概述
??logistic回歸是一種廣義線性回歸(generalized linear model),因此與多重線性回歸分析有很多相同之處。它們的模型形式基本上相同,都具有 w‘x+b,其中w和b是待求參數,其區別在于他們的因變量不同,多重線性回歸直接將w‘x+b作為因變量,即y =w‘x+b,而logistic回歸則通過函數L將w‘x+b對應一個隱狀態p,p =L(w‘x+b),然后根據p 與1-p的大小決定因變量的值。如果L是logistic函數,就是logistic回歸,如果L是多項式函數就是多項式回歸。
??logistic回歸的因變量可以是二分類的,也可以是多分類的,但是二分類的更為常用,也更加容易解釋,多類可以使用softmax方法進行處理。實際中最為常用的就是二分類的logistic回歸。
??Logistic回歸模型的適用條件
- 1 因變量為二分類的分類變量或某事件的發生率,并且是數值型變量。但是需要注意,重復計數現象指標不適用于Logistic回歸。
- 2 殘差和因變量都要服從二項分布。二項分布對應的是分類變量,所以不是正態分布,進而不是用最小二乘法,而是最大似然法來解決方程估計和檢驗問題。
- 3 自變量和Logistic概率是線性關系
- 4 各觀測對象間相互獨立。
原理:如果直接將線性回歸的模型扣到Logistic回歸中,會造成方程二邊取值區間不同和普遍的非直線關系。因為Logistic中因變量為二分類變量,某個概率作為方程的因變量估計值取值范圍為0-1,但是,方程右邊取值范圍是無窮大或者無窮小。所以,才引入Logistic回歸。
Logistic回歸實質:發生概率除以沒有發生概率再取對數。就是這個不太繁瑣的變換改變了取值區間的矛盾和因變量自變量間的曲線關系。究其原因,是發生和未發生的概率成為了比值 ,這個比值就是一個緩沖,將取值范圍擴大,再進行對數變換,整個因變量改變。不僅如此,這種變換往往使得因變量和自變量之間呈線性關系,這是根據大量實踐而總結。所以,Logistic回歸從根本上解決因變量要不是連續變量怎么辦的問題。還有,Logistic應用廣泛的原因是許多現實問題跟它的模型吻合。例如一件事情是否發生跟其他數值型自變量的關系。
原理
線性回歸
線性回歸是一種使用特征屬性的線性組合來預測響應的方法。它的目標是找到一個線性函數,以盡可能準確地描述特征或自變量(x)與響應值(y)之間的關系,使得預測值與真實值之間的誤差最小化。
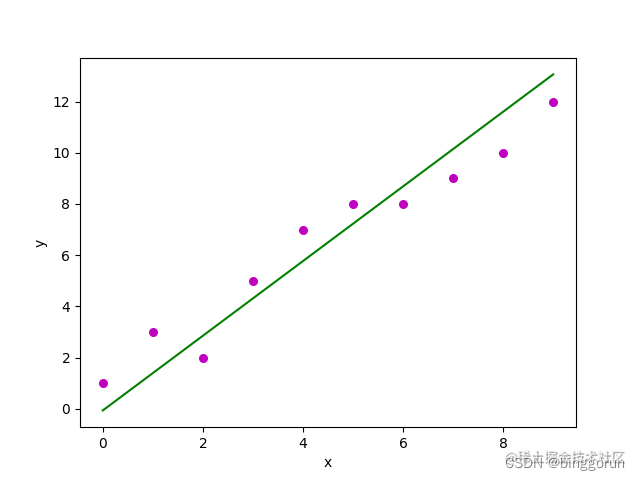
在數學上,線性回歸要找的這個線性函數叫回歸方程,其定義如下:

PS:損失函數的系數 1/2 是為了便于計算,使對平方項求導后的常數系數為 1。

現代機器學習中常用的參數更新方法是梯度下降法。
梯度下降法

- 批梯度下降(BGD):批梯度下降會獲得全局最優解,缺點是在更新每個參數的時候需要遍歷所有的數據,計算量會很大,并且會有很多的冗余計算,導致的結果是當數據量大的時候,每個參數的更新都會很慢。
- 隨機梯度下降(SGD):隨機梯度下降是以高方差頻繁更新,優點是使得sgd會跳到新的和潛在更好的局部最優解,缺點是使得收斂到局部最優解的過程更加的復雜。
- 小批量梯度下降(MGBD):小批量梯度下降結合了sgd和batch gd的優點,每次更新的時候使用n個樣本。減少了參數更新的次數,可以達到更加穩定收斂結果,一般在深度學習當中我們采用這種方法。
回歸的評價指標

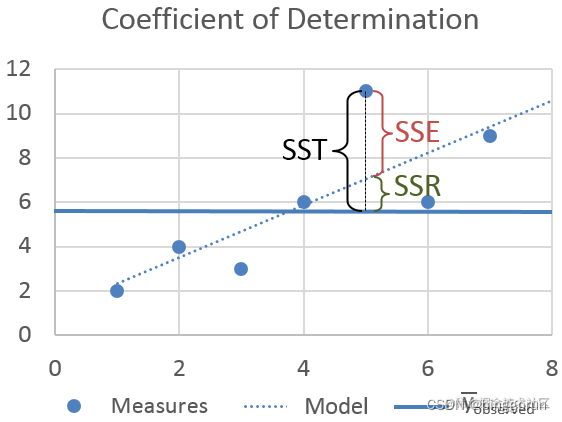
從圖中不難看出,三者的關系是:SST = SSR + SSE。如果 SSR 的值等于 SST,這意味著我們的回歸模型是完美的。
邏輯回歸
邏輯回歸和線性回歸不同的地方在于:線性回歸適用于解決回歸問題,而邏輯回歸適用于解決分類問題。本節我們就講講造成這種差異的原因。
Sigmoid函數

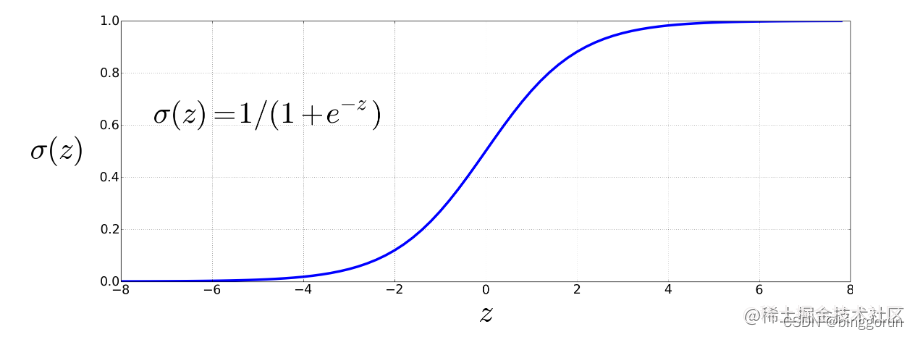

總結:邏輯回歸的總體思路就是,先用邏輯函數把線性回歸的結果 (-∞,∞) 映射到 (0,1),再通過決策邊界建立與分類的概率聯系。

代價函數

- 代價函數之所以要加負號,是因為機器學習的目標是最小化損失函數,而極大似然估計法的目標是最大化似然函數。那么加個負號,正好使二者等價。
- 對數損失函數與上面的極大似然估計的對數似然函數本質上是等價的。所以邏輯回歸直接采用對數損失函數來求參數,實際上與采用極大似然估計來求參數是一致的。
梯度下降法求解

邏輯回歸的分類
邏輯回歸對特征變量(x)和分類響應變量(y)之間的關系進行建模,在給定一組預測變量的情況下,它能給出落入特定類別響應水平的概率。也就是說,你給它一組數據(特征),它告訴你這組數據屬于某一類別的概率。根據分類響應變量(y)的性質,我們可以將邏輯回歸分為三類:
- 二元邏輯回歸(Binary Logistic Regression)
當分類結果只有兩種可能的時候,我們就稱為二元邏輯回歸。例如,考試通過或未通過,回答是或否,血壓高或低。 - 名義邏輯回歸(Nominal Logistic Regression)
當存在三個或更多類別且類別之間沒有自然排序時,我們就稱為名義邏輯回歸。例如,企業的部門有策劃、銷售、人力資源等,顏色有黑色、紅色、藍色、橙色等。 - 序數邏輯回歸(Ordinal Logistic Regression)
當存在三個或更多類別且類別之間有自然排序時,我們就稱為序數邏輯回歸。例如,評價有好、中、差,身材有偏胖、中等、偏瘦。注意,類別的排名不一定意味著它們之間的間隔相等。
Softmax Regression

原為鏈接:https://www.cnblogs.com/marvin-wen/p/15966151.html
