Render 階段會生成 Fiber Tree,所謂的 diff 實際上就是發生在這個階段,這里的 diff 指的是 current FiberNode 和 JSX 對象之間進行對比,然后生成新的的 wip FiberNode。
除了 React 以外,其他使用到了虛擬 DOM 的前端框架也會有類似的流程,比如 Vue 里面將這個流程稱之為 patch。
diff 算法本身是有性能上面的消耗,在 React 文檔中有提到,即便采用最前沿的算法,如果要完整的對比兩棵樹,那么算法的復雜度都會達到 O(n^3),n 代表的是元素的數量,如果 n 為 1000,要執行的計算量會達到十億量級的級別。
因此,為了降低算法的復雜度,React 為 diff 算法設置了 3 個限制:
- 限制一:只對同級別元素進行 diff,如果一個 DOM 元素在前后兩次更新中跨越了層級,那么 React 不會嘗試復用它
- 限制二:兩個不同類型的元素會產生不同的樹。比如元素從 div 變成了 p,那么 React 會直接銷毀 div 以及子孫元素,新建 p 以及 p 對應的子孫元素
- 限制三:開發者可以通過 key 來暗示哪些子元素能夠保持穩定
更新前:
<div><p key="one">one</p><h3 key="two">two</h3>
</div>更新后
<div><h3 key="two">two</h3><p key="one">one</p>
</div>如果沒有 key,那么 React 就會認為 div 的第一個子元素從 p 變成了 h3,第二個子元素從 h3 變成了 p,因此 React 就會采用限制二的規則。
但是如果使用了 key,那么此時的 DOM 元素是可以復用的,只不過前后交換了位置而已。
接下來我們回頭再來看限制一,對同級元素進行 diff,究竟是如何進行 diff ?整個 diff 的流程可以分為兩大類:
- 更新后只有一個元素,此時就會根據 newChild 創建對應的 wip FiberNode,對應的流程就是單節點 diff
- 更新后有多個元素,此時就會遍歷 newChild 創建對應的 wip FiberNode 以及它的兄弟元素,此時對應的流程就是多節點 diff
單節點 diff
單節點指的是新節點為單一節點,但是舊節點的數量是不一定
單節點 diff 是否能夠復用遵循以下的流程:
- 步驟一 :判斷 key 是否相同
- 如果更新前后沒有設置 key,那么 key 就是 null,也是屬于相同的情況
- 如果 key 相同,那么就會進入到步驟二
- 如果 key 不同,就不需要進入步驟二,無需判斷 type,結果直接為不能復用(如果有兄弟節點還會去遍歷兄弟節點)
- 步驟二 :如果 key 相同,再判斷 type 是否相同
- 如果 type 相同,那么就復用
- 如果 type 不同,無法復用(并且兄弟節點也一并標記為刪除)
更新前
<ul><li>1</li><li>2</li><li>3</li>
</ul>更新后
<ul><p>1</p>
</ul>這里因為沒有設置 key,所以會被設為 key 是相同的,接下來就會進入到 type 的判斷,此時發現 type 不同,因此不能夠復用。既然這里唯一的可能性都已經不能夠復用,會直接標記兄弟 FiberNode 為刪除狀態。
如果上面的例子中,key 不同只能代表當前的 FiberNode 無法復用,因此還需要去遍歷兄弟的 FiberNode
下面我們再來看一些示例
更新前
<div>one</div>更新后
