移動云助力大模型,開拓創新領未來。
云計算——AI模型的推動器。
當前人工智能技術發展的現狀和趨勢,以及中國在人工智能領域的發展策略和成就。確實,以 ChatGPT 為代表的大型語言模型在自然語言處理、文本生成、對話系統等領域取得了顯著的成果,并且正在逐步改變我們的工作和生活方式。
由于政府部門的大力支持和企業的積極投資,人工智能產業得到了迅速發展。大型模型訓練和部署需要巨大的計算資源和存儲空間,以及相應的技術支持,這對許多企業來說是一個挑戰。云計算平臺提供了解決這一問題的方案,它允許企業通過按需購買服務的方式來使用計算資源,而無需自行建設和維護昂貴的硬件基礎設施。
中國移動云和九天人工智能的合作,展示了中國在人工智能領域的創新和進步。通過構建智能計算基礎設施,提供高效的智能化算力服務,中國正在推動從數字化到數智化的轉變,這將有助于提升國家的競爭力。
此外,中國還在人工智能的關鍵技術領域進行突破,比如算網大腦的構建,這將進一步提升人工智能模型的性能和應用效率。通過這些努力,中國有望在未來的人工智能領域繼續保持領先地位。

架構創新,改變云計算服務供給模式
移動云通過推出COCA(Compute on chip Architecture)軟硬一體片上計算架構,正在重塑云計算服務供給模式,這一架構的發布標志著移動云在算力服務模式創新方面邁出了重要一步。