優劣勢
優點:
1)形式簡單,模型的可解釋性非常好。從特征的權重可以看到不同的特征對最后結果的影響,某個特征的權重值比較高,那么這個特征最后對結果的影響會比較大
2)模型效果不錯。在工程上是可以接受的(作為baseline),如果特征工程做的好,效果不會太差,并且特征工程可以大家并行開發,大大加快開發的速度。
3)訓練速度較快。分類的時候,計算量僅僅只和特征的數目相關。并且邏輯回歸的分布式優化sgd發展比較成熟,訓練的速度可以通過堆機器進一步提高,這樣我們可以在短時間內迭代好幾個版本的模型。
4)資源占用小,尤其是內存。因為只需要存儲各個維度的特征。
5)方便輸出結果調整。邏輯回歸可以很方便的得到最后的分類結果,因為輸出的是每個樣本的概率分數,我們可以很容易的對這些概率分數進行cutoff,也就是劃分閾值(大于某個閾值的是一類,小于某個閾值的是一類)。
缺點
1)準確率并不是很高。因為形式非常的簡單(非常類似線性模型),很難去擬合數據的真實分布。
2)很難處理數據不平衡的問題。舉個例子:如果我們對于一個正負樣本非常不平衡的問題比如正負樣本比 10000:1.我們把所有樣本都預測為正也能使損失函數的值比較小。但是作為一個分類器,它對正負樣本的區分能力不會很好。
3)處理非線性數據較麻煩。邏輯回歸在不引入其他方法的情況下,只能處理線性可分的數據,或者進一步說,處理二分類的問題 。
4)邏輯回歸本身無法篩選特征。有時候,我們會用gbdt來篩選特征,然后再上邏輯回歸。
實現
評分卡的目標模型是,依據客戶數據,預測客戶是否壞客戶
整個建模過程共5步:
1.變量分析與分箱:篩選與標簽SeriousDlqin2yrs有相關性的變量,并把變量進行分箱,作為建模的輸入特征。
2.建模
(1)數據預處理:轉woe,歸一化
(2)用逐步回歸選出盡量少的特征(同時保持建模效果)
(3)訓練邏輯回歸模型
3.模型評估:檢驗AUC是否達標,并檢查系數是否都為正。
4.將邏輯回歸模型預測結果轉為評分
5.確定生產上的判定為壞客戶的分數閾值
scikit-learn
在scikit-learn中,與邏輯回歸有關的主要是這3個類。LogisticRegression, LogisticRegressionCV 和logistic_regression_path。其中LogisticRegression和LogisticRegressionCV的主要區別是LogisticRegressionCV使用了交叉驗證來選擇正則化系數C。而LogisticRegression需要自己每次指定一個正則化系數。除了交叉驗證,以及選擇正則化系數C以外, LogisticRegression和LogisticRegressionCV的使用方法基本相同。
??logistic_regression_path類則比較特殊,它擬合數據后,不能直接來做預測,只能為擬合數據選擇合適邏輯回歸的系數和正則化系數。主要是用在模型選擇的時候。一般情況用不到這個類
???此外,scikit-learn里面有個容易讓人誤解的類RandomizedLogisticRegression,雖然名字里有邏輯回歸的詞,但是主要是用L1正則化的邏輯回歸來做特征選擇的,屬于維度規約的算法類,不屬于我們常說的分類算法的范疇。
????后面的講解主要圍繞LogisticRegression和LogisticRegressionCV中的重要參數的選擇來來展開,這些參數的意義在這兩個類中都是一樣的。
????函數調用形式:
LogisticRegression(penalty='l2',dual=False,tol=1e4,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver='liblinear',max_iter=100,multi_class='ovr',verbose=0,warm_start=False, n_jobs=1)參數
| 參數 | 參數名稱 | 解釋 |
|---|---|---|
| penalty | 正則化類型 | 1)字符串型,’l1’ or ‘l2’,默認:’l2’;正則化類型。 2)LogisticRegression和LogisticRegressionCV默認就帶了正則化項。penalty參數可選擇的值為"l1"和"l2".分別對應L1的正則化和L2的正則化,默認是L2的正則化。 3)penalty參數的選擇會影響我們損失函數優化算法的選擇。即參數solver的選擇,如果是L2正則化,那么4種可選的算法{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}都可以選擇。但是如果penalty是L1正則化的話,就只能選擇‘liblinear’了。這是因為L1正則化的損失函數不是連續可導的,而{‘newton-cg’, ‘lbfgs’,‘sag’}這三種優化算法時都需要損失函數的一階或者二階連續導數。而‘liblinear’并沒有這個依賴。 |
| dual | 布爾型,默認:False。當樣本數>特征數時,令dual=False;用于liblinear解決器中L2正則化。 | |
| tol | 誤差范圍 | 浮點型,默認:1e-4;迭代終止判斷的誤差范圍。 |
| C | 正則化強度 | 浮點型,默認:1.0;其值等于正則化強度的倒數,為正的浮點數。數值越小表示正則化越強。 |
| fit_intercept | 截距 | 布爾型,默認:True;指定是否應該向決策函數添加常量(即偏差或截距)。 |
| intercept_scaling | intercept_scaling | 浮點型,默認為1;僅僅當solver是”liblinear”時有用。 |