<p>one</p>沒有設置 key,那么可以認為默認 key 就是 null,更新前后兩個 key 是相同的,接下來就查看 type,發現 type 不同,因此不能復用。
更新前
<div key="one">one</div>更新后
<div key="two">one</div>更新前后 key 不同,不需要再判斷 type,結果為不能復用
更新前
<div key="one">one</div>更新后
<p key="two">one</p>更新前后 key 不同,不需要再判斷 type,結果為不能復用
更新前
<div key="one">one</div>更新后
<div key="one">two</div>首先判斷 key 相同,接下來判斷 type 發現也是相同,這個 FiberNode 就能夠復用,children 是一個文本節點,之后將文本節點更新即可。
多節點 diff
所謂多節點 diff,指的是新節點有多個。
React 團隊發現,在日常開發中,對節點的更新操作的情況往往要多余對節點“新增、刪除、移動”,因此在進行多節點 diff 的時候,React 會進行兩輪遍歷:
- 第一輪遍歷會嘗試逐個的復用節點
- 第二輪遍歷處理上一輪遍歷中沒有處理完的節點
第一輪遍歷
第一輪遍歷會從前往后依次進行遍歷,存在三種情況:
- 如果新舊子節點的key 和 type 都相同,說明可以復用
- 如果新舊子節點的 key 相同,但是 type 不相同,這個時候就會根據 ReactElement 來生成一個全新的 fiber,舊的 fiber 被放入到 deletions 數組里面,回頭統一刪除。但是注意,此時遍歷并不會終止
- 如果新舊子節點的 key 和 type 都不相同,或者key不同時,導致不能復用,結束遍歷
示例一
更新前
<div><div key="a">a</div><div key="b">b</div><div key="c">c</div><div key="d">d</div>
</div>更新后
<div><div key="a">a</div><div key="b">b</div><div key="e">e</div><div key="d">d</div>
</div>首先遍歷到 div.key.a,發現該 FiberNode 能夠復用

繼續往后面走,發現 div.key.b 也能夠復用
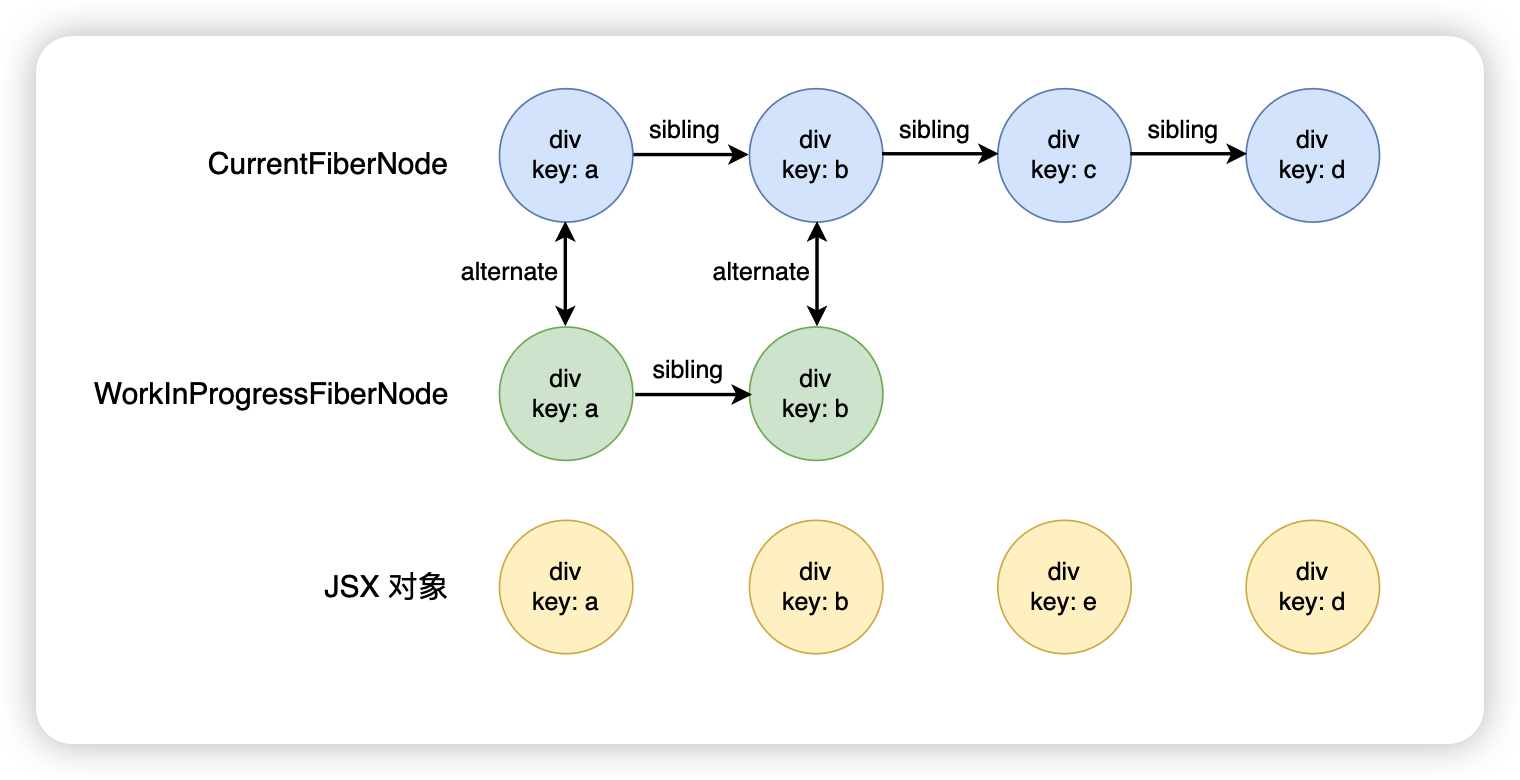
接下來繼續往后面走,div.key.e,這個時候發現 key 不一樣,因此第一輪遍歷就結束了

示例二
更新前
<div><div key="a">a</div><div key="b">b</div><div key="c">c</div><div key="d">d</div>
</div>更新后
<div><div key="a">a</div><div key="b">b</div><p key="c">c</p><div key="d">d</div>
</div>首先和上面的一樣,div.key.a 和 div.key.b 這兩個 FiberNode 可以進行復用,接下來到了第三個節點,此時會發現 key 是相同的,但是 type 不相同,此時就會將對應的舊的 FiberNode 放入到一個叫 deletions 的數組里面,回頭統一進行刪除,根據新的 React 元素創建一個新的 FiberNode,但是此時的遍歷是不會結束的
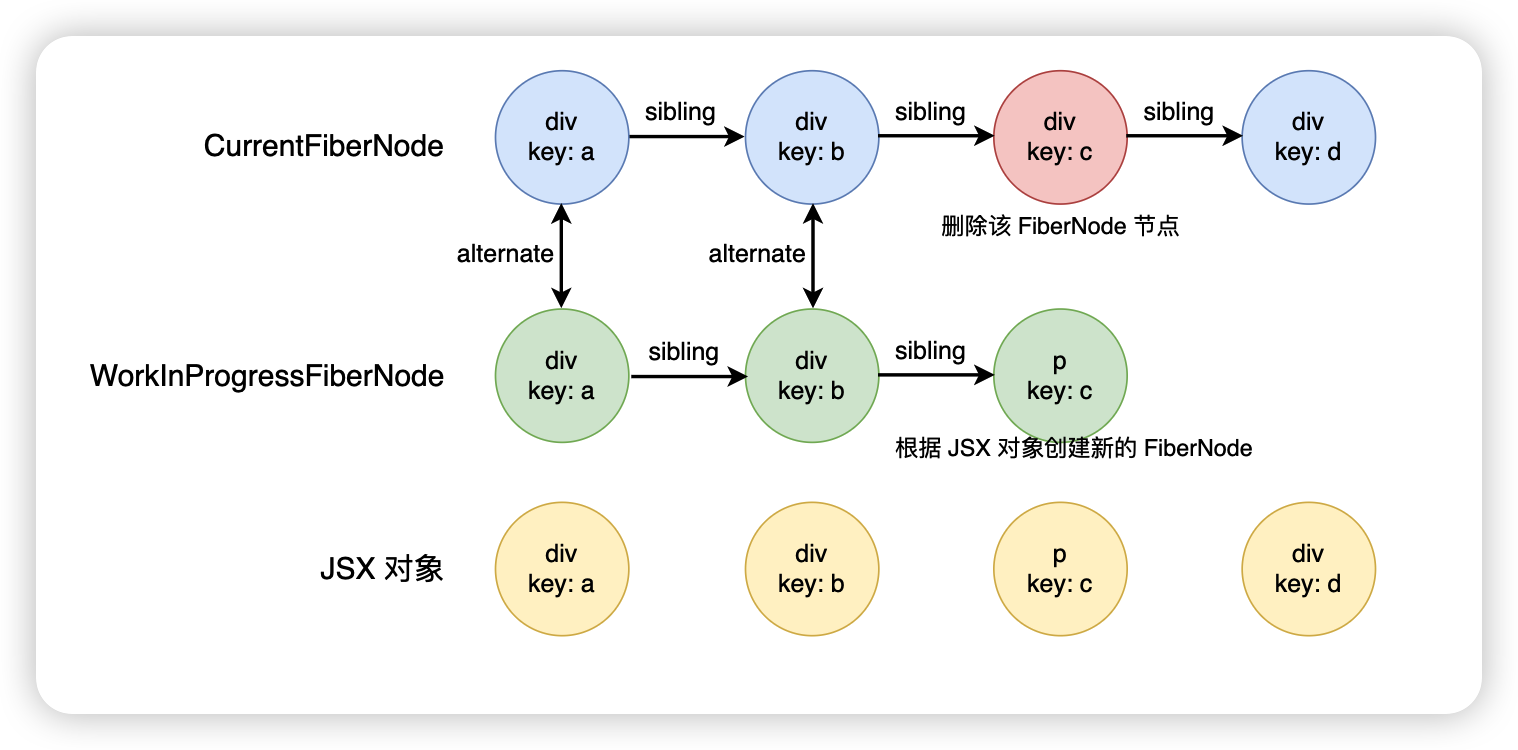
接下來繼續往后面進行遍歷,遍歷什么時候結束呢?
