1.前言
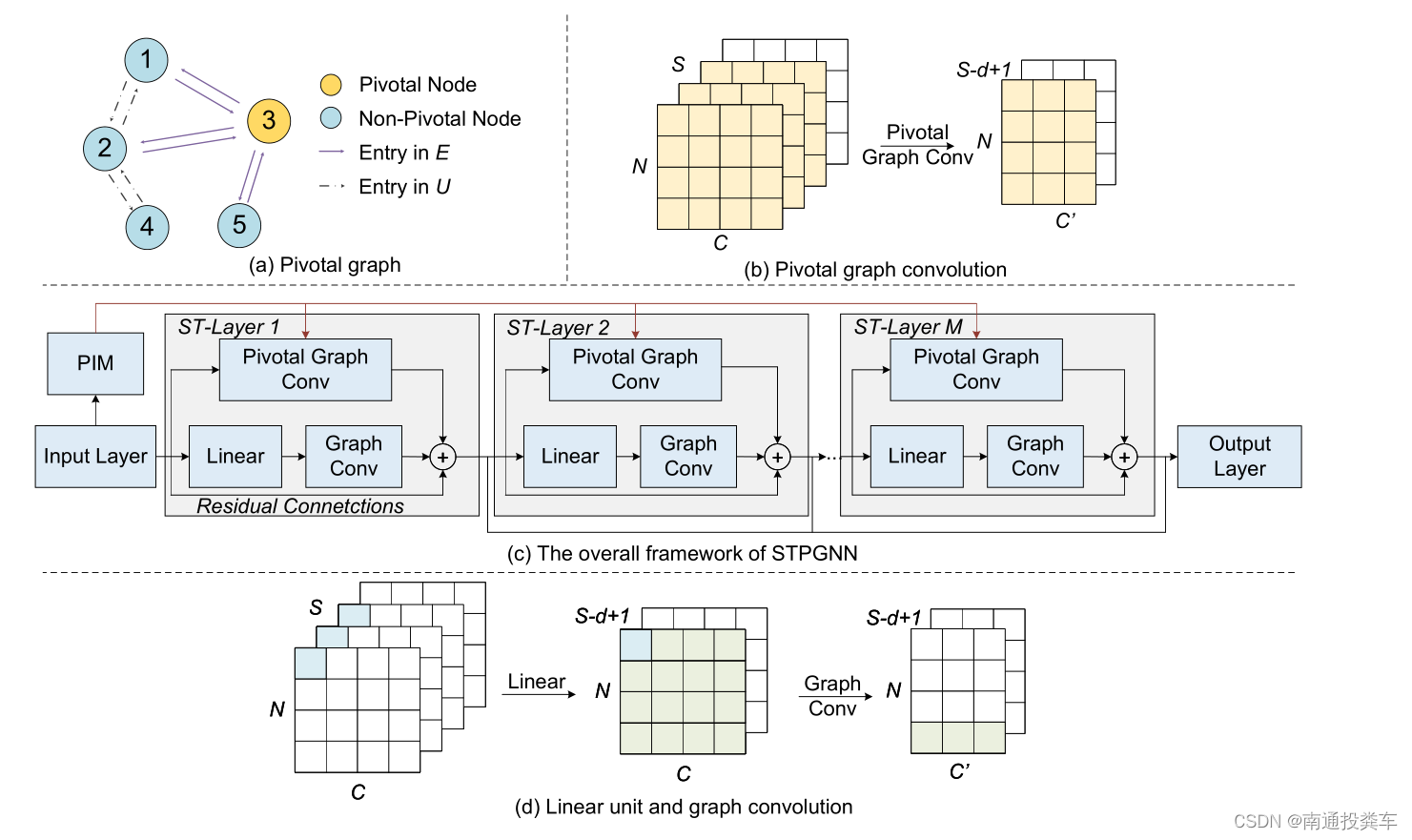
本次代碼文章來自于《2024-AAAI-Spatio-Temporal Pivotal Graph Neural Networks for Traffic Flow Forecasting》,基本模型結構如下圖所示:
文章講解視頻鏈接
代碼開源鏈接
接下來就開始代碼解讀了。
?
