提示:文章寫完后,目錄可以自動生成,如何生成可參考右邊的幫助文檔
文章目錄
- 前言
- 一、分貝是什么?
- 1.功率量
- 2.場量
- 二、實際操作
- 1.分析wav文件
- 2.讀取麥克風
- 總結
前言
最近面對一個需求,就是需要傳遞聲音文件到模型里推理完成語音轉文字,問題是我們使用的是麥克風啊,由于這個特殊屬性就需要有一個合理的方法來判斷聲音的開始,聲音的結束和聲音的長度。像科大訊飛這樣的庫已經有這個功能了,如果遇到沒有這個功能的怎么辦,還得靠自己。
方法其實有很多,我們這里使用根據分貝來判斷,首先就需要獲取到分貝。
一、分貝是什么?
分貝(decibel)是量度兩個相同單位之數量比例的單位,常用dB表示。“分”(deci-)指十分之一,個位是“貝”或“貝爾”(bel,紀念發明家亞歷山大·格拉漢姆·貝爾),但一般只用分貝。
計算分貝的方法有功率量和場量兩種方式,功率量這種方式我還沒有完全研究透,我先闡述下概念,等我研究透了再補充具體代碼。我們這里先介紹場量這種方式,再給出具體的代碼。
1.功率量
功率量(power quantity)是功率值或者直接與功率值成比例的其它量,如能量密度、音強、發光強度等。
考慮功率或者強度(intensity)時,其比值可以表示為分貝,這是通過把測量值與參考量值之比計算基于10的對數,再乘以10。因此功率值P1與另一個功率值P0之比用分貝表示為LdB:

兩個功率值的比值基于10的對數,就是貝爾(bel)值。兩個功率值之比的分貝值是貝爾值的1/10倍(或者說,1個分貝是十分之一貝爾)。P1與P0必須度量同一個數值類型,具有相同的單位。如果在上式中P1 = P0,那么LdB = 0。如果P1大于P0,那么LdB是正的;如果P1小于P0,那么LdB是負的。
重新安排上式可得到計算P1的公式,依據P0與LdB:

因為貝爾是10倍的分貝,對應的使用貝爾(LB)的公式為:

2.場量
場量(field quantity)是諸如電壓、電流、聲壓、電場強度、速度、電荷密度等量值,其平方值在一個線性系統中與功率成比例。
考慮到場(field)的幅值(amplitude)時,通常使用A1(度量到的幅值)的平方與A0(參考幅值)的平方之比。這是因為對于大多數應用,功率與幅值的平方成比例,并期望對同一應用采取功率計算的分貝與用場的幅值計算的分貝相等。因此使用下述場量的分貝定義:

上述公式可寫成:
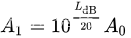
總結:拿到聲音的幅值和參考幅值以10為底求對數,然后再乘以20就是最終的分貝數了。為了方便闡述這里以單聲道、16000HZ采樣率、16bits小端為示例。
注意:以下所有的都是基于上面的參數來闡述的,不懂得請先補習下知識,要不然后面得就完全看不懂了。
二、實際操作
由于讀取麥克風和分析文件完全不一樣,這里就分開講。
1.分析wav文件
先說下RIFF,這個是分析文件必備的知識。
RIFF,全稱Resource Interchange File Format(資源交換文件格式),是一種元文件格式(meta-format),設計用于高效地存儲和交換多媒體數據,如音頻、視頻、圖像以及相關元數據。該格式由Microsoft和IBM于1991年聯合推出,主要用于當時的Windows 3.1操作系統,并成為其默認的多媒體文件格式。
就是說我們以.wav文件為示例,這種文件都是符合RIFF規范的。下面的圖片是.wav文件典型的存儲格式:
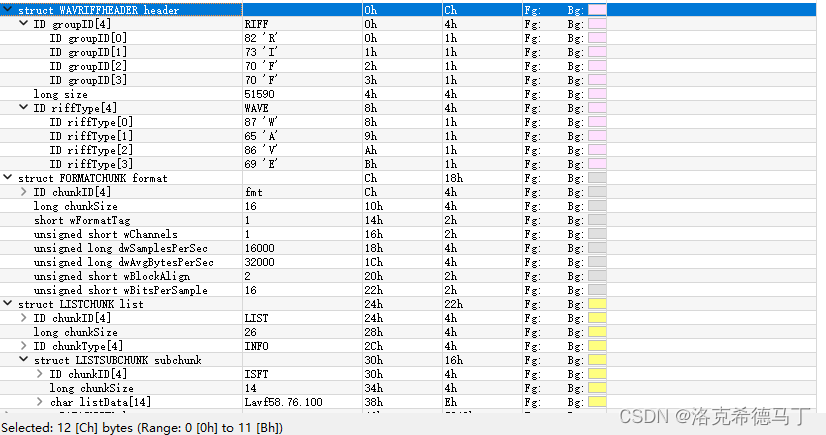
wav文件主要包含三個chunk:riff chunk、format chunk、data chunk,這三個是缺一不可的。我簡單寫了個解析wav的算法我覺得還不完善,所以暫時不放出來了,因為ffmpeg已經自帶解析算法了,也不需要再單獨寫一個,感興趣的可以私下研究下。這里我用ffmpeg的代碼來演示:
main.cpp
#include <iostream>
#include <cstdio>extern "C" {
#include <libavformat/avformat.h>
#include <libavdevice/avdevice.h>
}void read_file_ffmpeg(const char *filename) {av_register_all();avformat_network_init();AVFormatContext *formatContext = nullptr;if (avformat_open_input(&formatContext, filename, nullptr, nullptr) != 0) {fprintf(stderr, "Could not open file.\n");return;}if (avformat_find_stream_info(formatContext, nullptr) < 0) {fprintf(stderr, "Failed to retrieve stream info.\n");return;}int audioStreamIndex = av_find_best_stream(formatContext, AVMEDIA_TYPE_AUDIO, -1, -1, nullptr, 0);if (audioStreamIndex < 0) {fprintf(stderr, "No audio stream found.\n");return;}AVCodecContext *codecContext = formatContext->streams[audioStreamIndex]->codec;AVCodec *codec = avcodec_find_decoder(codecContext->codec_id);if (!codec) {fprintf(stderr, "Codec not found.\n");return;}if (avcodec_open2(codecContext, codec, nullptr) < 0) {fprintf(stderr, "Could not open codec.\n");return;}AVPacket packet;AVFrame *frame = av_frame_alloc();//check max dbdouble max_db = 0;while (av_read_frame(formatContext, &packet) >= 0) {if (packet.stream_index == audioStreamIndex) {int ret;// 發送數據包到解碼器ret = avcodec_send_packet(codecContext, &packet);if (ret < 0) {fprintf(stderr, "Error sending a packet for decoding.\n");break;}// 獲取解碼后的幀while (true) {ret = avcodec_receive_frame(codecContext, frame);if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF) {break;} else if (ret < 0) {fprintf(stderr, "Error during decoding.\n");break;}// 解碼成功,處理frame->data和frame->linesize中的音頻數據
// std::cout << frame->linesize[0] << std::endl;uint8_t *sampleValues = frame->data[0];for (int k = 0; k < frame->linesize[0]; k = k + 2) {uint16_t u_sample = sampleValues[k] | (sampleValues[k + 1] << 8);auto sample = (int16_t) u_sample;
// std::cout << sample << ',';double dB = 20 * log10(abs(sample));std::cout << dB << ',';if (dB > max_db) {max_db = dB;}
// if (dB > DB_SAMPLE) {
// std::cout << "people talk" << std::endl;
// }}std::cout << "---------------" << std::endl;}}av_packet_unref(&packet);}std::cout << "max_db: " << max_db << std::endl;av_frame_free(&frame);avcodec_close(codecContext);avformat_close_input(&formatContext);
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(read_microphone)set(CMAKE_CXX_STANDARD 11)
#set(CMAKE_CXX_COMPILER /usr/bin/g++-11)
#set(CMAKE_C_COMPILER /usr/bin/gcc-11)find_package(PkgConfig REQUIRED)pkg_check_modules(ffmpeg_lib REQUIRED IMPORTED_TARGET libavformat libavutil libavdevice libavcodec)
add_executable(ffmpeg_bin main.cpp)
target_link_libraries(ffmpeg_bin PkgConfig::ffmpeg_lib)
執行成功了輸出分貝值:
25.1055,20,20,18.0618,25.1055,6.0206,16.902,23.5218,33.442,31.8213,33.0643,34.4855,35.8478,33.9794,31.8213,33.6248,34.8073,36.2583,34.8073,35.563,32.2
這個結果的參考幅值是1而不是32767,我查了下幅值計算分貝是沒有標準參考值的,因參考值的不同結果也會不同。不過這并不影響我們對結果的判斷。
注意:一定要用我說的那種wav文件,因為市面上主流的語音識別都是基于16000hz,單聲道,16bits小端處理的。雙聲道除了增加了性能消耗和復雜度幾乎沒有特別的意義,而且過高的采樣率并不利于人聲識別,反而增加背景噪聲。
2.讀取麥克風
同樣使用ffmpeg,只不過讀出來的數據不是wav,而是pcm格式,不用對數據進行特別的解碼,直接拿來用即可。
main.cpp
#include <iostream>
#include <cstdio>
#include <fstream>extern "C" {
#include <libavformat/avformat.h>
#include <libavdevice/avdevice.h>
}/*** @author arnold* @brief use alsa and default device* */
void read_microphone() {// av_register_all();//ffmpeg 3.x versionavdevice_register_all();AVFormatContext *fmt_ctx = nullptr;AVInputFormat *input_fmt = av_find_input_format("alsa"); // 音頻設備的輸入格式,如alsa、pulse等const char *dev_name = "default"; // microphone device nameAVDictionary *format_opts = nullptr;//set stream format optionsav_dict_set(&format_opts, "sample_rate", "16000", 0);//set audio sampleav_dict_set(&format_opts, "channels", "1", 0);//set audio channelav_dict_set(&format_opts, "fragment_size", "256", 0);//set audio fragment size// open audio deviceif (avformat_open_input(&fmt_ctx, dev_name, input_fmt, &format_opts) != 0) {printf("can't open input device!\n");if (format_opts)av_dict_free(&format_opts);return;}if (format_opts)av_dict_free(&format_opts);//Output Info---printf("---------------- File Information ---------------\n");av_dump_format(fmt_ctx, 0, dev_name, 0);printf("-------------------------------------------------\n");// find audio stream infoif (avformat_find_stream_info(fmt_ctx, nullptr) < 0) {printf("can't get audio stream info!\n");return;}int audio_stream_idx = -1;// find audio stream indexfor (int i = 0; i < fmt_ctx->nb_streams; i++) {if (fmt_ctx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_AUDIO) {audio_stream_idx = i;break;}}if (audio_stream_idx == -1) {printf("can't find audio stream index!\n");return;}//write pcm data
// std::ofstream ofs("../audio/test.pcm");AVPacket packet;while (av_read_frame(fmt_ctx, &packet) >= 0) {if (packet.stream_index == audio_stream_idx) {std::cout << "packet size: " << packet.size << std::endl;std::cout << "packet duration: " << packet.duration << std::endl;
// ofs.write((char *) packet.data, packet.size);
// ofs.flush();for (int i = 0; i < packet.size; i = i + 2) {uint16_t u_sample = packet.data[i] | (packet.data[i + 1] << 8);auto sample = (int16_t) u_sample;
// std::cout << sample << ',';double dB = 20 * log10(abs(sample));if (dB > 60){std::cout << dB << ',';}}std::cout << std::endl;}av_packet_unref(&packet);}avformat_close_input(&fmt_ctx);
// ofs.close();
}int main() {read_microphone();return 0;
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(read_microphone)set(CMAKE_CXX_STANDARD 11)
#set(CMAKE_CXX_COMPILER /usr/bin/g++-11)
#set(CMAKE_C_COMPILER /usr/bin/gcc-11)find_package(PkgConfig REQUIRED)pkg_check_modules(ffmpeg_lib REQUIRED IMPORTED_TARGET libavformat libavutil libavdevice libavcodec)
add_executable(ffmpeg_bin main.cpp)
target_link_libraries(ffmpeg_bin PkgConfig::ffmpeg_lib)
總結
1、代碼完全基于單聲道音頻,沒對多聲道進行處理,理論上除了參考值不同對多聲道音頻也是能處理的
2、注意出來的分貝值不一定等于分貝計測出來的,分貝計很可能是基于功率強度或聲壓強度來來測試結果,我們依據的是幅值,原理還是不一樣的。










![[pyradiomics][python]pyradiomics所有whl文件下載地址匯總](http://pic.xiahunao.cn/[pyradiomics][python]pyradiomics所有whl文件下載地址匯總)
(HarmonyOS學習第七課))



)


常見表引擎)