| solver | 邏輯回歸損失函數的優化方法 | solver參數決定了我們對邏輯回歸損失函數的優化方法,有4種算法可以選擇,分別是: a. liblinear:使用了開源的liblinear庫實現,內部使用了坐標軸下降法來迭代優化損失函數。 b.lbfgs:擬牛頓法的一種,利用損失函數二階導數矩陣即海森矩陣來迭代優化損失函數。 c. newton-cg:也是牛頓法家族的一種,利用損失函數二階導數矩陣即海森矩陣來迭代優化損失函數。 d. sag:即隨機平均梯度下降,是梯度下降法的變種,和普通梯度下降法的區別是每次迭代僅僅用一部分的樣本來計算梯度,適合于樣本數據多的時候,SAG是一種線性收斂算法,這個速度遠比SGD快。 從上面的描述可以看出,newton-cg, lbfgs和sag這三種優化算法時都需要損失函數的一階或者二階連續導數,因此不能用于沒有連續導數的L1正則化,只能用于L2正則化。而liblinear通吃L1正則化和L2正則化。 同時,sag每次僅僅使用了部分樣本進行梯度迭代,所以當樣本量少的時候不要選擇它,而如果樣本量非常大,比如大于10萬,sag是第一選擇。但是sag不能用于L1正則化,所以當你有大量的樣本,又需要L1正則化的話就要自己做取舍了。要么通過對樣本采樣來降低樣本量,要么回到L2正則化。 |
| max_iter | 最大迭代次數 | 整型,默認是100; |
| multi_class | 分類方式 | multi_class參數決定了我們分類方式的選擇,有 ovr和multinomial兩個值可以選擇,默認是 ovr。如果是二元邏輯回歸,ovr和multinomial并沒有任何區別,區別主要在多元邏輯回歸上。 |
| verbose | 整型,默認是0;對于liblinear和lbfgs solver,verbose可以設為任意正數。 | |
| class_weight | 分類模型中各種類型的權重 | class_weight參數用于標示分類模型中各種類型的權重,可以不輸入,即不考慮權重,或者說所有類型的權重一樣。如果選擇輸入的話,可以選擇balanced讓類庫自己計算類型權重,或者我們自己輸入各個類型的權重,比如對于0,1的二元模型,我們可以定義class_weight={0:0.9, 1:0.1},這樣類型0的權重為90%,而類型1的權重為10%。 如果class_weight選擇balanced,那么類庫會根據訓練樣本量來計算權重。某種類型樣本量越多,則權重越低,樣本量越少,則權重越高。 sklearn的官方文檔中,當class_weight為balanced時,類權重計算方法如下:n_samples / (n_classes * np.bincount(y))_samples為樣本數,n_classes為類別數量,np.bincount(y)會輸出每個類的樣本數,例如y=[1,0,0,1,1],則np.bincount(y)=[2,3] |
| sample_weight | 樣本權重 | 由于樣本不平衡,導致樣本不是總體樣本的無偏估計,從而可能導致我們的模型預測能力下降。遇到這種情況,我們可以通過調節樣本權重來嘗試解決這個問題。調節樣本權重的方法有兩種: 第一種是在class_weight使用balanced。 第二種是在調用fit函數時,通過sample_weight來自己調節每個樣本權重。 在scikit-learn做邏輯回歸時,如果上面兩種方法都用到了,那么樣本的真正權重是class_weight*sample_weight。 |
| warm_start | 布爾型,默認為False;當設置為True時,重用前一個調用的解決方案以適合初始化。否則,只擦除前一個解決方案。對liblinear解碼器無效。 | |
| n_jobs | 使用的CPU核數 | 整型,默認是1;如果multi_class=‘ovr’ ,則為在類上并行時使用的CPU核數。無論是否指定了multi_class,當將’ solver ’ '設置為’liblinear’時,將忽略此參數。如果給定值為-1,則使用所有核。 |
| random_state | 隨機種子 | 整型,默認None;當“solver”==“sag”或“liblinear”時使用。在變換數據時使用的偽隨機數生成器的種子。如果是整數, random_state為隨機數生成器使用的種子;若為RandomState實例,則random_state為隨機數生成器;如果沒有,隨機數生成器就是’ np.random '使用的RandomState實例。 |
Toad:基于 Python 的標準化評分卡模型
原為鏈接:https://geekdaxue.co/read/fcant@ai/he3tkz
本次和大家分享一個開源的評分卡神器toad。從數據探索、特征分箱、特征篩選、特征WOE變換、建模、模型評估、轉換分數,都做了完美的包裝,極大的簡化了建模人員的門檻。
一、讀取數據、劃分樣本集
首先通過read_csv讀取數據,看看數據概況。
data = pd.read_csv('train.csv')
print('Shape:',data.shape)
data.head(10)
#>> Shape: (108940, 167)
這個測試數據有10萬條數據,167個特征。
print('month:',data.month.unique())
#>> month: ['2019-03' '2019-04' '2019-05' '2019-06' '2019-07']
通過觀察時間變量,可以發現數據的時間跨度為2019年5月到7月。為了真正測試模型效果,將用3月和4月數據用于訓練樣本,5月、6月、7月數據作為時間外樣本,也叫作OOT的跨期樣本。