2.代碼解讀?
class nconv(nn.Module):def __init__(self):super(nconv, self).__init__()def forward(self, x, A):x = torch.einsum('ncvl,nwv->ncwl', (x, A))return x.contiguous()讓我們逐行分析:
-
def __init__(self):這是構造函數,初始化nconv類的實例。這里沒有額外的初始化參數,因為它沒有定義任何需要學習的參數。 -
super(nconv, self).__init__():這一行調用了父類nn.Module的構造函數,確保了所有必要的初始化步驟得以執行。 -
def forward(self, x, A):定義了前向傳播方法,這是每個nn.Module子類必須實現的方法。這個方法接受兩個輸入參數:x: 輸入張量,形狀為?(N, C, V, L),其中?N?是批量大小,C?是通道數,V?是頂點數,L?是序列長度。A: 圖的鄰接矩陣,形狀為?(N, W, V),其中?W?是邊的權重數,V?是頂點數。這里的?W?和?V?應該對應于圖中的權重和頂點。
-
x = torch.einsum('ncvl,nwv->ncwl', (x, A))這一行是核心計算部分,使用了torch.einsum函數來執行一個高效的多維數組乘法和求和操作。einsum的第一個參數是一個字符串,描述了輸入張量的維度標簽和輸出張量的維度標簽。這里的標簽解釋如下:'ncvl'?表示輸入張量?x?的四個維度:N(批量大小),C(通道數),V(頂點數),L(序列長度)。'nwv'?表示輸入張量?A?的三個維度:N(批量大小),W(邊的權重數),V(頂點數)。'ncwl'?表示輸出張量的四個維度:N(批量大小),C(通道數),W(邊的權重數),L(序列長度)。
這個表達式實際上是在進行類似于圖卷積的操作,其中輸入特征
x與圖的鄰接矩陣A相乘,以傳播信息通過圖的邊。 -
return x.contiguous()最后返回處理后的張量。contiguous()方法用于確保返回的張量在內存中是連續存儲的,這對于后續可能的操作(如索引或視圖轉換)來說是必要的。
總的來說,nconv 模塊接收輸入特征和圖的鄰接矩陣,然后通過 torch.einsum 實現了一種特定的卷積操作,用于處理圖結構數據。
class pconv(nn.Module):def __init__(self):super(pconv, self).__init__()def forward(self, x, A):x = torch.einsum('bcnt, bmn->bc', (x, A))return x.contiguous()pconv 類定義了一個自定義的PyTorch模塊,該模塊實現了一種特定類型的卷積操作,其中輸入張量與一個可學習的或預定義的鄰接矩陣(A)進行乘法運算。這種類型的卷積通常在圖神經網絡(Graph Neural Networks, GNNs)中使用,其中A可以代表圖的鄰接矩陣,用于編碼節點之間的連接性。下面是對 pconv 類的詳細解釋:
__init__?方法
pconv 類繼承自 nn.Module,這是所有PyTorch神經網絡模塊的基類。構造函數 __init__ 中沒有定義任何額外的參數或層,這意味著 pconv 不包含任何可學習的參數,即它不會在訓練過程中更新其權重。
forward?方法
forward 方法定義了當數據通過這個模塊時的操作。它接受兩個參數:
x: 輸入張量,形狀為?(batch_size, channels, nodes, time_steps)。其中:batch_size?表示一個批次中的樣本數量。channels?表示每個節點在每個時間步上的特征數量。nodes?表示圖中的節點數量。time_steps?表示時間序列的長度。
A: 鄰接矩陣,形狀為?(batch_size, nodes, nodes)。A?可以是預定義的,也可以是可學習的,它編碼了圖中節點之間的關系。
內部操作
在 forward 方法內部,使用了 torch.einsum 函數來執行一個高效的矩陣乘法操作。einsum 是一個通用的函數,用于執行各種類型的張量運算,這里用來實現輸入張量 x 與鄰接矩陣 A 的乘法。
torch.einsum('bcnt, bmn->bc', (x, A)) 這行代碼中,字符串 'bcnt, bmn->bc' 定義了輸入張量的子標模式以及期望的輸出模式。具體來說:
'bcnt'?指代?x?的四個維度,分別對應于 batch size (b)、channels (c)、nodes (n) 和 time steps (t)。'bmn'?指代?A?的三個維度,分別對應于 batch size (b)、源節點 (m) 和目標節點 (n)。'bc'?是輸出張量的模式,意味著輸出將是一個二維張量,其維度為 batch size 和 channels。
輸出
x = torch.einsum('bcnt, bmn->bc', (x, A)) 計算的結果是一個形狀為 (batch_size, channels) 的張量,這表明對于每一個樣本,我們得到了一個壓縮后的特征表示,其中時間步和節點維度被聚合掉了。
最后,return x.contiguous() 確保返回的張量是連續存儲的,這對于后續的某些操作可能很重要,例如當張量需要在GPU上進行高效計算時。這是因為非連續的內存布局可能會導致性能下降。
?
