介紹GPT-1,GPT-2,GPT-3,GPT-4?
GPT-1 介紹
2018年6月,OpenAI公司發表了論文"|mproving Language Understanding by Generative Pre-training”《用生成式預訓練提高模型的語言理解力》,推出了具有1.17億個參數的GPT-1(Generative Pre-trainingTransformers,生成式預訓練變換器)模型。
與BERT最大的區別:在于GPT-1采用了傳統的語言模型方法進行預訓練,即使用單詞的上文來預測單詞,而BERT是采用了雙向上下文的信息共同來預測單詞,
正是因為訓練方法上的區別,使得GPT更擅長處理自然語言生成任務(NLG),而BERT更擅長處理自然語言理解任務(NLU).
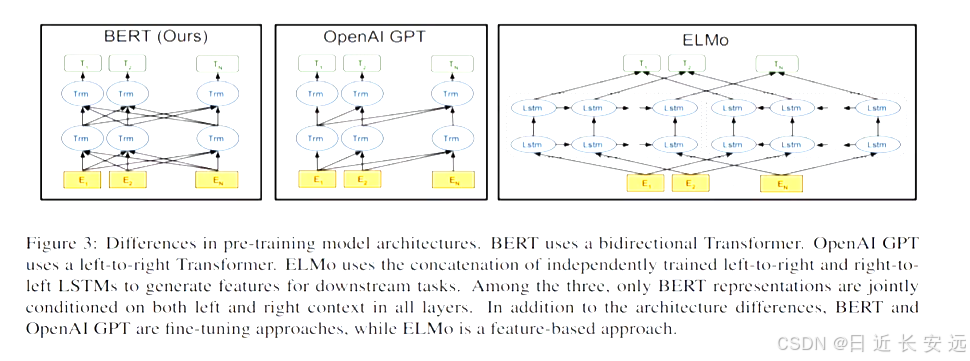
從上圖可以很清楚的看到GP1采用的是單向Iransfonmer模型,例如給定一個句子[u1,u2.,… un],GP1在預測單詞ui的時候只會利用[u1,u2.… u(i-1)]的信息,而BERT會同時利用上下文的信息[u1,u2,. u(i 1),u,...,u(i+1),....,un]
作為兩大模型的直接對比,BERT采用了tansformer的Ecoder模塊,而GPT采用了tansformer的Decode模塊。并且GPT的Decoder Block和經典tansformer Decode Block還有所不同,如下所示是一個(解碼)層(兩個模塊一起)
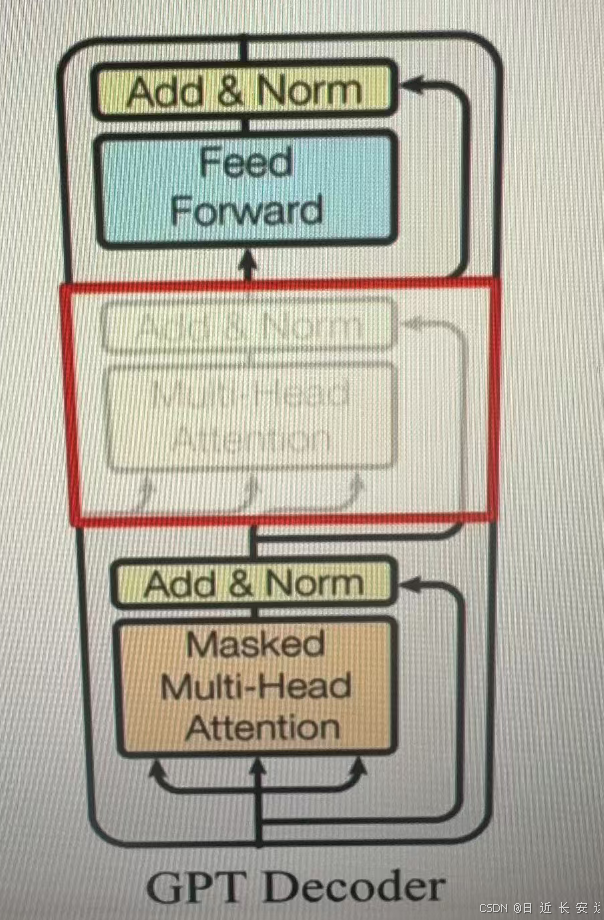
經典的包括3個子層,分別為msked multi-head attention(帶有掩碼的自注意力機制張量),encode-decoder attention層(正常的自注意力),以及Feed Forward層(前軌全連接層)。但GPT中取消了第二個層。?
add&norm 殘差鏈接+正則化處理
注點:對比經典的Transformer架構,解碼器摸塊采用了6個Decoder Block;GPT的架構中采用了12個Decoder Block.
