Vision-LSTM: xLSTM as Generic Vision Backbone
公和眾與號:EDPJ(進 Q 交流群:922230617 或加 VX:CV_EDPJ 進 V 交流群)

目錄
0. 摘要
2 方法
3 實驗
3.1 分類設計
4 結論
0. 摘要
Transformer 被廣泛用作計算機視覺中的通用骨干網絡,盡管它最初是為自然語言處理引入的。最近,長短期記憶網絡(LSTM)被擴展為一種可擴展且高性能的架構——xLSTM,通過指數門控和可并行的矩陣存儲結構克服了長期存在的 LSTM 局限性。在這份報告中,我們介紹了視覺 LSTM(Vision-LSTM,ViL),這是 xLSTM 構建模塊在計算機視覺中的一種改編。ViL 由一堆 xLSTM 模塊組成,奇數模塊從上到下處理補丁標記序列,而偶數模塊則從下到上處理。實驗表明,ViL 有望進一步作為新的計算機視覺架構通用骨干網絡進行部署。
項目頁面:https://nx-ai.github.io/vision-lstm/
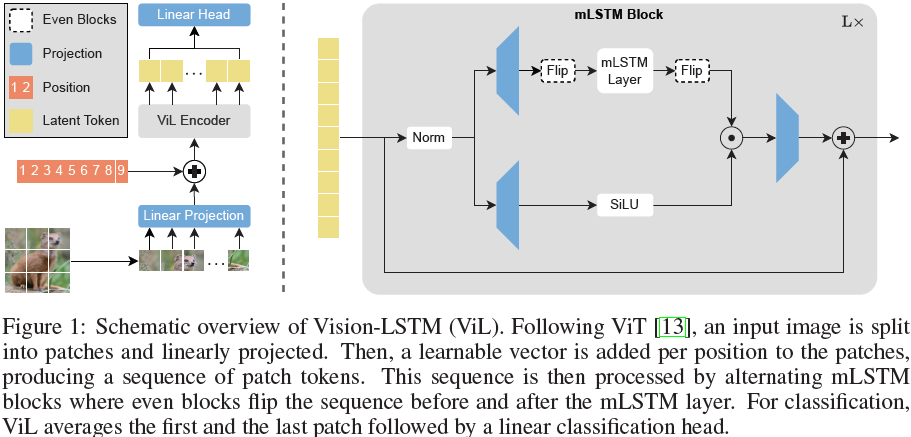
2 方法
Vision-LSTM(ViL)是一個用于計算機視覺任務的通用骨干網絡,它是由 xLSTM 模塊構建而成的,如圖 1 所示。按照 ViT [13] 的方法,ViL 首先通過共享的線性投影將圖像分割成不重疊的補丁(patch),然后為每個補丁標記(token)添加可學習的位置嵌入。ViL 的核心是交替的 mLSTM 模塊,這些模塊是完全可并行化的,并配備了矩陣存儲和協方差更新規則。奇數 mLSTM 模塊從左上角到右下角處理補丁標記,而偶數模塊則從右下角處理到左上角。
(2024,LSTM,Transformer,指數門控,歸一化器狀態,多頭內存混合)xLSTM:擴展的 LSTM
3 實驗
我們在 ImageNet-1K [12] 上進行實驗,該數據集包含 130 萬張訓練圖像和 5 萬張驗證圖像,每張圖像屬于 1000 個類別之一。我們的比較主要集中在使用序列建模骨干網絡并且參數數量大致相當的模型上。
我們在 224x224 分辨率下訓練 ViL 模型 800 個 epochs(tiny, tiny+)或 400 個 epochs(small, small+, base),學習率為 1e-3,使用余弦衰減調度。詳細的超參數可以在附錄 5 中找到。