COCA架構的三大核心單元——GPU、DPU、HPN,結合自研可編程DPU、多元異構智能算力、高性能RDMA網絡、Diskless存儲架構引擎等技術,旨在構建高效的大模型算力基礎設施。這種基礎設施能夠實現高性能算力集群的橫向融合和垂直抽象,統一提供計算、存儲、網絡、安全、管控能力的硬件卸載加速。
通過COCA架構,移動云計劃加速算力基礎設施的建設,并為目標用戶提供一體化的算力服務,這些服務將具有“融合、智能、無感、極簡”的特點。這種服務模式不僅提供了強大的計算能力,還通過硬件卸載加速減少了資源浪費,提高了效率,使得用戶能夠更加專注于自己的業務需求,而不是基礎的計算資源管理。這一創新有望在云計算領域引發新的變革,為企業和開發者提供更加高效、智能的算力支持。
對此感興趣的伙伴可以嘗試體驗一下,下面將介紹如何在移動云上簡單部署大模型。

移動云上部署大模型ChatGLM3-6b
前言
通過移動云,大語言模型可以在移動設備上得到更好的應用和發展。在部署后可以完全本地運行,后面將介紹移動云部署大模型的實際應用,介紹怎么通過移動云上在 Linux 服務器上部署 ChatGLM3 服務,并通過多種方式使用本地部署地大模型。
服務器準備
移動云服務器(試用申請網址)
-
進入官網頁面后,進行實名認證,選擇一個合適的云服務器。

-
