1 前提tip
1.1 使用什么數據類型訓練模型?
- Llama2模型是使用bfloat16訓練的
- 上傳到Hub的檢查點使用torch_dtype = 'float16',這將通過AutoModel API將檢查點從torch.float32轉換為torch.float16。
- 在線權重的數據類型通常無關緊要,這是因為模型將首先下載(使用在線檢查點的數據類型),然后轉換為torch的默認數據類型(變為torch.float32),最后,如果配置中提供了torch_dtype,則會使用它。
- 不建議在float16中訓練模型,因為已知會產生nan;因此,應該在bfloat16中訓練模型
1.2 Llama2 的tokenizer
- LlaMA的tokenizer是基于sentencepiece的BPE模型。
- sentencepiece的一個特點是,在解碼序列時,如果第一個令牌是詞的開頭(例如“Banana”),令牌器不會在字符串前添加前綴空格。?
2? transformers.LlamaConfig
根據指定的參數實例化LLaMA模型,定義模型架構。使用默認值實例化配置將產生與LLaMA-7B相似的配置
2.1 參數介紹
| vocab_size | (int, 可選,默認為32000) — LLaMA模型的詞匯量大小。 定義 通過調用LlamaModel時傳遞的inputs_ids表示的不同令牌的數量。 |
| hidden_size | (int, 可選,默認為4096) — 隱藏表示的維度 |
| intermediate_size | (int, 可選,默認為11008) — MLP表示的維度 |
| num_hidden_layers? | (int, 可選,默認為32) — 解碼器中的隱藏層數量 |
| num_attention_heads | (int, 可選,默認為32) — 解碼器中每個注意力層的注意力頭數。 |
| hidden_act | (str或函數, 可選,默認為"silu") — 解碼器中的非線性激活函數 |
| max_position_embeddings | (int, 可選,默認為2048) — 該模型可能使用的最大序列長度。 Llama 1支持最多2048個令牌,Llama 2支持最多4096個,CodeLlama支持最多16384個。 |
| initializer_range | (float, 可選,默認為0.02) — 用于初始化所有權重矩陣的截斷正態初始化器的標準差 |
| rms_norm_eps | (float, 可選,默認為1e-06) — rms歸一化層使用的epsilon |
| use_cache | (bool, 可選,默認為True) — 模型是否應返回最后的鍵/值注意力 |
| pad_token_id | (int, 可選) — 填充令牌id |
| bos_token_id | (int, 可選,默認為1) — 開始流令牌id |
| eos_token_id | int, 可選,默認為2) — 結束流令牌id |
| attention_bias | (bool, 可選,默認為False) — 在自注意力過程中的查詢、鍵、值和輸出投影層中是否使用偏置 |
| attention_dropout | (float, 可選,默認為0.0) — 注意力概率的丟棄率 |
| mlp_bias | (bool, 可選,默認為False) — 在MLP層中的up_proj、down_proj和gate_proj層中是否使用偏置 |
2.2 舉例
from transformers import LlamaModel, LlamaConfigconfiguration = LlamaConfig()
# 默認是Llama-7B的配置
configuration
'''
LlamaConfig {"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 1,"eos_token_id": 2,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 11008,"max_position_embeddings": 2048,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 32,"pretraining_tp": 1,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 10000.0,"tie_word_embeddings": false,"transformers_version": "4.41.0","use_cache": true,"vocab_size": 32000
}
'''3 transformers.LlamaTokenizer?
構建一個Llama令牌器。基于字節級Byte-Pair-Encoding。
默認的填充令牌未設置,因為原始模型中沒有填充令牌。
3.1 參數介紹
| vocab_file | (str) — 詞匯文件的路徑 |
| unk_token | (str或tokenizers.AddedToken, 可選, 默認為"<unk>") — 未知令牌。 不在詞匯表中的令牌將被設置為此令牌。 |
| bos_token | (str或tokenizers.AddedToken, 可選, 默認為"<s>") — 預訓練期間使用的序列開始令牌。 可以用作序列分類器令牌 |
| eos_token | (str或tokenizers.AddedToken, 可選, 默認為"</s>") — 序列結束令牌 |
| pad_token | (str或tokenizers.AddedToken, 可選) — 用于使令牌數組大小相同以便批處理的特殊令牌。 在注意力機制或損失計算中將其忽略。 |
| add_bos_token | (bool, 可選, 默認為True) — 是否在序列開始處添加bos_token。 |
| add_eos_token | (bool, 可選, 默認為False) — 是否在序列結束處添加eos_token。 |
| use_default_system_prompt | (bool, 可選, 默認為False) — 是否使用Llama的默認系統提示。 |
4??transformers.LlamaTokenizerFast
4.1 參數介紹
| vocab_file | (str) —SentencePiece文件(通常具有.model擴展名),包含實例化分詞器所需的詞匯表。 |
| tokenizer_file | (str, 可選) — 分詞器文件(通常具有.json擴展名),包含加載分詞器所需的所有內容。 |
| clean_up_tokenization_spaces | (bool, 可選, 默認為False) — 解碼后是否清理空格,清理包括移除潛在的如額外空格等人工痕跡。 |
| unk_token | (str或tokenizers.AddedToken, 可選, 默認為"<unk>") — 未知令牌。 不在詞匯表中的令牌將被設置為此令牌。 |
| bos_token | (str或tokenizers.AddedToken, 可選, 默認為"<s>") — 預訓練期間使用的序列開始令牌。 可以用作序列分類器令牌 |