class linear(nn.Module):def __init__(self, c_in, c_out):super(linear, self).__init__()self.mlp = torch.nn.Conv2d(c_in, c_out, kernel_size=(1, 1), padding=(0, 0), stride=(1, 1), bias=True)def forward(self, x):return self.mlp(x)linear 類是一個自定義的 PyTorch 模塊,它實質上實現了一個線性變換。
?
class gcn(nn.Module):def __init__(self, c_in, c_out, dropout, support_len=3, order=2):super(gcn, self).__init__()self.nconv = nconv()c_in = (order * support_len + 1) * c_inself.mlp = linear(c_in, c_out)self.dropout = dropoutself.order = orderdef forward(self, x, support):out = [x]for a in support:x1 = self.nconv(x, a)out.append(x1)for k in range(2, self.order + 1):x2 = self.nconv(x1, a)out.append(x2)x1 = x2h = torch.cat(out, dim=1)h = self.mlp(h)return hgcn 類定義了一個基于圖卷積網絡(Graph Convolutional Network, GCN)的模塊,它在圖結構數據上執行多階卷積操作,以捕獲不同層次的節點間關聯。下面是對 gcn 類的詳細解析:
初始化方法?__init__
在構造函數 __init__ 中,gcn 類繼承自 nn.Module 并初始化以下組件:
nconv: 實例化?nconv?類,用于執行圖卷積操作。mlp: 實例化?linear?類,用于線性變換和聚合來自不同階卷積的結果。dropout: 設置 dropout 比率,用于正則化和防止過擬合。order: 設置圖卷積的階數,控制卷積操作的深度,即卷積在圖上擴展的層數。
c_in 的值被重新定義為 (order * support_len + 1) * c_in,這考慮到了 support_len 個支持矩陣在 order 階的卷積中產生的特征通道數。+1 是因為原始輸入 x 也會被拼接到最終的輸出中。
前向傳播方法?forward
在 forward 方法中,gcn 類執行以下操作:
- 初始化一個列表?
out?來保存每一階卷積的結果,首先添加原始輸入?x。 - 對于?
support?中的每一個鄰接矩陣?a,執行以下操作:- 使用?
nconv?對輸入?x?和鄰接矩陣?a?進行一次卷積,結果存儲在?x1?中,并添加到?out。 - 接下來,對于?
order?中的每一階(從 2 開始),重復使用?nconv?對前一階的結果?x1?和同一個鄰接矩陣?a?進行卷積,結果存儲在?x2?中,再添加到?out,并將?x2?設為下一次迭代的輸入?x1。
- 使用?