選擇地區,以及服務器的型號與配置。
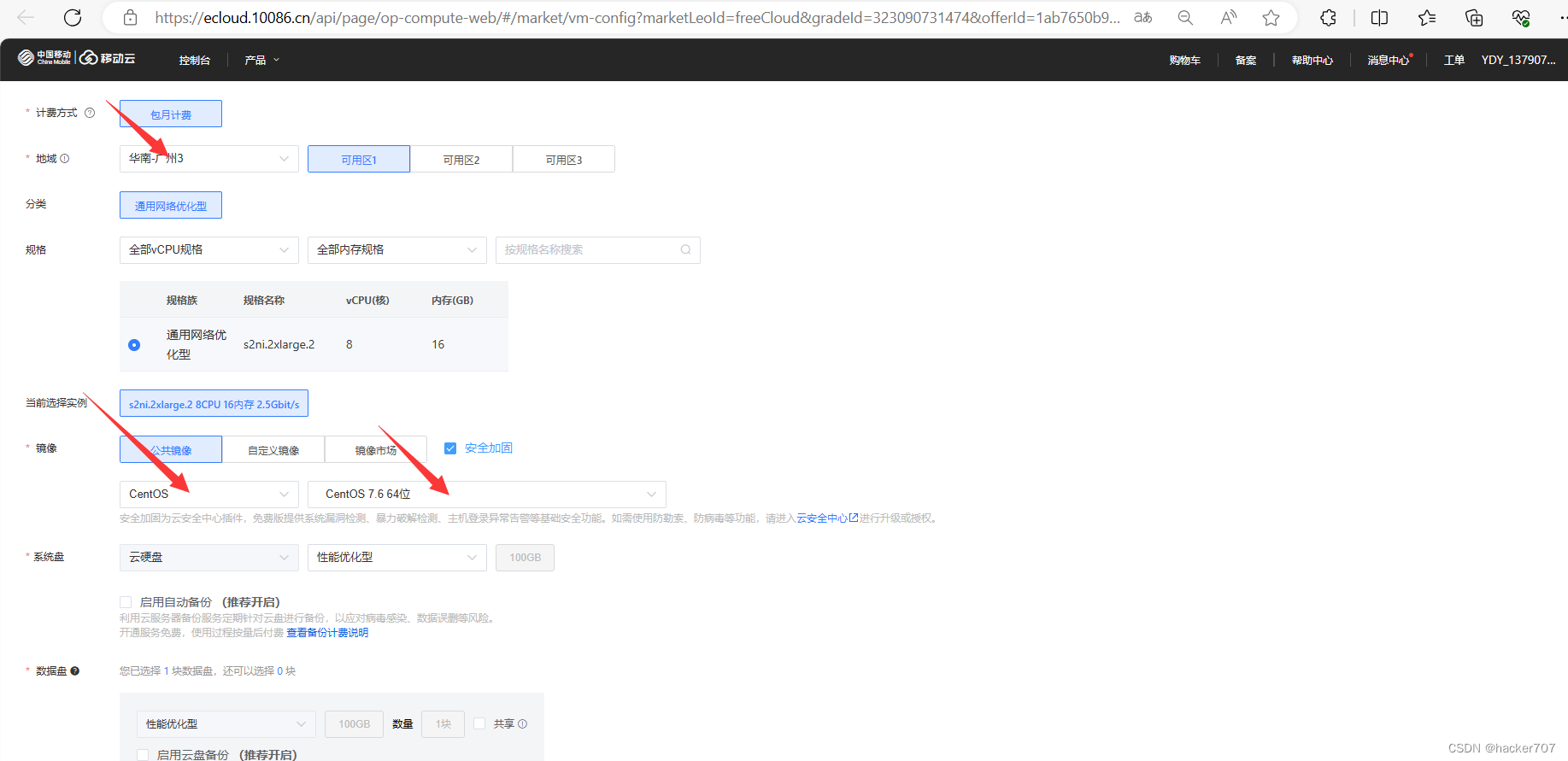
-
網絡配置(如果自己將要將自己的網站放在公網中時,需要先進行ICP備案。)以下操作將自己的網絡地址配置到自己的云主機中。

-
當前往支付完成后可以就得到一臺Linux服務器。
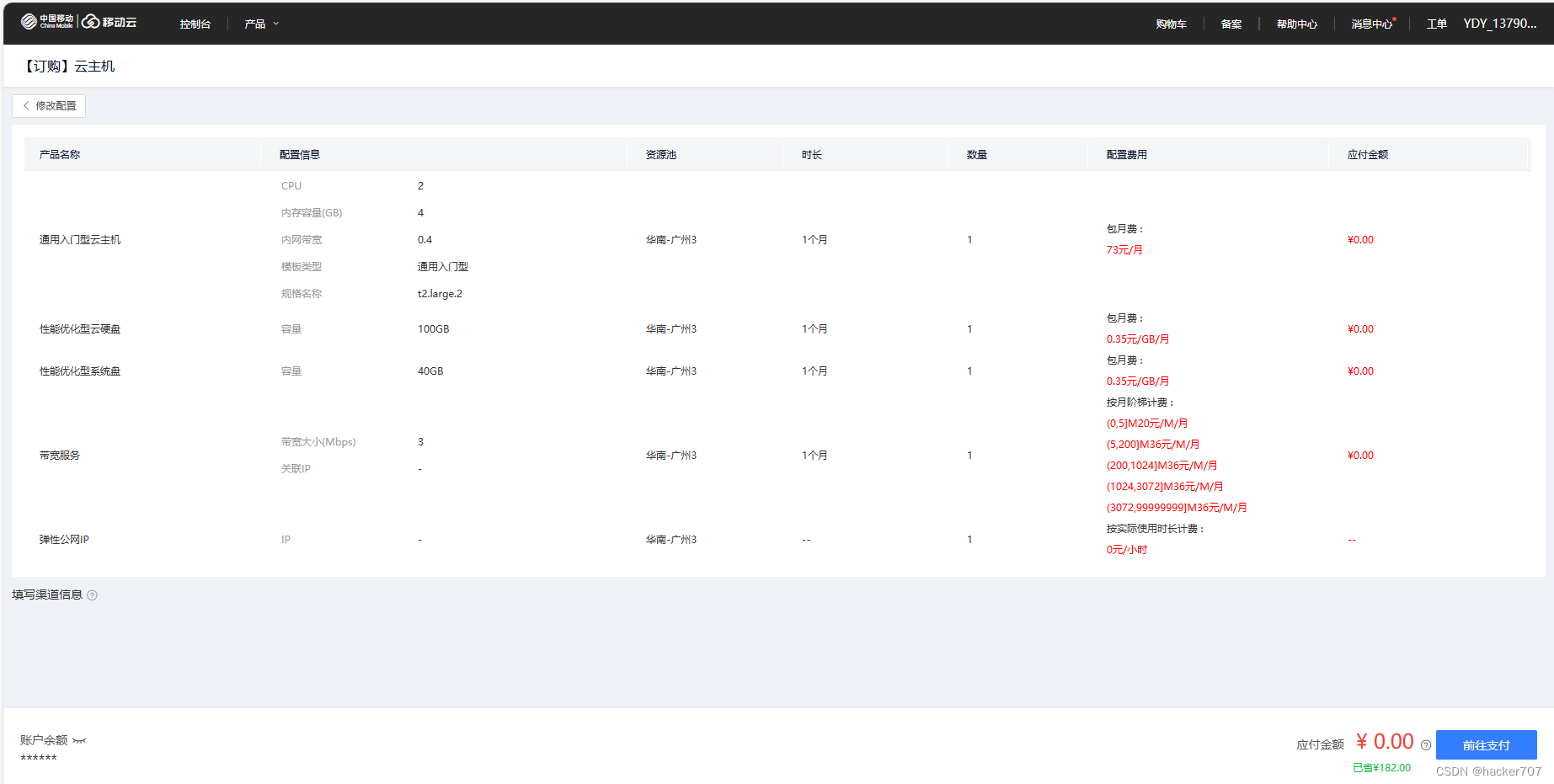
-
進行密碼修改
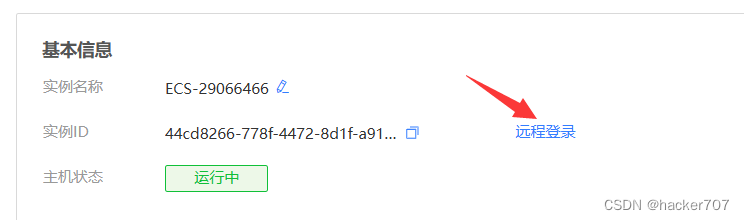
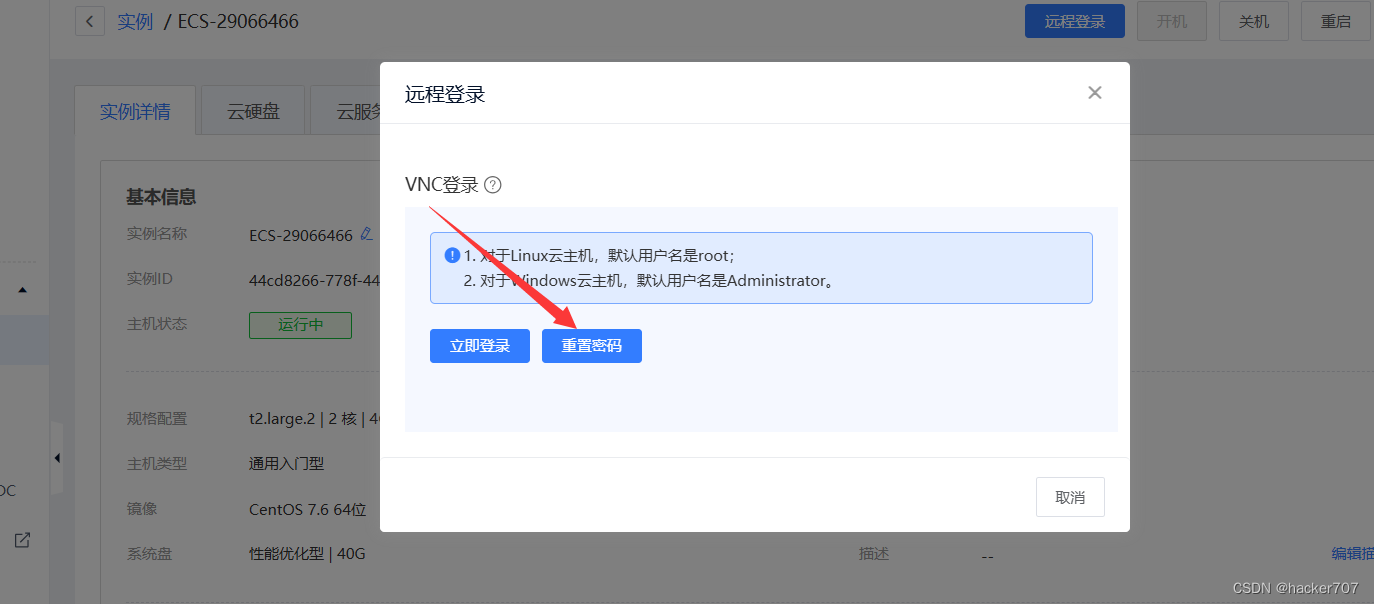
-
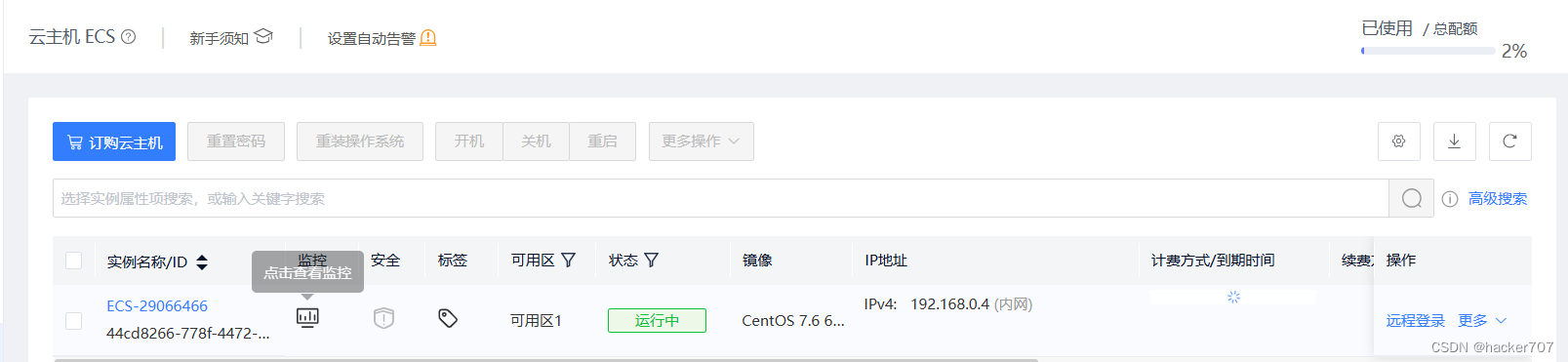
找到彈性公網IP,將系統默認給的公網IP分配給我們的云主機。
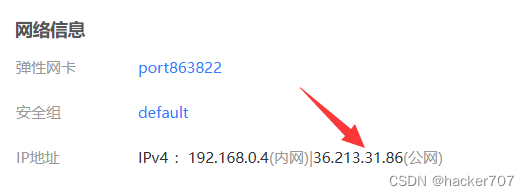
-
遠程登陸需要開放ssh端口(22)
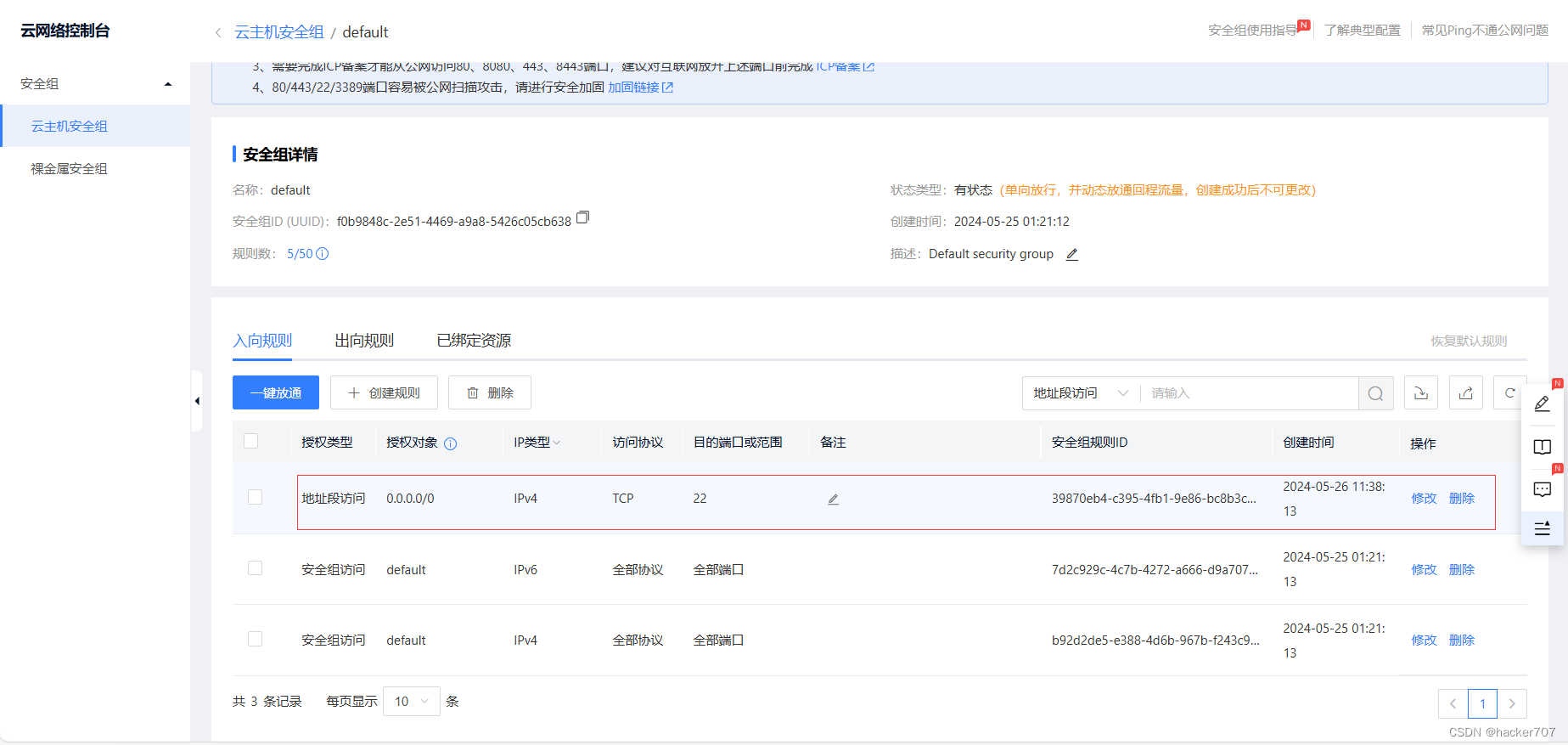
-
使用遠程登陸軟件,可以直接用vscode登陸,這里用xshell演示。
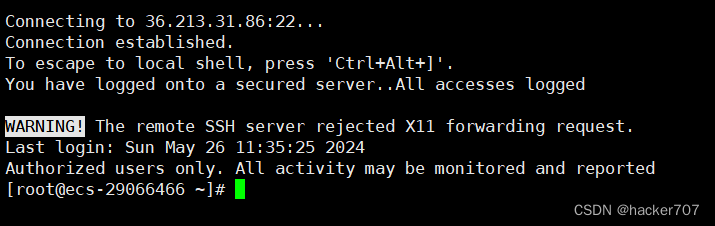
環境準備
- 安裝 Python 環境
