目錄
- 協同過濾
- 基于用戶的協同過濾
- 背后的思想
- 原理
- 實踐
- 1、構造矩陣
- 2、相似度計算
- 3、推薦計算
- 4、一些改進
- 應用場景:
- 總結
談及推薦系統,不得不說大名鼎鼎的協同過濾。協同過濾的重點在于協同,所謂協同,也就是群體互幫互助,互相支持是群體智慧的體現,協同過濾也是這般簡單直接,歷久彌新。
協同過濾
當你的推薦系統過了只能使用基于內容的推薦階段后,就有了可觀的用戶行為了。這時候的用戶行為通常是正向的,也就是用戶或明或暗地表達著喜歡的行為。這些行為可以表達成一個用戶和物品的關系矩陣,或是網絡,或是圖,本質是一個東西。
這個用戶物品關系矩陣中填充的就是用戶對物品的態度,但并不是每個位置都有,需要的就是把那些還沒有的地方填充起來。這個關系矩陣是協同過濾的關鍵,一切都圍繞它來進行;
協同過濾是一個比較大的算法范疇。通常劃分為兩類;
1、基于記憶的協同過濾(Memory-Based)
2、基于模型的協同過濾(Model-Based)
基于記憶的協同過濾,就是記住每個人消費過什么東西,然后推薦相似的東西,或者推薦相似的人消費的東西。基于模型的協同過濾則是從用戶物品關系矩陣中去學習一個模型,從而把那些矩陣空白處填滿;
今天先講一下基于基于的協同過濾的一種:基于用戶,或者叫做User-Based;
基于用戶的協同過濾
背后的思想
你有沒有過這種感覺,你遇到一個人,你發現你喜歡的書,他也喜歡,你喜歡的音樂,他也在聽,你喜歡看的電影,他也至少看了兩三遍,你們這叫什么,志同道合。所以問題來了,他又看了一本書,又聽了一首歌,你會不會正好也喜歡呢?
這個感覺非常的自然,這就是基于用戶的協同過濾背后的思想。詳細來說就是:先根據歷史消費行為幫你找到一群和你口味相似的用戶,然后根據這些和你很相似的用戶消費了什么新的、你沒見過的物品、都可以推薦給你。
這就是我們常說的物以類聚人以群分,你是什么人,你就會遇到什么人。
這其實也是一個用戶聚類的過程,把用戶按照興趣口味聚類成不同的群體,給用戶產生的推薦就來自這個群體的平均值;所以要做好這個推薦,關鍵是如何量化口味相似這個指標。
原理
我們來說一下基于用戶的協同過濾具體是怎么做的,核心是那個用戶物品的關系矩陣,這個矩陣是最原始的材料。
第一步,準備用戶向量,從這個矩陣中,理論上可以給每一個用戶得到一個向量 。為什么說要是理論上呢?因為得到向量的前提是:用戶需要在我們產品里有行為數據,否則就得不到這個向量。
這個向量有這么三個特點:
1、向量的維度就是物品的個數;
2、向量是稀疏的,也就是說并不是每個位置都有值;
3、向量維度上的取值可以是簡單的0或1,1表示喜歡過,0表示沒有;
第二步,用每一個用戶的向量,兩兩計算用戶之間的相似度,設定一個相似度閾值,為每個用戶保留與其最相似的用戶。
第三步,為每一個用戶產生推薦結果。
把和他相似的用戶們喜歡過的物品匯總起來,去掉用戶自己已經消費過的物品,剩下的排序輸出就是推薦結果。
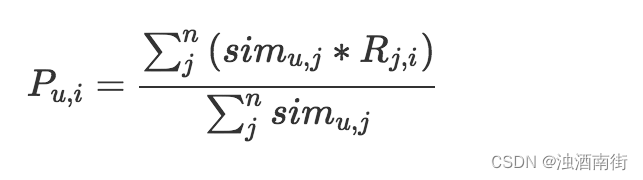
這個公式,等號左邊就是計算一個物品i和一個用戶u的匹配分數,等號右邊是這個分數的計算過程,分母是把用戶u相似的n個用戶的相似度累加起來分子是把這n個用戶各自對物品i的態度,按照相似度加權求和。這里的態度最簡單就是0或1,1表示喜歡過,0表示沒有,如果是評分,則可以是0到5的取值。整個公式就是相似用戶們的態度加權平均值。
實踐
原理看上去很簡單,但是在實現上卻有一些坑,需要非常小心;
1、只有原始的用戶行為日志,需要從中構造矩陣,怎么做?
2、如果用戶的向量很長,計算一個相似度則耗時很久,怎么辦?
3、如果用戶量很大,而且通常如此,而且兩兩計算用戶相似度也是一個大坑,怎么辦?
4、在計算推薦時,看上去要為每一個用戶計算他和每一個物品的分數,又是一個大坑,怎么辦?