- 將?
out?中的所有結果在通道維度(dim=1)上進行拼接,形成一個包含所有階卷積結果的張量?h。 - 將?
h?傳遞給?mlp?層,進行線性變換和通道數的調整,最終輸出調整后的特征表示。
總結
gcn 類通過多次調用 nconv 模塊來執行多階圖卷積,捕捉圖中節點間的多層次關系。通過將不同階的卷積結果拼接起來,它能夠整合從局部到全局的節點信息。最后,mlp 層負責將這些多階特征映射到期望的輸出維度,以便進一步的處理或分類。這種設計使得 gcn 能夠有效處理復雜圖結構數據,并在諸如社交網絡分析、分子結構預測等任務中發揮重要作用。
?
class pgcn(nn.Module):def __init__(self, c_in, c_out, dropout, support_len=3, order=2, temp=1):super(pgcn, self).__init__()self.nconv = nconv()self.temp = tempc_in = (order * support_len + 1) * c_inself.mlp = linear(c_in, c_out)self.dropout = dropoutself.order = orderdef forward(self, x, support):out = [x]for a in support:x1 = self.nconv(x, a)out.append(x1)for k in range(2, self.order + 1):x2 = self.nconv(x1, a)out.append(x2)x1 = x2h = torch.cat(out, dim=1)h = self.mlp(h)h = h[:,:,:,-h.size(3):-self.temp]return hpgcn 類定義了一個個性化的圖卷積網絡(Personalized Graph Convolutional Network)模塊,它在圖卷積的基礎上引入了個性化參數,允許模型在處理圖數據時考慮到更加細致的節點特性或時間序列特性。下面是對 pgcn 類的詳細解析:
初始化方法?__init__
pgcn 類繼承自 nn.Module 并初始化以下組件:
nconv: 實例化?nconv?類,用于執行圖卷積操作。temp: 一個個性化參數,用于在輸出中裁剪時間序列數據,這可能用于處理具有周期性或季節性模式的時間序列數據,通過移除某些時間點的數據來增強模型對特定時間模式的學習能力。mlp: 實例化?linear?類,用于線性變換和聚合來自不同階卷積的結果。dropout: 設置 dropout 比率,用于正則化和防止過擬合。order: 設置圖卷積的階數,控制卷積操作的深度。
與 gcn 類似,c_in 的值被重新定義為 (order * support_len + 1) * c_in,考慮到了多階卷積產生的特征通道數。
前向傳播方法?forward
forward 方法中,pgcn 類執行的操作與 gcn 類似,但在輸出階段有一個關鍵的區別:
- 初始化一個列表?
out?來保存每一階卷積的結果,首先添加原始輸入?x。 - 對于?
support?中的每一個鄰接矩陣?a,執行多階卷積操作,將結果存儲在?out?中。 - 將?
out?中的所有結果在通道維度(dim=1)上進行拼接,形成一個包含所有階卷積結果的張量?h。 - 將?
h?傳遞給?mlp?層,進行線性變換和通道數的調整。 - 個性化裁剪:在?
h?上執行一個個性化裁剪操作,通過?h = h[:,:,:,-h.size(3):-self.temp],這將從?h?的最后一個維度(通常是時間序列的長度)開始,去除從末尾開始的?self.temp?個時間點的數據。這種裁剪可以用于去除不需要的時間點,例如去除最近的短期波動,以便模型更專注于長期趨勢或周期性模式。
總結
pgcn 類通過在標準圖卷積網絡的基礎上引入個性化參數 temp,增強了模型處理時間序列圖數據的能力。通過裁剪時間序列的末端,模型可以更好地聚焦于數據中的長期模式,這對于處理具有季節性或周期性特性的數據集尤為重要。
?