- 到末尾了,也就是說整個遍歷完了
- 或者是和示例一相同,可以 key 不同
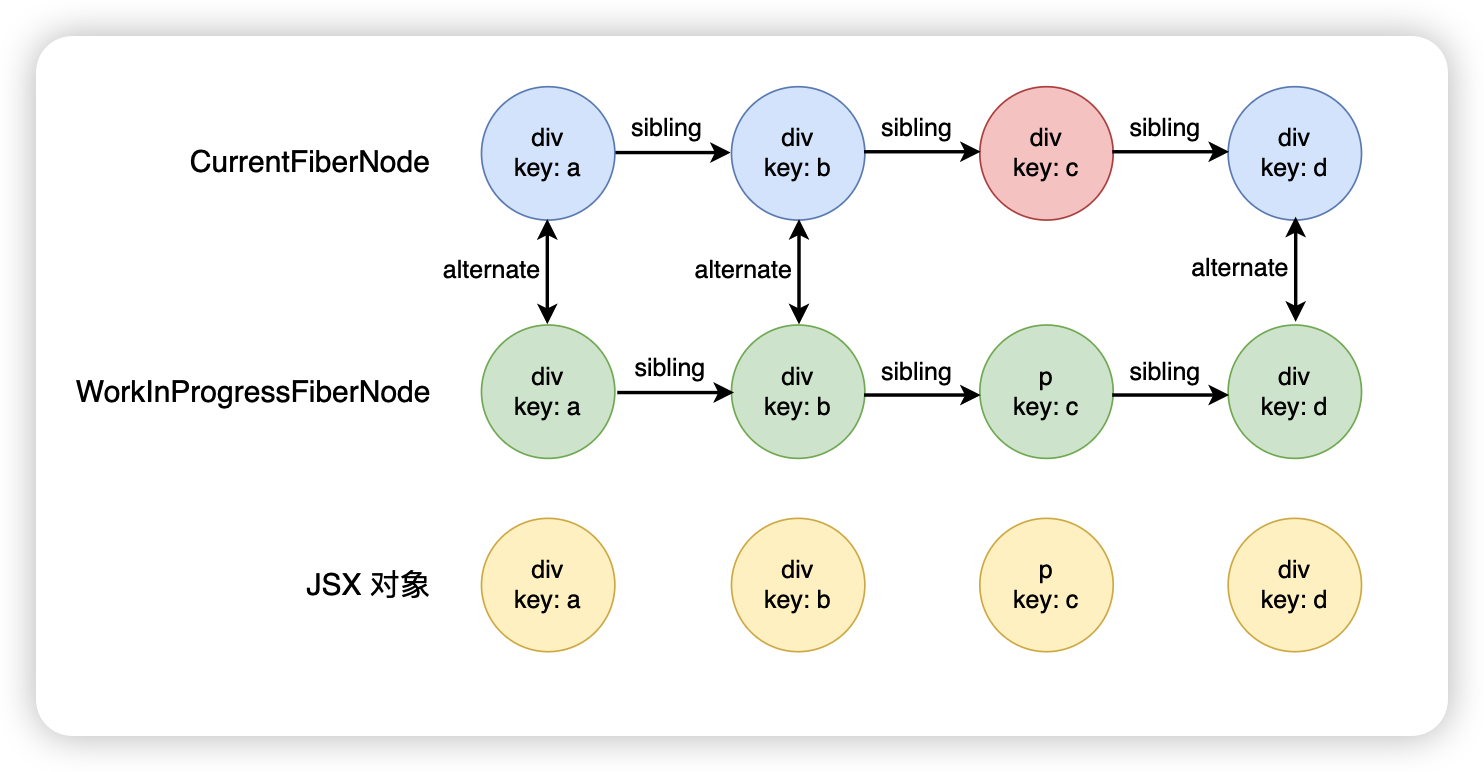
第二輪遍歷
如果第一輪遍歷被提前終止了,那么意味著有新的 React 元素或者舊的 FiberNode 沒有遍歷完,此時就會采用第二輪遍歷
第二輪遍歷會處理這么三種情況:
- 只剩下舊子節點:將舊的子節點添加到 deletions 數組里面之后統一刪除掉(刪除的情況)
- 只剩下新的 JSX 元素:根據 ReactElement 元素來創建 FiberNode 節點(新增的情況)
- 新舊子節點都有剩余:會將剩余的 FiberNode 節點放入一個 map 里面,遍歷剩余的新的 JSX 元素,然后從 map 中去尋找能夠復用的 FiberNode 節點,如果能夠找到,就拿來復用。(移動的情況)
- 如果不能找到,就新增唄。然后如果剩余的 JSX 元素都遍歷完了,map 結構中還有剩余的 Fiber 節點,就將這些 Fiber 節點添加到 deletions 數組里面,之后統一做刪除操作
只剩下舊子節點
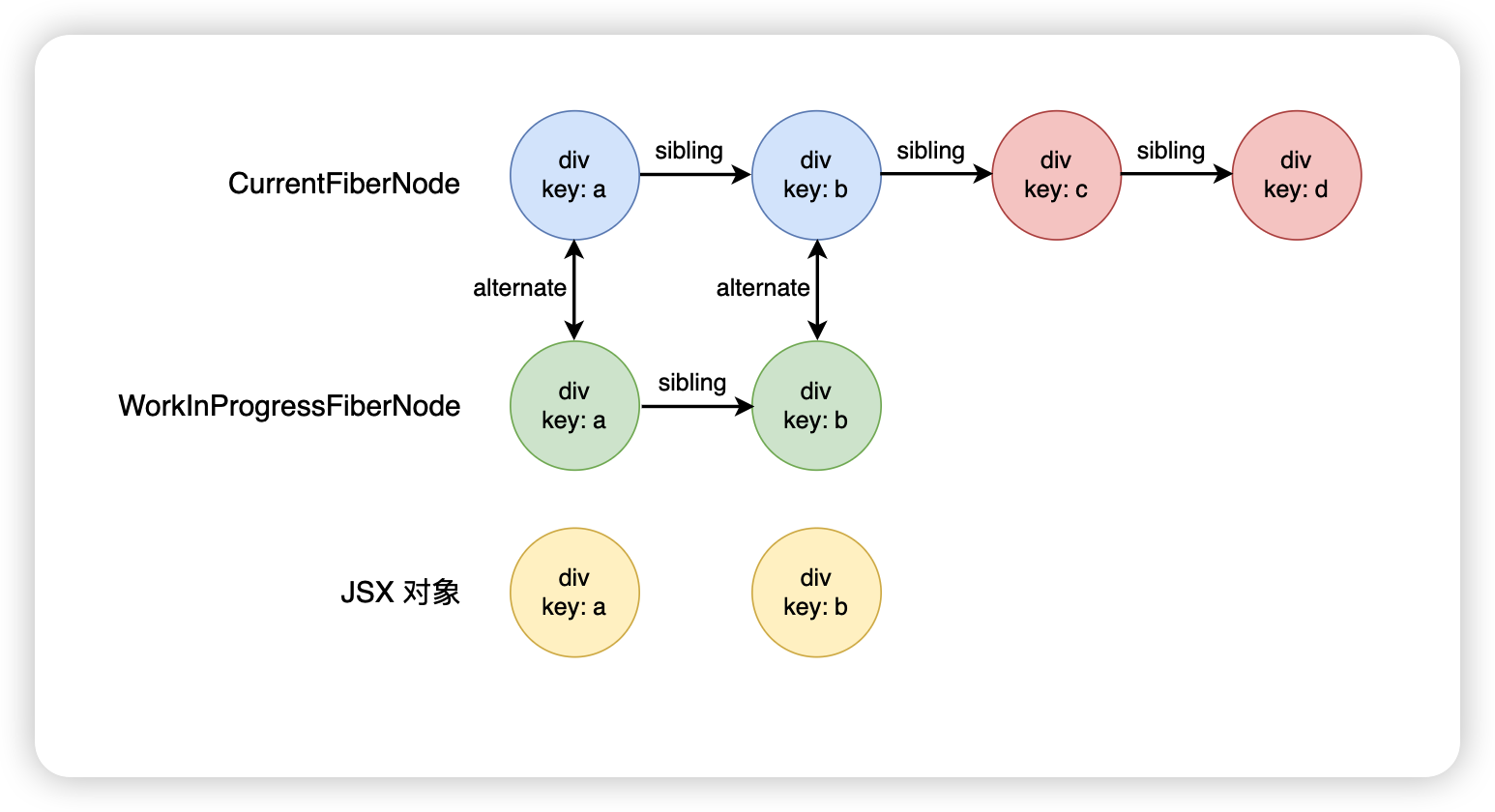
更新前
<div><div key="a">a</div><div key="b">b</div><div key="c">c</div><div key="d">d</div>
</div>更新后
<div><div key="a">a</div><div key="b">b</div>
</div>遍歷前面兩個節點,發現能夠復用,此時就會復用前面的節點,對于 React 元素來講,遍歷完前面兩個就已經遍歷結束了,因此剩下的FiberNode就會被放入到 deletions 數組里面,之后統一進行刪除
只剩下新的 JSX 元素
更新前
