LSTM
- 前言
- 網絡架構
- 總線
- 遺忘門
- 記憶門
- 記憶細胞
- 輸出門
- 模型定義
- 單個LSTM神經元的定義
- LSTM層內結構的定義
- 模型訓練
- 模型評估
- 代碼細節
- LSTM層單元的首尾的處理
- 配置Tensorflow的GPU版本
前言
LSTM作為經典模型,可以用來做語言模型,實現類似于語言模型的功能,同時還經常用于做時間序列。由于LSTM的原版論文相關版權問題,這里以colah大佬的博客為基礎進行講解。之前寫過一篇Tensorflow中的LSTM詳解,但是原理部分跟代碼部分的聯系并不緊密,實踐性較強但是如果想要進行更加深入的調試就會出現原理性上面的問題,因此特此作文解決這個問題,想要用LSTM這個有趣的模型做出更加好的機器學習效果😊。
網絡架構
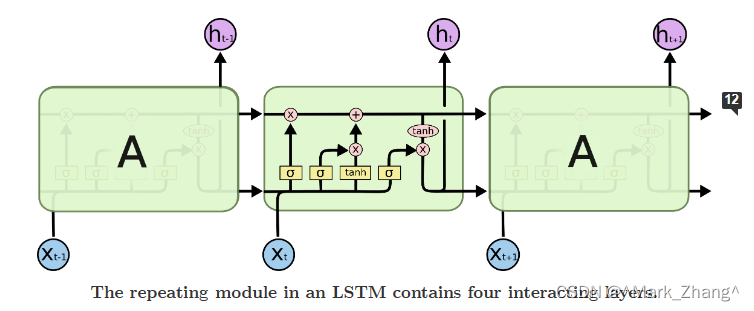
這張圖展示了LSTM在整體結構,下面就開始分部分介紹中間這個東東。
總線

這條是總線,可以實現神經元結構的保存或者更改,如果就是像上圖一樣一條總線貫穿不做任何改變,那么就是不改變細胞狀態。那么如果想要改變細胞狀態怎么辦?可以通過門來實現,這里的門跟高中生物中學的神經興奮閾值比較像,用數學來表示就是sigmoid函數或者其他的激活函數,當門的輸入達到要求,門就會打開,允許當前門后面的信息“穿過”門改變主線上面傳遞的信息,如果把每一個神經元看成一個時間節點,那么從上一個時間節點傳到下一個時間節點過程中的門的開啟與關閉就實現了時間序列數據的信息傳遞。
遺忘門
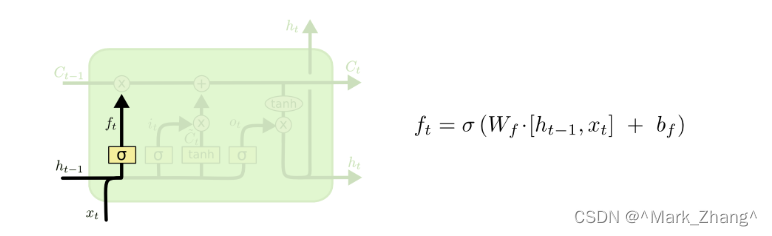
首先是遺忘門,這個門的作用是決定從上一個神經元傳輸到當前神經元的數據丟棄的程度,如果經過sigmoid函數以后輸出0表示全部丟棄,輸出1表示全部保留,這個層的輸入是舊的信息和當前的新信息。
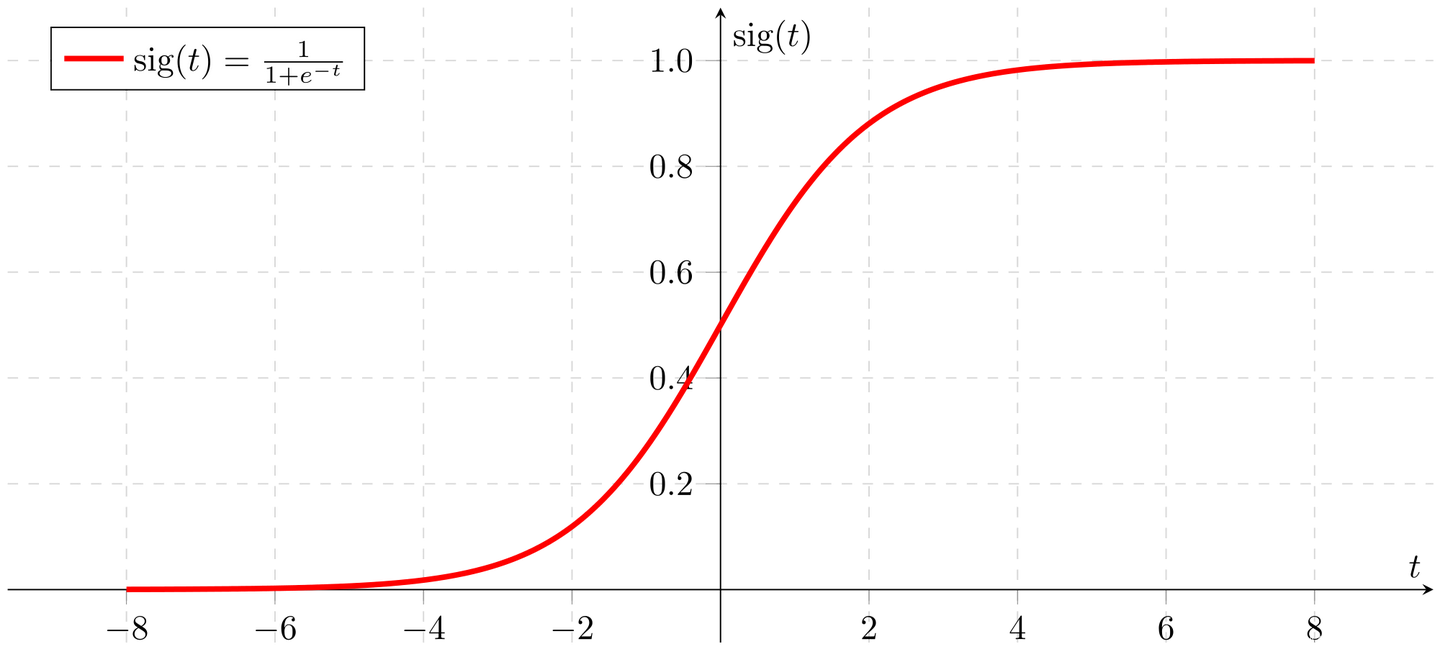
σ \sigma σ:sigmoid函數
W f W_f Wf?:權重向量
b f b_f bf?:偏置項,決定丟棄上一個時間節點的程度,如果是正數,表示更容易遺忘,如果是負數,表示比較容易記憶
h t ? 1 h_{t-1} ht?1?:上一個時刻的輸入
x t x_t xt?:當前層的輸入
記憶門