def __init__(self, device, num_nodes, dropout=0.3, topk=35,out_dim=12, residual_channels=16, dilation_channels=16, end_channels=512,kernel_size=2, blocks=4, layers=2, days=288, dims=40, order=2, in_dim=9, normalization="batch"):super(STPGNN, self).__init__()skip_channels = 8self.alpha = nn.Parameter(torch.tensor(-5.0)) self.topk = topkself.dropout = dropoutself.blocks = blocksself.layers = layersself.filter_convs = nn.ModuleList()self.gate_convs = nn.ModuleList()self.residual_convs = nn.ModuleList()self.skip_convs = nn.ModuleList()self.normal = nn.ModuleList()self.gconv = nn.ModuleList()self.residual_convs_a = nn.ModuleList()self.skip_convs_a = nn.ModuleList()self.normal_a = nn.ModuleList()self.pgconv = nn.ModuleList()self.start_conv_a = nn.Conv2d(in_channels=in_dim,out_channels=1,kernel_size=(1, 1))self.start_conv = nn.Conv2d(in_channels=in_dim,out_channels=residual_channels,kernel_size=(1, 1))receptive_field = 1self.supports_len = 1self.nodevec_p1 = nn.Parameter(torch.randn(days, dims).to(device), requires_grad=True).to(device)self.nodevec_p2 = nn.Parameter(torch.randn(num_nodes, dims).to(device), requires_grad=True).to(device)self.nodevec_p3 = nn.Parameter(torch.randn(num_nodes, dims).to(device), requires_grad=True).to(device)self.nodevec_pk = nn.Parameter(torch.randn(dims, dims, dims).to(device), requires_grad=True).to(device)這段代碼是 STPGNN 類的初始化方法 __init__ 的一部分,它主要負責構建模型的架構和初始化必要的參數。下面是詳細的解析:
構建網絡組件
-
Convolution Layers and Residual Connections:
self.filter_convs,?self.gate_convs: 這兩個列表存儲了因果卷積(Causal Convolution)層,它們用于處理時間序列數據,通過濾波器(filter)和門控(gate)機制捕捉時間依賴性。self.residual_convs,?self.skip_convs: 這些列表分別存儲了殘差卷積和跳躍連接卷積層,用于在網絡中建立殘差連接和跳躍連接,有助于梯度傳播并避免深度網絡中的梯度消失/爆炸問題。self.normal: 這個列表包含了歸一化層,如批量歸一化(Batch Normalization)或層歸一化(Layer Normalization),用于加速訓練過程和提升模型性能。
-
Graph Convolution Layers:
self.gconv,?self.pgconv: 這兩個列表分別存儲了圖卷積(Graph Convolution)層和個性化圖卷積(Personalized Graph Convolution)層,用于處理圖結構數據,捕捉節點間的空間依賴性。self.residual_convs_a,?self.skip_convs_a,?self.normal_a: 這些組件與前面提到的組件類似,但是專門用于輔助分支,可能是為了處理特定類型的信息或者用于構建個性化的圖卷積。
-
Input Layers:
self.start_conv_a,?self.start_conv: 這兩個卷積層用于調整輸入數據的維度,self.start_conv_a?可能用于特定的輔助特征提取,而?self.start_conv?則是主輸入層,用于調整輸入特征至殘差通道數。
參數初始化
-
Receptive Field:
receptive_field是一個變量,初始化為1,它表示網絡能夠感知的時間序列的寬度。隨著網絡的深入,這個值會增加,表示網絡可以捕捉到更遠的歷史信息。 -
Node Embeddings and Adjacency Matrix Parameters:
self.nodevec_p1,?self.nodevec_p2,?self.nodevec_p3,?self.nodevec_pk: 這些參數是節點嵌入向量和用于構建動態鄰接矩陣的參數,它們在訓練過程中是可學習的。self.nodevec_p1?代表時間相關的節點嵌入,self.nodevec_p2?和?self.nodevec_p3?代表空間相關的節點嵌入,而?self.nodevec_pk?用于構建核心節點之間的關聯,這些參數一起用于構建一個適應性更強的圖結構,使得模型能夠根據輸入數據動態調整節點之間的關聯強度。
通過上述組件和參數的初始化,STPGNN 構建了一個能夠處理時空序列數據的深度學習模型,結合了時間序列分析和圖結構數據處理的優勢,適用于如交通流量預測、環境監測等需要同時考慮時間和空間依賴性的任務。