<div><div key="a">a</div><div key="b">b</div>
</div>更新后
<div><div key="a">a</div><div key="b">b</div><div key="c">c</div><div key="d">d</div>
</div>根據新的 React 元素新增對應的 FiberNode 即可。
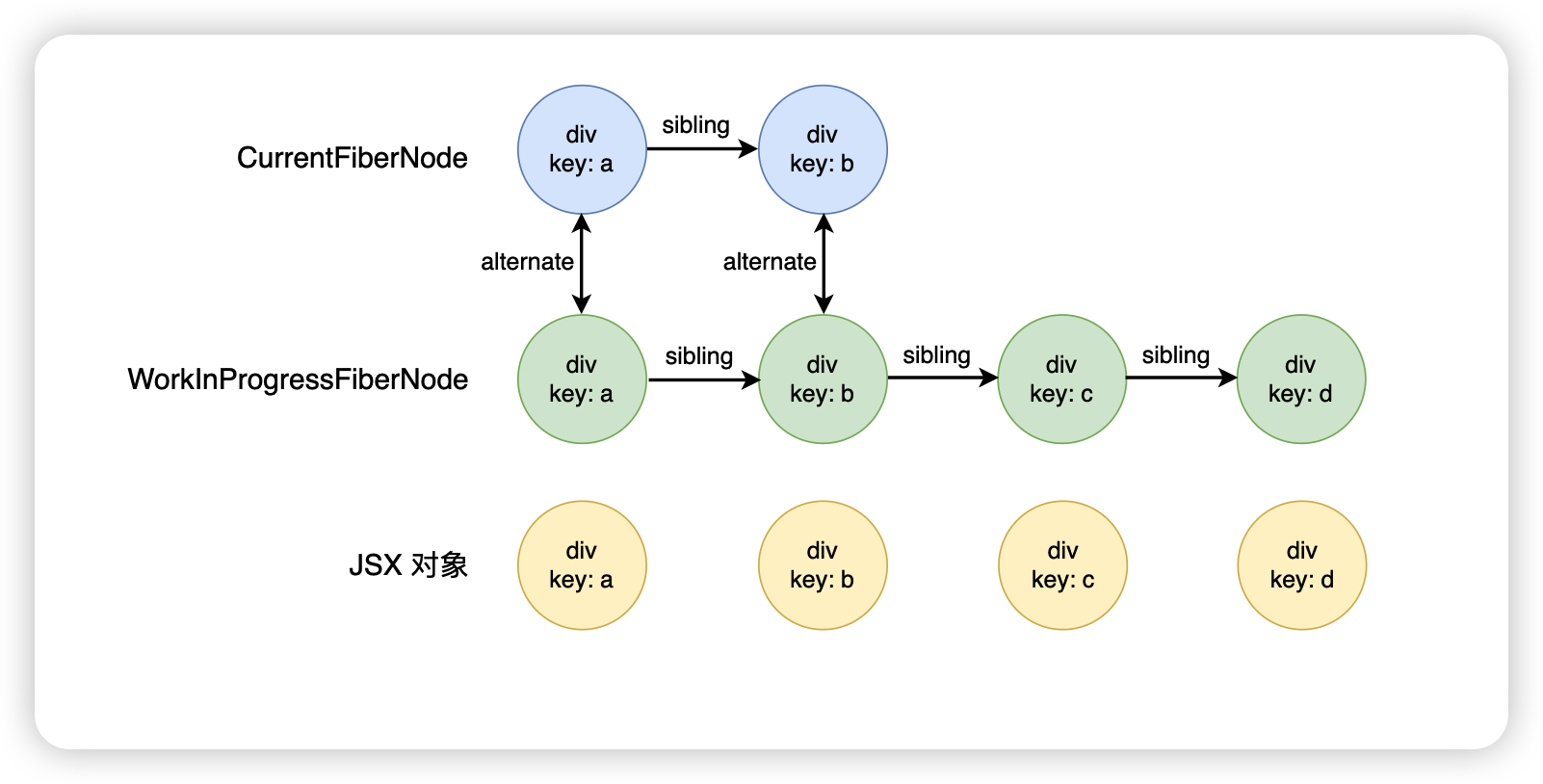
新舊子節點都有剩余(移動)
更新前
<div><div key="a">a</div><div key="b">b</div><div key="c">c</div><div key="d">d</div>
</div>更新后
<div><div key="a">a</div><div key="c">b</div><div key="b">b</div><div key="e">e</div>
</div>首先會將剩余的舊的 FiberNode 放入到一個 map 里面
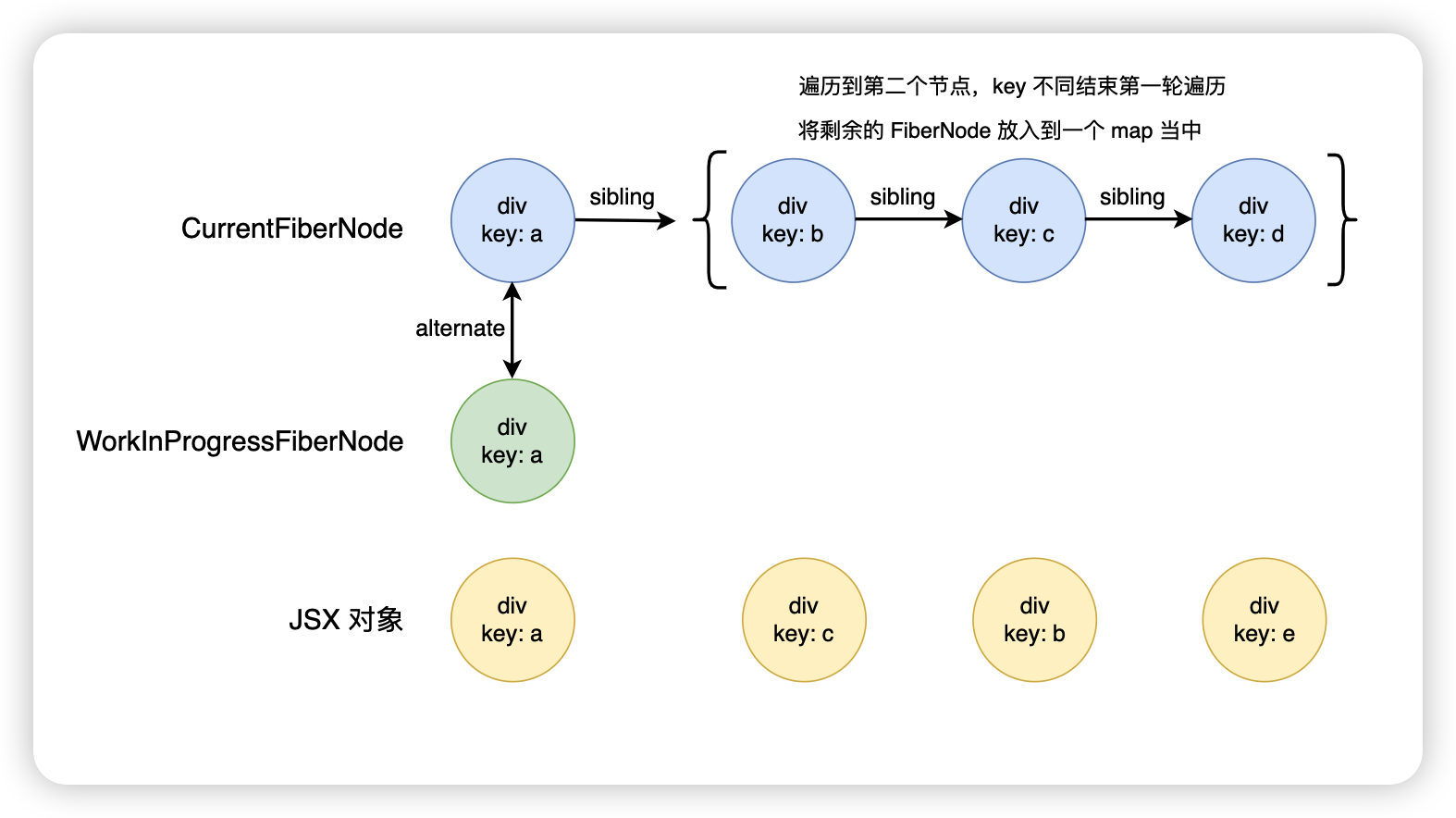
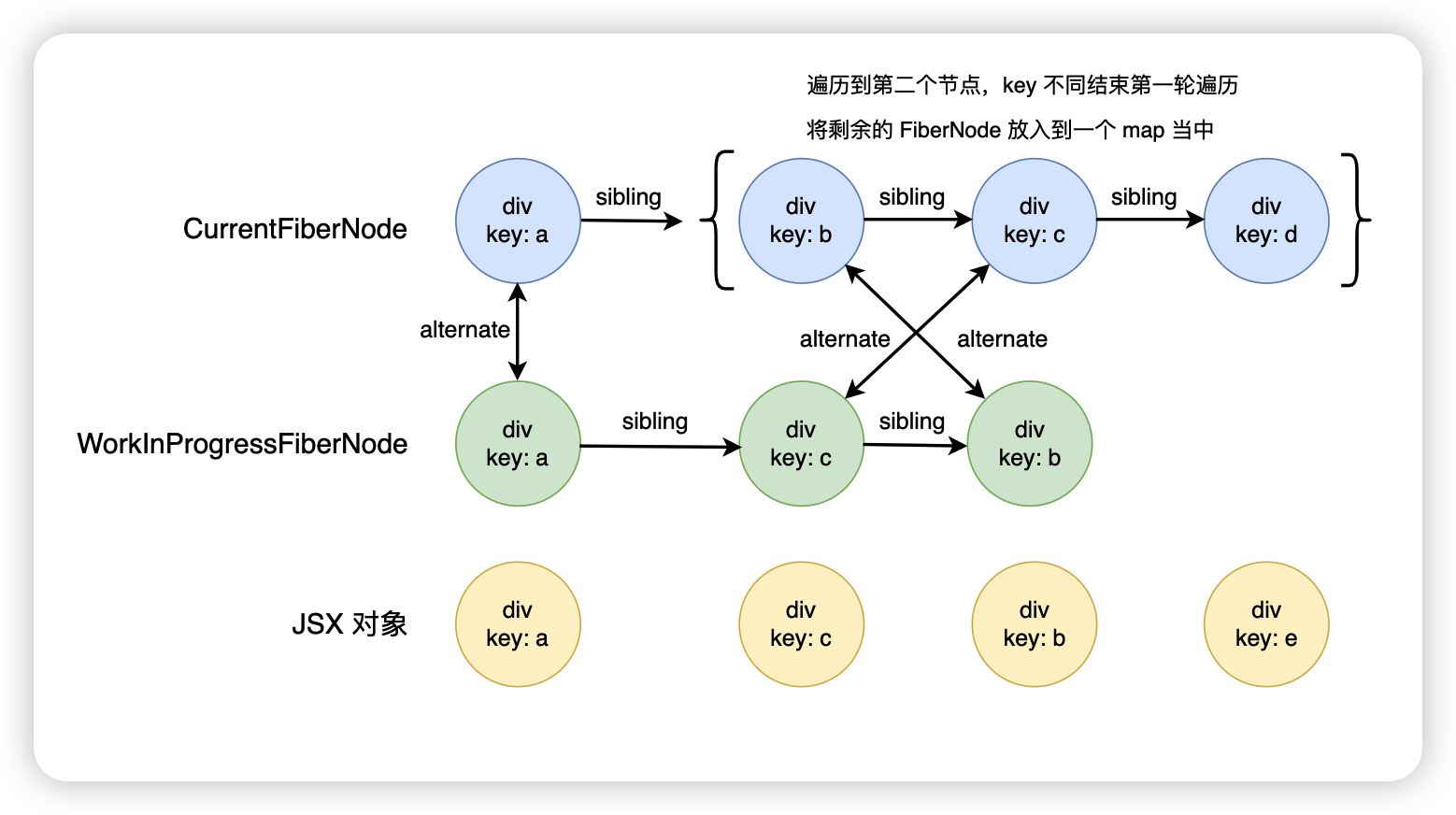
接下來會繼續去遍歷剩下的 JSX 對象數組,遍歷的同時,從 map 里面去找有沒有能夠復用
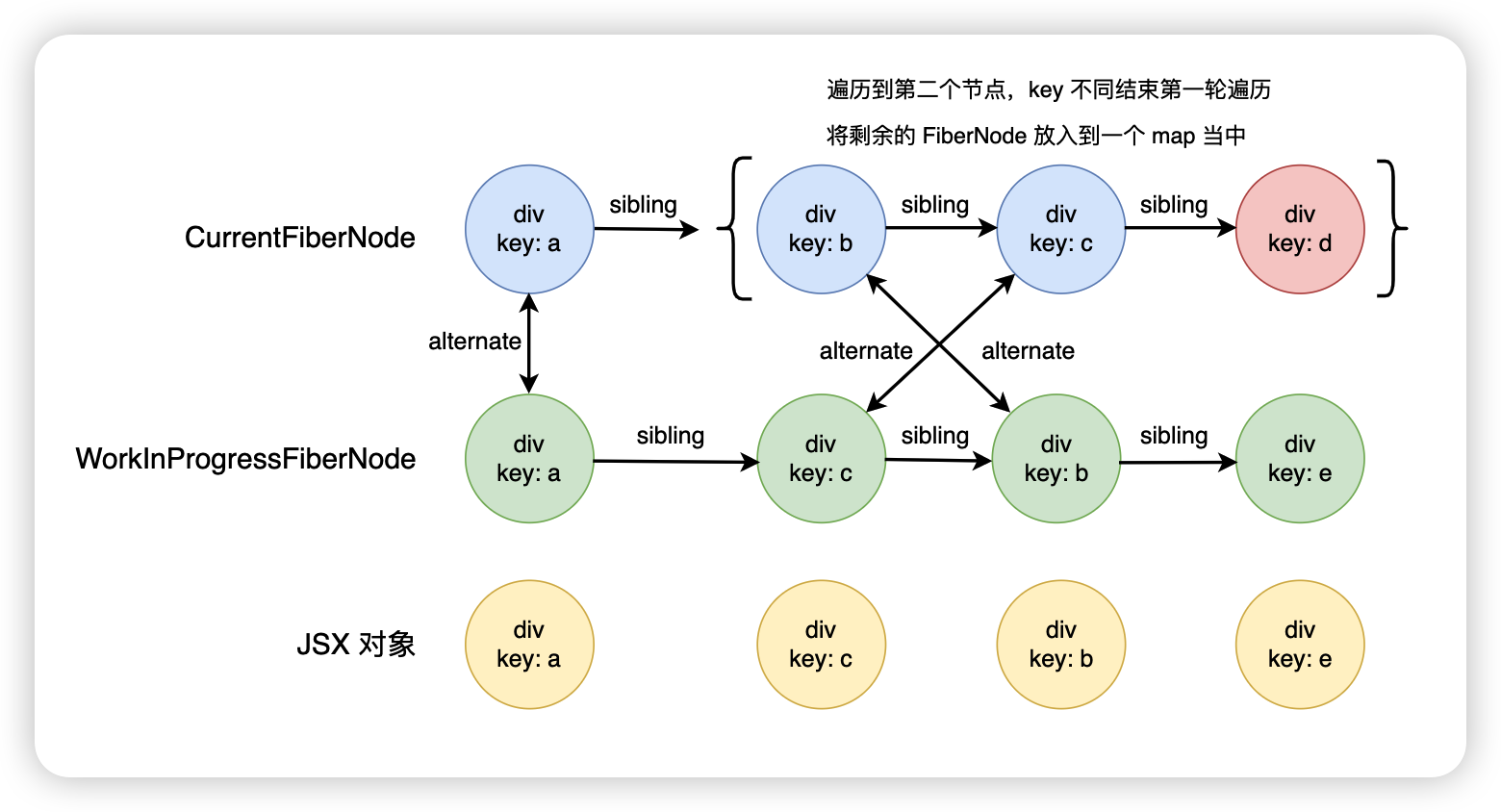
如果在 map 里面沒有找到,那就會新增這個 FiberNode,如果整個 JSX 對象數組遍歷完成后,map 里面還有剩余的 FiberNode,說明這些 FiberNode 是無法進行復用,直接放入到 deletions 數組里面,后期統一進行刪除。
雙端對比算法
所謂雙端,指的是在新舊子節點的數組中,各用兩個指針指向頭尾的節點,在遍歷的過程中,頭尾兩個指針同時向中間靠攏。
