
簡單來講,FIFO-Diffusion先通過一些模型如VideoCraft2、zeroscope、Opem-Sora Plan等與FIFO-Diffusion的組合生成短視頻,然后取結尾的幀(也可以取多幀),再用這一幀的圖片生成另一段短視頻,然后拼接起來。FIFO-Diffusion對如何取幀、生成新視頻的時候引用往前的多少幀,以及如何去噪加噪做了算法優化。
相關鏈接
論文:arxiv.org/abs/2405.11473
項目:jjihwan.github.io/projects/FIFO-Diffusion
代碼:github.com/jjihwan/FIFO-Diffusion_public
論文閱讀

FIFO-Diffusion:無需訓練即可從文本生成無限視頻
摘要
我們提出了一種基于預訓練擴散模型的新穎推理技術,用于文本條件視頻生成。我們的方法稱為 FIFO-Diffusion,從概念上講,無需訓練即可生成無限長的視頻。這是通過迭代執行對角去噪來實現的,該去噪同時處理隊列中噪聲級別不斷增加的一系列連續幀;
我們的方法在頭部將完全去噪的幀出隊,同時在尾部將新的隨機噪聲幀入隊。然而,對角去噪是一把雙刃劍,因為靠近尾部的幀可以通過前向參考利用更干凈的幀,但這種策略會導致訓練和推理之間的差異。因此,我們引入潛在分區來減少訓練與推理之間的差距,并引入前向降噪來利用前向引用的優勢。
我們已經在現有的文本到視頻生成基線上展示了所提出的方法的有希望的結果和有效性。
方法
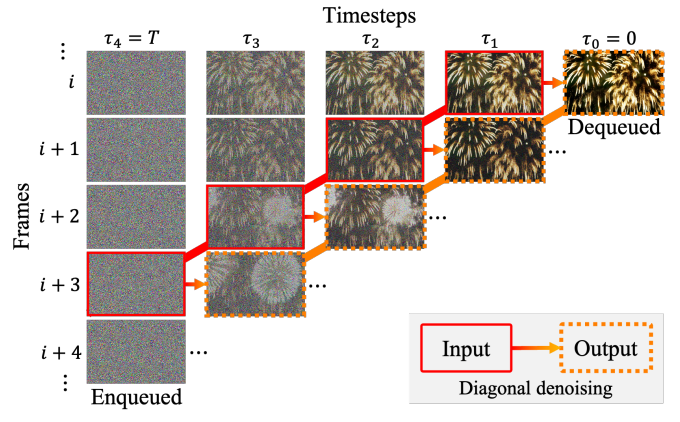
f = 4對角去噪示意圖。被實線包圍的框架是 被虛線包圍的幀是模型輸入的去噪版本。去噪后 當隨機噪聲進入隊列時,右上角完全去噪的實例被退出隊列。
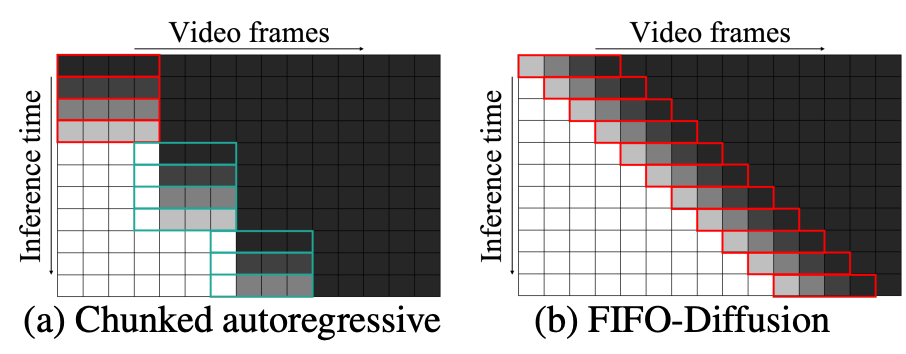
長視頻生成的分塊自回歸方法與FIFO-Diffusion方法的比較。隨機噪聲(黑色)被迭代去噪到圖像中模型的潛勢(白色)。紅色的盒子指出預訓練中的去噪網絡基本模型,綠框表示通過額外訓練得到的預測網絡。
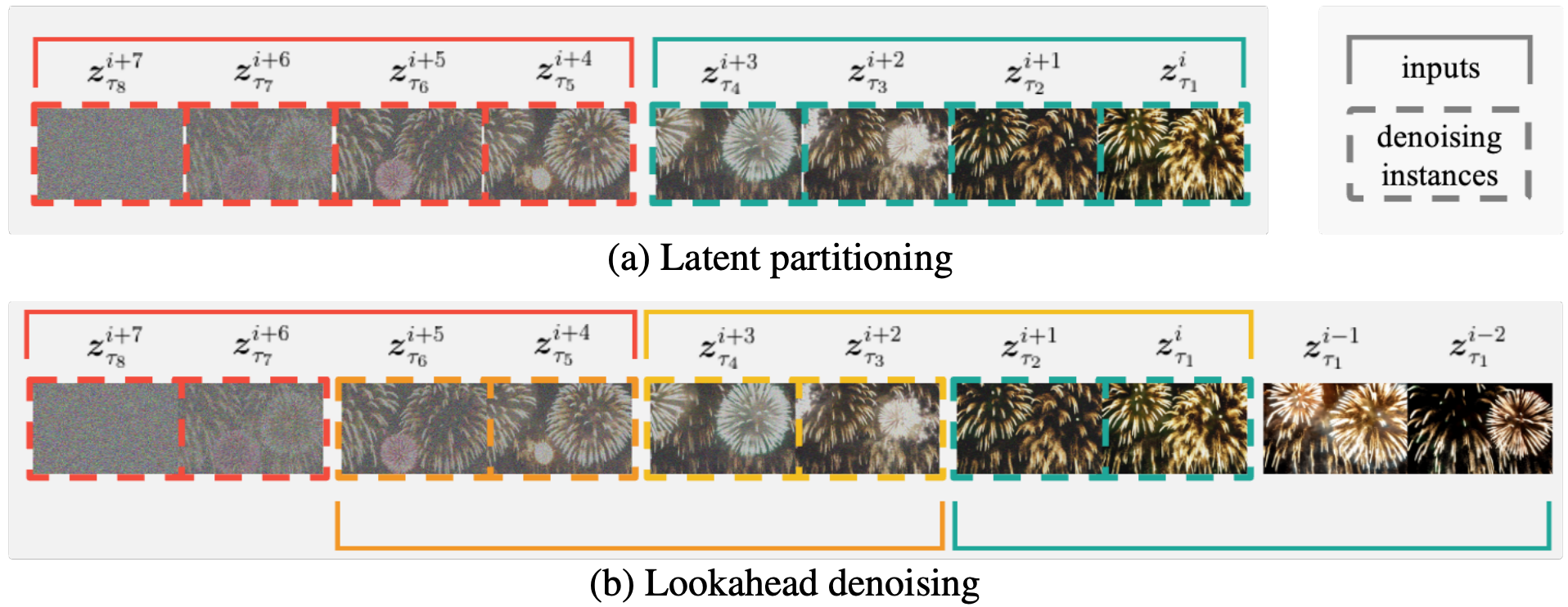
上圖為f = 4, n = 2時的潛在分區和前向去噪示意圖。
-
(a)潛在分區將擴散過程劃分為n個部分,以減少最大噪聲水平差異。
-
(b)在(a)上lookahead denoings使所有框架都能用足夠數量的以前框架來代替所有幀,而計算的計算是(a)的兩倍。
實驗
基于(a) Open-Sora計劃的FIFO-Diffusion生成的長視頻插圖。(b) VideoCrafter2,(c)基于VideoCrafter2的多個提示。電話上的號碼每個幀的左上角表示幀索引。