for b in range(blocks):additional_scope = kernel_size - 1new_dilation = 1for i in range(layers):# dilated convolutionsself.filter_convs.append(nn.Conv2d(in_channels=residual_channels,out_channels=dilation_channels,kernel_size=(1, kernel_size), dilation=new_dilation))self.gate_convs.append(nn.Conv1d(in_channels=residual_channels,out_channels=dilation_channels,kernel_size=(1, kernel_size), dilation=new_dilation))self.residual_convs.append(nn.Conv1d(in_channels=dilation_channels,out_channels=residual_channels,kernel_size=(1, 1)))self.skip_convs.append(nn.Conv1d(in_channels=dilation_channels,out_channels=skip_channels,kernel_size=(1, 1)))self.residual_convs_a.append(nn.Conv1d(in_channels=dilation_channels,out_channels=residual_channels,kernel_size=(1, 1)))self.pgconv.append(pgcn(dilation_channels, residual_channels, dropout, support_len=self.supports_len, order=order, temp=new_dilation))self.gconv.append(gcn(dilation_channels, residual_channels, dropout, support_len=self.supports_len, order=order))if normalization == "batch":self.normal.append(nn.BatchNorm2d(residual_channels))self.normal_a.append(nn.BatchNorm2d(residual_channels))elif normalization == "layer":self.normal.append(nn.LayerNorm([residual_channels, num_nodes, 13 - receptive_field - new_dilation + 1]))self.normal_a.append(nn.LayerNorm([residual_channels, num_nodes, 13 - receptive_field - new_dilation + 1]))new_dilation *= 2receptive_field += additional_scopeadditional_scope *= 2這段代碼是 STPGNN 類初始化方法的一部分,它主要負責構建多層因果卷積塊,這些塊是構成整個網絡的基礎單元。以下是詳細解析:
構建因果卷積塊
- Looping through blocks and layers:
- 外層循環?
for b in range(blocks)?控制著構建的殘差塊數量,每個塊由多個層組成。 - 內層循環?
for i in range(layers)?控制著每個殘差塊內的層數量。
- 外層循環?
卷積層的配置
- Dilated Convolutions:
self.filter_convs?和?self.gate_convs?分別存儲了濾波器和門控機制的擴張卷積層,用于捕捉時間序列數據中的長期依賴關系。擴張卷積(Dilated Convolution)通過增加卷積核之間的空洞來擴大感受野,而無需增加網絡深度或輸入尺寸。self.residual_convs?存儲了用于殘差連接的1x1卷積層,它們用于將輸入與擴張卷積的輸出相加,形成殘差塊的核心部分。self.skip_convs?存儲了用于跳躍連接的1x1卷積層,它們將中間層的輸出傳遞到網絡的最后階段,幫助網絡學習長期依賴。
圖卷積層的配置
- Graph Convolution Layers:
self.pgconv?和?self.gconv?分別存儲了個性化圖卷積(Personalized Graph Convolution)和圖卷積(Graph Convolution)層,用于處理圖結構數據,捕捉節點間的空間依賴性。這些層在每個因果卷積層之后被調用,將時間序列特征與圖結構特征相結合。
歸一化層的配置
- Normalization Layers:
- 根據?
normalization?參數的值,選擇批量歸一化(nn.BatchNorm2d)或層歸一化(nn.LayerNorm)。歸一化層有助于加速訓練過程,減少內部協變量偏移,提高模型的泛化能力。
- 根據?
擴張因子和感受野的更新
- Updating Dilation Factor and Receptive Field:
new_dilation *= 2?更新了擴張因子,每次內層循環都會翻倍,這樣擴張卷積的感受野會隨著層數的增加而指數級增長。receptive_field += additional_scope?和?additional_scope *= 2?更新了網絡的感受野,反映了隨著擴張卷積的深入,網絡能夠捕捉到的時間序列的寬度也在增加。
通過這種方式,STPGNN 構建了一個能夠同時處理時間序列數據和圖結構數據的深度學習模型,能夠捕捉到數據中的長期依賴和空間依賴,非常適合應用于如交通流量預測等需要同時考慮時間和空間因素的任務。
?