因此在新子節點數組中,會有兩個指針,newStartIndex 和 newEndIndex 分別指向新子節點數組的頭和尾。在舊子節點數組中,也會有兩個指針,oldStartIndex 和 oldEndIndex 分別指向舊子節點數組的頭和尾。
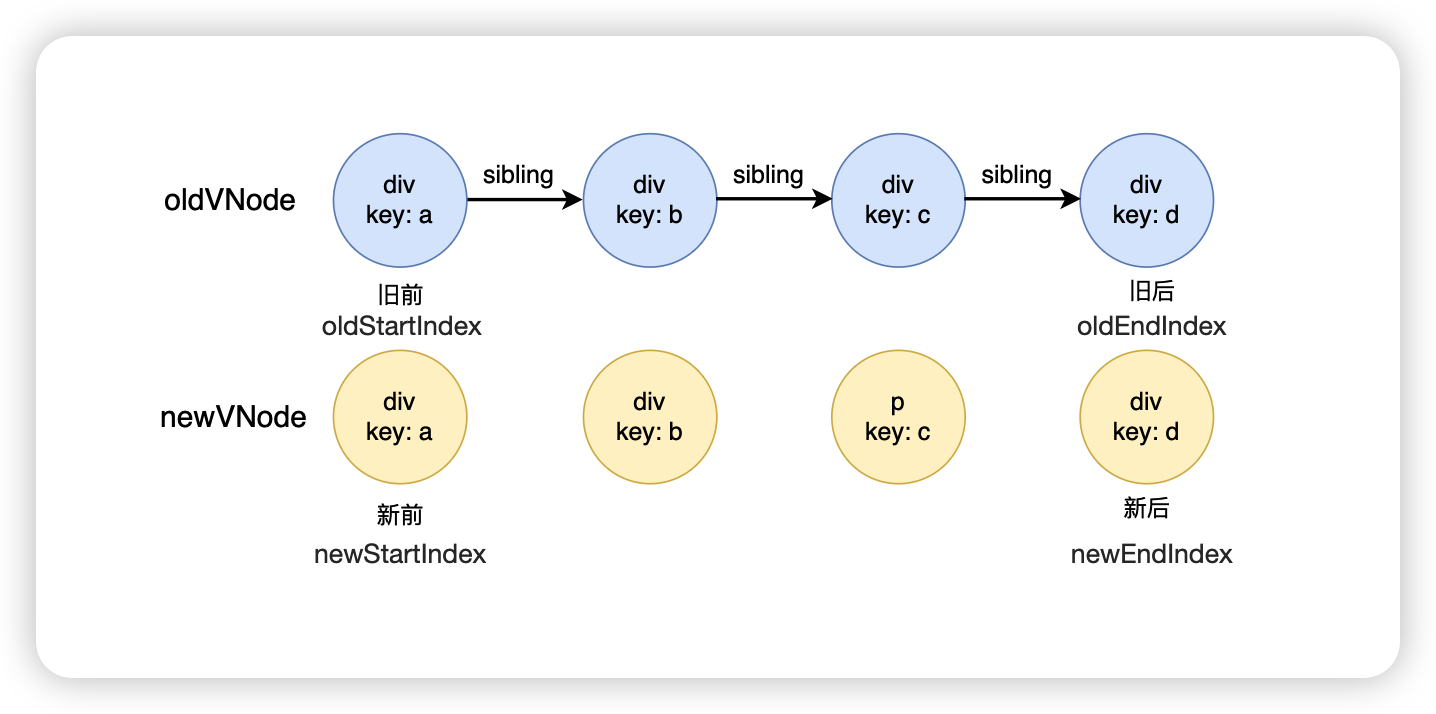
每遍歷到一個節點,就嘗試進行雙端比較:「新前 vs 舊前」、「新后 vs 舊后」、「新后 vs 舊前」、「新前 vs 舊后」,如果匹配成功,更新雙端的指針。比如,新舊子節點通過「新前 vs 舊后」匹配成功,那么 newStartIndex += 1,oldEndIndex -= 1。
如果新舊子節點通過「新后 vs 舊前」匹配成功,還需要將「舊前」對應的 DOM 節點插入到「舊后」對應的 DOM 節點之前。如果新舊子節點通過「新前 vs 舊后」匹配成功,還需要將「舊后」對應的 DOM 節點插入到「舊前」對應的 DOM 節點之前。
React不使用雙端算法的原因
實際上在 React 的源碼中,解釋了為什么不使用雙端 diff
function reconcileChildrenArray(
returnFiber: Fiber,currentFirstChild: Fiber | null,newChildren: Array<*>,expirationTime: ExpirationTime,
): Fiber | null {// This algorithm can't optimize by searching from boths ends since we// don't have backpointers on fibers. I'm trying to see how far we can get// with that model. If it ends up not being worth the tradeoffs, we can// add it later.