train = data.loc[data.month.isin(['2019-03','2019-04'])==True,:]
OOT = data.loc[data.month.isin(['2019-03','2019-04'])==False,:]
#train = data.loc[data.month.isin(['Mar-19','Apr-19'])==True,:]
#OOT = data.loc[data.month.isin(['Mar-19','Apr-19'])==False,:]
print('train size:',train.shape,'\nOOT size:',OOT.shape)
#>> train size: (43576, 167)
#>> OOT size: (65364, 167)
其實,這部分屬于模型設計的階段,是非常關鍵的環節。實際工作中會考慮很多因素,要結合業務場景,根據樣本量、可回溯特征、時間窗口等因素制定合適的觀察期、表現期、以及樣本,并且還要定義合適的Y標簽。本次主要介紹toad的用法,上面的設計階段先忽略掉。
二、EDA相關功能
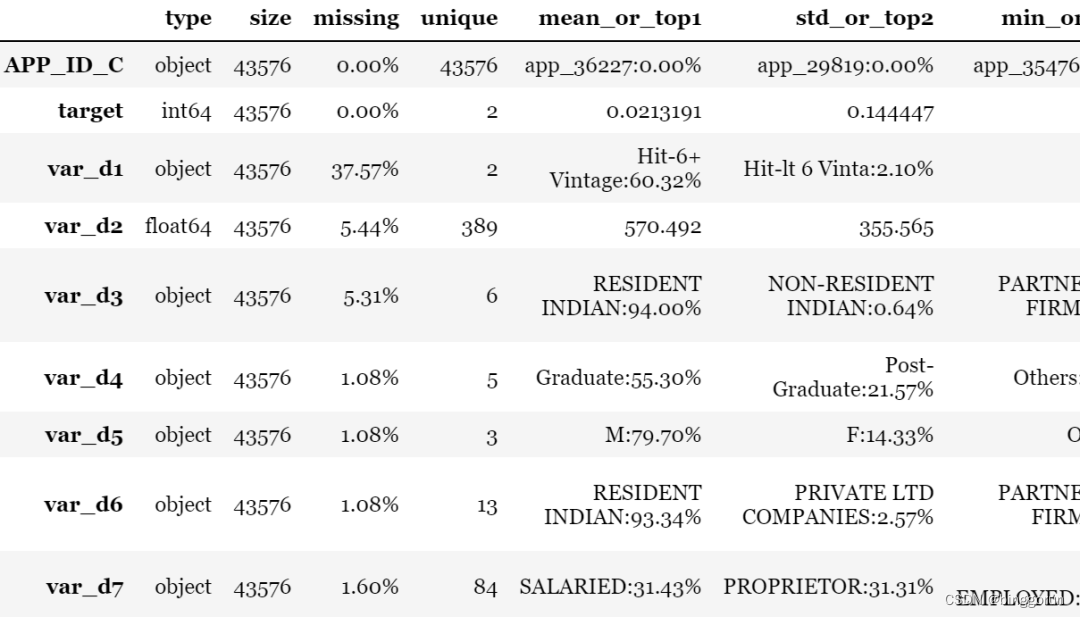
1. toad.detect
EDA也叫數據探索分析,主要用于檢測數據情況。toad輸出每列特征的統計性特征和其他信息,主要的信息包括:缺失值、unique values、數值變量的平均值、離散值變量的眾數等。
toad.detect(train)[:10]
2. toad.quality
這個功能主要用于進行變量的篩選,可以直接計算各種評估指標,如iv值、gini指數,entropy熵,以及unique values,結果以iv值排序。target為目標列,iv_only決定是否只輸出iv值。
to_drop = ['APP_ID_C','month'] # 去掉ID列和month列
toad.quality(data.drop(to_drop,axis=1),'target',iv_only=True)[:15]
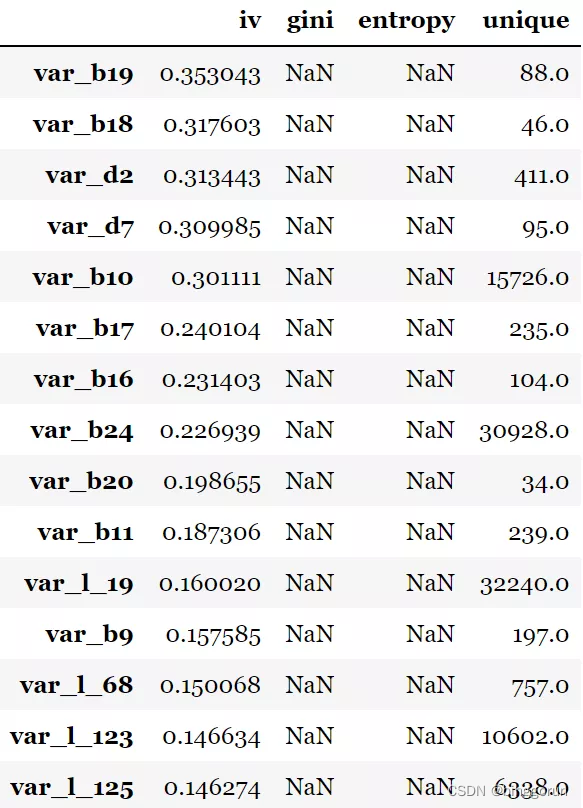
注意:1. 對于數據量大或高維度數據,建議使用iv_only=True 2. 要去掉主鍵,日期等高unique values且不用于建模的特征
但是,這一步只是計算指標而已,呈現結果進行分析,還并沒有真的完成篩選的動作。
三、特征篩選
toad.selection.select
前面通過EDA檢查過數據質量后,會有選擇的篩選一些樣本和變量,比如缺失值比例過高的、IV值過低的、相關性太強的等等。
empyt=0.9:缺失值大于0.9的變量被刪除
iv=0.02:iv值小于0.02的變量被刪除
corr=0.7:兩個變量相關性高于0.7時,iv值低的變量被刪除
return_drop=False:若為True,function將返回被刪去的變量列
exclude=None:明確不被刪去的列名,輸入為list格式
用法很簡單,只要通過設置以下幾個參數閾值即可實現,如下:
train_selected, dropped = toad.selection.select(train,target = 'target', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True, exclude=['APP_ID_C','month'])
print(dropped)
print(train_selected.shape)
經過上面的篩選,165個變量最終保留了32個變量。并且返回篩選過后的dataframe和被刪掉的變量列表。
當然了,上面都是一些常規篩選變量的方法,可能有些特殊的變量比如從業務角度很有用是需要保留的,但不滿足篩選要求,這時候可以用exclude排除掉。這個功能對于變量初篩非常有用,各種指標直接計算并展示出來。
四、分箱
在做變量的WOE變換之前需要做變量的分箱,分箱的好壞直接影響WOE的結果,以及變換后的單調性。toad將常用的分箱方法都集成了,包括等頻分箱、等距分箱、卡方分箱、決策樹分箱、最優分箱等。
并且,toad的分箱功能支持數值型數據和離散型分箱。 這部分東哥看過源碼,toad首先判斷變量類型,如果為數值型就按數值型分箱處理,如果為非數值型,那么會判斷變量唯一值的個數,如果大于10個或者超過變量總數的50%,那么也按照數值型處理。
另外,toad還支持將空值單獨分箱處理。
分箱步驟如下:
初始化:c = toad.transform.Combiner()
訓練分箱: c.fit(dataframe, y = ‘target’, method = ‘chi’, min_samples = None, n_bins = None, empty_separate = False)
- ?? y: 目標列
- ?? method: 分箱方法,支持chi(卡方分箱), dt(決策樹分箱), kmean, quantile, step(等步長分箱)
- ?? min_samples: 每箱至少包含樣本量,可以是數字或者占比
- ?? n_bins: 箱數,若無法分出這么多箱數,則會分出最多的箱數
- ?? empty_separate: 是否將空箱單獨分開
查看分箱節點:c.export()
手動調整分箱: c.load(dict)
apply分箱結果: c.transform(dataframe, labels=False):labels: 是否將分箱結果轉化成箱標簽。False時輸出0,1,2…(離散變量根據占比高低排序),True輸出(-inf, 0], (0,10], (10, inf)。