def dgconstruct(self, time_embedding, source_embedding, target_embedding, core_embedding):adp = torch.einsum('ai, ijk->ajk', time_embedding, core_embedding)adp = torch.einsum('bj, ajk->abk', source_embedding, adp)adp = torch.einsum('ck, abk->abc', target_embedding, adp)adp = F.softmax(F.relu(adp), dim=2)return adpdef pivotalconstruct(self, x, adj, k):x = x.squeeze(1)x = x.sum(dim=0)y = x.sum(dim=1).unsqueeze(0)adjp = torch.einsum('ij, jk->ik', x[:,:-1], x.transpose(0, 1)[1:,:]) / yadjp = adjp * adjscore = adjp.sum(dim=0) + adjp.sum(dim=1)N = x.size(0)_, topk_indices = torch.topk(score,k)mask = torch.zeros(N, dtype=torch.bool,device=x.device)mask[topk_indices] = Truemasked_matrix = adjp * mask.unsqueeze(1) * mask.unsqueeze(0)adjp = F.softmax(F.relu(masked_matrix), dim=1)return (adjp.unsqueeze(0))這段代碼定義了兩個函數,dgconstruct和pivotalconstruct,它們分別用于構建動態圖結構和識別關鍵節點。
dgconstruct函數接受四個參數:time_embedding(時間嵌入),source_embedding(源節點嵌入),target_embedding(目標節點嵌入),和core_embedding(核心嵌入)。此函數的目標是通過四者間的交互作用來構建動態的鄰接矩陣adp,這個矩陣描述了在特定時間下,源節點與目標節點之間的影響強度。具體步驟如下:
- 首先,使用
torch.einsum函數,將時間嵌入與核心嵌入相乘,生成一個中間矩陣adp。 - 接下來,將源節點嵌入與上一步得到的
adp相乘,進一步細化節點間的影響關系。 - 最后,目標節點嵌入與當前的
adp相乘,完成動態鄰接矩陣的構建。 - 應用ReLU激活函數和Softmax歸一化函數,使矩陣元素非負且按列歸一化,確保每個源節點到所有目標節點的邊權總和為1。
pivotalconstruct函數則用于識別交通網絡中的關鍵節點。它接受三個參數:x(輸入特征矩陣),adj(靜態鄰接矩陣),和k(關鍵節點數量)。以下是詳細步驟:
- 將輸入特征矩陣
x的維度調整,使其變為二維,然后沿列方向求和,得到節點的時間序列特征。 - 對節點的時間序列特征進行行求和,得到節點的總流量,然后將其轉置并擴展維度,便于后續計算。
- 利用
torch.einsum計算節點間的時間序列特征相互作用矩陣adjp,并通過除以節點總流量進行標準化。 - 將
adjp與靜態鄰接矩陣adj相乘,過濾掉不存在物理連接的節點間關系。 - 計算每個節點的“重要性”分數,這是通過將
adjp矩陣的行和列求和得到的。 - 使用
torch.topk函數找到具有最高分數的前k個節點,這些節點即為關鍵節點。 - 創建一個布爾掩碼
mask,用于標記哪些節點是關鍵節點。 - 應用掩碼到
adjp矩陣,僅保留關鍵節點間的關系。 - 最后,對關鍵節點的鄰接矩陣應用ReLU和Softmax,確保矩陣非負且按列歸一化,得到最終的關鍵節點鄰接矩陣
adjp,并增加一個維度以適應后續操作。
通過以上兩個函數,dgconstruct構建了基于動態特征的鄰接矩陣,而pivotalconstruct則識別出了網絡中對交通流動有重要影響的關鍵節點及其相互關系。這兩個矩陣將用于后續的圖神經網絡層,以捕捉交通網絡中的空間和時間依賴性。