// Even with a two ended optimization, we'd want to optimize for the case// where there are few changes and brute force the comparison instead of// going for the Map. It'd like to explore hitting that path first in// forward-only mode and only go for the Map once we notice that we need// lots of look ahead. This doesn't handle reversal as well as two ended// search but that's unusual. Besides, for the two ended optimization to// work on Iterables, we'd need to copy the whole set.// In this first iteration, we'll just live with hitting the bad case// (adding everything to a Map) in for every insert/move.// If you change this code, also update reconcileChildrenIterator() which// uses the same algorithm.
}將上面的注視翻譯成中文如下:
由于雙端 diff 需要向前查找節點,但每個 FiberNode 節點上都沒有反向指針,即前一個 FiberNode 通過 sibling 屬性指向后一個 FiberNode,只能從前往后遍歷,而不能反過來,因此該算法無法通過雙端搜索來進行優化。
React 想看下現在用這種方式能走多遠,如果這種方式不理想,以后再考慮實現雙端 diff。React 認為對于列表反轉和需要進行雙端搜索的場景是少見的,所以在這一版的實現中,先不對 bad case 做額外的優化。
總結
diff 計算發生在更新階段,當第一次渲染完成后,就會產生 Fiber 樹,再次渲染的時候(更新),就會拿新的 JSX 對象(vdom)和舊的 FiberNode 節點進行一個對比,再決定如何來產生新的 FiberNode,它的目標是盡可能的復用已有的 Fiber 節點。這個就是 diff 算法。
在 React 中整個 diff 分為單節點 diff 和多節點 diff。
所謂單節點是指新的節點為單一節點,但是舊節點的數量是不一定的。
單節點 diff 是否能夠復用遵循如下的順序:
- 判斷 key 是否相同
- 如果更新前后均未設置 key,則 key 均為 null,也屬于相同的情況
- 如果 key 相同,進入步驟二
- 如果 key 不同,則無需判斷 type,結果為不能復用(有兄弟節點還會去遍歷兄弟節點)
- 如果 key 相同,再判斷 type 是否相同
- 如果 type 相同,那么就復用
- 如果 type 不同,則無法復用(并且兄弟節點也一并標記為刪除)
多節點 diff 會分為兩輪遍歷:
第一輪遍歷會從前往后進行遍歷,存在以下三種情況:
- 如果新舊子節點的key 和 type 都相同,說明可以復用