在Linux操作系統中,盡管通常會預裝Python解釋器,但其版本往往較低,可能不符合ChatGLM所需的最小Python版本要求(3.7及以上)。因此,在大多數情況下,用戶需要部署一個符合要求的Python環境。然而,如果系統已經配備了滿足條件的Python版本,則無需重復安裝。
盡管可以選擇從源代碼下載并編譯安裝Python,但為了簡化安裝過程,確保PyTorch等庫的順利安裝,并避免對系統穩定性造成影響,推薦使用Anaconda發行版來安裝Python環境。
# 下載 conda 安裝包
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
# 安裝 conda 注意安裝過程中指定安裝路徑
bash Anaconda3-2023.03-1-Linux-x86_64.sh
# 配置軟連接
ln -s /[your-install-path]/anaconda3/condabin/conda /usr/bin/conda- 安裝 Git LFS
為了高效地從 Hugging Face Hub 上下載 ChatGLM 模型到本地,并提高加載模型的響應效率,推薦先安裝 Git LFS(Large File Storage)。Git LFS 是一種適用于 Git 倉庫的工具,它能夠優化大文件的管理,使得文件傳輸更加高效。
sudo yum install git -y
git --version
sudo yum install git-lfs -y
模型安裝
- 下載 ChatGLM3
首先,請從 Github 下載 ChatGLM3 倉庫,并在倉庫目錄下使用 pip 安裝所需的依賴。
根據官方推薦,為了獲得最佳的推理性能,建議使用 transformers 庫的 4.30.2 版本,以及 torch 2.0 或更高版本。
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
# conda 創建虛擬環境
conda create -n torch python=3.10
# 激活環境 # 退出環境 conda deactivate
conda activate torch
# 下載依賴包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
- 下載預訓練模型
下面我們用 Git LFS 從 Hugging Face Hub 將模型下載到本地,從本地加載模型響應速度更快。
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
如果從你從 HuggingFace 下載比較慢,也可以從 ModelScope 中下載!