注意:做篩選時要刪去不需要分箱的列,特別是ID列和時間列。
# initialise
c = toad.transform.Combiner()
# 使用特征篩選后的數據進行訓練:使用穩定的卡方分箱,規定每箱至少有5%數據, 空值將自動被歸到最佳箱。
c.fit(train_selected.drop(to_drop, axis=1), y = 'target', method = 'chi', min_samples = 0.05) #empty_separate = False
# 為了演示,僅展示部分分箱
print('var_d2:',c.export()['var_d2'])
print('var_d5:',c.export()['var_d5'])
print('var_d6:',c.export()['var_d6'])#結果輸出:
'''
var_d2: [747.0, 782.0, 820.0]
var_d5: [['O', 'nan', 'F'], ['M']]
var_d6: [['PUBLIC LTD COMPANIES', 'NON-RESIDENT INDIAN', 'PRIVATE LTD COMPANIES', 'PARTNERSHIP FIRM', 'nan'], ['RESIDENT INDIAN', 'TRUST', 'TRUST-CLUBS/ASSN/SOC/SEC-25 CO.', 'HINDU UNDIVIDED FAMILY', 'CO-OPERATIVE SOCIETIES', 'LIMITED LIABILITY PARTNERSHIP', 'ASSOCIATION', 'OVERSEAS CITIZEN OF INDIA', 'TRUST-NGO']]
'''
觀察分箱并調整
因為自動分箱也不可能滿足所有需要,很多情況下還是要手動分箱。toad除了上面自動分箱以外,還提供了可視化分箱的功能,幫助調整分箱節點,比如觀察變量的單調性。有兩種功能:
1. 時間內觀察
toad.plot.bin_plot(dataframe, x = None, target = target) #也就是不考慮時間的因素,單純的比較各個分箱里的bad_rate,觀察單調性。
# 看'var_d5'在時間內的分箱
col = 'var_d5'
#觀察單個變量分箱結果時,建議設置'labels = True'
bin_plot(c.transform(train_selected[[col,'target']], labels=True), x=col, target='target')
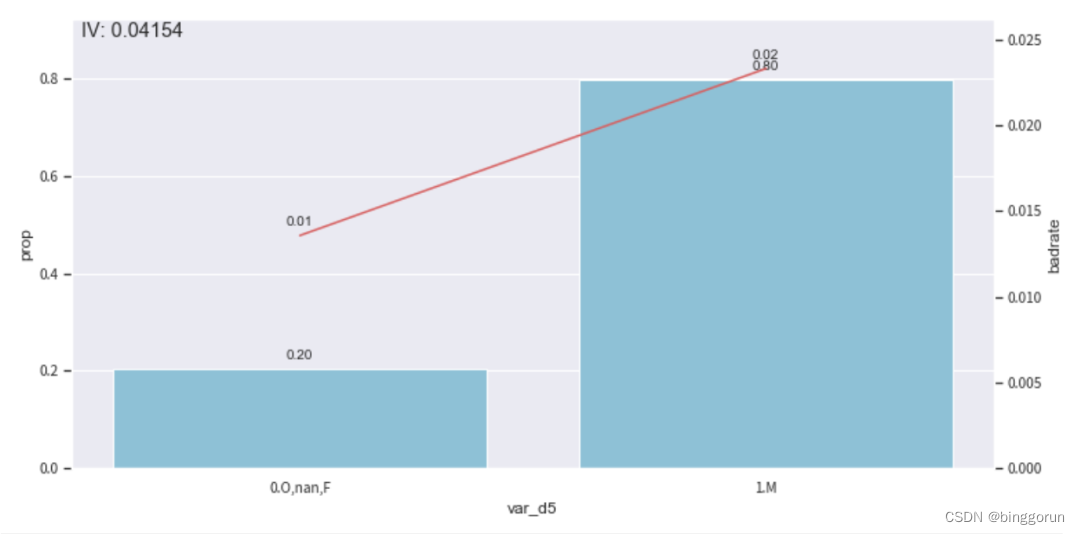
上圖中,bar代表了樣本量占比,紅線代表了壞客戶占比。通過觀察發現分箱有些不合理,還有調整優化的空間,比如將F和M單獨一箱,0和空值分為一箱。因此,使用**c.set_rules(dict)**對這個分箱進行調整。
# iv值較低,假設我們要 'F' 單獨分出一組來提高iv
#設置分組
rule = {'var_d5':[['O', 'nan'],['F'], ['M']]}
#調整分箱
c.set_rules(rule)
#查看手動分箱穩定性
bin_plot(c.transform(train_selected[['var_d5','target']], labels=True), x='var_d5', target='target')
badrate_plot(c.transform(OOT[['var_d5','target','month']], labels=True), target='target', x='month', by='var_d5')
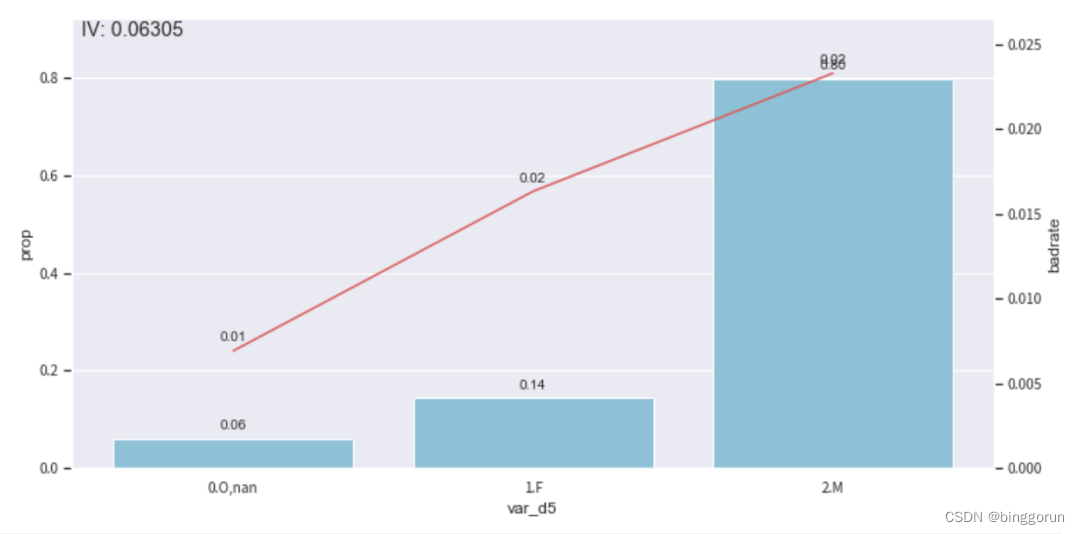
2. 跨時間觀察
toad.plot.badrate_plot:考慮時間因素,輸出不同時間段中每箱的正樣本占比,觀察分箱隨時間變量的穩定性。
- target: 目標列
- x: 時間列, string格式(要預先分好并設成string,不支持timestampe)
- by: 需要觀察的特征
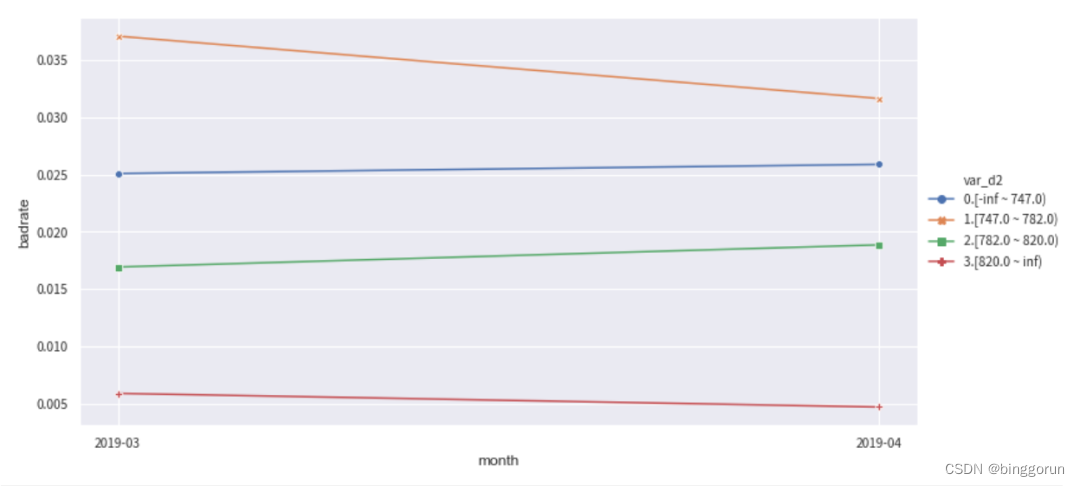
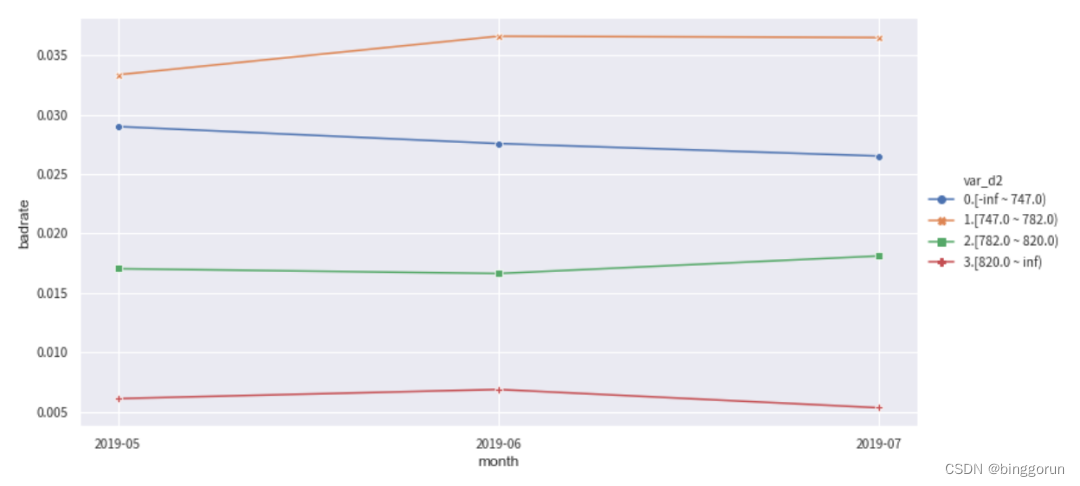
下面分別觀察變量var_d2在訓練集和OOT測試集中隨時間month變化的穩定性。正常情況下,每個分箱的bad_rate應該都有所區別,并且隨時間保持穩定不交叉。如果折現有所交叉,說明分箱不穩定,需要重新調整。
from toad.plot import badrate_plot
col = 'var_d2'
# 觀察 'var_d2' 分別在時間內和OOT中的穩定性
badrate_plot(c.transform(train[[col,'target','month']], labels=True), target='target', x='month', by=col)
badrate_plot(c.transform(OOT[[col,'target','month']], labels=True), target='target', x='month', by=col)
'''
敞口隨時間變化而增大為優,代表了變量在更新的時間區分度更強。線之前沒有交叉為優,代表分箱穩定。
'''
五、WOE轉化
WOE轉化在分箱調整好之后進行,步驟如下:
用上面調整好的Combiner(c)轉化數據: c.transform,只會轉化被分箱的變量。