GPT-1訓練過程
GPT-1的訓練包括兩階段過程:
第一階段: 無監督的預訓練語言模型
第二階段: 有監督的下游任務fine-tunning.
無監督的預訓練語言模型:

有監督的下游任務fine-tunning:

整體訓練過程架構圖
根據下游任務適配的過程分兩步:1、根據任務定義不同輸入,2、對不同任務增加不同的分類層

分類任務(Classification):將起始和終止token加入到原始序列兩端,輸入transformer中得到特征向量,最后經過一個全連接得到預測的概率分布;
文本蘊涵(Entailment):將前提(premise)和假設(hypothesis)通過分隔符(Delimiter)隔開,兩端加上起始和終止token.再依次通過transformer和全連接得到預測結果;
文本相似度(Similarity):輸入的兩個句子,正向和反向各拼接一次,然后分別輸入給transformer,得到的特征向量拼接后再送給全連接得到預測結果;
問答和常識推理(Multiple-Choice):將 N個選項的問題抽象化為N個二分類問題,即每個選項分別和內容進行拼接,然后各送入transformer和全連接中,最后選擇置信度最高的作為預測結果
GPT-1數據集:GPT-1使用了BooksCorpus數據集,這個數據集包含 7000 本沒有發布的書籍,選擇該部分數據集的原因:
1.數據集擁有更長的上下文依賴關系,得模型能學得更長期的依賴關系;
2.這些書籍因為沒有發布,所以很難在下游數據集上見到,更能驗證模型的泛化能力。
GPT-1特點:
優點:1.在有監督學習的12個任務中,GPT-1在9個任務上的表現超過了state-of-the-art的模型(sota)
2.利用Transformer做特征抽取,能夠捕捉到更長的記憶信息,且較傳統的 RNN 更易于并行化
缺點:1.GPT 最大的問題就是傳統的語言模型是單向的.
2.針對不同的任務,需要不同的數據集進行模型微調,相對比較麻煩(數據集、人力、算力)
GPT-1模型總結
GPT-1證明了transformer對學習詞向量的強大能力,在GPT-1得到的詞向量基礎上進行下游任務的學習(微調),能夠讓下游任務取得更好的泛化能力.對于下游任務的訓練,GPT-1往往只需要簡單的微調便能取得非常好的效果。
GPT-1在未經微調的任務上雖然也有一定效果,但是其泛化能力遠遠低于經過微調的有監督任務,說明了GPT-1只是一個簡單的領域專家,而非通用的語言學家.
GPT2?
2019年2月,openAl推出了GPT-2,同時,他們發表了介紹這個模型的論文"Language Models areUnsupervised Multitask Learners”(語言模型是無監督的多任務學習者).相比于GPT-1,GPT-2突出的核心思想為多任務學習,其目標旨在僅采用無監督預訓練得到一個泛化能力更強的語言模型,直接應用到下游仟務中,GRT-2并沒有對GPT-1的網絡結構進行過多的創新與設計,而是使用了更多的網絡參數與更大的數據集: 最大模型共計48層,參數量達15億
嵌入維度
架構微小改動:
1.LN層被放置在Self-Attention層和Feed Forward層前,而不是像原來那樣后置
2.在最后一層Tansfomer Block后增加了LN層
GPT-2訓練核心思想:
目前最好的 NLP 模型是結合無監督的 Pre-training 和監督學習的 Fune-tuning,但這種方法的缺點是針對某特定任務需要不同類型標注好的訓練數據,GPT-2的作者認為這是狹隘的專家而不是通才,因此該作者希望能夠通過無監督學習訓練出一個可以應對多種任務的通用系統.因此,GPT-2的訓練去掉了Fune-tuning只包括無監督的預訓練過程,和GPT-1第一階段訓練一樣,也屬于一個單向語言模型。
GPT-2模型的學習目標: 使用無監督的預訓練模型做有監督的任務
1.語言模型其實也是在給序列的條件概率建模,即p(sn|s1,s2.…sn-1)
2.任何有監督任務,其實都是在估計p(output|input),通常我們會用特定的網絡結構去給任務建模,但如果要做通用模型,它需要對p(output |input,task)建模,對于NLP任務的input和output,我們平常都可以用向”表示,而對于task,其實也是一樣的,18年已經有研究對task進行過建模了,這種模型的一條訓練樣本可以表示為:(translate to french,English text,french text),實驗證明以這種數據形式可以有監督地訓練一個single model,其實也就是對一個模型進行有監督的多任務學習.