(a)森林里寧靜的冬日景色。森林被一層厚厚的雪覆蓋著,這……”

(b)“一個充滿活力的水下場景,一個潛水者探索沉船,2K,逼真的。”

(c)“一只老虎在草原上行走→站立→休息,逼真,4k,高清”

“一個漂浮在太空中的宇航員,高質量,4K分辨率。”
不同基線結果比較
VideoCrafter2

視頻生成的FIFO擴散與VideoCrafter2。左上角的數字每一幀表示幀索引。
VideoCrafter1

視頻生成的FIFO擴散與VideoCrafter1。左上角的數字 每一幀表示幀索引。
zeroscope

用zeroscope的FIFO擴散產生的視頻。
Open-Sora Plan

使用Open-Sora計劃的fifo擴散生成的視頻。
長視頻生成方法比較
與其他長視頻生成技術,Gen-L-Video, FreeNoise和LaVie SEINE。

(一)“一個充滿活力的水下場景,一個潛水者探索沉船,2K,逼真的。”

(二)“寧靜禪宗花園的全景,高品質,4K分辨率。”
結論
我們介紹了一種新穎的推理算法,即FIFO擴散,該算法允許從文本中生成無限長的視頻,而無需在短視頻片段上預測的視頻擴散模型。 我們的方法是通過進行對角線降解來實現的,后者以第一次出局的方式處理潛在的噪聲水平的增加。
在每一步中,一個完全去噪的實例被去排隊,而一個新的隨機實例被去排隊噪音是排隊的。雖然對角去噪具有關鍵的權衡,但我們提出了潛在分區克服其固有的局限性,前瞻性去噪,發揮其優勢。 把它們結合在一起,FIFO-Diffusion成功地生成了高質量的長視頻,展示了上下文一致性的精彩的場景和動態運動表達。




中,其中A列的每個值都與B列的所有值組合。)




:使用空間+文件預覽+文件分享+文件下載)


![[數據集][目標檢測]吸煙檢測數據集VOC+YOLO格式1449張1類別](http://pic.xiahunao.cn/[數據集][目標檢測]吸煙檢測數據集VOC+YOLO格式1449張1類別)