初始化woe transer:transer = toad.transform.WOETransformer()
訓練轉化woe:transer.fit_transform訓練并輸出woe轉化的數據,用于轉化train/時間內數據
- ??target:目標列數據(非列名)
- ??exclude: 不需要被WOE轉化的列。注意:會轉化所有列,包括未被分箱transform的列,通過exclude刪去不要WOE轉化的列,特別是target列。
根據訓練好的transer,轉化test/OOT數據:transer.transform
根據訓練好的transer輸出woe轉化的數據,用于轉化test/OOT數據。
# 初始化
transer = toad.transform.WOETransformer()
# combiner.transform() & transer.fit_transform() 轉化訓練數據,并去掉target列
train_woe = transer.fit_transform(c.transform(train_selected), train_selected['target'], exclude=to_drop+['target'])
OOT_woe = transer.transform(c.transform(OOT))
print(train_woe.head(3))#結果輸出:
'''APP_ID_C target var_d2 var_d3 var_d5 var_d6 var_d7 \
0 app_1 0 -0.178286 0.046126 0.090613 0.047145 0.365305
1 app_2 0 -1.410248 0.046126 -0.271655 0.047145 -0.734699
2 app_3 0 -0.178286 0.046126 0.090613 0.047145 0.365305var_d11 var_b3 var_b9 ... var_l_60 var_l_64 var_l_68 var_l_71 \
0 -0.152228 -0.141182 -0.237656 ... 0.132170 0.080656 0.091919 0.150975
1 -0.152228 0.199186 0.199186 ... 0.132170 0.080656 0.091919 0.150975
2 -0.152228 -0.141182 0.388957 ... -0.926987 -0.235316 -0.883896 -0.385976var_l_89 var_l_91 var_l_107 var_l_119 var_l_123 month
0 0.091901 0.086402 -0.034434 0.027322 0.087378 2019-03
1 0.091901 0.086402 -0.034434 0.027322 0.087378 2019-03
2 0.091901 -0.620829 -0.034434 -0.806599 -0.731941 2019-03
[3 rows x 34 columns]
'''
六、逐步回歸
toad.selection.stepwise
逐步回歸特征篩選,支持向前,向后和雙向。 逐步回歸屬于包裹式的特征篩選方法,這部分通過使用sklearn的REF實現。
- estimator: 用于擬合的模型,支持’ols’, ‘lr’, ‘lasso’, ‘ridge’
- direction: 逐步回歸的方向,支持’forward’, ‘backward’, ‘both’ (推薦)
- criterion: 評判標準,支持’aic’, ‘bic’, ‘ks’, ‘auc’
- max_iter: 最大循環次數
- return_drop: 是否返回被剔除的列名
- exclude: 不需要被訓練的列名,比如ID列和時間列
根據多次驗證,一般來講 direction = 'both’效果最好。estimator = 'ols’以及criterion = 'aic’運行速度快且結果對邏輯回歸建模有較好的代表性。
# 將woe轉化后的數據做逐步回歸
final_data = toad.selection.stepwise(train_woe,target = 'target', estimator='ols', direction = 'both', criterion = 'aic', exclude = to_drop)
# 將選出的變量應用于test/OOT數據
final_OOT = OOT_woe[final_data.columns]
print(final_data.shape) # 逐步回歸從31個變量中選出了10個
#結果輸出:
'''
(43576, 13)
'''
#最后篩選后,再次確定建模要用的變量。
col = list(final_data.drop(to_drop+['target'],axis=1).columns)
七、建模和模型評估
首先,使用邏輯回歸建模,通過sklearn實現。模型參數比如正則化、樣本權重等不在這里詳解。
用邏輯回歸建模
# 用邏輯回歸建模
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(final_data[col], final_data['target'])
# 預測訓練和隔月的OOT
pred_train = lr.predict_proba(final_data[col])[:,1]
pred_OOT_may =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-05',col])[:,1]