1、構造矩陣
我們在做協同過濾計算時,所用的矩陣是稀疏的,也就是說很多矩陣元素不用存,都是0,這里介紹典型的稀疏矩陣存儲格式。
1.CSR:這個存儲稍微復雜點,是一個整體編碼方式。它有三個組成:數值,列號和行偏移共同編碼。COO
2.COO:這個存儲方式很簡單,每個元素由三元組表示(行號,列號,數值),只存儲有值的元素,缺失值不存儲。
這些存儲格式,在常見的計算框架里面都是標準的,如Spark中,Python的Numpy包中。把你的原始行為日志轉換為上述的格式,就可以使用常用的計算框架的標準輸入了。
2、相似度計算
相似度計算是個問題。
首先是單個相似度計算問題,如果碰上向量很長,無論什么相似度計算方法,都要遍歷向量。所以通常下降相似度計算復雜度的辦法有兩種。
1、對向量采樣計算。如果兩個100維向量的相似度是0.7,我們犧牲一些精度,隨機從取出10維計算,以得到的值作為其相似度值,雖然精度下降,但執行效率明顯快了很多。這個算法由Twitter提出,叫做DIMSUM算法,已經在spark中實現了。
2、向量化計算,與其說是一個技巧,不如說是一種思維。在機器學習領域,向量之間的計算時家常便飯,現代的線性代數庫都支持直接的向量計算,比循環快很多。一些常用的向量庫都天然支持,比如python中的numpy庫。
其次的問題就是,如果用戶量很大,兩兩之間計算代價很大。
有兩個辦法來緩解這個問題:
第一個辦法是:將相似度拆成Map Reduce任務,將原始矩陣Map成鍵為用戶對,值為兩個用戶對同一個物品的評分之積,Reduce階段對這些乘積再求和,map reduce任務結束后再對這些值歸一化;
第二個辦法是:不用基于用戶的協同過濾。
這種計算對象兩兩之間的相似度的任務,如果數據量不大,而且矩陣還是稀疏的,有很多工具可以使用:比如KGraph 、GraphCHI等;
3、推薦計算
得到用戶之間的相似度之后,接下來就是計算推薦分數。顯然未每一個用戶計算每一個物品的推薦分數,這個代價有點大。不過,有幾點我們可以來利用一下:
1.只有相似用戶喜歡過的物品才需要計算,這樣就減少很多物品量。
2、把計算過程拆成Map Reduce 任務。
拆Map Reduce任務的做法是:
1、遍歷每個用戶喜歡的用戶列表;
2、獲取該用戶的相似用戶列表;
3、把每一個喜歡的物品Map成兩個記錄發射出去,一個鍵為<相似用戶ID,物品ID,1>三元組,值為<相似度>,另一個鍵為<相似用戶ID,物品ID,0>三元組,值為<喜歡程度相似度>,其中1和0是為了區分兩者,會在最后一步中用到。
4、Reduce階段,求和后輸出;
5、<相似用戶ID,物品ID,0>的值除以<相似用戶ID,物品ID,1>的值
因為map過程,其實就是將原來耦合的計算過程解耦了,這樣的話我們可以利用多線程技術實現Map效果。
4、一些改進
對于基于用戶的協同過濾有一些常用的改進辦法,改進主要集中在用戶對物品的喜歡程度上:
1.懲罰對熱門物品的喜歡程度,這是因為熱門的東西很難反應出用戶的真實興趣,更可能是被煽動,或者無聊隨便點擊的情形,這是群體行為的常見特點。
2.增加喜歡程度的時間衰減,一般使用一個指數函數,指數是一個負數,值和喜歡行為發生時間間隔正相關即可,比如 e ( ? x ) e^{(-x)} e(?x),x代表喜歡時間距今的時間間隔。
應用場景:
最后說一下基于用戶的協同過濾有哪些應用場景。基于用戶的協同過濾有兩個產出:
1、相似用戶列表
2、基于用戶的推薦結果
所以,我們不僅可以推薦物品,還可以推薦用戶,比如我們在一些社交平臺看到的,相似粉絲、和你口味類似的人等等都可以這樣計算。
對于這個方法計算出來的推薦結果本身,由于是基于口味計算得出,所以在更強調個人隱私場景中應用更佳,在這樣的場景下,不受大v影響,更能反應真實的興趣群體。
總結
今天,我與你聊了基于用戶的協同過濾方法,也順便普及了一下協同過濾這個大框架的思想。基于用戶的協同過濾算法非常簡單,但非常有效。
在實現這個方法時,有許多需要注意的地方,比如:
1、相似度計算本身如果遇到超大維度向量怎么辦?
2、兩兩計算用戶相似度遇到用戶量很大時怎么辦?
同時,我也聊到了如何改進這個推薦算法,希望能夠幫到你。
















![如何從小米手機傳輸文件到電腦? [5個簡單的方法]](http://pic.xiahunao.cn/如何從小米手機傳輸文件到電腦? [5個簡單的方法])