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
模型使用
首先,將你從 THUDM/ChatGLM3-6b 下載的預訓練模型文件保存在 ChatGLM3 倉庫的適當目錄中。如果你是通過 ModelScope 獲取的模型,請確保目錄結構正確,因為加載模型時可能需要調整本地的路徑設置。
ChatGLM3 支持三種使用方式:命令行界面、網頁版界面和 API 接口。在運行模型之前,你需要找到對應使用方式的 Python 源代碼文件,即 cli_demo.py、web_demo.py 和 openai_api.py。在這些文件中,你需要修改一行代碼,使其指向你的模型文件。
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
修改兩個地方:(1)本地模型的存放路徑 THUDM/chatglm3-6b;(2)根據自己的硬件環境參考 DEPLOYMENT.md 選擇模型加載方式,float() CPU 部署,cuda() GPU 部署。
- 命令行版 cli_demo.py
命令行啟動方式,首先找到 ChatGLM3 目錄下的 cli_demo.py 文件,修改代碼如下:
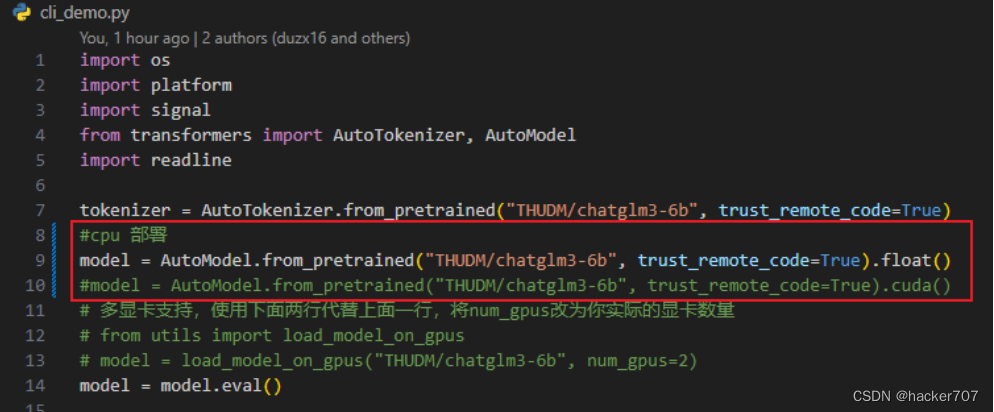
修改完成之后,到 ChatGLM3 目錄下運行 python cli_demo.py 啟動服務
程序會在命令行中進行交互式的對話,在命令行中通過 用戶: 進行輸入指示,直接輸入問題回車即可生成回復,輸入 clear 可以清空對話歷史,輸入 stop 終止程序。

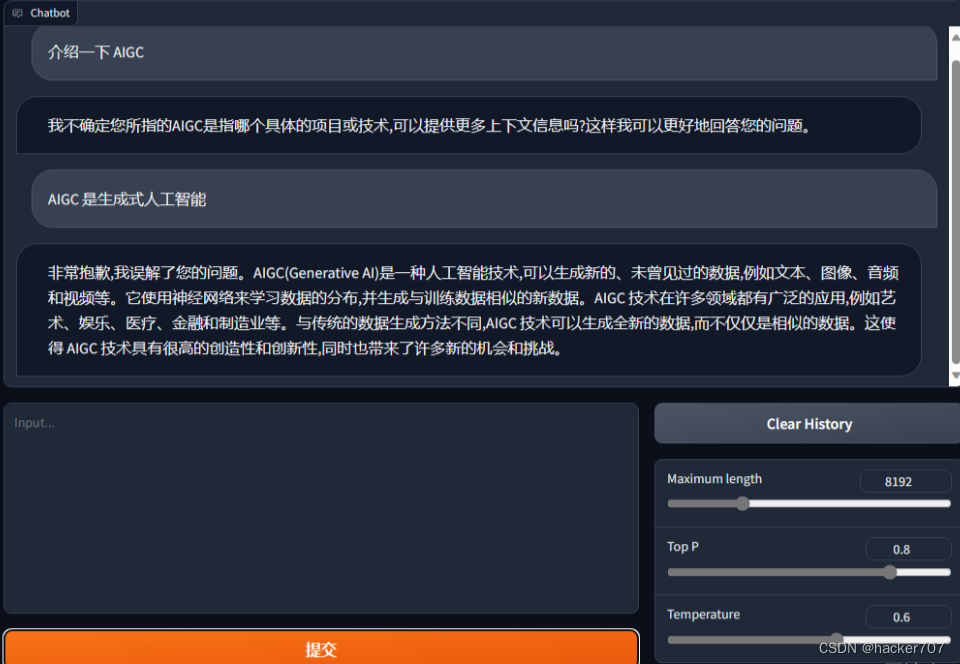
2. 網頁版 web_demo.py
網頁版和命令行相似,但是提供了更加友好交互頁面,找到 ChatGLM3 目錄下的 web_demo.py 文件,做出相同的代碼修改,
然后,到 ChatGLM3 目錄下運行 python web_demo.py 啟動服務
程序會運行一個 Web Server,并輸出一個訪問地址,在瀏覽器中打開輸出的地址即可使用。
3. API 部署 openai_api.py
這個部分將結合 ChatGPT-Next-Web為例,使得ChatGLM3 實現了 OpenAI 格式的流式 API 部署,這使得ChatGLM3可以作為任意基于 ChatGPT 的應用的后端。