pred_OOT_june =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-06',col])[:,1]
pred_OOT_july =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-07',col])[:,1]
然后,計算模型預測結果。風控模型常用的評價指標有: KS、AUC、PSI等。下面展示如果通過toad快速實現完成。
KS 和 AUC
評價指標
from toad.metrics import KS, AUC
print('train KS',KS(pred_train, final_data['target']))
print('train AUC',AUC(pred_train, final_data['target']))
print('OOT結果')
print('5月 KS',KS(pred_OOT_may, final_OOT.loc[final_OOT.month == '2019-05','target']))
print('6月 KS',KS(pred_OOT_june, final_OOT.loc[final_OOT.month == '2019-06','target']))
print('7月 KS',KS(pred_OOT_july, final_OOT.loc[final_OOT.month == '2019-07','target']))
#結果輸出:
'''
train KS 0.3707986228750539
train AUC 0.75060723924743
'''
#OOT結果'''
5月 KS 0.3686687175756087
6月 KS 0.3495273403486497
7月 KS 0.3796914199845523
'''
PSI
PSI分為兩種,一個是變量的PSI,一個是模型的PSI。
下面是變量PSI的計算,比較訓練集和OOT的變量分布之間的差異。
toad.metrics.PSI(final_data[col], final_OOT[col])
#結果輸出:
'''
var_d2 0.000254
var_d5 0.000012
var_d7 0.000079
var_d11 0.000191
var_b10 0.000209
var_b18 0.000026
var_b19 0.000049
var_b23 0.000037
var_l_20 0.000115
var_l_68 0.000213
dtype: float64
'''
模型PSI的計算,分別計算訓練集和OOT模型預測結果的差異,下面細分為三個月份比較。
print(toad.metrics.PSI(pred_train,pred_OOT_may))
print(toad.metrics.PSI(pred_train,pred_OOT_june))
print(toad.metrics.PSI(pred_train,pred_OOT_june))
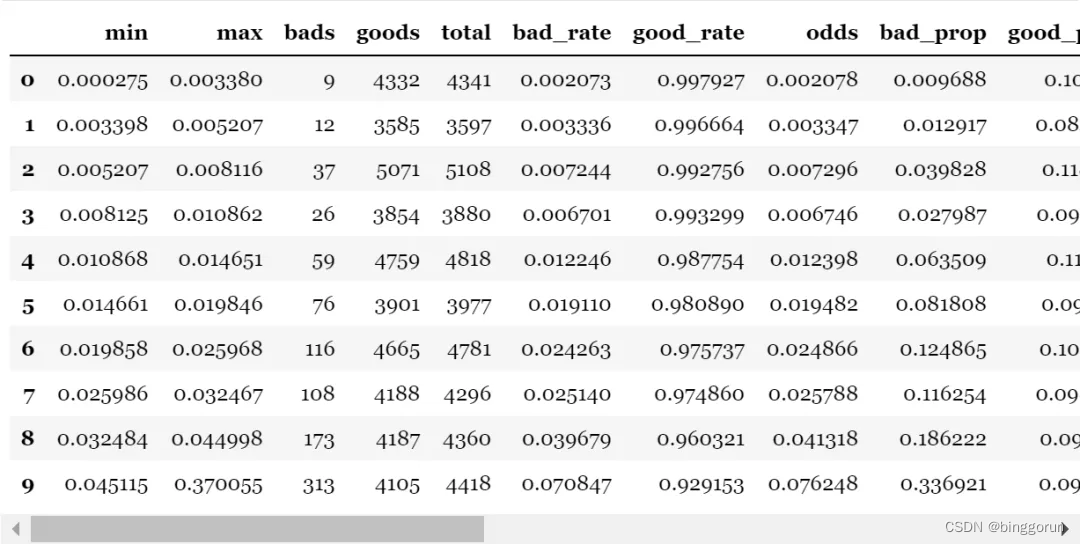
另外,toad還提供了整個評價指標的匯總,輸出模型預測分箱后評判信息,包括每組的分數區間,樣本量,壞賬率,KS等。
toad.metrics.KS_bucket
- bucket:分箱的數量
- method:分箱方法,建議用quantile(等人數),或step(等分數步長)
- bad_rate為每組壞賬率:
組之間的壞賬率差距越大越好
可以用于觀察是否有跳點
可以用與找最佳切點
可以對比
# 將預測等頻分箱,觀測每組的區別
toad.metrics.KS_bucket(pred_train, final_data['target'], bucket=10, method = 'quantile')
八、轉換評分
toad.ScoreCard
最后一步就是將邏輯回歸模型轉標準評分卡,支持傳入邏輯回歸參數,進行調參。
- combiner: 傳入訓練好的 toad.Combiner 對象
- transer: 傳入先前訓練的 toad.WOETransformer 對象
- pdo、rate、base_odds、base_score: e.g. pdo=60, rate=2, base_odds=20, base_score=750 實際意義為當比率為1/20,輸出基準評分750,當比率為基準比率2倍時,基準分下降60分
- card: 支持傳入專家評分卡
- **kwargs: 支持傳入邏輯回歸參數(參數詳見 sklearn.linear_model.LogisticRegression) ```python card = toad.ScoreCard( combiner = c, transer = transer,class_weight = ‘balanced’,C=0.1,base_score = 600,base_odds = 35 ,pdo = 60,rate = 2)
card.fit(final_data[col], final_data[‘target’])
結果輸出:
'''
ScoreCard(base_odds=35, base_score=750, card=None,combiner=<toad.transform.Combiner object at 0x1a2434fdd8>, pdo=60,rate=2,transer=<toad.transform.WOETransformer object at 0x1a235a5358>)