接下來是記憶門,這個門決定要記住什么信息,同時決定按照什么程度記住上一個狀態的信息。
i t i_t it?:在時間步t時刻的輸入門激活值,計算方法跟上面的遺忘門是一樣的,只是目的不一樣,這里是記憶
C ~ t \tilde{C}_{t} C~t?:表示上一個時刻的信息和當前時刻的信息的集合,但是是規則化到[-1,1]這個范圍內了的
記憶細胞
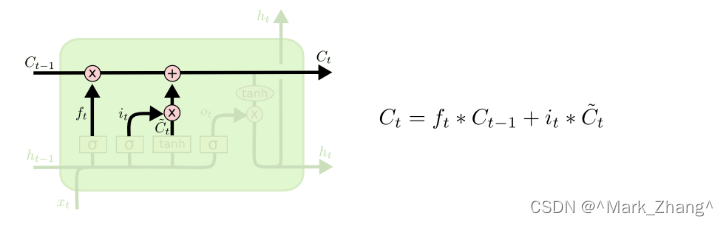
有了上面的要記憶的信息和要丟棄的信息,記憶細胞的功能就可以得到實現,用 f t f_t ft?這個標量決定上一個狀態要遺忘什么,用 i t i_t it?這個標量決定上一個狀態要記住什么以及當前狀態的信息要記住什么。這樣就形成了一個記憶閉環了。
輸出門
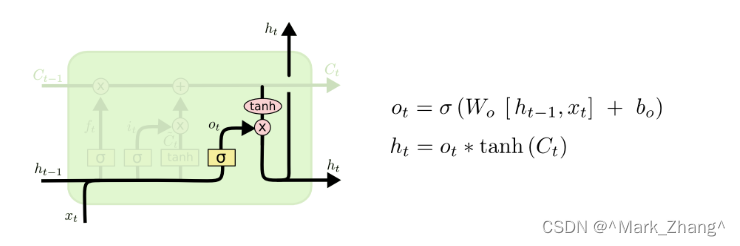
最后,在有了記憶細胞以后不僅僅不要將當前細胞狀態記住,還要將當前的信息向下一層繼續傳輸,實現公式中的狀態轉移。
o t o_t ot?:跟前面的門公式都一樣,但是功能是決定輸出的程度
h t h_t ht?:將輸出規范到[-1,1]的區間,這里有兩個輸出的原因是在構建LSTM網絡的時候需要有縱向向上的那個 h t h_t ht?,然而在當前層的LSTM的神經元之間還是首尾相接的😍。
模型定義
單個LSTM神經元的定義
# 定義單個LSTM單元
# 定義單個LSTM單元
class My_LSTM(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(My_LSTM, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size# 初始化門的權重和偏置,由于每一個神經元都有自己的偏置,所以在定義單元內部定義self.Wf = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))self.bf = nn.Parameter(torch.Tensor(hidden_size))self.Wi = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))self.bi = nn.Parameter(torch.Tensor(hidden_size))self.Wo = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))self.bo = nn.Parameter(torch.Tensor(hidden_size))self.Wg = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))self.bg = nn.Parameter(torch.Tensor(hidden_size))# 初始化輸出層的權重和偏置self.W = nn.Parameter(torch.Tensor(hidden_size, output_size))self.b = nn.Parameter(torch.Tensor(output_size))# 用于計算每一種權重的函數def cal_weight(self, input, weight, bias):return F.linear(input, weight, bias)# x是輸入的數據,數據的格式是(batch, seq_len, input_size),包含的是batch個序列,每個序列有seq_len個時間步,每個時間步有input_size個特征def forward(self, x):# 初始化隱藏層和細胞狀態h = torch.zeros(1, 1, self.hidden_size).to(x.device)c = torch.zeros(1, 1, self.hidden_size).to(x.device)# 遍歷每一個時間步for i in range(x.size(1)):input = x[:, i, :].view(1, 1, -1) # 取出每一個時間步的數據# 計算每一個門的權重f = torch.sigmoid(self.cal_weight(input, self.Wf, self.bf)) # 遺忘門i = torch.sigmoid(self.cal_weight(input, self.Wi, self.bi)) # 輸入門o = torch.sigmoid(self.cal_weight(input, self.Wo, self.bo)) # 輸出門C_ = torch.tanh(self.cal_weight(input, self.Wg, self.bg)) # 候選值# 更新細胞狀態c = f * c + i * C_# 更新隱藏層h = o * torch.tanh(c) # 將輸出標準化到-1到1之間output = self.cal_weight(h, self.W, self.b) # 計算輸出return outputLSTM層內結構的定義
class My_LSTMNetwork(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(My_LSTMNetwork, self).__init__()self.hidden_size = hidden_sizeself.lstm = My_LSTM(input_size, hidden_size) # 使用自定義的LSTM單元self.fc = nn.Linear(hidden_size, output_size) # 定義全連接層def forward(self, x):h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)c0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)out, _ = self.lstm(x, (h0, c0)) # LSTM層的前向傳播out = self.fc(out[:, -1, :]) # 全連接層的前向傳播return out模型訓練
history = model.fit(trainX, trainY, batch_size=64, epochs=50, validation_split=0.1, verbose=2)
print('compilation time:', time.time()-start)
模型評估
為了更加直觀展示,這里用畫圖的方法進行結果展示。
fig3 = plt.figure(figsize=(20, 15))
plt.plot(np.arange(train_size+1, len(dataset)+1, 1), scaler.inverse_transform(dataset)[train_size:], label='dataset')
plt.plot(testPredictPlot, 'g', label='test')
plt.ylabel('price')
plt.xlabel('date')
plt.legend()
plt.show()
代碼細節
LSTM層單元的首尾的處理
-
首部:由于第一個節點不用接受來自上一個節點的輸入,不需要有輸入,當然也有一些是添加標識。
-
尾部:由于已經進行到當前層的最后一個節點,因此輸出只需要向下一層進行傳遞而不用向下一個節點傳遞,添加標識也是可以的。
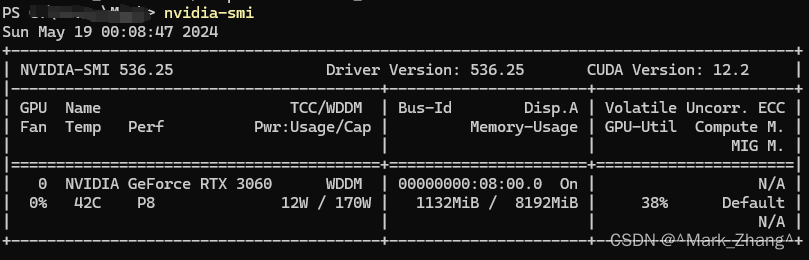
配置Tensorflow的GPU版本
這一篇寫的比較好,我自己的硬件環境如下圖所示,需要的可以借鑒一下,當然也可以在我提供的代碼鏈接直接用我給的environment.yml一鍵構建環境😃。


函數,看這一篇文章就夠了)



)

:Windows安裝版二次開發環境搭建(上):安裝OSGeo4W運行依賴其Qt的基礎環境Demo)


)

)
|插入排序(三路排序函數std::sort))