| eos_token | (str或tokenizers.AddedToken, 可選, 默認為"</s>") — 序列結束令牌 |
| pad_token | (str或tokenizers.AddedToken, 可選) — 用于使令牌數組大小相同以便批處理的特殊令牌。 在注意力機制或損失計算中將其忽略。 |
| add_bos_token | (bool, 可選, 默認為True) — 是否在序列開始處添加bos_token。 |
| add_eos_token | (bool, 可選, 默認為False) — 是否在序列結束處添加eos_token。 |
| use_default_system_prompt | (bool, 可選, 默認為False) — 是否使用Llama的默認系統提示。 |
?4.2 和 LlamaTokenizer的對比
調用from_pretrained從huggingface獲取已有的tokenizer時,可以使用AutoTokenizer和LlamaTokenizerFast,不能使用LlamaTokenizer
from transformers import AutoTokenizertokenizer1=AutoTokenizer.from_pretrained('meta-llama/Meta-Llama-3-8B')
tokenizer1.encode('Hello world! This is a test file for Llama tokenizer')
#[128000, 9906, 1917, 0, 1115, 374, 264, 1296, 1052, 369, 445, 81101, 47058]from transformers import LlamaTokenizerFasttokenizer2=LlamaTokenizerFast.from_pretrained('meta-llama/Meta-Llama-3-8B')
tokenizer2.encode('Hello world! This is a test file for Llama tokenizer')
#[128000, 9906, 1917, 0, 1115, 374, 264, 1296, 1052, 369, 445, 81101, 47058]from transformers import LlamaTokenizertokenizer3=LlamaTokenizer.from_pretrained('meta-llama/Meta-Llama-3-8B')
tokenizer3.encode('Hello world! This is a test file for Llama tokenizer')
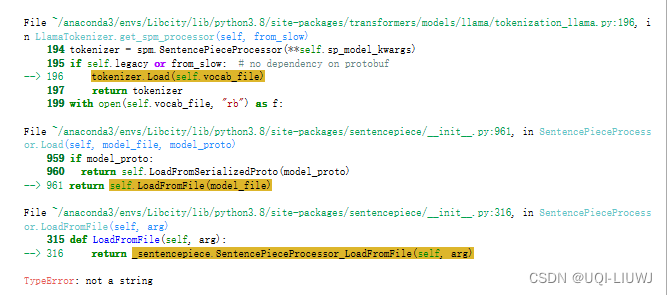
5?LlamaModel
5.1 參數介紹
- config
- 模型配置類,包含模型的所有參數
- 使用配置文件初始化不會加載與模型相關的權重,只加載配置
- 使用from_pretrained() 方法以加載模型權重
5.2 介紹
- LLaMA 模型的基本形式,輸出原始隱藏狀態,頂部沒有任何特定的頭部。
- 這個模型繼承自 PreTrainedModel
- 此模型也是 PyTorch torch.nn.Module 的子類
- 解碼器包括 config.num_hidden_layers 層。每層是一個 LlamaDecoderLayer
使用前面的LlamaConfig:
from transformers import LlamaModel, LlamaConfigconfiguration = LlamaConfig()
# 默認是Llama-7B的配置model=LlamaModel(configuration)
model
'''
LlamaModel((embed_tokens): Embedding(32000, 4096)(layers): ModuleList((0-31): 32 x LlamaDecoderLayer((self_attn): LlamaSdpaAttention((q_proj): Linear(in_features=4096, out_features=4096, bias=False)(k_proj): Linear(in_features=4096, out_features=4096, bias=False)(v_proj): Linear(in_features=4096, out_features=4096, bias=False)(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(rotary_emb): LlamaRotaryEmbedding())(mlp): LlamaMLP((gate_proj): Linear(in_features=4096, out_features=11008, bias=False)(up_proj): Linear(in_features=4096, out_features=11008, bias=False)(down_proj): Linear(in_features=11008, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): LlamaRMSNorm()(post_attention_layernorm): LlamaRMSNorm()))(norm): LlamaRMSNorm()
)
'''model.from_pretrained('meta-llama/Meta-Llama-3-8B')
model
'''
LlamaModel((embed_tokens): Embedding(32000, 4096)(layers): ModuleList((0-31): 32 x LlamaDecoderLayer((self_attn): LlamaSdpaAttention((q_proj): Linear(in_features=4096, out_features=4096, bias=False)(k_proj): Linear(in_features=4096, out_features=4096, bias=False)(v_proj): Linear(in_features=4096, out_features=4096, bias=False)(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(rotary_emb): LlamaRotaryEmbedding())(mlp): LlamaMLP((gate_proj): Linear(in_features=4096, out_features=11008, bias=False)(up_proj): Linear(in_features=4096, out_features=11008, bias=False)(down_proj): Linear(in_features=11008, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): LlamaRMSNorm()(post_attention_layernorm): LlamaRMSNorm()))(norm): LlamaRMSNorm()
)