def forward(self, inputs, ind):"""input: (B, F, N, T)"""in_len = inputs.size(3)num_nodes = inputs.size(2)if in_len < self.receptive_field:xo = nn.functional.pad(inputs, (self.receptive_field - in_len, 0, 0, 0))else:xo = inputsx = self.start_conv(xo[:, [0]])x_a = self.start_conv_a(xo[:, [0]])skip = 0adj = self.dgconstruct(self.nodevec_p1[ind], self.nodevec_p2, self.nodevec_p3, self.nodevec_pk)pivweight = nn.Parameter(torch.randn(num_nodes, num_nodes).to(x.device), requires_grad=True).to(x.device)adj_p = self.pivotalconstruct(x_a, pivweight, self.topk)supports = [adj]supports_a = [adj_p]for i in range(self.blocks * self.layers):residual = xfilter = self.filter_convs[i](residual)filter = torch.tanh(filter)gate = self.gate_convs[i](residual)gate = torch.sigmoid(gate)x = filter * gatex_a = self.pgconv[i](residual, supports_a)x = self.gconv[i](x, supports)alpha_sigmoid = torch.sigmoid(self.alpha) x = alpha_sigmoid * x_a + (1 - alpha_sigmoid) * xx = x + residual[:, :, :, -x.size(3):]s = xs = self.skip_convs[i](s)if isinstance(skip, int): # B F N Tskip = s.transpose(2, 3).reshape([s.shape[0], -1, s.shape[2], 1]).contiguous()else:skip = torch.cat([s.transpose(2, 3).reshape([s.shape[0], -1, s.shape[2], 1]), skip], dim=1).contiguous()x = self.normal[i](x)x = F.relu(skip)x = F.relu(self.end_conv_1(x))x = self.end_conv_2(x)return x這段代碼實現了一個深度學習模型的前向傳播過程,該模型被設計用于處理時序數據,如交通流量預測。模型的輸入是一個四維張量,形狀為(B, F, N, T),其中B代表批量大小,F代表特征數,N代表節點數,T代表時間步長。模型的架構包含了卷積、門控機制、殘差連接、跳過連接以及圖神經網絡組件。
-
輸入預處理:
- 首先檢查輸入的時間長度T是否小于模型的受感野(receptive_field),如果小于,則使用
nn.functional.pad對輸入進行填充,確保輸入的時間序列長度滿足要求。
- 首先檢查輸入的時間長度T是否小于模型的受感野(receptive_field),如果小于,則使用
-
起始卷積:
- 使用
start_conv和start_conv_a進行起始卷積,分別對輸入的首個特征通道進行處理,得到x和x_a。
- 使用
-
動態圖構建:
dgconstruct函數用于構建動態鄰接矩陣,根據節點特征構建圖結構。這將用于圖卷積操作。pivotalconstruct函數用于構建關鍵節點圖,它使用x_a和關鍵節點權重矩陣pivweight來構造關鍵節點的鄰接矩陣adj_p。
-
多層殘差模塊:
- 模型包含多個殘差塊,每個殘差塊由多層組成。每層首先應用殘差連接,之后進行卷積操作,包括濾波器和門控機制。
- 濾波器和門控卷積的結果分別經過tanh和sigmoid激活函數,之后相乘,產生門控信號控制信息流。
- 使用
pgconv進行關鍵節點圖上的卷積,并使用gconv進行常規圖卷積。 - 引入一個可學習的參數alpha_sigmoid,通過sigmoid函數得到一個0到1之間的值,用于加權融合關鍵節點圖卷積和常規圖卷積的結果。
- 結果再與殘差項相加,之后進行跳過連接,將結果存儲在skip變量中,用于后續的跳躍連接操作。
-
跳躍連接與輸出:
- 跳躍連接將每一層的輸出收集起來,進行整合,形成skip變量。
- 經過跳躍連接后,結果經過
end_conv_1和end_conv_2卷積層處理,最終得到模型的輸出。
整個模型通過這種結構能夠同時捕捉空間和時間依賴性,特別是在處理像交通流量預測這樣的問題時,它能有效利用圖結構和時序特性,從而做出更準確的預測。

)


常見表引擎)




RCP第三方庫的引入方式)



)


![[力扣題解] 700. 二叉搜索樹中的搜索](http://pic.xiahunao.cn/[力扣題解] 700. 二叉搜索樹中的搜索)

)
)