理,在 Build 階段,Hash Join 使用哈希算法生成哈希表。在 Probe 階段,哈希表一方面可以提供 O(1) 的查找效率,另一方面,在查找過程中,Hash Keys 之間的對比遠比 Join Keys 之間的對比要高效得多。受此啟發,我們為什么不能計算 Join Keys 的哈希值,然后把生成的哈希值當作是新的 Join Key 呢?
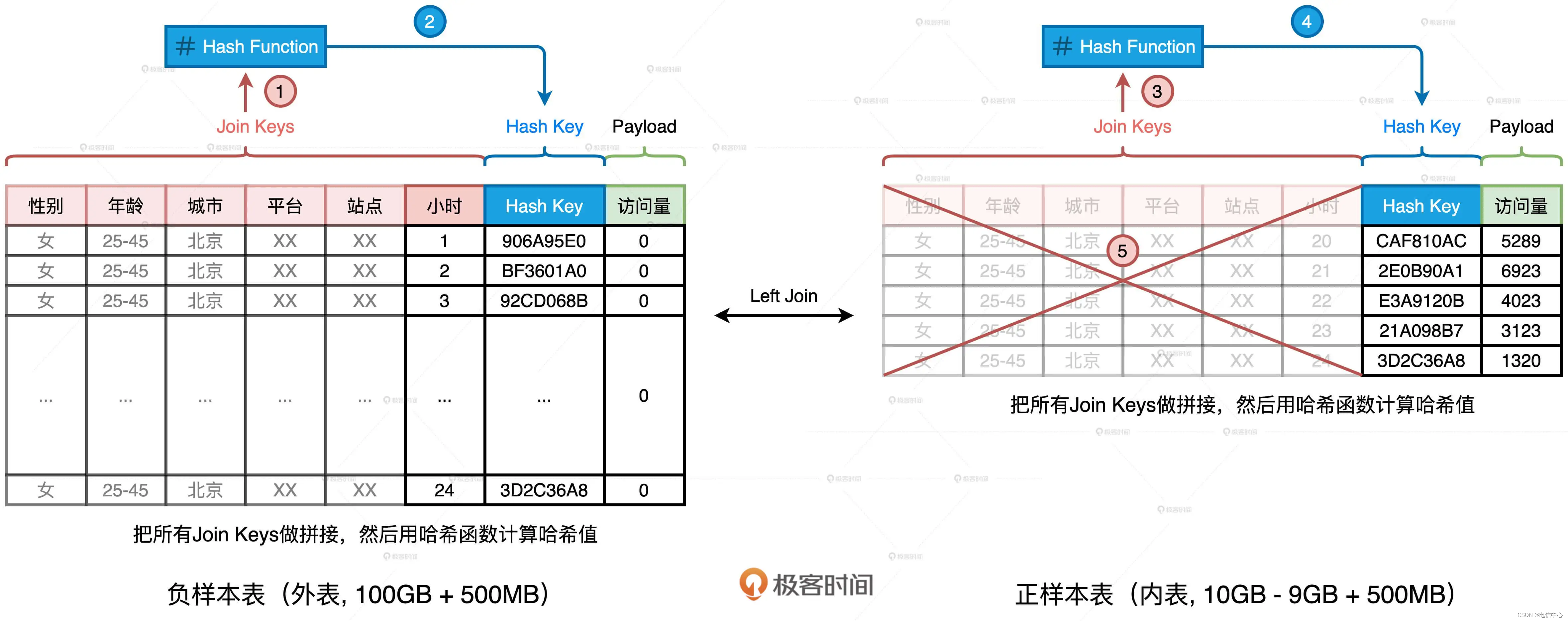
我們完全可以基于現有的 Join Keys 去生成一個全新的數據列,它可以叫“Hash Key”。生成的方法分兩步:把所有 Join Keys 拼接在一起,把性別、年齡、一直到小時拼接成一個字符串,如圖中步驟 1、3 所示使用哈希算法(如 MD5 或 SHA256)對拼接后的字符串做哈希運算,得到哈希值即為“Hash Key”,如上圖步驟 2、4 所示在兩張表上,我們都進行這樣的操作。
如此一來,在做左連接的時候,為了把主鍵一致的記錄關聯在一起,我們不必再使用數量眾多、冗長的原始 Join Keys,用單一的生成列 Hash Key 就可以了。相應地,SQL 查詢語句也變成了如下的樣子。
//調整后的左連接查詢語句
select t1.gender, t1.age, t1.city, t1.platform, t1.site, t1.hour, coalesce(t2.access, t1.access) as access
from t1 left join t2 on
t1.hash_key = t2. hash_key