'''5.3 forward方法
參數:
| input_ids | torch.LongTensor,形狀為 (batch_size, sequence_length)) 輸入序列token在詞匯表中的索引 索引可以通過 AutoTokenizer 獲取【PreTrainedTokenizer.encode()】 |
| attention_mask | torch.Tensor,形狀為 (batch_size, sequence_length),可選) 避免對填充標記索引執行注意力操作的掩碼。 掩碼值在 [0, 1] 中選擇:
|
| inputs_embeds | (torch.FloatTensor,形狀為 (batch_size, sequence_length, hidden_size) 選擇性地,可以直接傳遞嵌入表示,而不是傳遞 input_ids |
| output_attentions | (布爾值,可選)— 是否返回所有注意力層的注意力張量。 |
| output_hidden_states | (布爾值,可選)— 是否返回所有層的隱藏狀態 |
5.3.1 舉例
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")a=m.forward(inputs.input_ids)a.keys()
#odict_keys(['last_hidden_state', 'past_key_values'])a.last_hidden_state
'''
tensor([[[ 4.0064, -0.4994, -1.9927, ..., -3.7454, 0.8413, 2.6989],[-1.5624, 0.5211, 0.1731, ..., -1.5174, -2.2977, -0.3990],[-0.7521, -0.4335, 1.0871, ..., -0.7031, -1.8011, 2.0173],...,[-3.5611, -0.2674, 1.7693, ..., -1.3848, -0.4413, -1.6342],[-1.2451, 1.5639, 1.5049, ..., 0.5092, -1.2059, -2.3104],[-3.2812, -2.2462, 1.8884, ..., 3.7066, 1.2010, 0.2117]]],grad_fn=<MulBackward0>)
'''a.last_hidden_state.shape
#torch.Size([1, 13, 4096])len(a.past_key_values)
#32a.past_key_values[1][0].shape
#torch.Size([1, 8, 13, 128])
6?LlamaForCausalLM?
用于對話系統
6.1 forward方法
參數:
| input_ids | torch.LongTensor,形狀為 (batch_size, sequence_length)) 輸入序列token在詞匯表中的索引 索引可以通過 AutoTokenizer 獲取【PreTrainedTokenizer.encode()】 |
| attention_mask | torch.Tensor,形狀為 (batch_size, sequence_length),可選) 避免對填充標記索引執行注意力操作的掩碼。 掩碼值在 [0, 1] 中選擇:
|
| inputs_embeds | (torch.FloatTensor,形狀為 (batch_size, sequence_length, hidden_size) 選擇性地,可以直接傳遞嵌入表示,而不是傳遞 input_ids |
| output_attentions | (布爾值,可選)— 是否返回所有注意力層的注意力張量。 |
| output_hidden_states | (布爾值,可選)— 是否返回所有層的隱藏狀態 |
6.2? 舉例
from transformers import LlamaForCausalLMm1=LlamaForCausalLM.from_pretrained('meta-llama/Meta-Llama-3-8B')
m1
'''
LlamaForCausalLM((model): LlamaModel((embed_tokens): Embedding(128256, 4096)(layers): ModuleList((0-31): 32 x LlamaDecoderLayer((self_attn): LlamaSdpaAttention((q_proj): Linear(in_features=4096, out_features=4096, bias=False)(k_proj): Linear(in_features=4096, out_features=1024, bias=False)(v_proj): Linear(in_features=4096, out_features=1024, bias=False)(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(rotary_emb): LlamaRotaryEmbedding())(mlp): LlamaMLP((gate_proj): Linear(in_features=4096, out_features=14336, bias=False)(up_proj): Linear(in_features=4096, out_features=14336, bias=False)(down_proj): Linear(in_features=14336, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): LlamaRMSNorm()(post_attention_layernorm): LlamaRMSNorm()))(norm): LlamaRMSNorm())(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
'''結構是一樣的
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")tokenizer.batch_decode(m1.generate(inputs.input_ids, max_length=30))
'''
['<|begin_of_text|>Hey, are you conscious? Can you talk to me? Can you hear me? Are you sure you can hear me? Can you understand what']
'''m1.generate(inputs.input_ids, max_length=30)
'''
tensor([[128000, 19182, 11, 527, 499, 17371, 30, 3053, 499,3137, 311, 757, 30, 3053, 499, 6865, 757, 30,8886, 499, 2103, 27027, 30, 3053, 499, 1518, 757,30, 3053, 499]])
'''






)







-不要驚慌)
)
 和 sorted() 的區別)

、Seata分布式事務)