語言模型=無監督多任務學習,相比于有監督的多任務學習,語言模型只是不需要顯示地定義哪些字段是要預測的輸出,所以,實際上有監督的輸出只是語言模型序列中的一個子集,舉個例子,比如我在訓練語言模型時,有一句話"The translation of word Machine Learning in chinese is 機器學習”,那在訓練完這句話時語言模型就自然地將翻譯任務和任務的輸入輸出都學到了
再比如,當模型訓練完"MichealJordanis thebest basketbal player in the history"語料的語言模型之后,便也學會了(question: "who is the bestbasketball player in the history ?",answer:"Micheal jordan")的Q&A任務
基于上面的思想,作者將GPT-2模型根據給定輸入與任務來做出相應的輸出,那么模型就可以表示成下面這個樣子:p(outputlinput,task),例如可以直接輸入:(“自然語言處理”,中文翻譯)來得到我們需要的結果(“Nature Language Processing”),因此提出的模型可以將機器翻譯,自然語言推理,語義分析,關系提取等10類任務統一建模為一個任務,而不再為每一個子任務單獨設計一個模型.綜上,GPT-2的核心思想概括為:任何有監督任務都是語言模型的一個子集,當模型的容量非常大且數據量足夠豐富時,僅僅靠訓練語言模型的學習便可以完成其他有監督學習的任務:
GPT-2的數據集:于Reddit上高贊的文章,命名為WebText,數據集共有約800萬篇文章,累計體積約40G.為了避免和測試集的沖突,WebText移除了涉及Wikipedia的文章,
特點:
優點
1.文本生成效果好,在8個語言模型任務中,僅僅通過zero-shot學習,GPT-2就有7個超過了state-of-the-art的方法.
海量數據和大量參數訓練出來的詞向量模型,可以遷移到其它類別任務中而不需要額外的訓練.
缺點
1.無監督學習能力有待提升
2.有些任務上的表現不如隨機
GPT-2模型總結
GPT-2的最大貢獻是驗證了通過海量數據和大量參數訓練出來的詞向量模型有遷移到其它類別任務中而不需要額外的訓練,但是很多實驗也表明,GPT-2的無監督學習的能力還有很大的提升空間,甚至在有些任務上的表現不比隨機的好,盡管在有些zero-shot的任務上的表現不錯,但是我們仍不清楚GPT-2的這種策略究竟能做成什么樣子.GPT-2表明隨著模型容量和數據量的增大,其潛能還有進一步開發的空間,基于這個思想,誕生了我們下面要介紹的GPT-3.
GPT3
2020年5月,OpenAl發布了GPT-3,同時發表了論文"Language Models are Few-Shot Learner”《小樣本學習者的語言模型》
GPT-3 作為其先前語言模型(LM)GPT-2 的繼承者.它被認為比GPT-2更好、更大.事實上,與他語言模型相比OpenAI GPT-3 的完整版擁有大約 1750 億個可訓練參數,是迄今為止訓練的最大模型,這份 72 頁的研究論文非常詳細地描述了該模型的特性、功能、性能和局限性
實際上GPT-3 不是一個單一的模型,而是一個模型系列,系列中的每個模型都有不同數量的可訓練參數
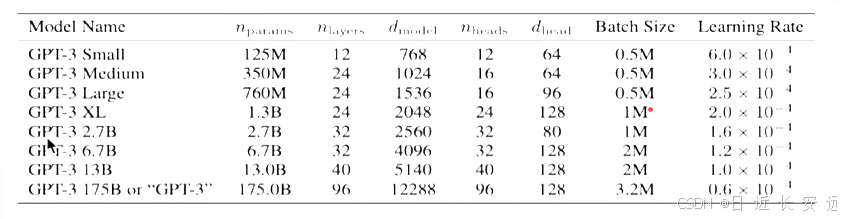
事實上,GPT-3系列模型結構與GPT-2完全一致,為了探究機器學習性能和模型參數的關系,作者分別訓練了包含1.25億至1750億參數的8個模型,并把1750億參數的模型命名為GPT-3.其中最大版本 GPT-3 1758 或“GPT-3"縣有175個B參數,96層的多頭Transformer、Head size為96、詞向量維度為12288、文本長度大小為2048.
GPT-3訓練核心思想:GPT-3模型訓練的思想與GPT-2的方法相似,去除了fine-tune過程,只包括預訓練過程,不同只在于采用了參數更多的模型、更豐富的數據集和更長的訓練的過程.