添加了這一列之后,我們就可以把內表,也就是“正樣本表”中所有的 Join Keys 清除掉,大幅縮減內表的存儲空間,上圖中的步驟 5 演示了這個過程。當內表縮減到足以放進廣播變量的時候,我們就可以把 SMJ 轉化為 BHJ,從而把 SMJ 中的 Shuffle 環節徹底省掉。這樣一來,清除掉 Join Keys 的內表的存儲大小就變成了 1.5GB。對于這樣的存儲量級,我們完全可以使用配置項或是強制廣播的方式,來完成 Shuffle Join 到 Broadcast Join 的轉化,具體的轉化方法你可以參考廣播變量那一講(第 13 講)。
案例 1 說到這里,其實已經基本解決了,不過這里還有一個小細節需要我們特別注意。案例 1 優化的關鍵在于,先用 Hash Key 取代 Join Keys,再清除內表冗余數據。Hash Key 實際上是 Join Keys 拼接之后的哈希值。既然存在哈希運算,我們就必須要考慮哈希沖突的問題。
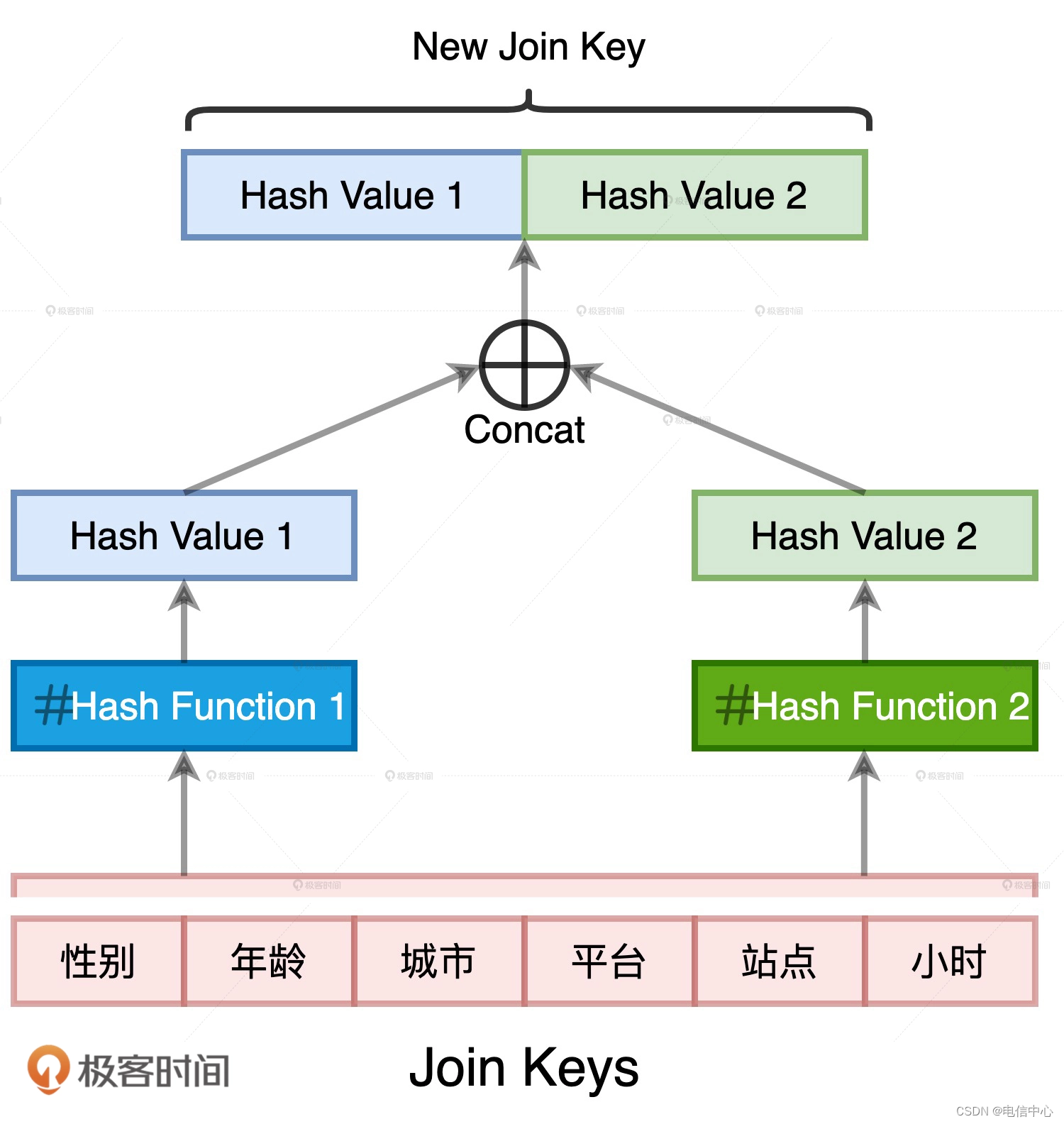
哈希沖突我們都很熟悉,它指的就是不同的數據源經過哈希運算之后,得到的哈希值相同。在案例 1 當中,如果我們為了優化引入的哈希計算出現了哈希沖突,就會破壞原有的關聯關系。比如,本來兩個不相等的 Join Keys,因為哈希值恰巧相同而被關聯到了一起。顯然,這不是我們想要的結果。消除哈希沖突隱患的方法其實很多,比如“二次哈希”,也就是我們用兩種哈希算法來生成 Hash Key 數據列。兩條不同的數據記錄在兩種不同哈希算法運算下的結果完全相同,這種概率幾乎為零。













)
Adobe Flash Player已不再受支持)

)

方法——連接字符串、元組、列表和字典)