首先,到 https://github.com/Yidadaa/ChatGPT-Next-Web/releases 下載 ChatGPT-Next-Web,這個交互頁面很輕量級。
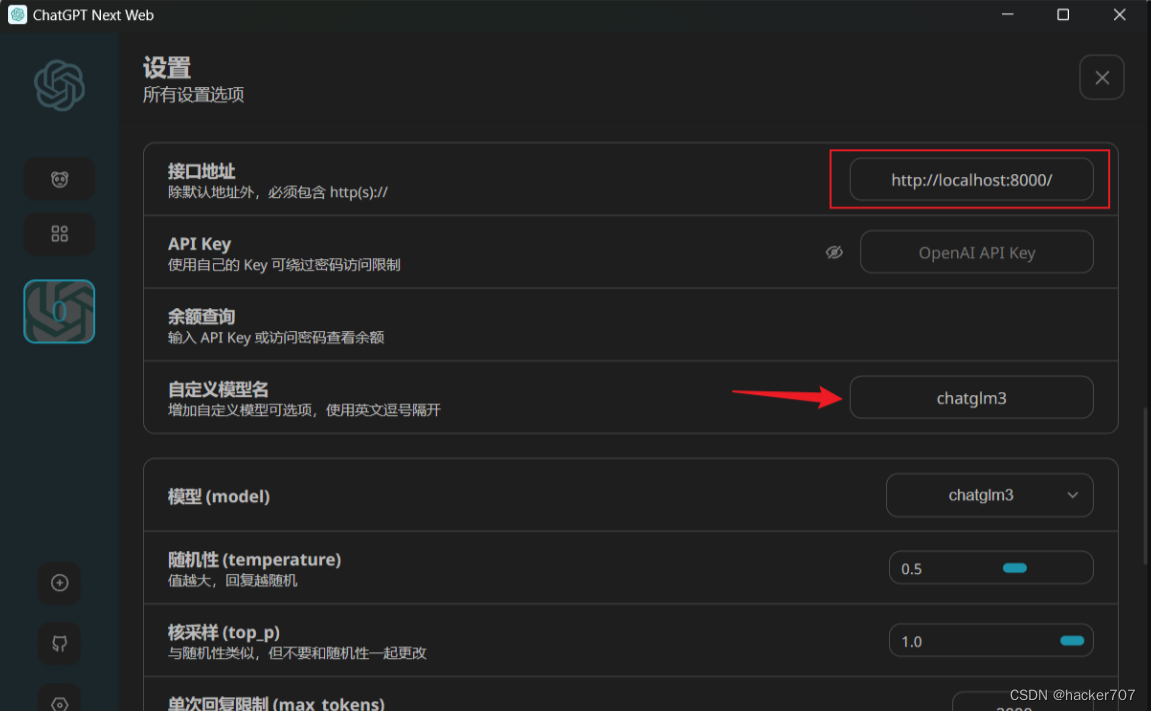
然后,到 ChatGLM3 目錄下找到 openai_api.py 源碼文件,和上面方式一樣,修改本地模型路徑和部署方式,還有根據自己需要修改最后一行代碼中定義的 Host 和 Port,這是 ChatGPT 應用的訪問 URL。

接著,在倉庫目錄下執行 python openai_api.py 啟動模型服務

然后將日志打印出的接口地址 http://localhost:8000/ 寫入 ChatGPT-Next-Web 的設置中,并添加自定義模型 chatglm3
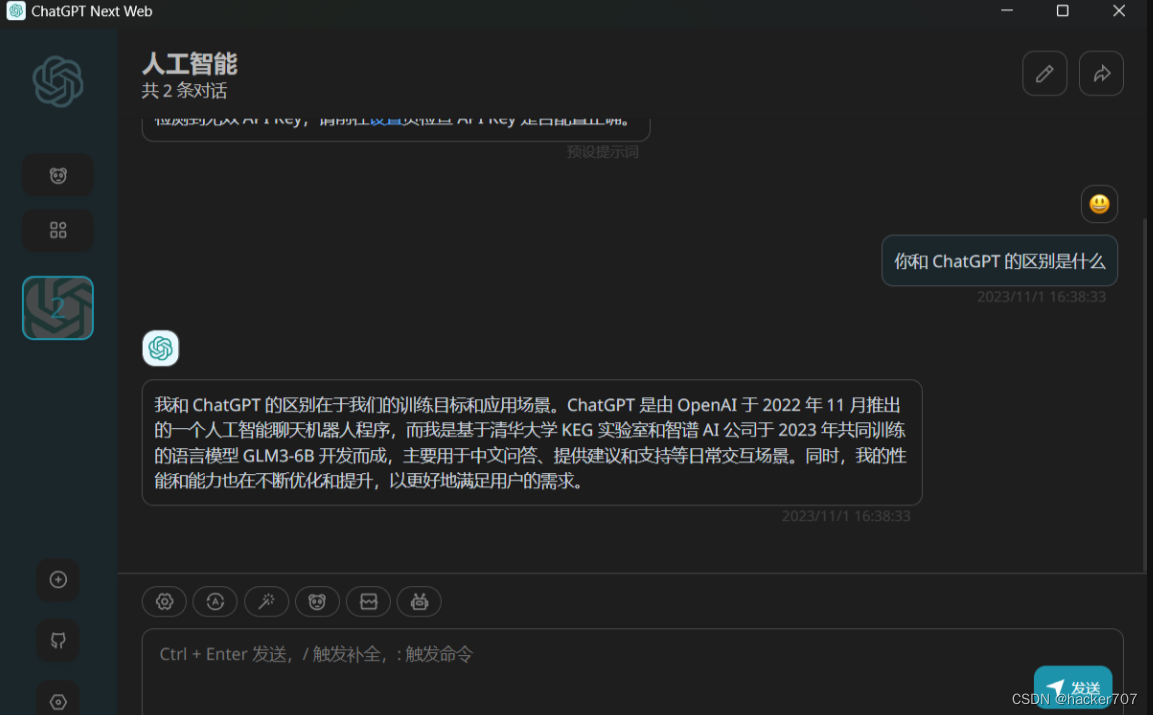
完成設置之后,API部署就完成了。
結束語
了解更多移動云產品請移步官網移動云官網













,直接可用)


![[ C++ ] 類和對象( 中 ) 2](http://pic.xiahunao.cn/[ C++ ] 類和對象( 中 ) 2)
樹與二叉樹)
--Spring框架中@Value注解和配置管理詳解)