'''
注:評分卡在 fit 時使用 WOE 轉換后的數據來計算最終的分數,分數一旦計算完成,便無需 WOE 值,可以直接使用 原始數據 進行評分。
# 直接使用原始數據進行評分
card.predict(train)
#輸出標準評分卡
card.export()
#結果輸出:
{'var_d2': {'[-inf ~ 747.0)': 65.54,'[747.0 ~ 782.0)': 45.72,'[782.0 ~ 820.0)': 88.88,'[820.0 ~ inf)': 168.3},'var_d5': {'O,nan': 185.9, 'F': 103.26, 'M': 68.76},'var_d7': {'LARGE FLEET OPERATOR,COMPANY,STRATEGIC TRANSPRTER,SALARIED,HOUSEWIFE': 120.82,'DOCTOR-SELF EMPLOYED,nan,SAL(RETIRAL AGE 60),SERVICES,SAL(RETIRAL AGE 58),OTHERS,DOCTOR-SALARIED,AGENT,CONSULTANT,DIRECTOR,MEDIUM FLEETOPERATOR,TRADER,RETAIL TRANSPORTER,MANUFACTURING,FIRST TIME USERS,STUDENT,PENSIONER': 81.32,'PROPRIETOR,TRADING,STRATEGIC CAPTIVE,SELF-EMPLOYED,SERV-PRIVATE SECTOR,SMALL RD TRANS.OPR,BUSINESSMAN,CARETAKER,RETAIL,AGRICULTURIST,RETIRED PERSONNEL,MANAGER,CONTRACTOR,ACCOUNTANT,BANKS SERVICE,GOVERNMENT SERVICE,ADVISOR,STRATEGIC S1,SCHOOLS,TEACHER,GENARAL RETAILER,RESTAURANT KEEPER,OFFICER,POLICEMAN,SERV-PUBLIC SECTOR,BARRISTER,Salaried,SALESMAN,RETAIL CAPTIVE,Defence (NCO),STRATEGIC S2,OTHERS NOT DEFINED,JEWELLER,SECRETARY,SUP STRAT TRANSPORT,LECTURER,ATTORNEY AT LAW,TAILOR,TECHNICIAN,CLERK,PLANTER,DRIVER,PRIEST,PROGRAMMER,EXECUTIVE ASSISTANT,PROOF READER,STOCKBROKER(S)-COMMD,TYPIST,ADMINSTRATOR,INDUSTRY,PHARMACIST,Trading,TAXI DRIVER,STRATEGIC BUS OP,CHAIRMAN,CARPENTER,DISPENSER,HELPER,STRATEGIC S3,RETAIL BUS OPERATOR,GARAGIST,PRIVATE TAILOR,NURSE': 55.79},'var_d11': {'N': 88.69, 'U': 23.72},'var_b10': {'[-inf ~ -8888.0)': 67.76,'[-8888.0 ~ 0.548229531)': 97.51,'[0.548229531 ~ inf)': 36.22},'var_b18': {'[-inf ~ 2)': 83.72, '[2 ~ inf)': 39.23},'var_b19': {'[-inf ~ -9999)': 70.78, '[-9999 ~ 4)': 97.51, '[4 ~ inf)': 42.2},'var_b23': {'[-inf ~ -8888)': 64.51, '[-8888 ~ inf)': 102.69},'var_l_20': {'[-inf ~ 0.000404297)': 78.55,'[0.000404297 ~ 0.003092244)': 103.85,'[0.003092244 ~ inf)': 36.21},'var_l_68': {'[-inf ~ 0.000255689)': 70.63,'[0.000255689 ~ 0.002045513)': 24.56,'[0.002045513 ~ 0.007414983000000002)': 66.63,'[0.007414983000000002 ~ 0.019943748)': 99.55,'[0.019943748 ~ inf)': 142.36}
}
九、其他功能
toad.transform.GBDTTransformer
toad還支持用gbdt編碼,用于gbdt + lr建模的前置。這種融合的方式來自facebook,即先使用gbdt訓練輸出,再將輸出結果作為lr的輸入訓練,以此達到更好的學習效果。
gbdt_transer = toad.transform.GBDTTransformer()
gbdt_transer.fit(final_data[col+['target']], 'target', n_estimators = 10, max_depth = 2)
gbdt_vars = gbdt_transer.transform(final_data[col])
gbdt_vars.shape
#>> (43576, 40)
以上就是toad的基本用法。


)







:最大回撤率)





)