但是GPT-3 模型在進行下游任務時采用了一種新的思想,即情境學習(in-context learning),情境學習理解: 在被給定的幾個任務示例或一個任務說明的情況下,模型應該能通過簡單預測以補全任務中其他的實例.即情境學習要求預訓練模型要對任務本身進行理解,在GPT-3模型中給出了三種不同類型的情景學習,他們分別是:Few-shot、One-shot、Zero-shot.
傳統的微調策略存在問題:
1.微調需要對每一個任務有一個任務相關的數據集以及和任務相關的微調。
2.需要一個相關任務大的數據集,而且需要對其進行標注。
3.當一個樣本沒有出現在數據分布的時候,泛化性不見得比小模型要好.
Zero-shot:
The model predicts the answer given only a natural languagedescription of the task. No gradient updates are performed.
定義:給出任務的描述,然后提供測試數據對其進行預測,直接讓預訓練好的模型去進行任務測試
One-shot:
In addition to the task description, the model sees a single example of the task. No gradient updates are performed.
定義:在預訓練和真正翻譯的樣本之間,插入一個樣本做指導,相當于在預訓練好的結果和所要執行的任務中之間,給一個例子,告訴模型英語翻譯為法語,應該這么翻譯.
示例: 向模型輸入"這個任務要求將中文翻譯為英文,你好->helo,銷售->”,然后要求模型預測下一個輸出應0該是什么,正確答案應為“sell”.
Few-shot:
In addition to the task description, the model sees a few examples of the task, No gradient updates are performed
定義:在預訓練和真正翻譯的樣本之間,插入多個樣本做指導,相當于在預訓練好的結果和所要執行的任務之間,給多個例子,告訴模型應該如何工作,
示例: 向模型輸入"這個任務要求將中文翻譯為英文,你好->hello,再見->goodbye,購買->purchase,銷售->”,然后要求模型預測下一個輸出應該是什么,正確答案應為“sell".
GPT-3的數據集:一般來說,模型的參數越多,訓練模型所需的數據就越多,GPT-3共訓練了5個不同的語料大約 45 TB 的文本數據,分別是低質量的Common Crawl,高質量WebText2,Books1,Books2和Wikipedia,GPT-3根據數據集的不同的質量賦予了不同的權值,權值越高的在訓練的時候越容易抽樣到,如下表所示:
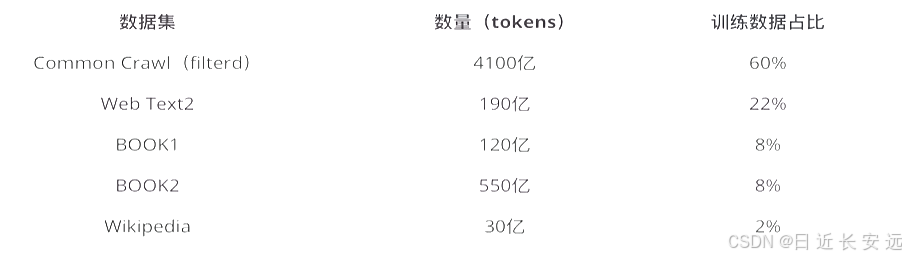
Common Crawl語料庫包含在8年的網絡爬行中收集的PB 級數據,語料庫包含原始網頁數據、元數據提取和帶有光過濾的文本提取
WebText2是來自具有 3+ upvotes 的帖子的所有出站 Reddit 鏈接的網頁文本
Books1和Books2是兩個基于互聯網的圖書語料庫
英文維基百科頁面 也是訓練語料庫的一部分.
特點:
優點
1.去除了fune-tuning任務
2.整體上,GPT-3在zero-shot或one-shot設置下能取得尚可的成績,在few-shot設置下有可能超越基于fine-tune的SOTA模型
缺點
1.由于40TB海量數據的存在,很難保證GPT-3生成的文章不包含一些非常敏感的內容
2.對于部分任務比如:“判斷命題是否有效“等,會給出沒有意義的答案
GPT-3模型總結
GPT系列從1到3,通通采用的是transformer架構,可以說模型結構并沒有創新性的設計.GPT-3的本質還是通過海量的參數學習海量的數據,然后依賴transformer強大的擬合能力使得模型能夠收斂,得益于龐大的數據集,GPT-3可以完成一些令人感到驚喜的任務,但是GPT-3也不是萬能的,對于一些明顯不在這個分布或者和這個分布有沖突的任務來說,GPT-3還是無能為力的.
GPT4~4.5
最新介紹,保持熱情!!!



















)