(2024,ViM,雙向 SSM 骨干,序列建模)利用雙向狀態空間模型進行高效視覺表示學習
為了與 Vision Mamba (Vim) [44] 進行公平比較,我們在模型中添加了額外的模塊,以匹配 tiny 和 small 變體的參數數量(分別記為 ViL-T+ 和 ViL-S+)。需要注意的是,ViL 所需的計算量顯著少于 Vim,因為 ViL 以交替方式遍歷序列,而 Vim 每個模塊遍歷序列兩次。這一點即使在 Vim 使用優化的 CUDA 內核的情況下依然成立,目前 mLSTM 尚無優化的 CUDA 內核(可進一步加速 ViL)。我們在附錄 A.1 中比較了運行時間,ViL 比 Vim 快達 69%。

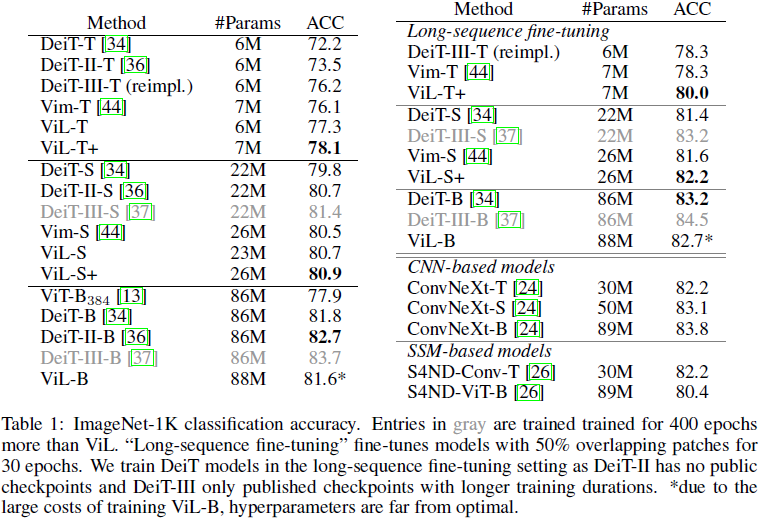
由于 ViT 在視覺領域已得到廣泛應用,經過多年的多次優化循環 [13, 34, 36, 35, 37, 19]。作為首次將 xLSTM 應用于計算機視覺的工作,我們不期望在所有情況下都能超越多年超參數調優的ViT。然而,表 1 中的結果顯示,ViL 在較小規模上顯示出比經過大量優化的 ViT 協議(DeiT, DeiT-II, DeiT-III)更好的結果,只有經過雙倍訓練的 DeiT-III-S 略優于 ViL-S。在 “base” 規模上,ViL 表現優于初始 ViT [13] 模型,并且與 DeiT [34] 取得了可比的結果。需要注意的是,由于在這種規模上訓練模型的成本很高,ViL-B 的超參數遠未達到最佳。參考,訓練 ViL-B 大約需要 600 A100 GPU 小時,或者在 32 個 A100 GPU 上約 19 小時。
通過在 “長序列微調” 設置中微調模型可以進一步提高性能 [44],該設置通過在連續補丁標記之間使用 50% 的重疊,增加序列長度到 729,并微調模型 30 個 epoches。
ViL 在與基于 CNN 的模型(如 ConvNeXt [24])的競爭中也表現出色,盡管沒有利用卷積固有的歸納偏差。

塊設計。我們在表 2 中研究了不同的 ViL 模塊設計方法。簡單的單向 xLSTM 模塊未能達到競爭性能,因為 xLSTM 的自回歸特性不適合圖像分類。以雙向方式遍歷模塊,即在每個模塊中引入一個反向遍歷序列的第二個 mLSTM 層(類似于 Vim [44]),可以提高性能,但也需要更多的參數和 FLOPS。共享前向和后向 mLSTM 的參數使模型更具參數效率,但仍需要更多的計算資源,并且會導致這些參數過載,從而導致性能下降。使用交替模塊可以提高性能,同時保持計算和參數效率。我們還探索了四向設計(類似于 [23]),即行方向(雙向)和列方向(雙向)遍歷序列。雙向僅在行方向(雙向)上遍歷序列。圖 2 可視化了不同的遍歷路徑。