- 如果新舊子節點的 key 相同,但是 type 不相同,這個時候就會根據 ReactElement 來生成一個全新的 fiber,舊的 fiber 被放入到 deletions 數組里面,回頭統一刪除。但是注意,此時遍歷并不會終止
- 如果新舊子節點的 key 和 type 都不相同,結束遍歷
如果第一輪遍歷被提前終止了,那么意味著還有新的 JSX 元素或者舊的 FiberNode 沒有被遍歷,因此會采用第二輪遍歷去處理。
第二輪遍歷會遇到三種情況:
- 只剩下舊子節點:將舊的子節點添加到 deletions 數組里面直接刪除掉(刪除的情況)
- 只剩下新的 JSX 元素:根據 ReactElement 元素來創建 FiberNode 節點(新增的情況)
- 新舊子節點都有剩余:會將剩余的 FiberNode 節點放入一個 map 里面,遍歷剩余的新的 JSX 元素,然后從 map 中去尋找能夠復用的 FiberNode 節點,如果能夠找到,就拿來復用。(移動的情況)
- 如果不能找到,就新增唄。然后如果剩余的 JSX 元素都遍歷完了,map 結構中還有剩余的 Fiber 節點,就將這些 Fiber 節點添加到 deletions 數組里面,之后統一做刪除操作
整個 diff 算法最最核心的就是兩個字“復用”。
React 不使用雙端 diff 的原因:
由于雙端 diff 需要向前查找節點,但每個 FiberNode 節點上都沒有反向指針,即前一個 FiberNode 通過 sibling 屬性指向后一個 FiberNode,只能從前往后遍歷,而不能反過來,因此該算法無法通過雙端搜索來進行優化。
React 想看下現在用這種方式能走多遠,如果這種方式不理想,以后再考慮實現雙端 diff。React 認為對于列表反轉和需要進行雙端搜索的場景是少見的,所以在這一版的實現中,先不對 bad case 做額外的優化。

















)