由于雙向和四向模塊的成本增加,這項研究是在大幅減少的設置中進行的。我們在 ImageNet-1K 的一個子集上訓練,該子集僅包含 100 個類別的樣本,分辨率為 128x128,訓練 400 個周期。這尤其必要,因為我們的四向實現不兼容 torch.compile(PyTorch [29] 的一種通用速度優化方法),這導致運行時間更長,如表 2 最后一列所示。由于這一技術限制,我們選擇交替雙向模塊作為我們的核心設計。

3.1 分類設計
為了使用 ViT 進行分類,通常將標記序列池化為單個標記,然后用作分類頭的輸入。最常見的池化方法是:(i)在序列開始處添加一個可學習的 [CLS] 標記,或(ii)對所有補丁標記取平均值生成一個 [AVG] 標記。是否使用 [CLS] 或 [AVG] 標記通常是一個超參數,兩種變體的性能大致相當。而自回歸模型通常需要專門的分類設計。例如,Vim [44] 需要將 [CLS] 標記放在序列中間,如果使用其他分類設計(如 [AVG] 標記或在序列開始和結束處分別放置兩個 [CLS] 標記),性能會大幅下降。由于其自回歸特性,我們在表 3 中探索了不同的 ViL 分類設計。[AVG] 對所有補丁標記取平均值,“Middle Patch” 使用中間補丁標記,“Middle [CLS]” 在序列中間使用一個 [CLS] 標記,“Bilateral [AVG]” 使用第一個和最后一個補丁標記的平均值。我們發現,ViL 對分類設計相對魯棒,所有性能差異都在 0.6% 以內。我們選擇 “Bilateral [AVG]” 而不是 “Middle [CLS]”,因為 ImageNet-1K 已知具有中心偏差,即物體通常位于圖片中央。通過使用 “Bilateral [AVG]”,我們避免了利用這種偏差,使我們的模型更具普適性。
為了與使用單一標記作為分類頭輸入的先前架構保持可比性,我們對第一個和最后一個補丁取平均值。為了實現最佳性能,我們建議將這兩個標記連接起來(“Bilateral Concat”)而不是取平均值。這類似于自監督視 ViT 中的常見做法,如 DINOv2 [28],它們通過在 [CLS] 和 [AVG] 標記處分別附加兩個目標進行訓練,因此通過連接 [CLS] 和 [AVG] 標記的表示受益。這一方向也已在視覺 SSM 模型 [40] 中進行了探索,在序列中散布多個 [CLS] 標記并用作分類器的輸入。類似的方法也可以提高 ViL 的性能。
4 結論
受 xLSTM 在語言建模中成功的啟發,我們介紹了 ViL,這是一種將 xLSTM 架構改編到視覺任務中的方法。ViL 以交替方式處理補丁標記序列。奇數模塊按行從左上角處理到右下角,而偶數模塊從右下角處理到左上角。我們的新架構在 ImageNet-1K 分類中優于基于 SSM 的視覺架構和優化后的 ViT 模型。值得注意的是,ViL 在公平比較中能夠超越經過多年超參數調優和改進的 ViT 訓練管道。
未來,我們看到在需要高分辨率圖像以獲得最佳性能的場景中應用 ViL 的潛力,例如語義分割或醫學成像。在這些設置中,transofrmer 由于自注意力的二次復雜性而面臨高計算成本,而 ViL 由于其線性復雜性則不然。此外,改進預訓練方案(如通過自監督學習),探索更好的超參數設置或遷移 transformer 中的技術(如 LayerScale [35])都是 ViL 的有前景的方向。













)





部署YOLOv5-YOLOv7步驟詳解)